Was ist Mixture of Experts? Die KI, die nur aktiviert, was sie braucht
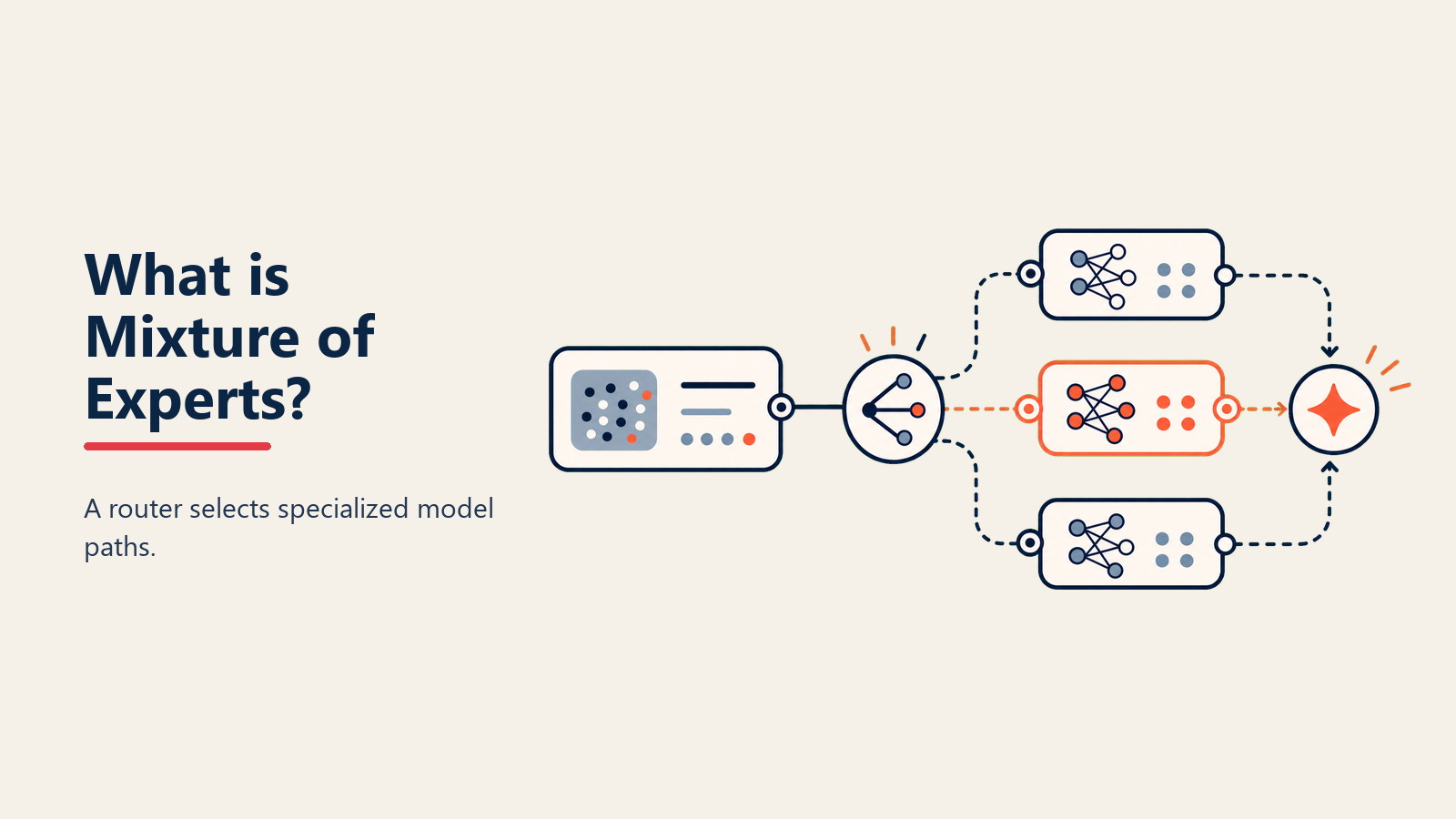 Stellen Sie sich vor, Ihr Gehirn würde für jeden Gedanken jedes Neuron aktivieren – E-Mails zu lesen würde genauso viel Energie verbrauchen wie Kalküllösungen. Stattdessen aktiviert Ihr Gehirn nur die Regionen, die es benötigt. Mixture of Experts bringt diese Effizienz zur KI und nutzt spezialisierte Sub-Modelle, die nur dann aktivieren, wenn ihr Fachwissen erforderlich ist.
