What is Multimodal AI? One Model for All Your Content
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Imagine an AI that can read your email, analyze the attached spreadsheet, watch the demo video, and respond with insights from all three. No switching between tools. No manual summarization. Just one intelligent system that understands everything you throw at it. That's multimodal AI.
The Unified AI Revolution
Multimodal AI emerged as researchers realized the limitations of single-input systems. Early AI models could process only text or only images. By 2023, breakthrough models like GPT-4V and Google's Gemini changed everything.
According to Google Research, multimodal AI represents "models that can process and reason across multiple types of input data, including text, images, audio, and video, in a single unified architecture, mirroring how humans naturally perceive and understand the world."
The breakthrough came when OpenAI released GPT-4 with vision capabilities in September 2023, followed by Google's Gemini in December 2023 and Anthropic's Claude 3 in March 2024, each demonstrating that AI could finally match human ability to work with mixed media.
Multimodal AI for Business Leaders
For business leaders, multimodal AI is like hiring an expert who can read documents, interpret charts, watch videos, and listen to calls, all at once, then synthesize insights across every format your business produces.
Think of the difference between having separate specialists for text, images, and audio versus one expert who understands all three together. The multimodal expert sees patterns, connections, and insights that specialists working in isolation would miss.
In practical terms, multimodal AI can analyze customer calls (audio), review product images, read support tickets (text), and identify trends across all channels simultaneously. This represents a massive leap beyond traditional large language models that handled only text.
Core Components of Multimodal AI
Multimodal AI systems consist of these essential elements:

• Unified Encoder: Converts different data types, text, images, audio, video, into a common representation that the model can process together, like a universal translator for information formats
• Cross-Modal Attention: Mechanism that allows the model to understand relationships between different types of input, like connecting spoken words in audio to objects in images
• Shared Reasoning Layer: Common processing engine that thinks about all input types together, enabling true synthesis rather than separate analysis
• Modal Adapters: Specialized components that handle the unique characteristics of each input type while feeding into the unified system
• Output Generation: Ability to respond in multiple formats, from text to images to structured data, depending on what best serves the use case
How Multimodal AI Operates
Multimodal AI follows this operational cycle:
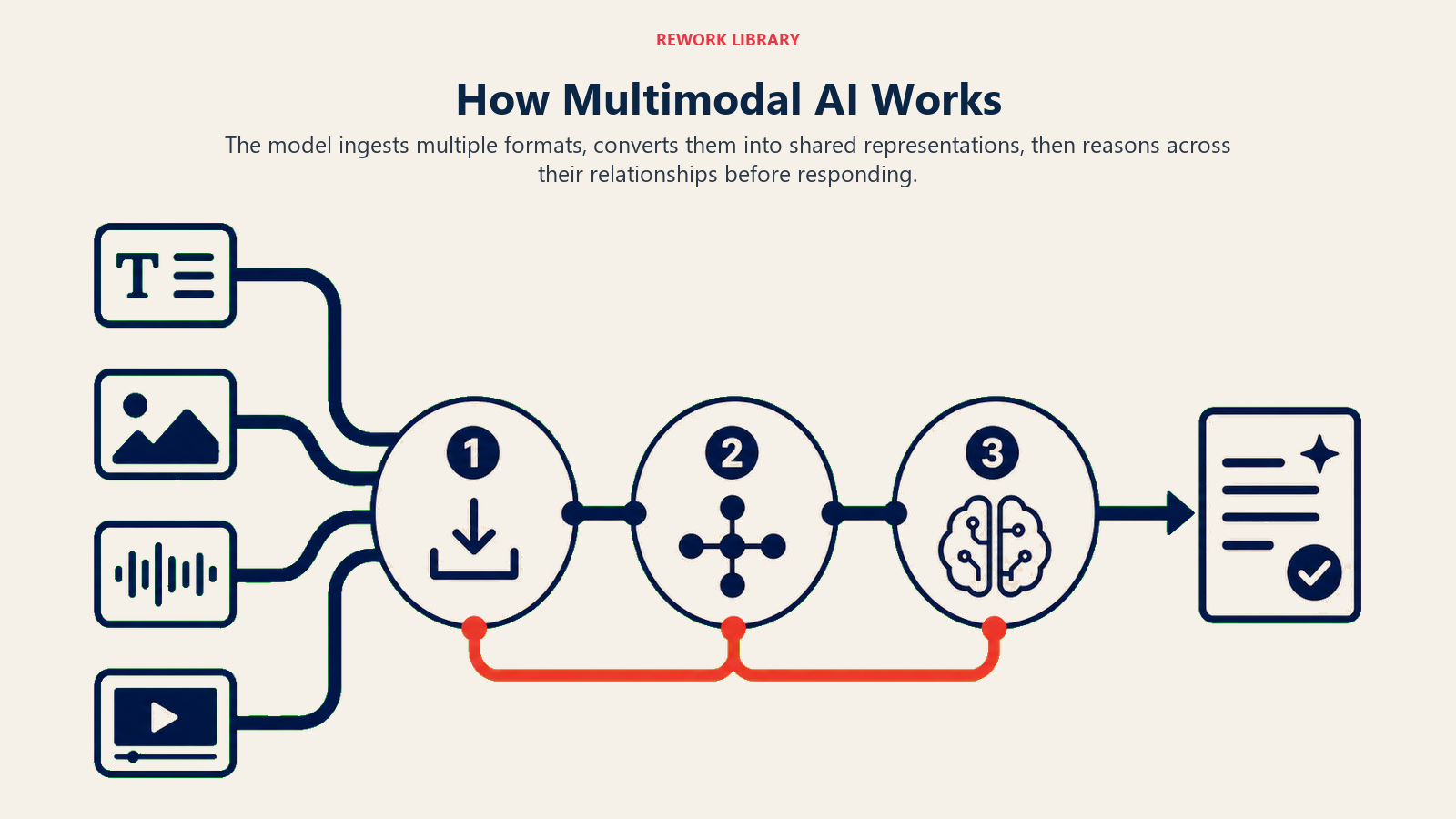
Simultaneous Ingestion: Model receives inputs across multiple formats, say, a product image, customer review text, and demo video, all at once
Unified Processing: Converts all inputs into common internal representations, allowing the model to understand relationships across modalities, like how the image relates to written descriptions
Cross-Modal Reasoning: Analyzes patterns and insights that span multiple types of data, such as noticing that positive audio sentiment correlates with specific visual product features
This cycle continues with the model learning from feedback across all modalities, becoming more skilled at understanding how different types of information connect.
