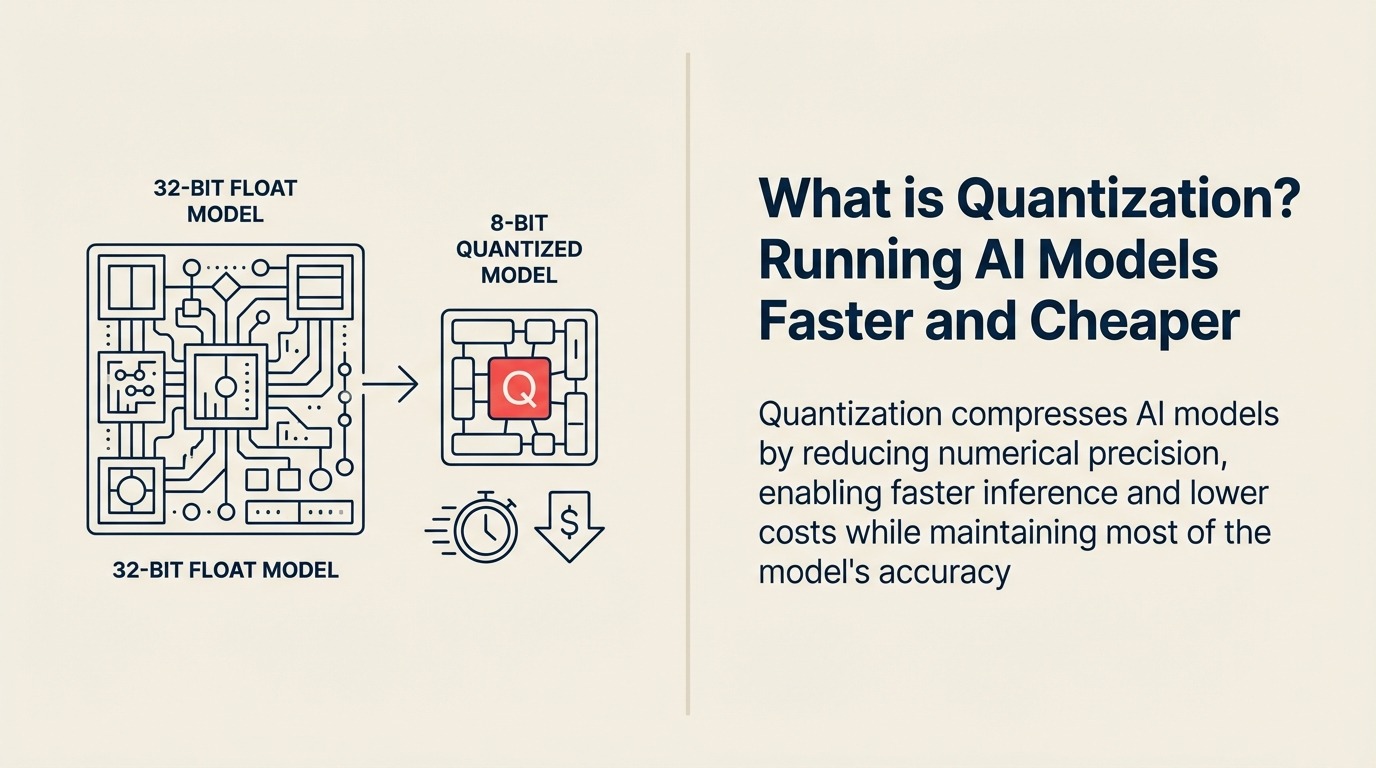
What is Quantization? Making AI Models Lean and Fast
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Running a powerful AI model costs thousands of dollars per hour and requires data center GPUs. But what if you could shrink that same model by 75%, run it on a laptop, and still get 95% of the performance? Quantization has become the secret weapon for deploying large language models at scale, transforming AI from an expensive cloud-only technology into something that runs efficiently on edge devices and consumer hardware.
From Research Luxury to Production Necessity
Quantization emerged as a critical technique around 2017 when researchers realized that AI models trained with high-precision numbers (32-bit floating point) could run effectively with much lower precision (8-bit or even 4-bit integers) after training was complete.
NVIDIA defines quantization as "the process of reducing the number of bits used to represent model weights and activations, decreasing model size and computational requirements while maintaining acceptable accuracy levels for inference tasks."
