What is AI Technical Debt? The Hidden Cost of Moving Fast

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Your AI project launched on time and under budget. Six months later, accuracy dropped 15%, maintenance costs tripled, and the data science team spends 80% of their time fixing issues instead of building new features. Welcome to AI technical debt.
Defining AI Technical Debt
AI technical debt is the implied cost of future rework and maintenance caused by choosing expedient AI solutions now instead of better approaches that would take longer. It encompasses model architecture shortcuts, data quality compromises, inadequate testing, poor documentation, and integration hacks that create compounding maintenance burden.
According to Google Research, "Technical debt in ML systems is particularly insidious because the system may appear to be working fine while accumulating debt that manifests as degraded performance, increased maintenance costs, and reduced agility over time." This insight came from analyzing production machine learning systems that became increasingly expensive to maintain.
Unlike traditional software debt, AI technical debt includes unique elements: trained models that degrade over time (model drift), data pipelines that slowly corrupt, and tightly coupled systems where changing one model breaks others, making the debt harder to detect and more expensive to pay down.
Executive Perspective
For business leaders, AI technical debt is the difference between AI systems that compound value over time and AI projects that become exponentially more expensive to maintain – it's why your AI budget keeps growing but capabilities don't.
Think of AI technical debt like deferred building maintenance. Skipping routine upkeep saves money initially, but eventually the roof leaks, pipes burst, and repairs cost 10x more than prevention. The building still stands, but operating costs skyrocket.
In practical terms, AI technical debt means models that need constant retraining, data pipelines that break unexpectedly, integration nightmares when updating systems, and talented data scientists stuck fixing old projects instead of creating new value.
Sources of AI Technical Debt
Where debt accumulates:

Model Debt:
- Quick hacks instead of proper architecture
- Over-complex models chosen for benchmarks vs. production needs
- Undocumented assumptions about data distributions
- No version control or reproducibility
- Example: Using latest research models without production readiness assessment
Data Debt:
- Inconsistent data quality checks
- Unstable data dependencies across systems
- Manual data processing not automated
- No monitoring of upstream data changes
- Example: Pipeline assumes data format never changes, breaks when source system updates
Integration Debt:
- Glue code connecting incompatible systems
- Tight coupling between AI and business logic
- Hard-coded configurations and thresholds
- No API abstraction layers
- Example: Business rules embedded in model code, requiring data scientist for business changes
Configuration Debt:
- Parameters hard-coded instead of configurable
- No systematic hyperparameter management
- Feature flags scattered across codebase
- Environment-specific hacks
- Example: Different code paths for prod/dev instead of configuration
Testing Debt:
- Inadequate test coverage for edge cases
- No systematic testing of model predictions
- Missing data validation tests
- Skipped integration and system tests
- Example: Only testing happy path, not data quality degradation
The Compounding Nature
Why AI debt grows exponentially:
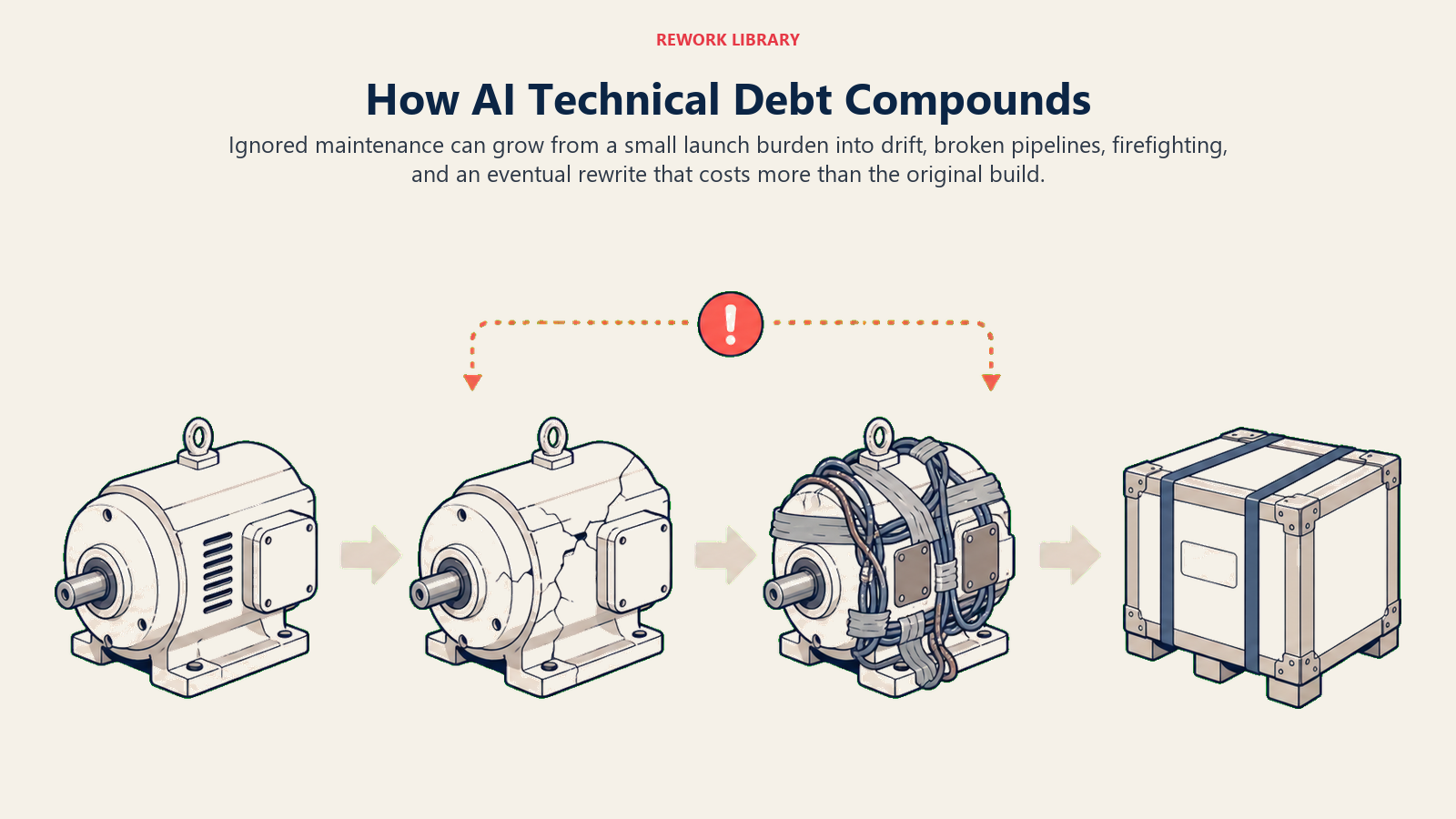
Year 1: Launch
- Model works well, team celebrates
