What is Mixture of Experts? The AI That Activates Only What It Needs

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Imagine if your brain activated every neuron for every thought, reading email would consume as much energy as solving calculus. Instead, your brain activates only the regions it needs. Mixture of Experts (MoE) brings this efficiency to AI, using specialized sub-models that activate only when their expertise is required.
The Architecture That Changed AI Economics
Mixture of Experts emerged from academic research in the 1990s, but became practically important in 2024 when OpenAI revealed that GPT-4 uses MoE architecture. The breakthrough demonstrated that bigger isn't always better, smarter routing beats brute force.

According to Google Research, MoE is "a neural network architecture that contains multiple specialized sub-networks (experts), where a gating mechanism dynamically routes each input to the most relevant experts, activating only a fraction of the total model capacity for any single inference."
The game-changer came when Mistral AI released Mixtral 8x7B in December 2023, showing that an MoE model could match much larger models' performance while using 5x less computation, making powerful AI accessible to smaller organizations.
Mixture of Experts for Business Leaders
For business leaders, MoE means getting GPT-4 level performance at a fraction of the cost and speed, as the AI intelligently activates only the specialized components needed for each query instead of running the entire massive model.
Think of the difference between consulting every department for every question versus routing questions to the right specialists. MoE is like having a brilliant coordinator who instantly knows which expert to activate, avoiding the waste of engaging everyone.
In practical terms, MoE models deliver faster responses, lower infrastructure costs, and better performance-per-dollar than traditional dense models, making sophisticated large language models economically viable for more use cases.
Core Components of Mixture of Experts
MoE systems consist of these essential elements:
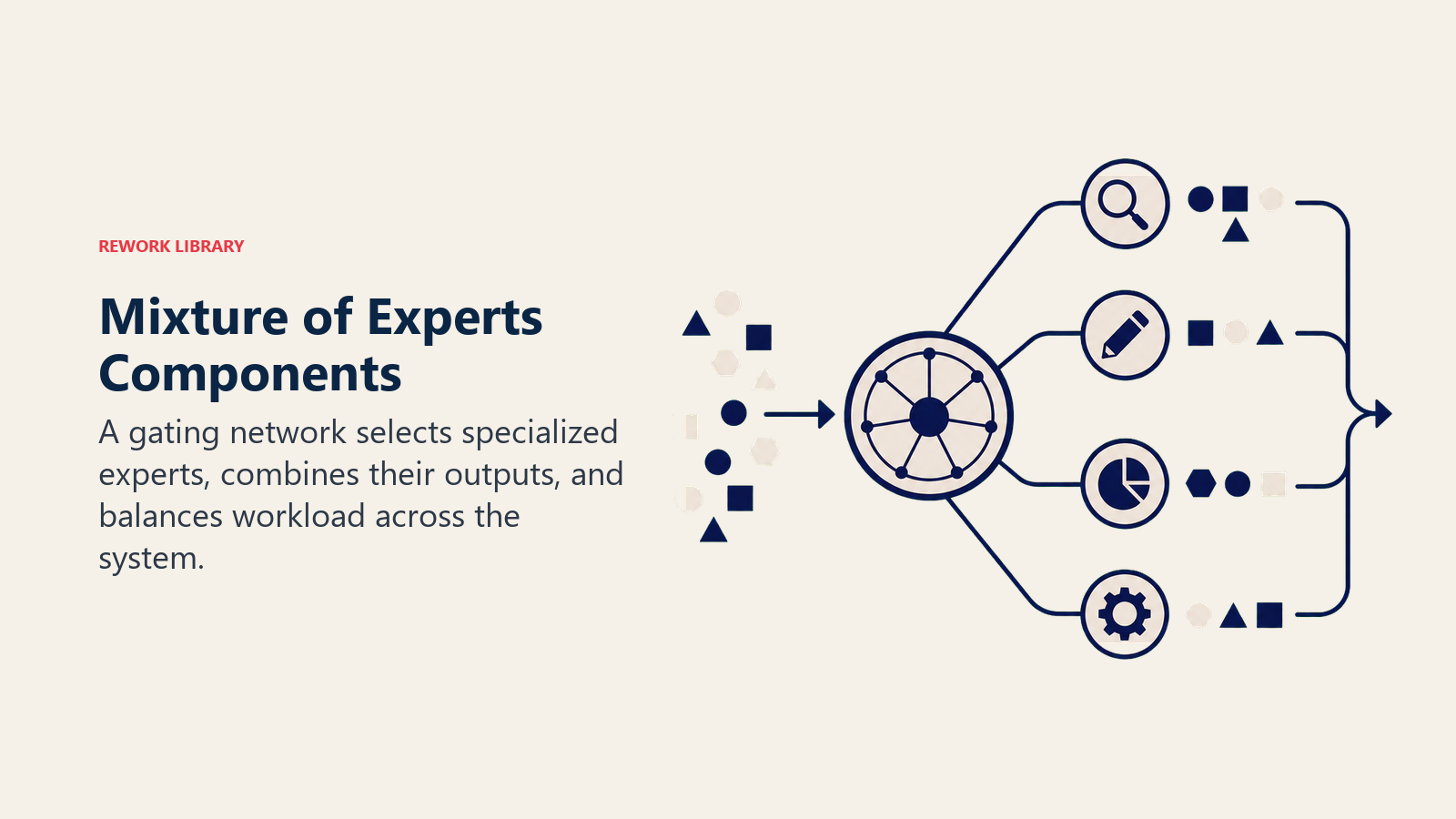
• Expert Networks: Multiple specialized sub-models, each excelling at particular types of inputs or tasks, like having departments that each master different domains
