What is Inference Optimization? Scaling AI Without Breaking the Bank
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Training an AI model once costs millions. But running that model billions of times costs even more. A single large language model serving 100,000 daily users can rack up $50,000 monthly in compute costs. Inference optimization has become the critical discipline that separates AI pilots from profitable AI products, enabling companies to serve the same quality results at 10x lower cost and 5x faster speed.
From Prototype to Production Reality
Inference optimization emerged as a distinct field around 2019 when companies realized that model accuracy wasn't enough, production AI systems needed to be fast, cheap, and scalable. What started as ad-hoc performance tuning evolved into a systematic engineering discipline.

NVIDIA defines inference optimization as "the process of maximizing throughput, minimizing latency, and reducing computational costs for AI model predictions in production environments through software optimization, hardware acceleration, and architectural improvements."
The field exploded when businesses discovered that simple optimization techniques could reduce costs by 70-90% while improving response times from seconds to milliseconds, making AI applications feel instantaneous and economically viable.
Making Sense for Business Leaders
For business leaders, inference optimization means delivering the same AI capabilities at a fraction of the cost and latency, enabling real-time applications, reducing infrastructure spend by 60-80%, and scaling AI services profitably as usage grows exponentially.
Think of it as the difference between a restaurant cooking each order individually versus preparing ingredients in advance, batching similar orders, and using specialized equipment. Both deliver the same food quality, but one is 10x more efficient.
In practical terms, inference optimization enables you to serve thousands of users simultaneously without crushing your cloud bill, respond to customer queries in milliseconds instead of seconds, and scale from pilot to production without linear cost increases.
Key Elements of Inference Optimization
Inference optimization encompasses these essential techniques:

• Batching: Processing multiple requests together instead of one at a time, dramatically improving throughput by leveraging GPU parallel processing capabilities
• Caching: Storing common queries and responses to avoid redundant computation, reducing latency from seconds to milliseconds for frequently asked questions
• Hardware Acceleration: Using specialized processors (GPUs, TPUs, custom ASICs) optimized for AI inference, delivering 10-100x speedups over general-purpose CPUs