- Minor maintenance issues ignored
- "We'll fix it later" becomes pattern
- Cost: 5% of budget on fixes
Year 2: Cracks Appear
- Accuracy drops due to data drift
- Pipeline breaks from upstream changes
- New features harder to add
- Cost: 20% of budget on maintenance
Year 3: Crisis Mode
- Critical failures increase
- Team paralyzed by interconnected issues
- Business demanding new features but can't deliver
- Cost: 60% of budget firefighting
Year 4: Rewrite or Die
- Debt so high that rewriting is cheaper
- Lost business value during rebuild
- Repeated mistakes without lessons learned
- Cost: 100%+ of original development
Model Drift and Decay
Performance degradation over time:

Concept Drift:
- Problem: Relationship between inputs and outputs changes
- Example: Customer behavior shifts post-pandemic, old model predicts wrong
- Detection: Monitor prediction distribution changes
- Solution: Automated retraining pipelines with MLOps
Data Drift:
- Problem: Input data distribution changes over time
- Example: New product categories not in training data
- Detection: Compare incoming data to training data statistics
- Solution: Data validation and automatic alerts
Upstream Data Changes:
- Problem: Source systems change format or meaning
- Example: Customer age field switches from years to birthdate
- Detection: Schema validation and data quality checks
- Solution: Formal data contracts with upstream teams
Feedback Loops:
- Problem: Model predictions influence future data
- Example: Recommendation system narrows customer interests over time
- Detection: Diversity metrics in predictions
- Solution: Explicit exploration strategies
Data Quality Decay
How data degrades:
Pipeline Complexity:
- Multiple transformation steps create failure points
- Each step adds potential for quality loss
- Debugging becomes archaeological expedition
- Prevention: Simplify pipelines, minimize transformations
Dependency Chains:
- Model depends on features from other models
- Those models depend on more models
- Cascading failures when one breaks
- Prevention: Minimize cross-model dependencies
Manual Interventions:
- Ad-hoc data fixes not automated
- Tribal knowledge about data quirks
- Person leaves, knowledge lost
- Prevention: Automate all data operations
Monitoring Gaps:
- Assuming data quality remains constant
- No alerts when distributions change
- Problems discovered by users, not systems
- Prevention: Comprehensive data pipeline monitoring
Integration Complexity
The spaghetti problem:
Tight Coupling:
- Business logic mixed with ML code
- Changing business rules requires retraining models
- Example: Pricing rules embedded in recommendation model
- Solution: Separate concerns, use model as component
Configuration Hell:
- Hundreds of parameters scattered across systems
- No single source of truth
- Different values in prod/staging creating bugs
- Solution: Centralized configuration management
Version Incompatibility:
- Model trained with library v1.0, production runs v2.0
- Framework updates break deployed models
- Example: TensorFlow upgrade renders old models incompatible
- Solution: Containerization and version pinning
Entangled Systems:
- Can't update one component without breaking others
- Testing requires spinning up entire infrastructure
- Example: A/B testing impossible due to interconnections
- Solution: Microservices architecture with clear interfaces
Real-World Debt Disasters
Cautionary tales:
E-commerce Example: Retailer built recommendation system with hard-coded category IDs, when catalog restructured, model stopped working, 6-month emergency rebuild cost $3M vs. $200K to build properly initially, lost revenue during downtime exceeded rebuild cost.