The field exploded when companies discovered that quantized models could run 4x faster, use 75% less memory, and cost a fraction as much to operate, while delivering nearly identical results for most business applications.
Making Sense for Business Leaders
For business leaders, quantization means running the same AI capabilities at a fraction of the cost and latency, enabling real-time AI on mobile devices, reducing cloud bills by 70%, and deploying powerful models where network connectivity is limited or expensive.
Think of it as the difference between shipping high-resolution RAW images versus compressed JPEGs. Most viewers can't tell the difference, but the JPEG is 10x smaller and loads instantly. Quantization does the same for AI models, compressing them without noticeable quality loss for most use cases.
In practical terms, quantization enables you to run ChatGPT-class models on smartphones, process customer queries in milliseconds instead of seconds, and cut your AI infrastructure costs by 60-80%.
Key Elements of Quantization
Quantization consists of these essential components:
• Precision Reduction: Converting high-precision numbers (32-bit floating point) to lower precision (16-bit, 8-bit, or even 4-bit integers), dramatically reducing memory requirements
• Calibration: Analyzing model weights and activations to determine optimal scaling factors that minimize accuracy loss during conversion
• Hardware Optimization: Leveraging specialized processors that run integer arithmetic much faster than floating-point operations, accelerating inference speed
• Accuracy Preservation: Carefully selecting which layers and operations to quantize to maintain model performance on critical tasks
• Dynamic vs Static: Choosing between quantizing weights only (static) or quantizing activations during runtime (dynamic) based on performance needs
The Quantization Process
Implementing quantization follows these steps:
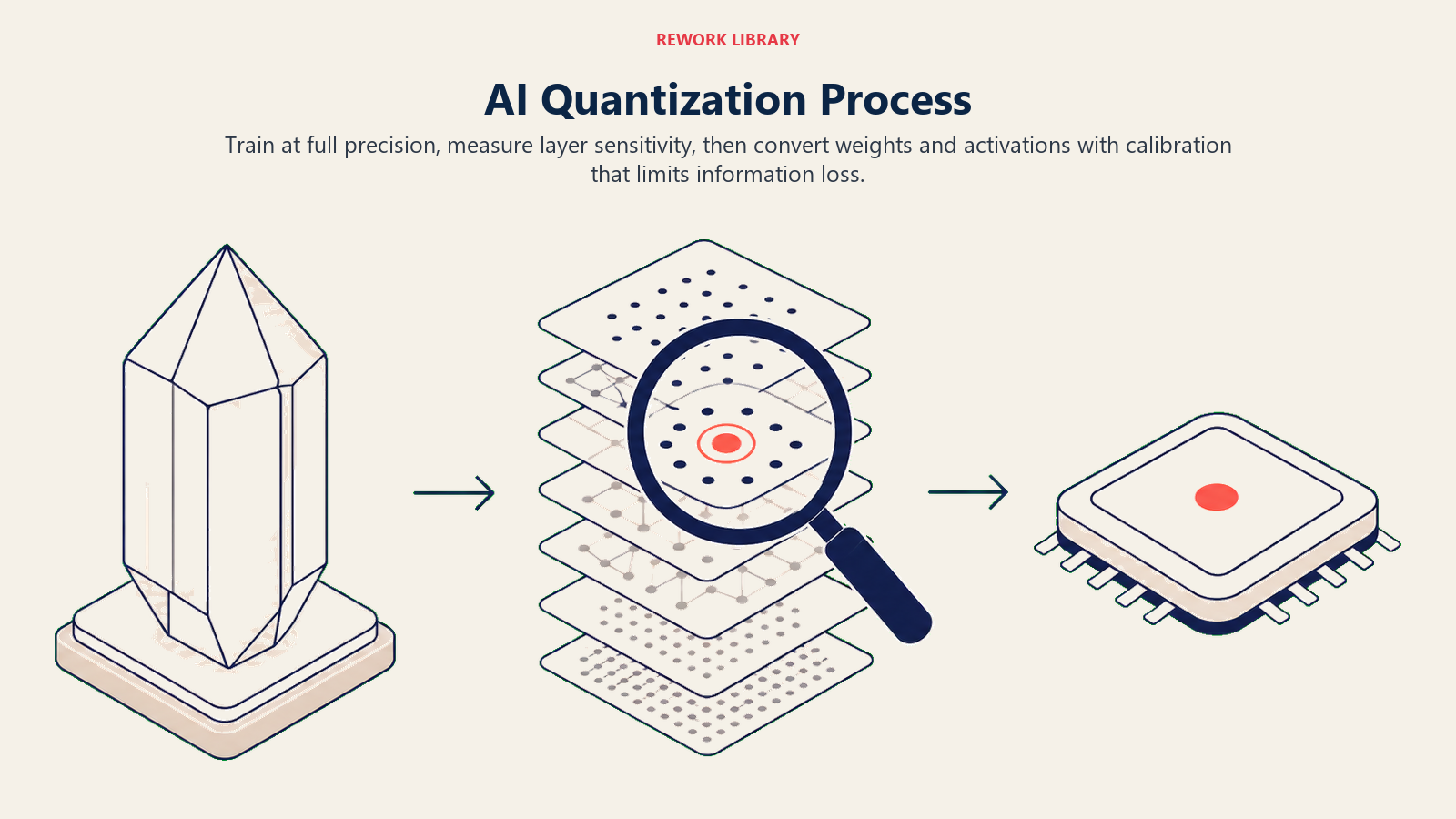
Train Full Precision: Start with a standard model trained using 32-bit floating-point numbers, ensuring the model learns all the patterns and nuances in your data