• Model Compression: Reducing model size through quantization and pruning while maintaining accuracy, enabling faster loading and execution
• Request Routing: Directing different query types to appropriate models (simple queries to small models, complex ones to large models), optimizing cost-accuracy trade-offs
The Inference Optimization Process
Implementing inference optimization follows these steps:
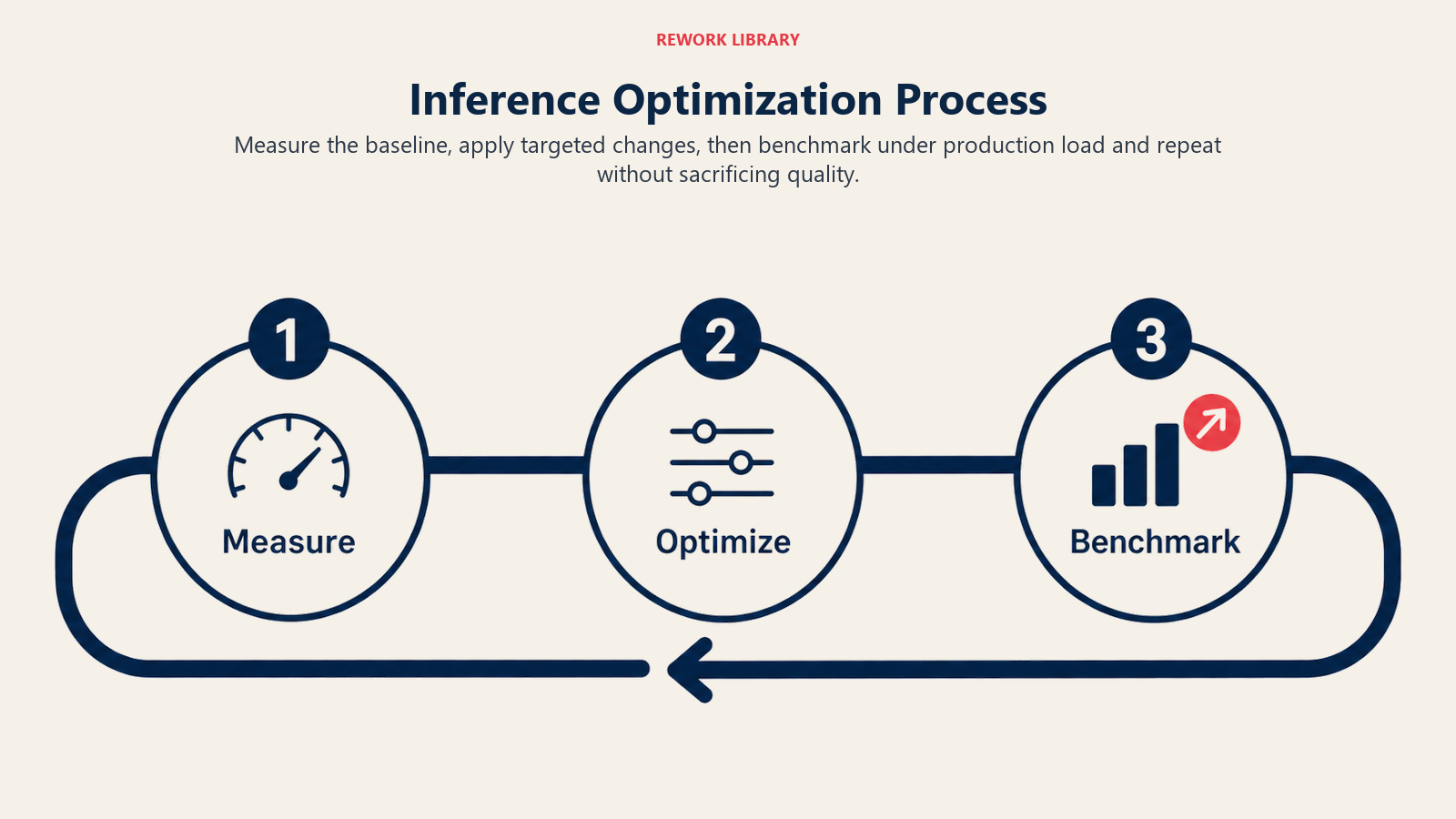
Measure Baseline: Profile current inference performance, identifying bottlenecks in preprocessing, model execution, and postprocessing to understand where optimization efforts will have maximum impact
Apply Optimizations: Implement batching for throughput, caching for common requests, model compression for size, and hardware acceleration for speed, often combining multiple techniques
Benchmark and Iterate: Test optimized system under production load, measuring latency, throughput, and cost to ensure improvements meet business requirements without sacrificing quality
This process transforms a proof-of-concept that handles 10 requests per second into a production system serving 10,000 requests per second at lower total cost.
Types of Inference Optimization
Inference optimization employs several approaches:
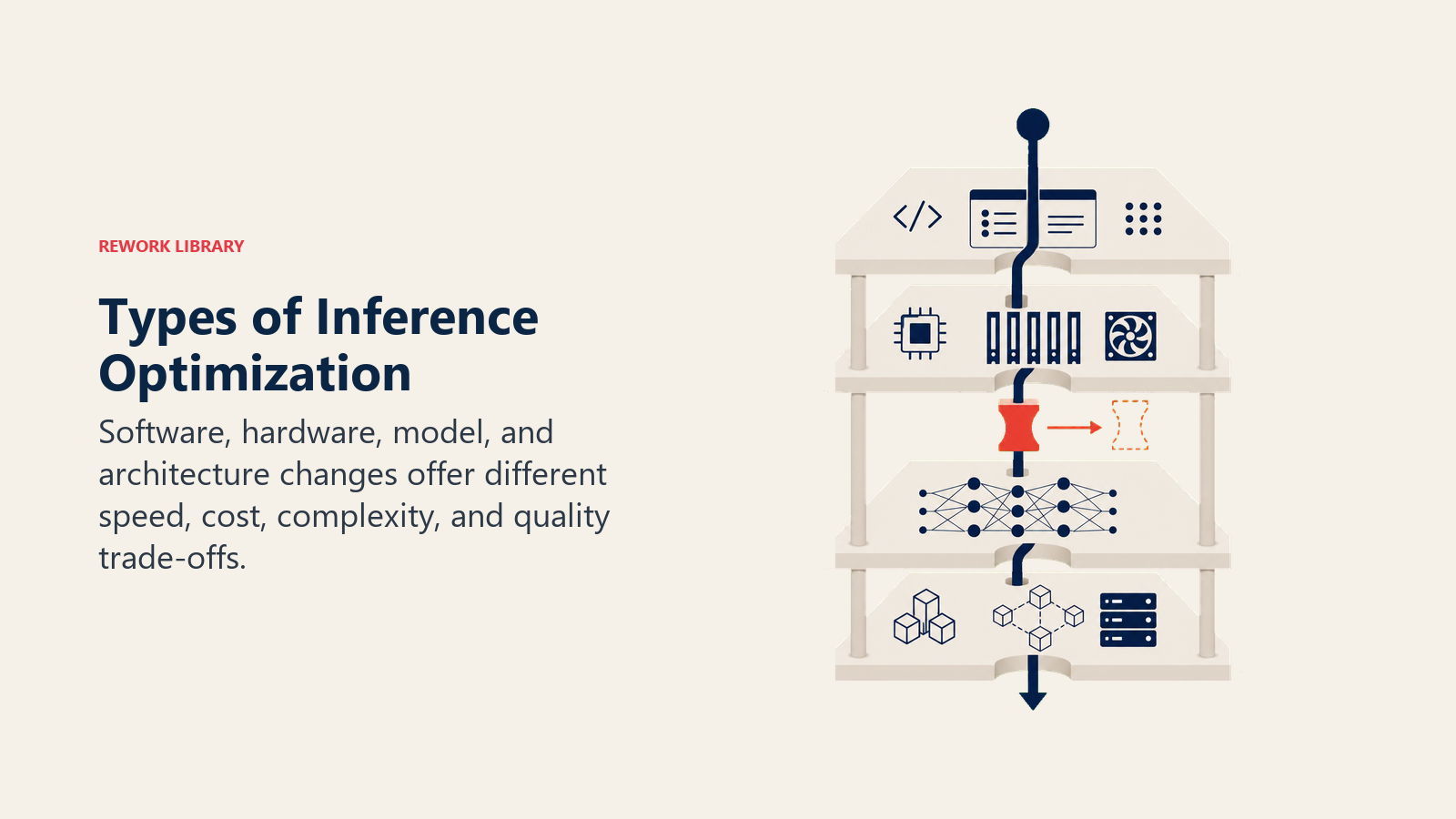
Type 1: Software Optimization Best for: Quick wins without infrastructure changes Key feature: Code-level improvements and algorithm tuning Example: Implementing request batching to process 50 queries simultaneously instead of sequentially
Type 2: Hardware Acceleration Best for: Maximum performance improvements Key feature: Specialized inference processors Example: Moving from CPU to NVIDIA T4 GPUs for 20x speedup
Type 3: Model Optimization Best for: Reducing computational requirements Key feature: Smaller, faster models with same capabilities Example: Using knowledge distillation to create a 4x smaller model with 95% original accuracy
Type 4: Architecture Optimization Best for: Large-scale production systems Key feature: Distributed processing and load balancing Example: Multi-region deployment with intelligent request routing
Inference Optimization in Action
Here's how businesses actually use inference optimization:
E-commerce Example: Shopify optimized their product recommendation engine by implementing batching, caching, and model quantization. Response times dropped from 800ms to 50ms, and infrastructure costs decreased by 73% while serving 10x more requests.
Customer Service Example: Zendesk's AI ticket routing system uses inference optimization to process 100,000 daily tickets. By caching common question patterns and using smaller specialized models for 80% of queries, they reduced costs by $200,000 annually.