Financial Services Example: Bank's fraud detection model degraded over 2 years from 95% to 72% accuracy as fraud patterns evolved, no monitoring detected drift, discovered only after fraud losses spiked, emergency retraining and new monitoring cost $5M plus reputation damage.
Healthcare Example: Clinical decision support system with data pipeline assuming specific EMR format, EMR vendor update changed schema, system failed silently producing incorrect recommendations for 3 weeks, resulted in regulatory investigation and lawsuit.
Prevention Strategies
Avoiding debt accumulation:
Design Phase:
- Build for production from day one, not research prototype
- Plan for data drift and concept drift explicitly
- Design simple architectures that can evolve
- Document assumptions and dependencies
Development Phase:
- Implement MLOps practices from start
- Automate everything: testing, deployment, monitoring
- Code review AI systems like critical infrastructure
- Version control data, models, and configurations
Deployment Phase:
- Comprehensive monitoring of models and data
- Automated retraining pipelines
- Gradual rollouts with rollback capability
- Clear ownership and on-call rotation
Maintenance Phase:
- Regular model audits and performance reviews
- Scheduled debt paydown sprints
- Continuous refactoring and simplification
- Post-incident learning and system improvements
Debt Paydown Strategy
Addressing existing debt:
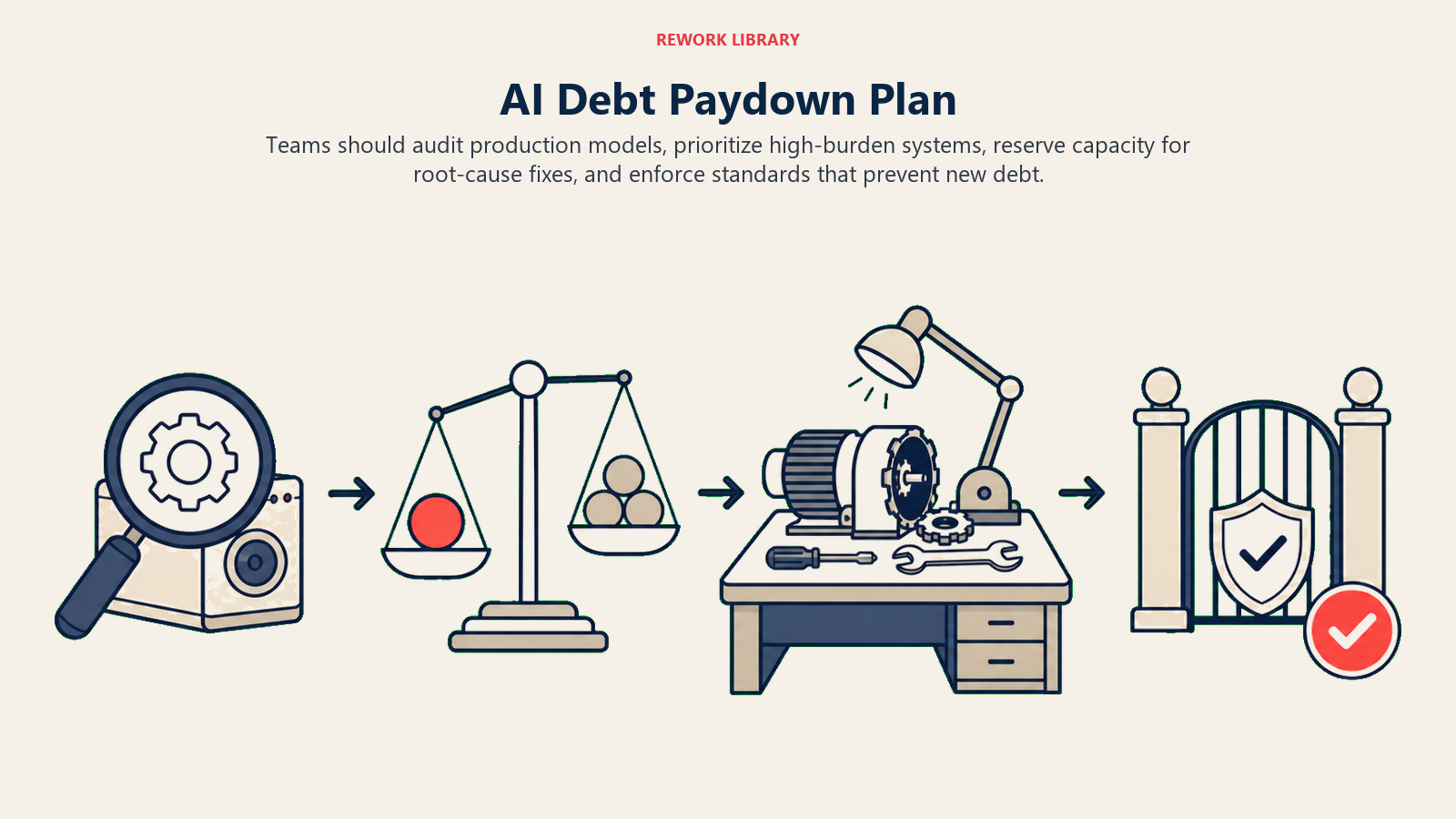
Assess Current Debt:
- Audit all models in production
- Identify high-maintenance systems
- Quantify maintenance costs and business impact
- Prioritize by debt burden and business criticality
Create Paydown Plan:
- Allocate 20-30% of capacity to debt reduction
- Start with highest ROI improvements
- Fix root causes, not symptoms
- Track debt reduction as key metric
Prevent New Debt:
- Require AI governance reviews for new projects
- Enforce MLOps standards
- Make debt visible in planning
- Incentivize quality over speed
Long-Term Discipline:
- Regular architecture reviews
- Continuous refactoring culture
- Knowledge sharing and documentation
- Celebrate debt paydown, not just new features
Measuring AI Technical Debt
Quantifying the invisible:
Direct Cost Metrics:
- Hours spent on maintenance vs. new development
- Incident frequency and resolution time
- Retraining frequency and effort required
- Infrastructure costs trend over time
Quality Metrics:
- Model performance degradation rate
- Data quality scores over time
- Test coverage and pass rates
- Number of production hotfixes
Agility Metrics:
- Time to deploy model updates
- Time to add new features
- Experimentation velocity
- Developer satisfaction scores
Business Impact:
- Revenue lost to model failures
- Customer satisfaction with AI features
- Competitive position vs. AI-native competitors
- AI project ROI trending down