Analyze Sensitivity: Determine which model layers are most sensitive to precision reduction and which can be aggressively compressed without accuracy loss
Apply Quantization: Convert weights and potentially activations to lower precision, using calibration data to optimize the conversion process and minimize information loss
This transformation takes a 7GB model and compresses it to 2GB while maintaining 95%+ of the original performance.
Types of Quantization
Quantization comes in several approaches:
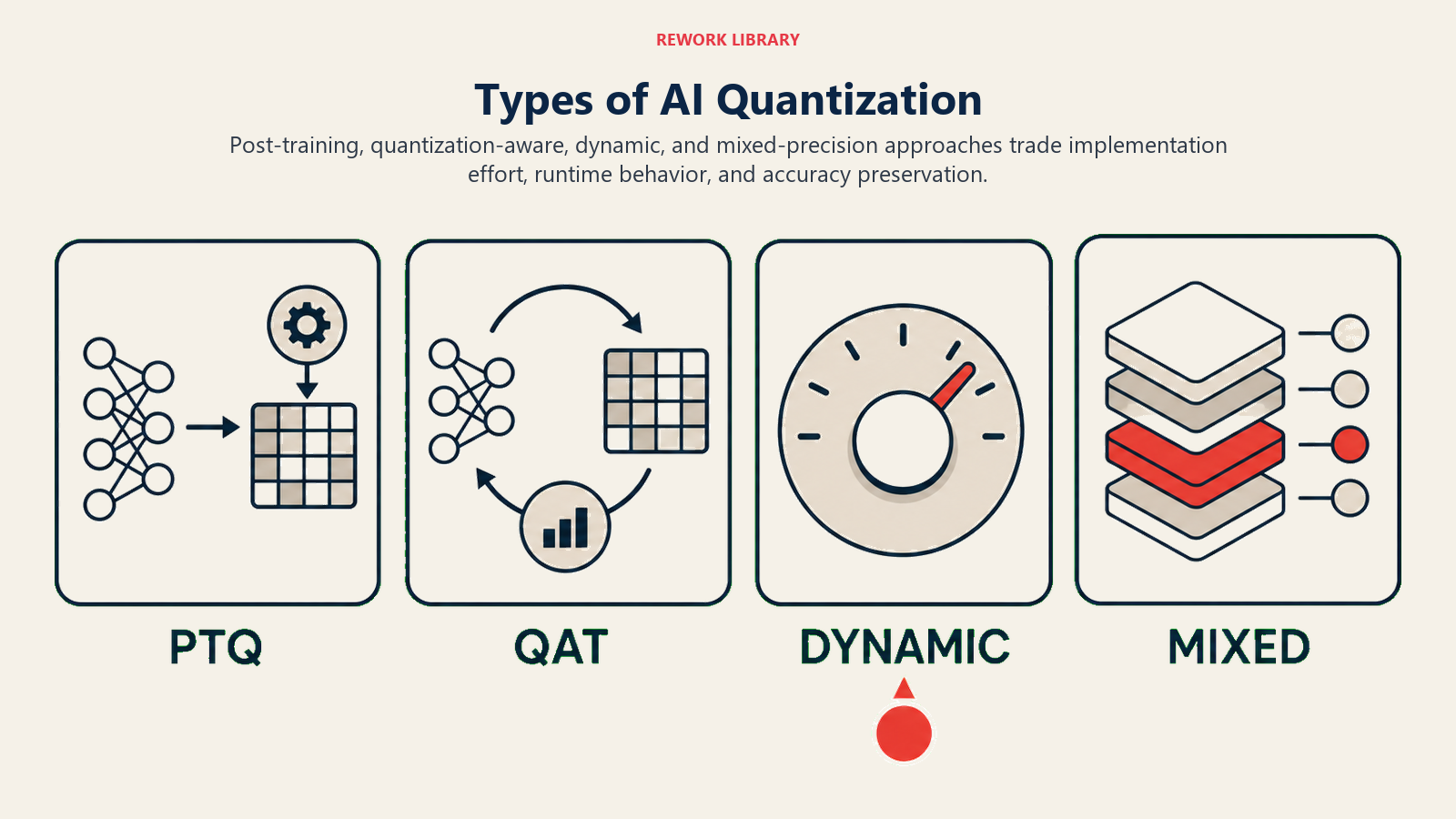
Type 1: Post-Training Quantization (PTQ) Best for: Quick deployment without retraining Key feature: Quantize after training is complete Example: Converting a pre-trained GPT model to 8-bit for faster inference
Type 2: Quantization-Aware Training (QAT) Best for: Maximum accuracy preservation Key feature: Model learns during training to be quantization-friendly Example: Training a vision model that anticipates 4-bit deployment
Type 3: Dynamic Quantization Best for: Models with varying input sizes Key feature: Weights quantized, activations converted at runtime Example: Language models that process different text lengths
Type 4: Mixed-Precision Quantization Best for: Balancing speed and accuracy Key feature: Different precision levels for different layers Example: 4-bit for most layers, 8-bit for attention heads
Quantization in Action
Here's how businesses actually use quantization:
Mobile AI Example: Meta's Llama 2 models quantized to 4-bit precision run on iPhone and Android devices, enabling on-device AI assistants without sending data to the cloud. Response times dropped from 2 seconds to 200 milliseconds.
Cloud Cost Reduction Example: Anthropic quantized Claude models for certain use cases, reducing inference costs by 70% while maintaining 96% of original quality scores. This enabled lower pricing for API customers.
Edge Computing Example: Tesla uses quantized neural networks for autonomous driving, running complex vision models on car hardware at 36 frames per second, impossible with full-precision models.
Your Path to Quantization Mastery
Ready to make your AI models lean and fast?
- Understand model optimization with Inference Optimization
- Explore smaller models via Knowledge Distillation
