What are Diffusion Models? From Noise to Art in Seconds

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Type "a professional office with natural lighting" and watch as AI creates that exact image in seconds. Behind this magic are diffusion models, the breakthrough technology that revolutionized AI creativity. They don't draw pixels one by one. They start with pure noise and gradually refine it into perfect images.
The Innovation That Launched a Creative Revolution
Diffusion models emerged from Stanford research in 2015, but exploded into mainstream awareness in 2022 when Stable Diffusion, DALL-E 2, and Midjourney demonstrated photorealistic image generation. The technique reversed traditional approaches to image creation.
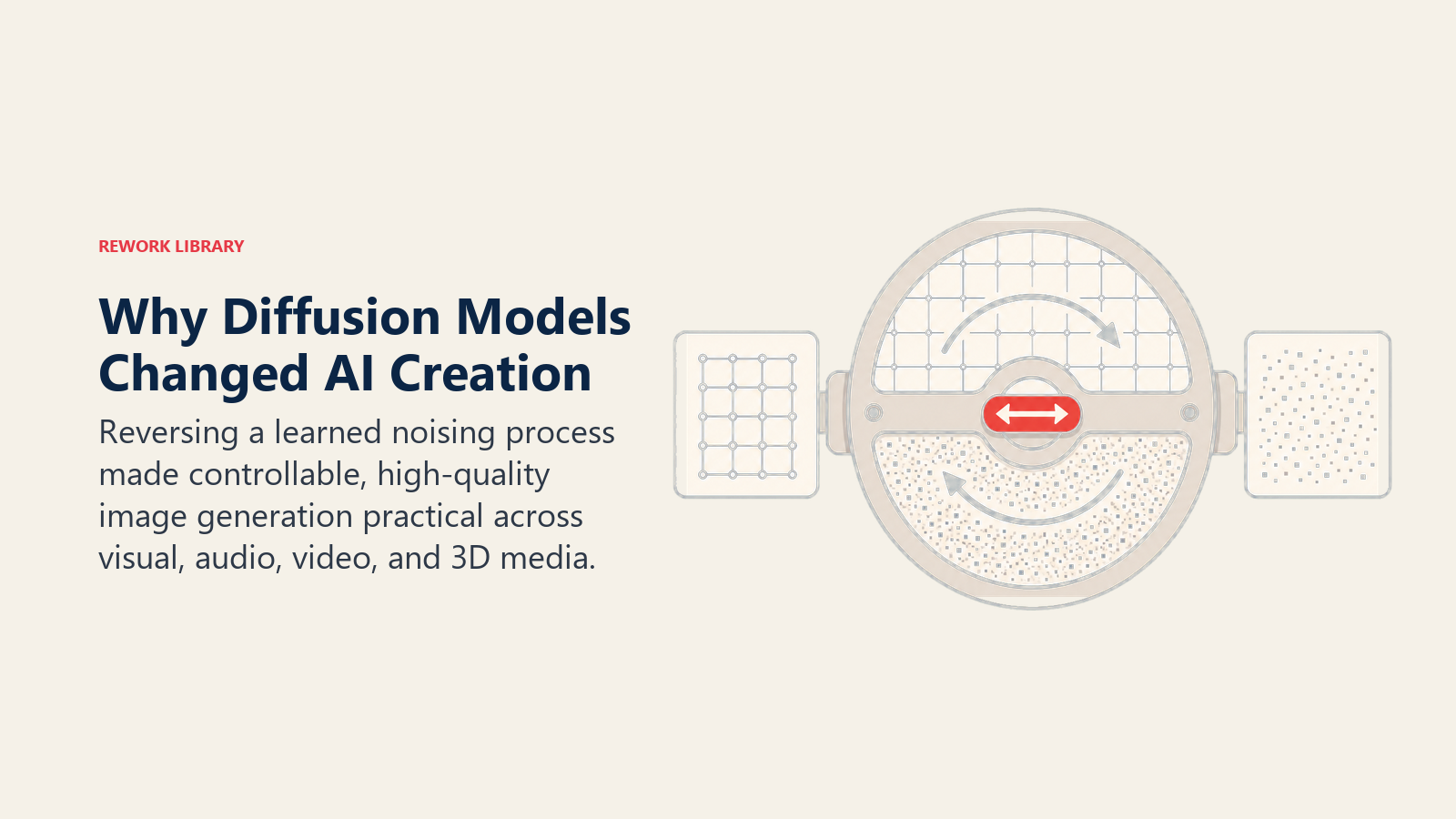
According to OpenAI's research team, diffusion models are "generative models that learn to create images by reversing a gradual noising process, starting from random noise and iteratively refining it into coherent outputs guided by learned patterns from training data."
