O que é Mixture of Experts? A AI Que Ativa Apenas O Que Precisa
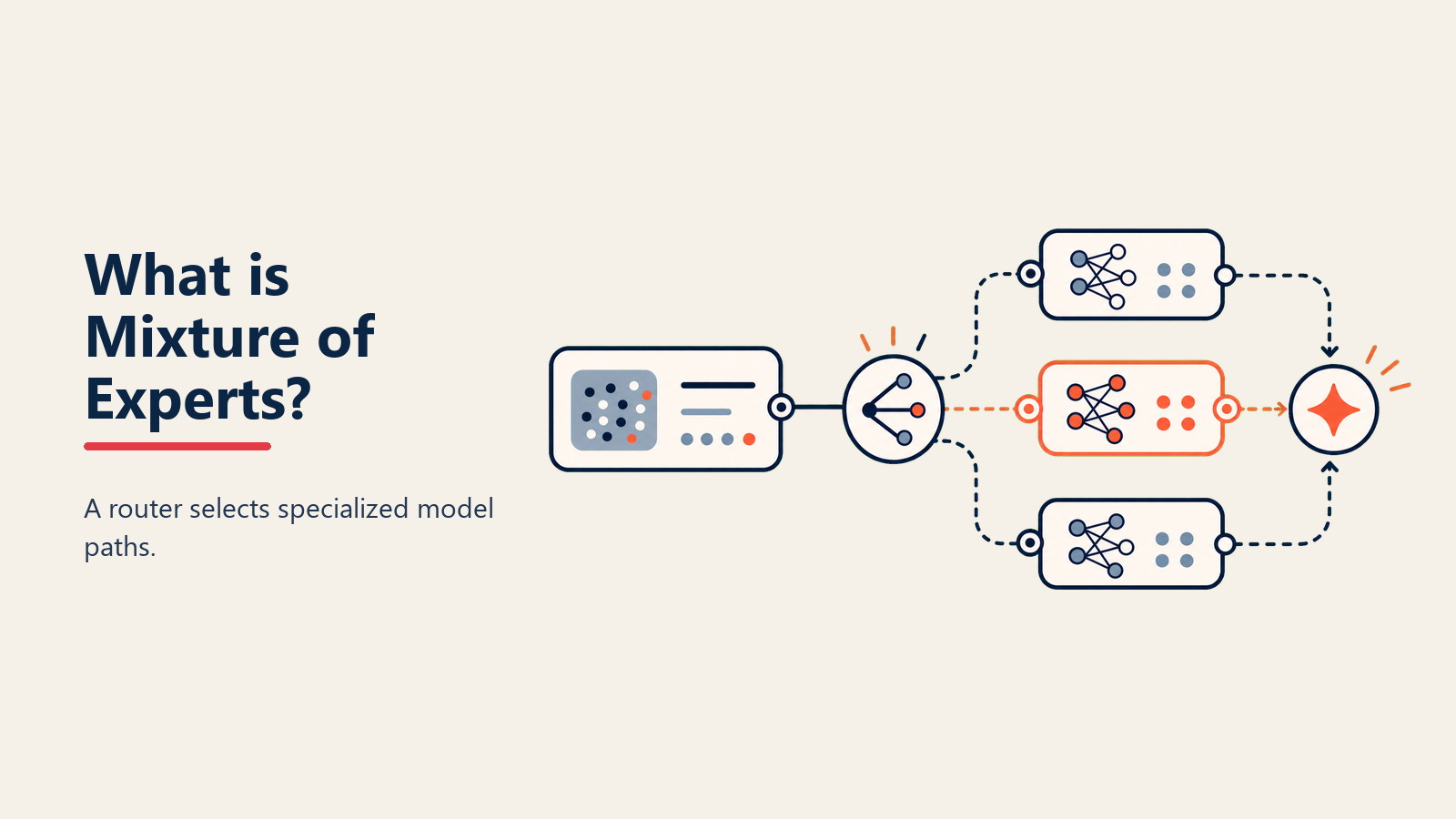 Imagine se seu cérebro ativasse cada neurônio para cada pensamento—ler email consumiria tanta energia quanto resolver cálculo. Em vez disso, seu cérebro ativa apenas as regiões que precisa. Mixture of Experts (MoE) traz essa eficiência para AI, usando sub-modelos especializados que ativam apenas quando sua expertise é necessária.
