Bahasa Indonesia
Apa itu Mixture of Experts? AI yang Hanya Mengaktifkan Apa yang Dibutuhkan
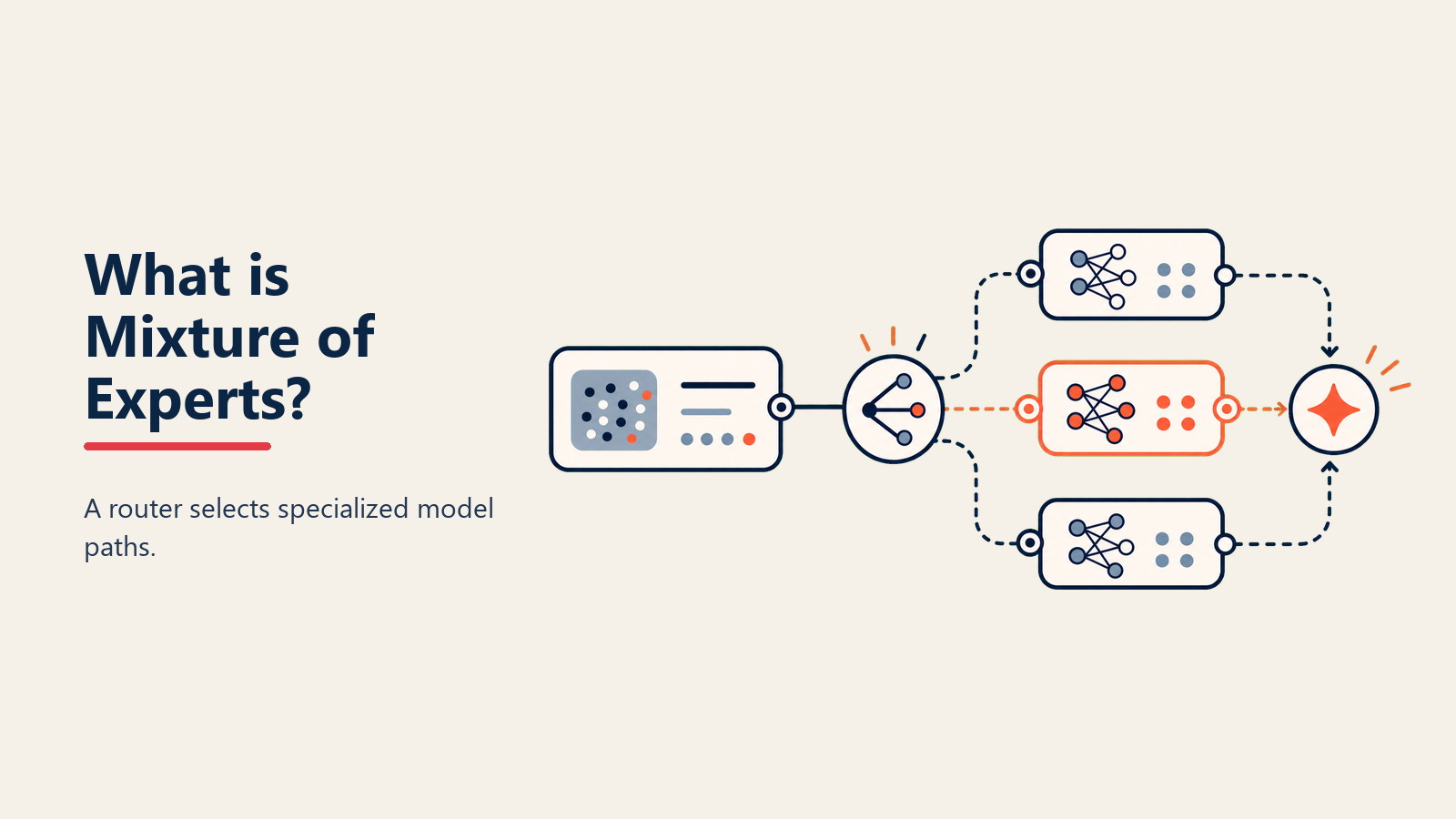 Bayangkan jika otak Anda mengaktifkan setiap neuron untuk setiap pemikiran—membaca email akan mengonsumsi energi sebanyak memecahkan kalkulus. Sebagai gantinya, otak Anda hanya mengaktifkan wilayah yang dibutuhkan. Mixture of Experts (MoE) membawa efisiensi ini ke AI, menggunakan sub-model spesialis yang hanya aktif ketika keahlian mereka diperlukan.
