What is RLHF? Teaching AI What Humans Actually Want

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ChatGPT didn't become helpful by accident. Behind its polite, useful responses is a training technique that makes AI care about what humans actually want, not just what's technically correct. That technique is RLHF, and it's the reason modern AI feels so different from earlier versions.
The Breakthrough That Changed AI
Reinforcement Learning from Human Feedback emerged from OpenAI research in 2017, but exploded into mainstream awareness when it powered ChatGPT in 2022. The technique solved a critical problem: how to make AI not just smart, but genuinely helpful.
According to OpenAI's research, RLHF is "a machine learning technique that trains AI models to behave according to human preferences by learning from comparative feedback, optimizing for responses that humans actually find useful rather than just statistically probable."
The game-changer came when researchers realized that predicting the next word (traditional language model training) doesn't naturally lead to helpful behavior. You need to explicitly teach AI what humans consider good responses, and RLHF provided the missing piece.
RLHF for Business Leaders
For business leaders, RLHF is the training process that transforms raw AI into a useful business tool, teaching it to be helpful, harmless, and honest rather than just technically accurate or statistically likely.
Think of the difference between an intern who answers questions literally versus one who understands what you really need. RLHF is like having thousands of expert trainers give feedback on every response until the AI learns not just what's correct, but what's actually useful.
In practical terms, RLHF is why AI can now decline inappropriate requests, explain complex topics clearly, and admit when it doesn't know something. This represents a fundamental evolution beyond traditional machine learning approaches that optimize for accuracy alone.
Core Components of RLHF
