Apakah Mixture of Experts? AI yang Mengaktifkan Hanya Apa yang Ia Perlukan
 Bayangkan jika otak anda mengaktifkan setiap neuron untuk setiap pemikiran—membaca e-mel akan menggunakan tenaga sebanyak menyelesaikan kalkulus. Sebaliknya, otak anda mengaktifkan hanya kawasan yang ia perlukan. Mixture of Experts (MoE) membawa kecekapan ini kepada AI, menggunakan sub-model khusus yang mengaktifkan hanya bila kepakaran mereka diperlukan.
Bayangkan jika otak anda mengaktifkan setiap neuron untuk setiap pemikiran—membaca e-mel akan menggunakan tenaga sebanyak menyelesaikan kalkulus. Sebaliknya, otak anda mengaktifkan hanya kawasan yang ia perlukan. Mixture of Experts (MoE) membawa kecekapan ini kepada AI, menggunakan sub-model khusus yang mengaktifkan hanya bila kepakaran mereka diperlukan.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Seni Bina yang Mengubah Ekonomi AI
Mixture of Experts muncul daripada penyelidikan akademik pada 1990-an, tetapi menjadi penting secara praktikal pada 2024 apabila OpenAI mendedahkan bahawa GPT-4 menggunakan seni bina MoE. Terobosan itu menunjukkan bahawa lebih besar tidak sentiasa lebih baik—penghalaan lebih pintar mengalahkan kekuatan kasar.
Menurut Google Research, MoE adalah "seni bina neural network yang mengandungi berbilang sub-rangkaian khusus (pakar), di mana mekanisme gating secara dinamik menghalakan setiap input kepada pakar paling relevan, mengaktifkan hanya sebahagian daripada jumlah kapasiti model untuk mana-mana inference tunggal."
Pengubah permainan datang apabila Mistral AI melancarkan Mixtral 8x7B pada Disember 2023, menunjukkan bahawa model MoE boleh sepadan prestasi model lebih besar sambil menggunakan 5x kurang pengiraan, menjadikan AI berkuasa boleh diakses oleh organisasi lebih kecil.
Mixture of Experts untuk Pemimpin Perniagaan
Untuk pemimpin perniagaan, MoE bermakna mendapat prestasi tahap GPT-4 pada sebahagian kecil kos dan kelajuan, kerana AI secara pintar mengaktifkan hanya komponen khusus yang diperlukan untuk setiap pertanyaan dan bukannya menjalankan keseluruhan model besar-besaran.