Bayangkan jika otak Anda mengaktifkan setiap neuron untuk setiap pemikiran—membaca email akan mengonsumsi energi sebanyak memecahkan kalkulus. Sebagai gantinya, otak Anda hanya mengaktifkan wilayah yang dibutuhkan. Mixture of Experts (MoE) membawa efisiensi ini ke AI, menggunakan sub-model spesialis yang hanya aktif ketika keahlian mereka diperlukan.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Arsitektur yang Mengubah Ekonomi AI
Mixture of Experts muncul dari riset akademis di tahun 1990-an, tetapi menjadi praktis penting pada tahun 2024 ketika OpenAI mengungkapkan bahwa GPT-4 menggunakan arsitektur MoE. Terobosan ini mendemonstrasikan bahwa lebih besar tidak selalu lebih baik—routing yang lebih cerdas mengalahkan brute force.
Menurut Google Research, MoE adalah "arsitektur neural network yang berisi beberapa sub-network spesialis (experts), di mana mekanisme gating secara dinamis merutekan setiap input ke expert yang paling relevan, mengaktifkan hanya sebagian kecil dari total kapasitas model untuk setiap inferensi tunggal."
Game-changer datang ketika Mistral AI merilis Mixtral 8x7B pada Desember 2023, menunjukkan bahwa model MoE dapat menyamai kinerja model yang jauh lebih besar sambil menggunakan komputasi 5x lebih sedikit, membuat AI yang powerful dapat diakses oleh organisasi yang lebih kecil.
Mixture of Experts untuk Pemimpin Bisnis
Bagi pemimpin bisnis, MoE berarti mendapatkan kinerja level GPT-4 dengan sebagian kecil biaya dan kecepatan, karena AI secara cerdas hanya mengaktifkan komponen spesialis yang diperlukan untuk setiap query alih-alih menjalankan seluruh model besar.
Pikirkan perbedaan antara berkonsultasi dengan setiap departemen untuk setiap pertanyaan versus merutekan pertanyaan ke spesialis yang tepat. MoE seperti memiliki koordinator brilian yang langsung tahu expert mana yang harus diaktifkan, menghindari pemborosan melibatkan semua orang.
Dalam istilah praktis, model MoE memberikan respons lebih cepat, biaya infrastruktur lebih rendah, dan kinerja per dolar yang lebih baik daripada model dense tradisional, membuat large language models yang canggih secara ekonomis layak untuk lebih banyak use case.
Komponen Inti Mixture of Experts
Sistem MoE terdiri dari elemen-elemen penting ini:
• Expert Networks: Beberapa sub-model spesialis, masing-masing unggul pada tipe input atau tugas tertentu, seperti memiliki departemen yang masing-masing menguasai domain yang berbeda
• Gating Network: Sistem routing yang memutuskan expert mana yang akan diaktifkan untuk setiap input, menganalisis query dan memilih spesialis yang paling relevan
• Sparse Activation: Hanya 1-3 expert yang aktif per input alih-alih semuanya, secara dramatis mengurangi komputasi sambil mempertahankan kualitas melalui seleksi cerdas
• Load Balancing: Mekanisme yang memastikan expert digunakan secara merata dari waktu ke waktu, mencegah beberapa bekerja terlalu keras sementara yang lain menganggur
• Expert Specialization: Melalui training, expert yang berbeda secara alami mengembangkan fokus pada pola yang berbeda—satu mungkin unggul dalam kode, yang lain dalam penulisan kreatif, yang lain dalam analisis
Bagaimana Mixture of Experts Beroperasi
Model MoE mengikuti siklus operasional ini:
Analisis Input: Ketika Anda mengirimkan query, gating network menganalisisnya untuk memahami jenis keahlian apa yang diperlukan, memeriksa pola linguistik dan konten
Seleksi Expert: Berdasarkan analisis, gating network merutekan input Anda ke 1-3 expert yang paling relevan dari potensi ratusan yang tersedia
Pemrosesan Spesialis: Hanya expert yang dipilih yang aktif dan memproses input Anda, masing-masing berkontribusi dengan pengetahuan khusus mereka sementara sisanya tetap dormant, menghemat komputasi besar
Routing dinamis ini terjadi dalam milidetik, dengan gating network belajar dari waktu ke waktu expert mana yang menangani jenis query mana paling efektif.