RLHF consists of these essential elements:

• Supervised Fine-Tuning (SFT): Initial training phase where humans demonstrate ideal responses to various prompts, giving the AI examples of high-quality outputs to learn from
• Reward Modeling: Humans compare multiple AI responses and indicate which is better, training a separate model to predict human preferences automatically
• Reinforcement Learning: The AI practices generating responses and receives "rewards" based on the preference model, gradually learning to produce outputs humans prefer
• Human Evaluators: Teams of reviewers who provide the comparative feedback that drives the entire process, often with detailed guidelines on helpfulness, safety, and accuracy
• Iterative Refinement: Continuous cycles of feedback and training that progressively align the model with human values and expectations
How RLHF Works
The RLHF process follows these steps:
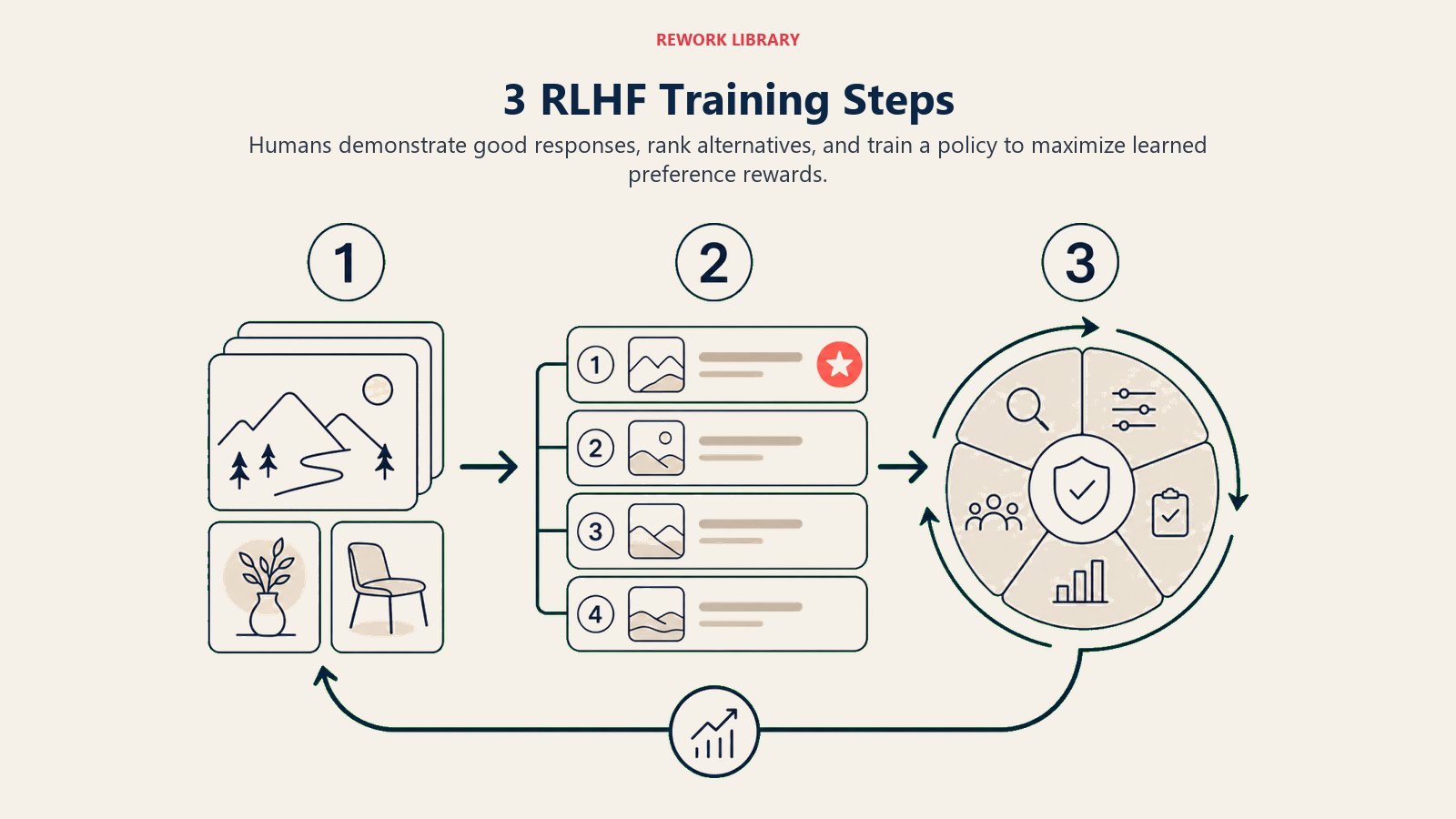
Demonstration Collection: Human trainers write example conversations showing how the AI should respond to various queries, creating a foundation of helpful behavior
Preference Learning: The AI generates multiple responses to prompts, and humans rank them from best to worst, teaching the system to distinguish good from poor outputs
Policy Optimization: The AI learns a policy, a strategy for generating responses, that maximizes expected human approval based on the learned preferences, using reinforcement learning algorithms
This cycle repeats thousands of times, with the AI gradually internalizing what makes responses helpful, safe, and aligned with human intentions.
RLHF Implementation Patterns
RLHF systems come in several varieties:
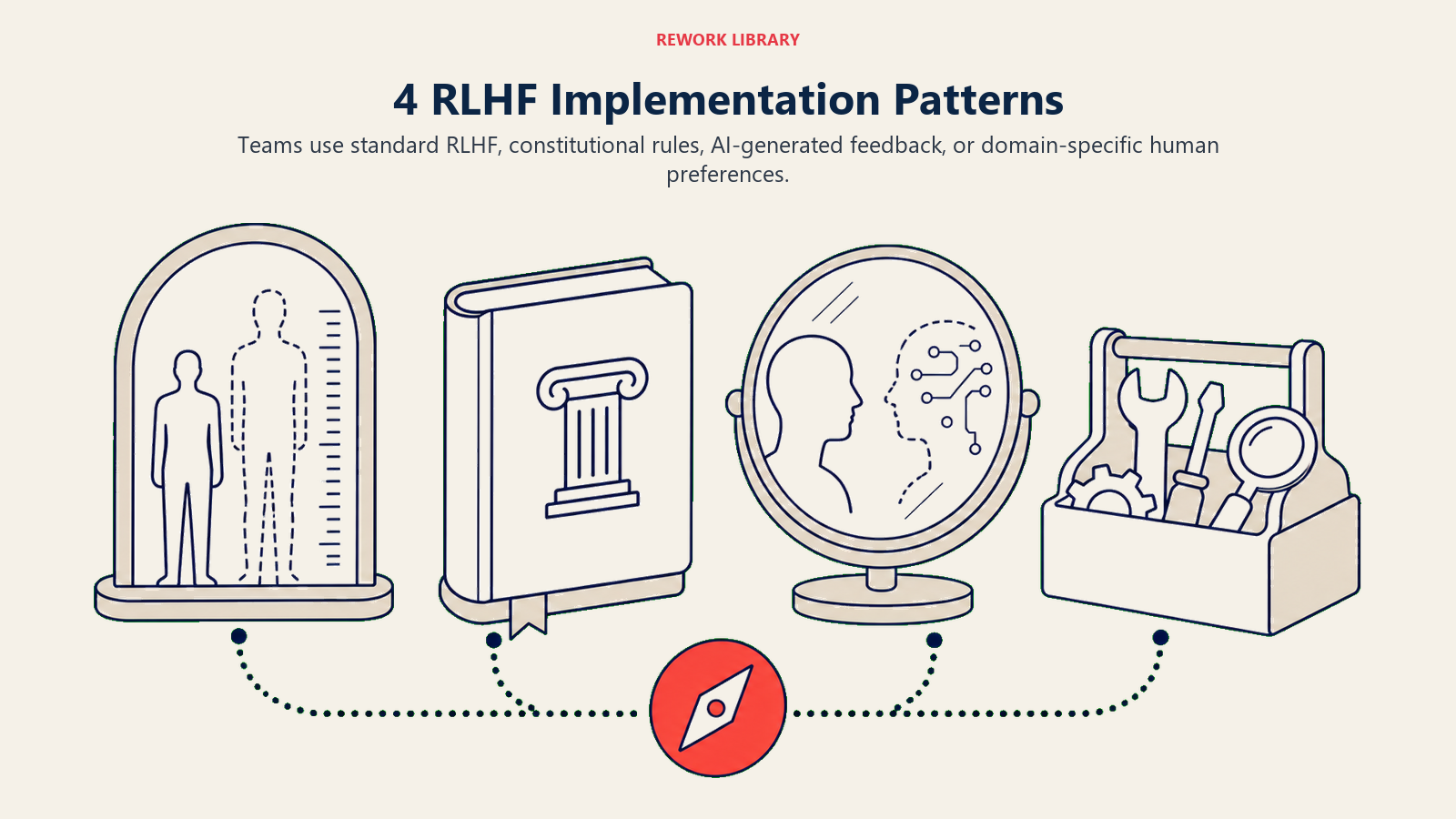
Type 1: Vanilla RLHF Best for: General conversational AI Key feature: Standard preference learning from comparisons Example: ChatGPT's helpful assistant behavior
Type 2: Constitutional AI Best for: Safety-critical applications Key feature: Trains against explicit principles and values (see AI Alignment) Example: Anthropic's Claude with harm prevention