Fikirkan perbezaan antara merujuk setiap jabatan untuk setiap soalan berbanding menghalakan soalan kepada pakar yang betul. MoE seperti mempunyai penyelaras cemerlang yang serta-merta tahu pakar mana untuk diaktifkan, mengelakkan pembaziran melibatkan semua orang.
Secara praktikalnya, model MoE menyampaikan respons lebih pantas, kos infrastruktur lebih rendah, dan prestasi lebih baik setiap dolar daripada model padat tradisional, menjadikan large language models canggih berdaya maju ekonomi untuk lebih banyak kes penggunaan.
Komponen Teras Mixture of Experts
Sistem MoE terdiri daripada elemen penting ini:
• Expert Networks: Berbilang sub-model khusus, setiap satu cemerlang pada jenis input atau tugas tertentu, seperti mempunyai jabatan yang setiap satu menguasai domain berbeza
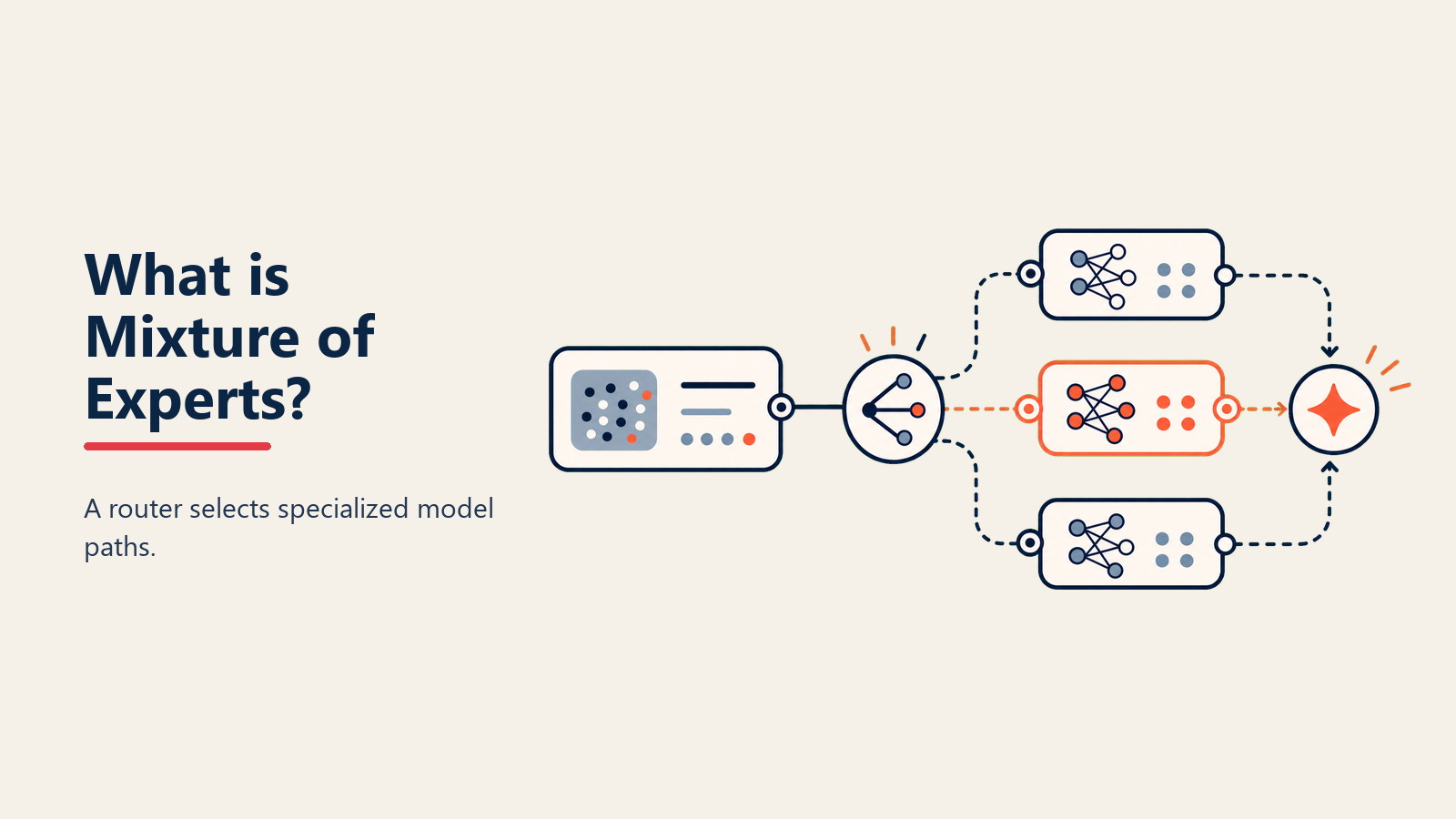
• Gating Network: Sistem penghalaan yang memutuskan pakar mana untuk diaktifkan untuk setiap input, menganalisis pertanyaan dan memilih pakar paling relevan
• Sparse Activation: Hanya 1-3 pakar mengaktifkan setiap input dan bukannya semua daripada mereka, mengurangkan pengiraan secara dramatik sambil mengekalkan kualiti melalui pemilihan pintar
• Load Balancing: Mekanisme memastikan pakar digunakan kira-kira sama rata sepanjang masa, mencegah sebahagian daripada terlebih bekerja manakala yang lain duduk diam
• Expert Specialization: Melalui latihan, pakar berbeza secara semula jadi membangunkan tumpuan pada corak berbeza—satu mungkin cemerlang dalam kod, yang lain dalam penulisan kreatif, yang lain dalam analisis
Cara Mixture of Experts Beroperasi
Model MoE mengikuti kitaran operasi ini:
Input Analysis: Bila anda hantar pertanyaan, gating network menganalisisnya untuk memahami jenis kepakaran apa yang diperlukan, memeriksa corak linguistik dan kandungan
Expert Selection: Berdasarkan analisis, gating network menghalakan input anda kepada 1-3 pakar paling relevan daripada berpotensi ratusan yang ada
Specialized Processing: Hanya pakar terpilih mengaktifkan dan memproses input anda, setiap satu menyumbangkan pengetahuan khusus mereka manakala yang lain kekal tidak aktif, menjimatkan pengiraan besar-besaran
Penghalaan dinamik ini berlaku dalam milisaat, dengan gating network belajar sepanjang masa pakar mana mengendalikan jenis pertanyaan mana dengan paling berkesan.