Types of Multimodal AI Systems
Multimodal AI serves different business functions:
Type 1: Vision-Language Models Best for: Document understanding and visual analysis Key feature: Combine text and images seamlessly Example: GPT-4V analyzing charts and reports
Type 2: Audio-Visual Models Best for: Video analysis and meeting intelligence Key feature: Understand speech in context of visual content Example: Automated meeting summaries with speaker identification
Type 3: Text-Image-Audio Systems Best for: Comprehensive content analysis Key feature: Process all major media types together using generative AI Example: Google Gemini handling mixed-format queries
Type 4: Sensor-Fusion Models Best for: IoT and real-world applications Key feature: Combine structured sensor data with media Example: Manufacturing quality control with cameras and measurements
Multimodal AI Delivering Results
Here's how businesses deploy multimodal AI:
Healthcare Example: Siemens Healthineers uses multimodal AI to analyze medical images, lab results, and clinical notes together, reducing diagnostic time by 40% while catching issues that single-modality systems missed.
Retail Example: Amazon's product search now uses multimodal AI to understand queries like "show me shoes like in this photo but in blue," combining image recognition with text understanding to deliver 35% more accurate results.
Financial Services Example: JPMorgan analyzes earnings calls using multimodal AI that processes spoken language, presentation slides, and financial documents simultaneously, identifying investment insights 50% faster than analyst teams.
Implementing Multimodal AI
Ready to unify your AI capabilities?
- Start with Large Language Models fundamentals
- Understand Computer Vision basics
- Learn about Natural Language Processing
- Consider AI Orchestration for complex workflows
Frequently Asked Questions about Multimodal AI
What is Multimodal AI?
Multimodal AI refers to models that can process and reason across multiple types of input data, including text, images, audio, and video, in a single unified architecture, similar to how humans naturally understand the world.
What's the difference between multimodal AI and traditional AI?
Traditional AI models process one type of data (text-only or image-only). Multimodal AI processes multiple data types simultaneously, understanding relationships between them and generating insights across formats.
What are the main types of multimodal AI systems?
Vision-Language Models (text and images), Audio-Visual Models (speech and video), Text-Image-Audio Systems (all major media types), and Sensor-Fusion Models (structured data plus media).
What are examples of multimodal AI models?
GPT-4V (OpenAI), Gemini (Google), Claude 3 (Anthropic), and specialized models like CLIP (image-text), Whisper (audio), and ImageBind (all modalities).
Related Resources
Explore these related concepts to deepen your understanding of multimodal AI:
- Computer Vision - How AI processes and understands images
- Neural Networks - The foundational architecture powering multimodal systems
- Transformer Architecture - The technical foundation behind modern multimodal models
- Embeddings - How different data types are converted to common representations
External Resources
- Google Research - Multimodal AI - Latest advances in unified AI models
- Meta AI - Vision and Language - Research on cross-modal understanding
- Microsoft Research - Multimodal Systems - Enterprise multimodal applications
Part of the AI Terms Collection. Last updated: 2026-02-09