• Gating Network: The routing system that decides which experts to activate for each input, analyzing the query and selecting the most relevant specialists
• Sparse Activation: Only 1-3 experts activate per input instead of all of them, dramatically reducing computation while maintaining quality through smart selection
• Load Balancing: Mechanisms ensuring experts are used roughly equally over time, preventing some from being overworked while others sit idle
• Expert Specialization: Through training, different experts naturally develop focus on different patterns, one might excel at code, another at creative writing, another at analysis
How Mixture of Experts Operates
MoE models follow this operational cycle:
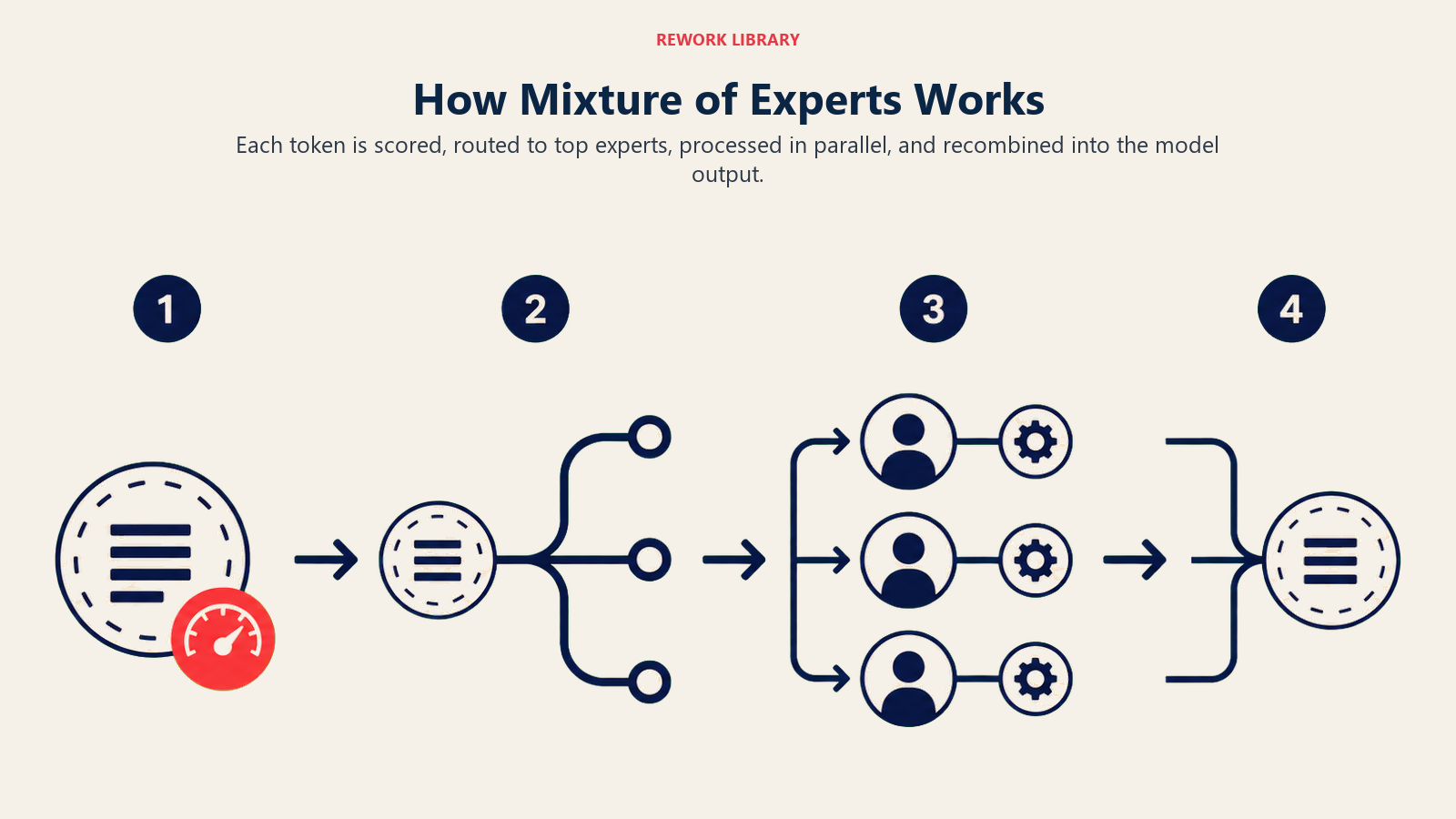
Input Analysis: When you submit a query, the gating network analyzes it to understand what type of expertise is needed, examining linguistic patterns and content
Expert Selection: Based on analysis, the gating network routes your input to the top 1-3 most relevant experts out of potentially hundreds available
Specialized Processing: Only the selected experts activate and process your input, each contributing their specialized knowledge while the rest remain dormant, saving massive computation
This dynamic routing happens in milliseconds, with the gating network learning over time which experts handle which types of queries most effectively.
Types of MoE Implementations
MoE architectures serve different needs:
Type 1: Sparse MoE Best for: Efficient inference at scale Key feature: Routes to small subset of experts Example: GPT-4, Mixtral 8x7B for cost efficiency
Type 2: Dense MoE Best for: Maximum performance Key feature: Activates most or all experts Example: Research models prioritizing quality over speed
Type 3: Hierarchical MoE Best for: Complex multi-domain tasks Key feature: Cascading expert selection at multiple levels Example: Multi-modal systems handling text, vision, audio
Type 4: Soft MoE Best for: Smooth expert blending Key feature: Weighted combination of multiple experts Example: Systems requiring nuanced domain mixing
MoE Delivering Results
Here's how organizations leverage MoE:
Developer Tools Example: Replit's Ghostwriter uses MoE architecture to provide code assistance across dozens of programming languages, activating language-specific experts on demand and reducing response latency by 60% compared to dense models.
