Mixture of Expertsとは?必要なものだけを活性化するAI
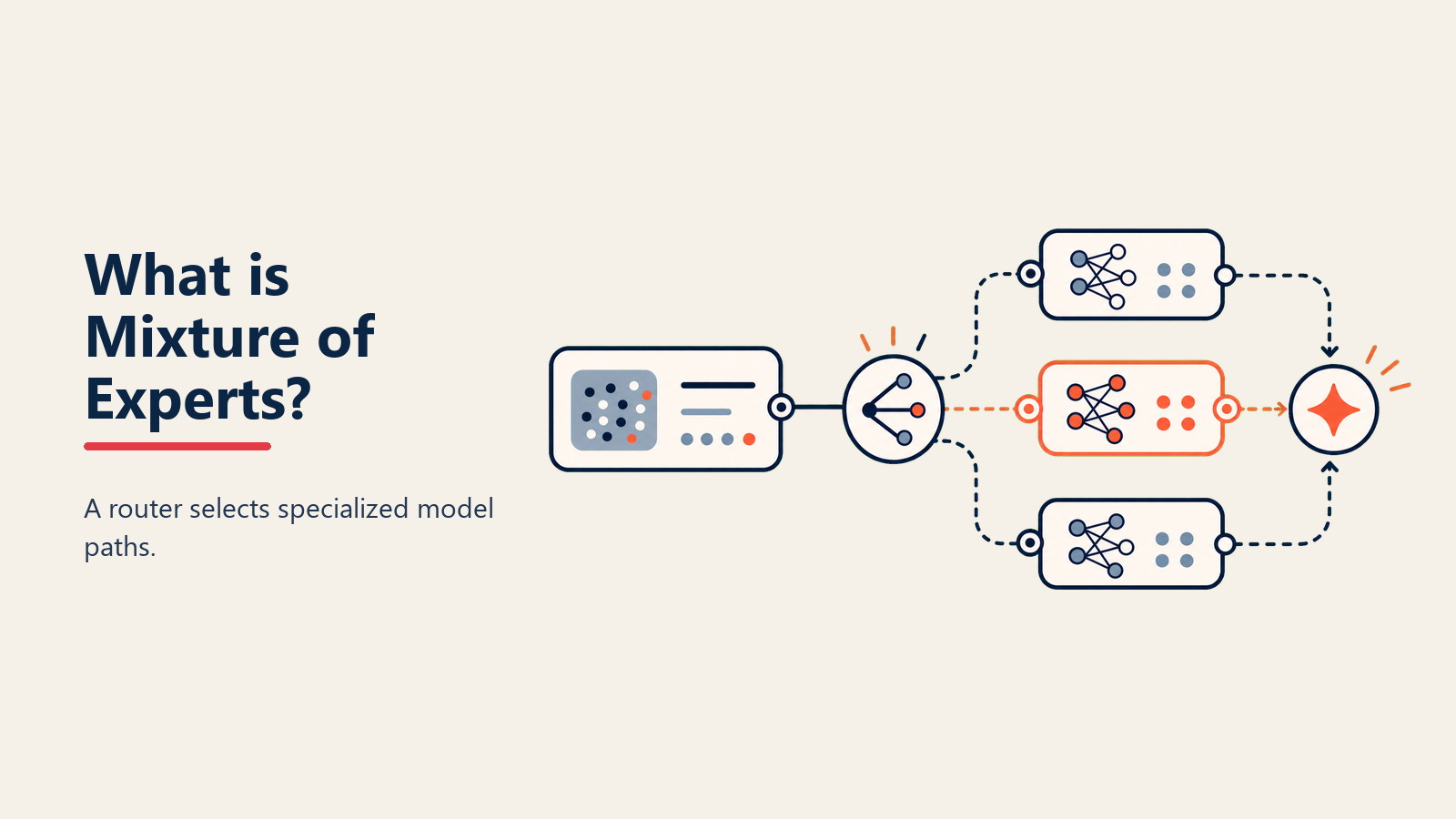 もしあなたの脳がすべての思考に対してすべてのニューロンを活性化したら - メールを読むことが微積分を解くのと同じエネルギーを消費することになります。代わりに、あなたの脳は必要な領域だけを活性化します。Mixture of Experts (MoE)はこの効率性をAIにもたらし、専門性が必要なときにのみ活性化する専門化されたサブモデルを使用します。
もしあなたの脳がすべての思考に対してすべてのニューロンを活性化したら - メールを読むことが微積分を解くのと同じエネルギーを消費することになります。代わりに、あなたの脳は必要な領域だけを活性化します。Mixture of Experts (MoE)はこの効率性をAIにもたらし、専門性が必要なときにのみ活性化する専門化されたサブモデルを使用します。
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AI経済を変えたアーキテクチャ
Mixture of Expertsは1990年代の学術研究から生まれましたが、2024年にOpenAIがGPT-4がMoEアーキテクチャを使用していることを明らかにしたとき、実用的に重要になりました。この画期的な発見は、大きければ良いというわけではないことを示しました - スマートなルーティングがブルートフォースを打ち負かします。
Google Researchによれば、MoEは「複数の専門化されたサブネットワーク(エキスパート)を含むNeural Networkアーキテクチャであり、ゲーティングメカニズムが各入力を最も関連性の高いエキスパートに動的にルーティングし、単一の推論に対して総モデル容量のほんの一部だけを活性化する」ものです。
ゲームチェンジャーは、Mistral AIが2023年12月にMixtral 8x7Bをリリースし、MoEモデルが5分の1の計算で、はるかに大きなモデルのパフォーマンスに匹敵できることを示したときに来ました。これにより、強力なAIが小規模組織にもアクセス可能になりました。
ビジネスリーダーのためのMixture of Experts
ビジネスリーダーにとって、MoEは、AIが各クエリに必要な専門化されたコンポーネントのみをインテリジェントに活性化し、巨大なモデル全体を実行する代わりに、コストとスピードの一部でGPT-4レベルのパフォーマンスを得ることを意味します。
すべての質問に対してすべての部門に相談することと、正しいスペシャリストに質問をルーティングすることの違いと考えてください。MoEは、どのエキスパートを活性化すべきかを瞬時に知る優秀なコーディネーターを持つようなもので、全員を関与させる無駄を避けます。
実用的には、MoEモデルは、従来のDenseモデルよりも速いレスポンス、低いインフラストラクチャコスト、優れたコストパフォーマンスを提供し、より多くのユースケースで洗練されたLarge Language Modelsを経済的に実行可能にします。
Mixture of Expertsのコアコンポーネント
MoEシステムは、これらの本質的な要素で構成されています:
• Expert Networks: 複数の専門化されたサブモデルで、それぞれが特定のタイプの入力またはタスクに優れ、異なるドメインをマスターする部門を持つようなもの
• Gating Network: 各入力に対してどのエキスパートを活性化するかを決定するルーティングシステムで、クエリを分析し、最も関連性の高いスペシャリストを選択
• Sparse Activation: すべてではなく、入力ごとに1-3のエキスパートのみが活性化し、スマートな選択によって品質を維持しながら計算を劇的に削減
• Load Balancing: エキスパートが時間とともにほぼ均等に使用されることを保証するメカニズムで、一部が過労になり、他が待機するのを防ぐ
• Expert Specialization: トレーニングを通じて、異なるエキスパートが自然に異なるパターンに焦点を合わせ - 1つはコードに優れ、別は創造的な執筆に、もう1つは分析に優れる
Mixture of Expertsの動作
MoEモデルは、この運用サイクルに従います:
入力分析: クエリを送信すると、Gating Networkがそれを分析し、どのタイプの専門知識が必要かを理解し、言語パターンとコンテンツを調査
エキスパート選択: 分析に基づいて、Gating Networkは、潜在的に利用可能な数百のうち、最も関連性の高いトップ1-3のエキスパートに入力をルーティング
専門化された処理: 選択されたエキスパートのみが活性化し、入力を処理し、それぞれが専門知識を提供しながら、残りは休止状態を保ち、膨大な計算を節約
この動的なルーティングはミリ秒で発生し、Gating Networkは時間とともにどのエキスパートがどのタイプのクエリを最も効果的に処理するかを学習します。
MoE実装のタイプ
MoEアーキテクチャはさまざまなニーズに対応します:
タイプ1:Sparse MoE 最適な用途:大規模な効率的な推論 主な機能:エキスパートの小さなサブセットにルーティング 例:コスト効率のためのGPT-4、Mixtral 8x7B
タイプ2:Dense MoE 最適な用途:最大のパフォーマンス 主な機能:ほとんどまたはすべてのエキスパートを活性化 例:スピードよりも品質を優先する研究モデル
タイプ3:Hierarchical MoE 最適な用途:複雑なマルチドメインタスク 主な機能:複数のレベルでのカスケードエキスパート選択 例:テキスト、ビジョン、オーディオを処理するマルチモーダルシステム
タイプ4:Soft MoE 最適な用途:スムーズなエキスパートブレンディング 主な機能:複数のエキスパートの重み付け結合 例:微妙なドメインミキシングを必要とするシステム
結果を提供するMoE
組織がMoEをどのように活用しているかを以下に示します:
開発者ツールの例: ReplitのGhostwriterは、MoEアーキテクチャを使用して数十のプログラミング言語全体でコード支援を提供し、オンデマンドで言語固有のエキスパートを活性化し、Denseモデルと比較してレスポンスレイテンシを60%削減しています。
カスタマーサポートの例: IntercomのAIエージェントは、MoEを使用して、技術的な問題、請求、製品の質問、一般的な問い合わせのための専門化されたエキスパートに質問をルーティングし、解決精度を35%向上させながら、サーバーあたり3倍の会話を処理しています。