Imagine se seu cérebro ativasse cada neurônio para cada pensamento—ler email consumiria tanta energia quanto resolver cálculo. Em vez disso, seu cérebro ativa apenas as regiões que precisa. Mixture of Experts (MoE) traz essa eficiência para AI, usando sub-modelos especializados que ativam apenas quando sua expertise é necessária.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A Arquitetura Que Mudou a Economia de AI
Mixture of Experts emergiu da pesquisa acadêmica nos anos 1990, mas se tornou praticamente importante em 2024 quando a OpenAI revelou que GPT-4 usa arquitetura MoE. O avanço demonstrou que maior nem sempre é melhor—roteamento inteligente supera força bruta.
Segundo Google Research, MoE é "uma arquitetura de rede neural que contém múltiplas sub-redes especializadas (experts), onde um mecanismo de gateamento roteia dinamicamente cada entrada para os experts mais relevantes, ativando apenas uma fração da capacidade total do modelo para qualquer inferência única."
O grande avanço veio quando Mistral AI lançou Mixtral 8x7B em dezembro de 2023, mostrando que um modelo MoE poderia igualar o desempenho de modelos muito maiores usando 5x menos computação, tornando AI poderosa acessível a organizações menores.
Mixture of Experts para Líderes Empresariais
Para líderes empresariais, MoE significa obter desempenho nível GPT-4 a uma fração do custo e velocidade, pois a AI ativa inteligentemente apenas os componentes especializados necessários para cada consulta em vez de executar todo o modelo massivo.
Pense na diferença entre consultar cada departamento para cada pergunta versus rotear perguntas aos especialistas certos. MoE é como ter um coordenador brilhante que sabe instantaneamente qual expert ativar, evitando o desperdício de engajar todos.
Em termos práticos, modelos MoE entregam respostas mais rápidas, custos de infraestrutura menores e melhor desempenho por dólar que modelos densos tradicionais, tornando modelos de linguagem grandes sofisticados economicamente viáveis para mais casos de uso.
Componentes Centrais de Mixture of Experts
Sistemas MoE consistem destes elementos essenciais:
• Expert Networks: Múltiplos sub-modelos especializados, cada um excelente em tipos particulares de entradas ou tarefas, como ter departamentos que cada um domina domínios diferentes
• Gating Network: O sistema de roteamento que decide quais experts ativar para cada entrada, analisando a consulta e selecionando os especialistas mais relevantes
• Sparse Activation: Apenas 1-3 experts ativam por entrada em vez de todos, reduzindo drasticamente computação enquanto mantém qualidade através de seleção inteligente
• Load Balancing: Mecanismos garantindo que experts sejam usados aproximadamente igualmente ao longo do tempo, prevenindo que alguns fiquem sobrecarregados enquanto outros ficam ociosos
• Expert Specialization: Através de treinamento, diferentes experts naturalmente desenvolvem foco em padrões diferentes—um pode se destacar em código, outro em escrita criativa, outro em análise
Como Mixture of Experts Opera
Modelos MoE seguem este ciclo operacional:
Análise de Entrada: Quando você submete uma consulta, a gating network a analisa para entender que tipo de expertise é necessária, examinando padrões linguísticos e conteúdo
Seleção de Expert: Baseado na análise, a gating network roteia sua entrada para os top 1-3 experts mais relevantes dentre potencialmente centenas disponíveis
Processamento Especializado: Apenas os experts selecionados ativam e processam sua entrada, cada um contribuindo seu conhecimento especializado enquanto o resto permanece dormente, economizando computação massiva
Esse roteamento dinâmico acontece em milissegundos, com a gating network aprendendo ao longo do tempo quais experts lidam com quais tipos de consultas mais efetivamente.