The breakthrough came when researchers realized that teaching AI to denoise images, to recognize and remove random noise, could be inverted into a powerful image creation tool. This same principle now powers video, audio, and 3D model generation.
Diffusion Models for Business Leaders
For business leaders, diffusion models are AI systems that generate professional-quality images, videos, and designs from text descriptions, enabling instant creative production without photographers, designers, or stock photo subscriptions.
Think of the difference between describing what you want to a designer and having it appear instantly. Diffusion models are like having an infinite creative team that works at the speed of thought, producing exactly what you specify.
In practical terms, diffusion models can create product mockups, marketing visuals, architectural renderings, and design variations in seconds, transforming creative workflows from weeks to minutes. This represents a fundamental shift in how businesses approach generative AI for visual content.
Core Components of Diffusion Models
Diffusion models consist of these essential elements:
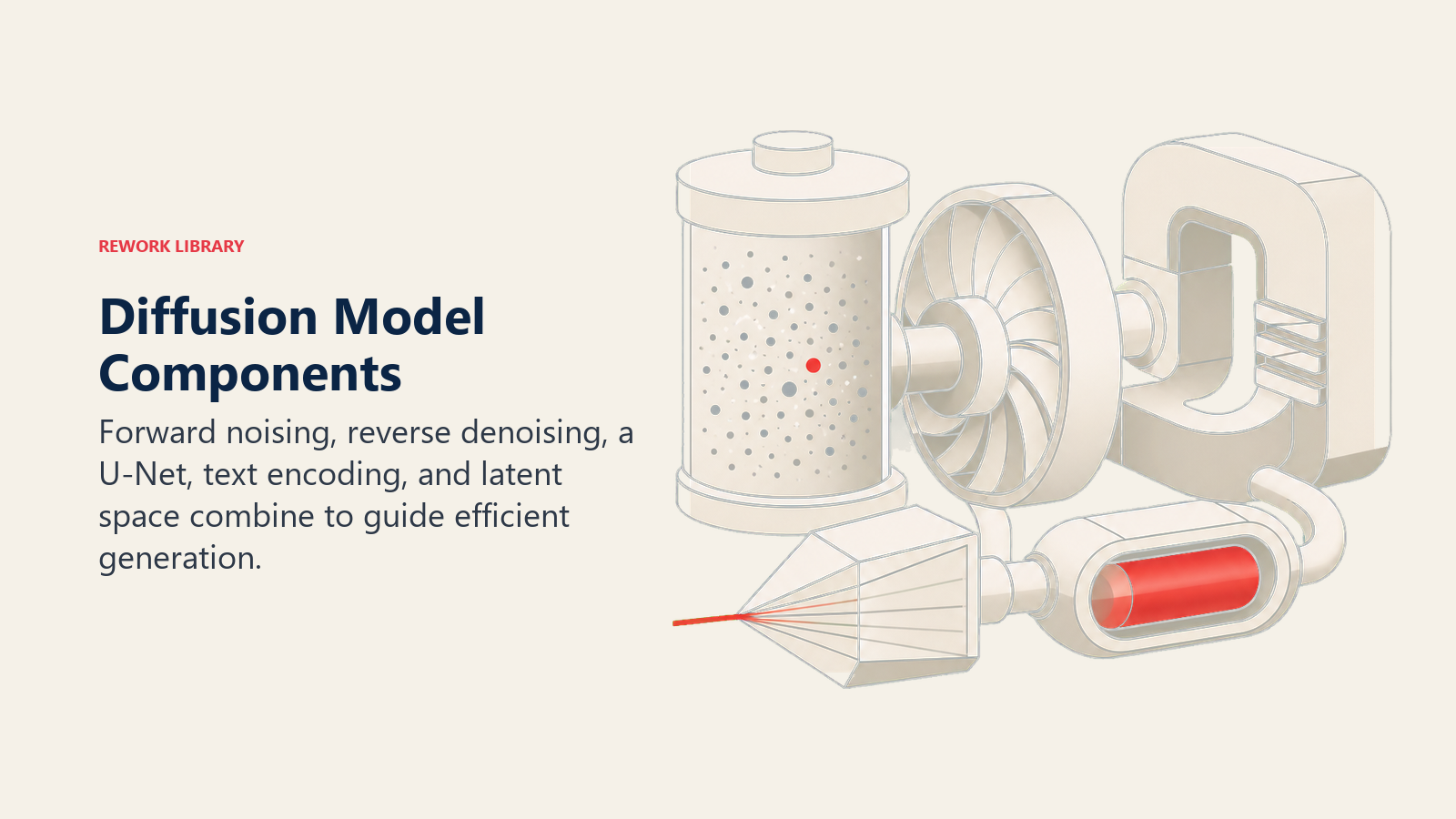
• Forward Process (Noising): Gradually adds random noise to training images over many steps until they become pure static, teaching the model what the destruction of structure looks like
• Reverse Process (Denoising): Learns to reverse the noising process, removing randomness step by step to recover the original image from pure noise
• U-Net Architecture: The neural network that predicts and removes noise at each step, understanding both fine details and broad composition simultaneously
• Text Encoder: Converts your text description into a mathematical representation that guides the denoising process toward your intended image
• Latent Space: Compressed representation where the diffusion process actually happens, making generation faster and more controllable than working with raw pixels
How Diffusion Models Operate
Diffusion models follow this creative process:
Starting Point: Begin with a canvas of pure random noise, like visual static with no structure or meaning whatsoever
Guided Denoising: Over 20-50 steps, the model gradually removes noise while being guided by your text description, slowly revealing structure and detail
Refinement: Each step removes more randomness and adds more coherent details aligned with your prompt, with early steps defining composition and later steps adding fine details
This process happens in seconds, with the model essentially "imagining" what image could exist beneath the noise that matches your description.
Types of Diffusion Models
Diffusion models serve different creative needs:
Type 1: Text-to-Image Models Best for: Creating images from descriptions Key feature: Generate original images from text prompts Example: DALL-E 3, Midjourney, Stable Diffusion
Type 2: Image-to-Image Models Best for: Transforming existing images Key feature: Modify images while preserving structure Example: ControlNet for guided generation