Financial Services Example: Stripe optimized fraud detection inference to analyze transactions in under 100ms (from 2 seconds), combining GPU acceleration, request batching, and model compression. This enabled real-time fraud prevention without customer experience impact.
Your Path to Inference Optimization Mastery
Ready to make your AI systems fast and affordable?
- Understand model compression with Quantization
- Explore efficient architectures via Knowledge Distillation
- Learn about production deployment with MLOps
Learn More
Expand your understanding of related AI concepts:
- Model Serving - Deploying models to production
- Edge AI - Running inference on devices
- Model Compression - Reducing model size and complexity
- Latency - Understanding response time factors
External Resources
- NVIDIA AI Inference Platform - Hardware acceleration and optimization techniques
- Hugging Face Optimization Guide - Practical tutorials on model optimization
- Google Cloud AI Performance - Scalable inference architecture patterns
Frequently Asked Questions about Inference Optimization
What is Inference Optimization?
Inference optimization is the process of making AI model predictions faster, cheaper, and more scalable in production through techniques like batching, caching, hardware acceleration, and model compression.
What's the difference between training optimization and inference optimization?
Training optimization focuses on learning models faster and cheaper (happens once). Inference optimization focuses on making predictions faster and cheaper (happens millions of times in production). Inference optimization has greater business impact because it affects every user request.
How much can inference optimization reduce costs?
Properly implemented inference optimization typically reduces costs by 60-90% while improving speed by 5-50x. The exact savings depend on current baseline, optimization techniques applied, and workload characteristics.
What are the main inference optimization techniques?
The core techniques are batching (process multiple requests together), caching (store common results), hardware acceleration (use specialized processors), model compression (reduce model size), and request routing (match queries to appropriate models).
When should I optimize inference?
Start optimizing when moving from prototype to production, when costs scale linearly with usage, when latency affects user experience, or when serving thousands of requests daily. Early optimization prevents expensive infrastructure scaling.
Part of the AI Terms Collection. Last updated: 2026-02-09

Co-Founder, Rework.com