Jenis Pelaksanaan MoE
Seni bina MoE memenuhi keperluan berbeza:
Jenis 1: Sparse MoE Terbaik untuk: Inference cekap pada skala Ciri utama: Menghala kepada subset kecil pakar Contoh: GPT-4, Mixtral 8x7B untuk kecekapan kos
Jenis 2: Dense MoE Terbaik untuk: Prestasi maksimum Ciri utama: Mengaktifkan kebanyakan atau semua pakar Contoh: Model penyelidikan mengutamakan kualiti berbanding kelajuan
Jenis 3: Hierarchical MoE Terbaik untuk: Tugas berbilang domain kompleks Ciri utama: Pemilihan pakar berperingkat pada berbilang tahap Contoh: Sistem pelbagai modal mengendalikan teks, penglihatan, audio
Jenis 4: Soft MoE Terbaik untuk: Pengadunan pakar licin Ciri utama: Kombinasi berwajaran berbilang pakar Contoh: Sistem memerlukan pencampuran domain bernuansa
MoE Menyampaikan Hasil
Begini cara organisasi memanfaatkan MoE:
Contoh Developer Tools: Ghostwriter Replit menggunakan seni bina MoE untuk menyediakan bantuan kod merentas berpuluh-puluh bahasa pengaturcaraan, mengaktifkan pakar khusus bahasa atas permintaan dan mengurangkan latency respons sebanyak 60% berbanding model padat.
Contoh Customer Support: Ejen AI Intercom menggunakan MoE untuk menghalakan soalan kepada pakar khusus untuk isu teknikal, bil, soalan produk, dan pertanyaan umum, meningkatkan ketepatan penyelesaian sebanyak 35% sambil mengendalikan 3x lebih banyak perbualan setiap server.
Contoh Terjemahan: DeepL menggunakan model MoE di mana pakar berbeza mengkhusus dalam pasangan bahasa dan domain (undang-undang, perubatan, teknikal), mencapai 25% kualiti terjemahan lebih baik daripada pendekatan model tunggal dalam kandungan khusus.
Melaksanakan MoE
Bersedia untuk dapat lebih daripada kurang?
- Mulakan dengan asas Large Language Models
- Fahami seni bina Neural Networks
- Ketahui tentang teknik Model Optimization
- Pertimbangkan Fine-Tuning untuk kepakaran domain
Bahagian FAQ
Soalan Lazim tentang Mixture of Experts
Apakah Mixture of Experts (MoE)?
Mixture of Experts adalah seni bina neural network mengandungi berbilang sub-rangkaian khusus (pakar), di mana mekanisme gating secara dinamik menghalakan setiap input kepada pakar paling relevan, mengaktifkan hanya sebahagian daripada jumlah kapasiti setiap inference.
Apakah perbezaan antara MoE dan neural network tradisional?
Rangkaian padat tradisional mengaktifkan semua parameter untuk setiap input. Rangkaian MoE mengaktifkan hanya pakar khusus yang relevan, mencapai prestasi lebih baik dengan kurang pengiraan melalui penghalaan pintar input.
Apakah jenis utama pelaksanaan MoE?
Sparse MoE (mengaktifkan beberapa pakar untuk kecekapan), Dense MoE (mengaktifkan kebanyakan untuk kualiti), Hierarchical MoE (pemilihan berperingkat), dan Soft MoE (pengadunan berwajaran pakar).
Apakah contoh model MoE?
GPT-4 (model utama OpenAI), Mixtral 8x7B (model cekap Mistral AI), Switch Transformer (model trilion parameter Google), dan pelbagai model domain khusus menggunakan penghalaan pakar.
Sumber Berkaitan
Terokai konsep berkaitan ini untuk memperdalam pemahaman anda tentang Mixture of Experts:
- Large Language Models - Sistem yang seni bina MoE tingkatkan
- Neural Networks - Seni bina asas untuk expert networks
- Model Optimization - Teknik untuk deployment AI cekap
- Transformer Architecture - Seni bina asas sering digabungkan dengan MoE
Sumber Luar
- Google Research - Sparse Expert Models - Penyelidikan tentang seni bina MoE cekap
- Meta AI - Model Efficiency - Kemajuan dalam pengaktifan jarang dan penghalaan pakar
- Microsoft Research - Scalable AI - Pelaksanaan MoE enterprise
Sebahagian daripada AI Terms Collection. Kemaskini terakhir: 2026-02-09