Tipos de Implementações MoE
Arquiteturas MoE servem necessidades diferentes:
Tipo 1: Sparse MoE Melhor para: Inferência eficiente em escala Característica-chave: Roteia para pequeno subconjunto de experts Exemplo: GPT-4, Mixtral 8x7B para eficiência de custo
Tipo 2: Dense MoE Melhor para: Desempenho máximo Característica-chave: Ativa maioria ou todos os experts Exemplo: Modelos de pesquisa priorizando qualidade sobre velocidade
Tipo 3: Hierarchical MoE Melhor para: Tarefas complexas multi-domínio Característica-chave: Seleção de expert em cascata em múltiplos níveis Exemplo: Sistemas multi-modais lidando com texto, visão, áudio
Tipo 4: Soft MoE Melhor para: Mistura suave de experts Característica-chave: Combinação ponderada de múltiplos experts Exemplo: Sistemas requerendo mistura sutil de domínios
MoE Entregando Resultados
Veja como organizações aproveitam MoE:
Exemplo Ferramentas de Desenvolvedor: Ghostwriter da Replit usa arquitetura MoE para fornecer assistência de código através de dezenas de linguagens de programação, ativando experts específicos de linguagem sob demanda e reduzindo latência de resposta em 60% comparado a modelos densos.
Exemplo Suporte ao Cliente: Agente AI da Intercom usa MoE para rotear perguntas a experts especializados para questões técnicas, cobrança, dúvidas sobre produtos e consultas gerais, melhorando acurácia de resolução em 35% enquanto lida com 3x mais conversas por servidor.
Exemplo Tradução: DeepL emprega modelos MoE onde diferentes experts se especializam em pares de idiomas e domínios (jurídico, médico, técnico), alcançando 25% melhor qualidade de tradução que abordagens de modelo único em conteúdo especializado.
Implementando MoE
Pronto para obter mais com menos?
- Comece com fundamentos de Large Language Models
- Entenda arquitetura de Neural Networks
- Aprenda sobre técnicas de Model Optimization
- Considere Fine-Tuning para expertise de domínio
Seção de FAQ
Perguntas Frequentes sobre Mixture of Experts
O que é Mixture of Experts (MoE)?
Mixture of Experts é uma arquitetura de rede neural contendo múltiplas sub-redes especializadas (experts), onde um mecanismo de gateamento roteia dinamicamente cada entrada para os experts mais relevantes, ativando apenas uma fração da capacidade total por inferência.
Qual a diferença entre MoE e redes neurais tradicionais?
Redes densas tradicionais ativam todos os parâmetros para cada entrada. Redes MoE ativam apenas experts especializados relevantes, alcançando melhor desempenho com menos computação através de roteamento inteligente de entradas.
Quais são os principais tipos de implementações MoE?
Sparse MoE (ativa poucos experts para eficiência), Dense MoE (ativa maioria para qualidade), Hierarchical MoE (seleção em cascata) e Soft MoE (mistura ponderada de experts).
Quais são exemplos de modelos MoE?
GPT-4 (modelo flagship da OpenAI), Mixtral 8x7B (modelo eficiente da Mistral AI), Switch Transformer (modelo de trilhão de parâmetros do Google) e vários modelos de domínio especializados usando roteamento de experts.
Recursos Relacionados
Explore esses conceitos relacionados para aprofundar seu entendimento de Mixture of Experts:
- Large Language Models - Os sistemas que arquiteturas MoE aprimoram
- Neural Networks - A arquitetura fundacional para redes de experts
- Model Optimization - Técnicas para implantação eficiente de AI
- Transformer Architecture - A arquitetura base frequentemente combinada com MoE
Recursos Externos
- Google Research - Sparse Expert Models - Pesquisa em arquiteturas MoE eficientes
- Meta AI - Model Efficiency - Avanços em ativação esparsa e roteamento de experts
- Microsoft Research - Scalable AI - Implementações MoE enterprise
Parte da Coleção de Termos de AI. Última atualização: 2026-02-09

Co-Founder, Rework.com