- Learn about efficient training with Transfer Learning
External Resources
Explore authoritative research and documentation on quantization:
- NVIDIA Deep Learning Inference Guide - Comprehensive documentation on quantization techniques and optimization
- Hugging Face Quantization Guide - Practical implementation guides and tools for model quantization
- PyTorch Quantization Documentation - Technical reference for quantization frameworks and methods
Learn More
Expand your understanding of related AI concepts:
- Model Compression - Other techniques for reducing model size
- Edge AI - Running AI on devices instead of cloud
- Inference - Understanding AI prediction process
- Neural Architecture Search - Designing efficient model structures
Frequently Asked Questions about Quantization
What is Quantization in AI?
Quantization is the process of reducing the numerical precision of AI model weights and activations, converting them from high-precision formats (32-bit float) to lower-precision formats (8-bit or 4-bit integers) to reduce model size and increase inference speed.
Does quantization hurt model accuracy?
Properly implemented quantization typically maintains 95-99% of original accuracy. The key is calibration and choosing appropriate precision levels for different model components.
What's the difference between 8-bit and 4-bit quantization?
8-bit quantization provides a good balance of compression (4x smaller) and accuracy preservation. 4-bit quantization offers extreme compression (8x smaller) but requires more careful implementation to maintain acceptable accuracy.
When should I use quantization?
Quantization is valuable when deploying models to edge devices with limited resources, reducing cloud inference costs, achieving lower latency requirements, or running models in bandwidth-constrained environments.
Can all AI models be quantized?
Most neural networks can be quantized effectively. Large language models, computer vision models, and recommendation systems all benefit from quantization. Some specialized models or tasks requiring extreme precision may need careful validation.
Part of the AI Terms Collection. Last updated: 2026-02-09