Stellen Sie sich vor, Ihr Gehirn würde für jeden Gedanken jedes Neuron aktivieren – E-Mails zu lesen würde genauso viel Energie verbrauchen wie Kalküllösungen. Stattdessen aktiviert Ihr Gehirn nur die Regionen, die es benötigt. Mixture of Experts bringt diese Effizienz zur KI und nutzt spezialisierte Sub-Modelle, die nur dann aktivieren, wenn ihr Fachwissen erforderlich ist.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die Architektur, die die KI-Ökonomie veränderte
Mixture of Experts entstand aus akademischer Forschung in den 1990er Jahren, wurde aber 2024 praktisch wichtig, als OpenAI enthüllte, dass GPT-4 MoE-Architektur nutzt. Der Durchbruch demonstrierte, dass größer nicht immer besser ist – intelligenteres Routing schlägt rohe Gewalt.
Laut Google Research ist MoE "eine neuronale Netzwerkarchitektur, die mehrere spezialisierte Sub-Netzwerke (Experten) enthält, wobei ein Gating-Mechanismus jeden Input dynamisch an die relevantesten Experten weiterleitet und nur einen Bruchteil der gesamten Modellkapazität für eine einzelne Inferenz aktiviert."
Der Game-Changer kam, als Mistral AI im Dezember 2023 Mixtral 8x7B veröffentlichte und zeigte, dass ein MoE-Modell die Leistung viel größerer Modelle erreichen konnte, während es 5x weniger Rechenleistung nutzte, was leistungsstarke KI für kleinere Organisationen zugänglich machte.
Mixture of Experts für Business-Leader
Für Business-Leader bedeutet MoE, GPT-4-Level-Leistung zu einem Bruchteil der Kosten und Geschwindigkeit zu erhalten, da die KI intelligent nur die spezialisierten Komponenten aktiviert, die für jede Anfrage benötigt werden, anstatt das gesamte massive Modell auszuführen.
Denken Sie an den Unterschied zwischen der Konsultation jeder Abteilung für jede Frage versus dem Weiterleiten von Fragen an die richtigen Spezialisten. MoE ist wie ein brillanter Koordinator zu haben, der sofort weiß, welchen Experten er aktivieren muss, und die Verschwendung vermeidet, alle einzubeziehen.
Praktisch liefern MoE-Modelle schnellere Antworten, niedrigere Infrastrukturkosten und bessere Leistung pro Dollar als traditionelle Dense Models, wodurch anspruchsvolle Large Language Models für mehr Use Cases wirtschaftlich machbar werden.
Kernkomponenten von Mixture of Experts
MoE-Systeme bestehen aus diesen wesentlichen Elementen:
• Expert Networks: Mehrere spezialisierte Sub-Modelle, jedes exzellierend bei bestimmten Arten von Inputs oder Aufgaben, wie Abteilungen zu haben, die jeweils verschiedene Domänen meistern
• Gating Network: Das Routing-System, das entscheidet, welche Experten für jeden Input zu aktivieren sind, die Anfrage analysiert und die relevantesten Spezialisten auswählt
• Sparse Activation: Nur 1-3 Experten aktivieren pro Input anstatt aller, was die Berechnung dramatisch reduziert, während Qualität durch intelligente Auswahl erhalten bleibt
• Load Balancing: Mechanismen, die sicherstellen, dass Experten über die Zeit ungefähr gleichmäßig genutzt werden, verhindernd, dass einige überlastet werden, während andere untätig bleiben
• Expertenspezialisierung: Durch Training entwickeln verschiedene Experten natürlich Fokus auf verschiedene Muster – einer könnte bei Code exzellieren, ein anderer bei kreativem Schreiben, ein anderer bei Analyse
Wie Mixture of Experts funktioniert
MoE-Modelle folgen diesem Operationszyklus:
Input-Analyse: Wenn Sie eine Anfrage einreichen, analysiert das Gating Network sie, um zu verstehen, welche Art von Expertise benötigt wird, untersucht linguistische Muster und Inhalte
Expertenauswahl: Basierend auf der Analyse leitet das Gating Network Ihren Input an die Top-1-3 relevantesten Experten aus potenziell Hunderten verfügbaren
Spezialisierte Verarbeitung: Nur die ausgewählten Experten aktivieren und verarbeiten Ihren Input, jeder trägt sein spezialisiertes Wissen bei, während der Rest inaktiv bleibt und massive Berechnung spart
Dieses dynamische Routing geschieht in Millisekunden, wobei das Gating Network über die Zeit lernt, welche Experten welche Arten von Anfragen am effektivsten bearbeiten.