Building Sustainable AI
Steps to debt-free AI systems:
- Implement MLOps for sustainable operations
- Monitor continuously with Model Monitoring
- Build quality data with Data Pipeline best practices
- Govern effectively via AI Governance
Frequently Asked Questions about AI Technical Debt
What is AI Technical Debt?
AI technical debt is the implied cost of future rework and maintenance caused by choosing expedient AI solutions instead of better approaches that take longer, including model architecture shortcuts, data quality compromises, inadequate testing, poor documentation, and integration hacks that create compounding maintenance burden.
What are the five main sources of AI technical debt?
Model Debt (architecture shortcuts and over-complexity), Data Debt (inconsistent quality and unstable dependencies), Integration Debt (glue code and tight coupling), Configuration Debt (hard-coded parameters), and Testing Debt (inadequate coverage and validation).
What is model drift and why does it matter?
Model drift is performance degradation over time due to concept drift (input-output relationships change), data drift (input distributions change), upstream changes (source data format changes), or feedback loops (predictions influence future data). It causes AI systems to silently degrade from 95% to 70% accuracy.
How does AI technical debt compound over time?
Year 1: 5% budget on fixes with minor issues ignored. Year 2: 20% on maintenance as accuracy drops and pipelines break. Year 3: 60% firefighting with team paralyzed. Year 4: 100%+ cost to rewrite system, making initial shortcuts far more expensive than building properly.
How do I prevent AI technical debt?
Design for production from day one, implement MLOps practices from start, automate testing and deployment, monitor models and data comprehensively, maintain clear documentation, allocate 20-30% capacity to debt prevention, and enforce governance reviews for new projects.
External Resources
- Google Research on ML Technical Debt - Foundational research papers
- MLOps Community - Best practices and case studies
- Microsoft MLOps - Enterprise guidance
Related Resources
Explore these related concepts to prevent and manage AI technical debt:
- MLOps - Practices for sustainable AI operations
- Model Monitoring - Detecting drift and degradation early
- Data Pipeline - Building reliable data infrastructure
- AI Governance - Framework preventing debt accumulation
Part of the AI Terms Collection. Last updated: 2026-02-09

Co-Founder, Rework.com
On this page
- Defining AI Technical Debt
- Executive Perspective
- Sources of AI Technical Debt
- The Compounding Nature
- Model Drift and Decay
- Data Quality Decay
- Integration Complexity
- Real-World Debt Disasters
- Prevention Strategies
- Debt Paydown Strategy
- Measuring AI Technical Debt
- Building Sustainable AI
- External Resources
- Related Resources