Type 3: Video Diffusion Models Best for: Moving image creation Key feature: Generate coherent video sequences Example: Runway Gen-2, Stable Video Diffusion
Type 4: Specialized Diffusion Models Best for: Domain-specific applications Key feature: Optimized for particular content types Example: Medical imaging, 3D objects, audio generation
Diffusion Models Delivering Results
Here's how businesses leverage diffusion models:
E-commerce Example: Shopify merchants use diffusion models to generate product images in multiple settings and angles, reducing photography costs by 80% while increasing conversion rates 25% through more diverse product visualization.
Marketing Example: Heinz used DALL-E to generate hundreds of ad variations, discovering through rapid iteration that certain visual styles drove 40% higher engagement, testing in days what previously took months.
Architecture Example: Foster + Partners generates dozens of building design variations using diffusion models, accelerating conceptual design by 10x while exploring options that manual rendering made impractical.
Implementing Diffusion Models
Ready to generate your visual content?
- Understand Generative AI fundamentals
- Learn about Neural Networks basics
- Explore Prompt Engineering for better results
- Consider Fine-Tuning for brand-specific styles
Frequently Asked Questions about Diffusion Models
What are Diffusion Models?
Diffusion models are generative AI systems that create images by reversing a gradual noising process, starting from random noise and iteratively refining it into coherent outputs guided by text descriptions or other inputs.
What's the difference between diffusion models and GANs?
GANs (Generative Adversarial Networks) use competing neural networks. Diffusion models use iterative denoising, which produces more diverse outputs, better training stability, and easier control through text prompts.
What are the main types of diffusion models?
Text-to-Image Models (creating from descriptions), Image-to-Image Models (transforming existing images), Video Diffusion Models (generating motion), and Specialized Diffusion Models (domain-specific applications).
What are examples of diffusion model applications?
DALL-E 3 and Midjourney (image generation), Stable Diffusion (open-source image creation), Runway Gen-2 (video generation), and specialized models for medical imaging, 3D models, and audio synthesis.
Related Resources
Explore these related concepts to deepen your understanding of diffusion models:
- Generative AI - The broader category of AI that creates content
- Neural Networks - The foundational architecture behind diffusion models
- Prompt Engineering - Techniques for effective image generation
- Computer Vision - Understanding how AI processes visual information
External Resources
- Stability AI Research - Open-source diffusion model development
- OpenAI DALL-E Documentation - Technical details on image generation
- Hugging Face Diffusers - Practical guide to diffusion models
Part of the AI Terms Collection. Last updated: 2026-02-09

Co-Founder, Rework.com