Typen von MoE-Implementierungen
MoE-Architekturen dienen unterschiedlichen Bedürfnissen:
Typ 1: Sparse MoE Am besten für: Effiziente Inferenz im Maßstab Hauptmerkmal: Leitet zu kleiner Teilmenge von Experten Beispiel: GPT-4, Mixtral 8x7B für Kosteneffizienz
Typ 2: Dense MoE Am besten für: Maximale Leistung Hauptmerkmal: Aktiviert die meisten oder alle Experten Beispiel: Forschungsmodelle, die Qualität über Geschwindigkeit priorisieren
Typ 3: Hierarchical MoE Am besten für: Komplexe Multi-Domain-Aufgaben Hauptmerkmal: Kaskadierende Expertenauswahl auf mehreren Ebenen Beispiel: Multi-modale Systeme, die Text, Vision, Audio handhaben
Typ 4: Soft MoE Am besten für: Sanfte Expertenmischung Hauptmerkmal: Gewichtete Kombination mehrerer Experten Beispiel: Systeme, die nuancierte Domain-Mischung erfordern
MoE liefert Ergebnisse
So nutzen Organisationen MoE:
Developer-Tools-Beispiel: Replits Ghostwriter nutzt MoE-Architektur, um Code-Assistenz über Dutzende Programmiersprachen bereitzustellen, aktiviert sprachspezifische Experten on-demand und reduziert Response-Latenz um 60% im Vergleich zu Dense Models.
Kundensupport-Beispiel: Intercoms AI-Agent nutzt MoE, um Fragen an spezialisierte Experten für technische Probleme, Abrechnung, Produktfragen und allgemeine Anfragen weiterzuleiten, verbessert Lösungsgenauigkeit um 35%, während 3x mehr Konversationen pro Server bearbeitet werden.
Übersetzungsbeispiel: DeepL setzt MoE-Modelle ein, bei denen verschiedene Experten sich auf Sprachpaare und Domänen (Recht, Medizin, Technik) spezialisieren und 25% bessere Übersetzungsqualität als Single-Model-Ansätze in spezialisierten Inhalten erzielen.
MoE implementieren
Bereit, mehr aus weniger zu machen?
- Beginnen Sie mit Large Language Models-Grundlagen
- Verstehen Sie Neural Networks-Architektur
- Lernen Sie über Model Optimization-Techniken
- Erwägen Sie Fine-Tuning für Domain-Expertise
FAQ-Bereich
Häufig gestellte Fragen zu Mixture of Experts
Was ist Mixture of Experts (MoE)?
Mixture of Experts ist eine neuronale Netzwerkarchitektur, die mehrere spezialisierte Sub-Netzwerke (Experten) enthält, wobei ein Gating-Mechanismus jeden Input dynamisch an die relevantesten Experten weiterleitet und nur einen Bruchteil der Gesamtkapazität pro Inferenz aktiviert.
Was ist der Unterschied zwischen MoE und traditionellen neuronalen Netzwerken?
Traditionelle Dense Networks aktivieren alle Parameter für jeden Input. MoE-Netzwerke aktivieren nur relevante spezialisierte Experten und erreichen bessere Leistung mit weniger Berechnung durch intelligentes Routing von Inputs.
Was sind die Haupttypen von MoE-Implementierungen?
Sparse MoE (aktiviert wenige Experten für Effizienz), Dense MoE (aktiviert die meisten für Qualität), Hierarchical MoE (kaskadierende Auswahl) und Soft MoE (gewichtete Mischung von Experten).
Was sind Beispiele für MoE-Modelle?
GPT-4 (OpenAIs Flaggschiff-Modell), Mixtral 8x7B (Mistral AIs effizientes Modell), Switch Transformer (Googles Billion-Parameter-Modell) und verschiedene spezialisierte Domain-Modelle mit Experten-Routing.
Verwandte Ressourcen
Erkunden Sie diese verwandten Konzepte, um Ihr Verständnis von Mixture of Experts zu vertiefen:
- Large Language Models - Die Systeme, die MoE-Architekturen verbessern
- Neural Networks - Die grundlegende Architektur für Experten-Netzwerke
- Model Optimization - Techniken für effizientes KI-Deployment
- Transformer Architecture - Die Basis-Architektur, die oft mit MoE kombiniert wird
Externe Ressourcen
- Google Research - Sparse Expert Models - Forschung zu effizienten MoE-Architekturen
- Meta AI - Model Efficiency - Fortschritte in Sparse Activation und Experten-Routing
- Microsoft Research - Scalable AI - Enterprise-MoE-Implementierungen
Teil der AI Terms Collection. Zuletzt aktualisiert: 2026-02-09

Co-Founder, Rework.com