Customer Support Example: Intercom's AI agent uses MoE to route questions to specialized experts for technical issues, billing, product questions, and general inquiries, improving resolution accuracy by 35% while handling 3x more conversations per server.
Translation Example: DeepL employs MoE models where different experts specialize in language pairs and domains (legal, medical, technical), achieving 25% better translation quality than single-model approaches in specialized content.
Implementing MoE
Ready to get more from less?
- Start with Large Language Models fundamentals
- Understand Neural Networks architecture
- Learn about Model Optimization techniques
- Consider Fine-Tuning for domain expertise
Frequently Asked Questions about Mixture of Experts
What is Mixture of Experts (MoE)?
Mixture of Experts is a neural network architecture containing multiple specialized sub-networks (experts), where a gating mechanism dynamically routes each input to the most relevant experts, activating only a fraction of total capacity per inference.
What's the difference between MoE and traditional neural networks?
Traditional dense networks activate all parameters for every input. MoE networks activate only relevant specialized experts, achieving better performance with less computation by intelligently routing inputs.
What are the main types of MoE implementations?
Sparse MoE (activates few experts for efficiency), Dense MoE (activates most for quality), Hierarchical MoE (cascading selection), and Soft MoE (weighted blending of experts).
What are examples of MoE models?
GPT-4 (OpenAI's flagship model), Mixtral 8x7B (Mistral AI's efficient model), Switch Transformer (Google's trillion-parameter model), and various specialized domain models using expert routing.
Related Resources
Explore these related concepts to deepen your understanding of Mixture of Experts:
- Large Language Models - The systems that MoE architectures enhance
- Neural Networks - The foundational architecture for expert networks
- Model Optimization - Techniques for efficient AI deployment
- Transformer Architecture - The base architecture often combined with MoE
External Resources
- Google Research - Sparse Expert Models - Research on efficient MoE architectures
- Meta AI - Model Efficiency - Advances in sparse activation and expert routing
- Microsoft Research - Scalable AI - Enterprise MoE implementations
Part of the AI Terms Collection. Last updated: 2026-02-09