Jenis Implementasi MoE
Arsitektur MoE melayani kebutuhan yang berbeda:
Tipe 1: Sparse MoE Terbaik untuk: Inferensi efisien dalam skala besar Fitur kunci: Merutekan ke subset kecil expert Contoh: GPT-4, Mixtral 8x7B untuk efisiensi biaya
Tipe 2: Dense MoE Terbaik untuk: Kinerja maksimal Fitur kunci: Mengaktifkan sebagian besar atau semua expert Contoh: Model riset yang memprioritaskan kualitas daripada kecepatan
Tipe 3: Hierarchical MoE Terbaik untuk: Tugas multi-domain kompleks Fitur kunci: Seleksi expert bertingkat di beberapa level Contoh: Sistem multi-modal yang menangani teks, visi, audio
Tipe 4: Soft MoE Terbaik untuk: Blending expert yang halus Fitur kunci: Kombinasi tertimbang dari beberapa expert Contoh: Sistem yang memerlukan mixing domain yang bernuansa
MoE Memberikan Hasil
Berikut cara organisasi memanfaatkan MoE:
Contoh Developer Tools: Ghostwriter Replit menggunakan arsitektur MoE untuk memberikan bantuan kode di puluhan bahasa pemrograman, mengaktifkan expert spesifik bahasa sesuai permintaan dan mengurangi latensi respons sebesar 60% dibandingkan model dense.
Contoh Customer Support: Agen AI Intercom menggunakan MoE untuk merutekan pertanyaan ke expert spesialis untuk masalah teknis, penagihan, pertanyaan produk, dan inquiry umum, meningkatkan akurasi resolusi sebesar 35% sambil menangani 3x lebih banyak percakapan per server.
Contoh Terjemahan: DeepL menggunakan model MoE di mana expert yang berbeda berspesialisasi dalam pasangan bahasa dan domain (hukum, medis, teknis), mencapai kualitas terjemahan 25% lebih baik daripada pendekatan single-model dalam konten spesialis.
Mengimplementasikan MoE
Siap mendapatkan lebih banyak dari lebih sedikit?
- Mulai dengan fundamental Large Language Models
- Pahami arsitektur Neural Networks
- Pelajari teknik Model Optimization
- Pertimbangkan Fine-Tuning untuk keahlian domain
FAQ Section
Frequently Asked Questions about Mixture of Experts
Apa itu Mixture of Experts (MoE)?
Mixture of Experts adalah arsitektur neural network yang berisi beberapa sub-network spesialis (experts), di mana mekanisme gating secara dinamis merutekan setiap input ke expert yang paling relevan, mengaktifkan hanya sebagian kecil dari total kapasitas per inferensi.
Apa perbedaan antara MoE dan neural network tradisional?
Neural network dense tradisional mengaktifkan semua parameter untuk setiap input. Network MoE hanya mengaktifkan expert spesialis yang relevan, mencapai kinerja lebih baik dengan komputasi lebih sedikit melalui routing cerdas input.
Apa saja jenis utama implementasi MoE?
Sparse MoE (mengaktifkan beberapa expert untuk efisiensi), Dense MoE (mengaktifkan sebagian besar untuk kualitas), Hierarchical MoE (seleksi bertingkat), dan Soft MoE (blending tertimbang expert).
Apa contoh model MoE?
GPT-4 (model flagship OpenAI), Mixtral 8x7B (model efisien Mistral AI), Switch Transformer (model triliunan parameter Google), dan berbagai model domain spesialis yang menggunakan expert routing.
Related Resources
Jelajahi konsep terkait ini untuk memperdalam pemahaman Anda tentang Mixture of Experts:
- Large Language Models - Sistem yang ditingkatkan arsitektur MoE
- Neural Networks - Arsitektur fondasi untuk expert networks
- Model Optimization - Teknik untuk deployment AI yang efisien
- Transformer Architecture - Arsitektur dasar yang sering dikombinasikan dengan MoE
External Resources
- Google Research - Sparse Expert Models - Research on efficient MoE architectures
- Meta AI - Model Efficiency - Advances in sparse activation and expert routing
- Microsoft Research - Scalable AI - Enterprise MoE implementations
Bagian dari AI Terms Collection. Terakhir diperbarui: 2026-02-09

Co-Founder, Rework.com