翻訳の例: DeepLは、異なるエキスパートが言語ペアとドメイン(法律、医療、技術)に特化するMoEモデルを採用し、専門コンテンツで単一モデルアプローチより25%優れた翻訳品質を達成しています。
MoEの実装
より少ないリソースでより多くを得る準備はできましたか?
- Large Language Modelsの基礎から始める
- Neural Networksアーキテクチャを理解する
- Model Optimization技術について学ぶ
- ドメイン専門知識のためのFine-Tuningを検討する
よくある質問
Mixture of Expertsに関するよくある質問
Mixture of Experts (MoE)とは何ですか?
Mixture of Expertsは、複数の専門化されたサブネットワーク(エキスパート)を含むNeural Networkアーキテクチャであり、Gatingメカニズムが各入力を最も関連性の高いエキスパートに動的にルーティングし、推論ごとに総容量のほんの一部だけを活性化します。
MoEと従来のNeural Networksの違いは何ですか?
従来のDense Networksは、すべての入力に対してすべてのパラメータを活性化します。MoE Networksは、関連する専門化されたエキスパートのみを活性化し、入力をインテリジェントにルーティングすることで、より少ない計算でより良いパフォーマンスを達成します。
MoE実装の主なタイプは何ですか?
Sparse MoE(効率のために少数のエキスパートを活性化)、Dense MoE(品質のためにほとんどを活性化)、Hierarchical MoE(カスケード選択)、Soft MoE(エキスパートの重み付けブレンディング)です。
MoEモデルの例は何ですか?
GPT-4(OpenAIのフラッグシップモデル)、Mixtral 8x7B(Mistral AIの効率的なモデル)、Switch Transformer(Googleの兆パラメータモデル)、およびエキスパートルーティングを使用するさまざまな専門ドメインモデルです。
関連リソース
Mixture of Expertsの理解を深めるために、これらの関連概念を探索してください:
- Large Language Models - MoEアーキテクチャが強化するシステム
- Neural Networks - Expert Networksの基盤アーキテクチャ
- Model Optimization - 効率的なAI展開のための技術
- Transformer Architecture - MoEと組み合わせられることが多い基本アーキテクチャ
外部リソース
- Google Research - Sparse Expert Models - 効率的なMoEアーキテクチャに関する研究
- Meta AI - Model Efficiency - Sparse ActivationとExpert Routingの進歩
- Microsoft Research - Scalable AI - エンタープライズMoE実装
AI Terms Collectionの一部。最終更新:2026-02-09