Type 3: RLAIF (RL from AI Feedback) Best for: Scalable preference learning Key feature: Uses AI to generate preference labels Example: Automated safety training at scale
Type 4: Domain-Specific RLHF Best for: Specialized business applications Key feature: Preferences tuned to industry requirements Example: Medical AI trained on clinical appropriateness
RLHF Success Stories
Here's how RLHF powers real applications:
Customer Service Example: Intercom trained their AI customer service agent using RLHF based on support team feedback, reducing escalations by 45% while maintaining 90% customer satisfaction, as the AI learned nuanced communication preferences.
Code Generation Example: GitHub Copilot uses RLHF to generate code that developers actually use rather than technically correct but impractical suggestions, leading to 46% of code being accepted versus 26% without RLHF.
Content Moderation Example: OpenAI's GPT-4 uses RLHF to navigate complex content policy decisions, reducing false positives by 40% compared to rule-based systems by understanding contextual nuance.
Implementing RLHF
Ready to align your AI with human preferences?
- Understand foundations with Large Language Models
- Learn about Reinforcement Learning basics
- Explore Prompt Engineering for guidance
- Consider Fine-Tuning as a complementary approach
Frequently Asked Questions about RLHF
What is RLHF (Reinforcement Learning from Human Feedback)?
RLHF is a machine learning technique that trains AI models to behave according to human preferences by learning from comparative feedback, optimizing for useful responses rather than just statistically probable ones.
What's the difference between RLHF and traditional AI training?
Traditional training teaches AI to predict patterns in data. RLHF teaches AI to produce outputs that humans actually prefer, making it helpful and aligned with human values rather than just accurate.
What are the main types of RLHF approaches?
Vanilla RLHF (standard preference learning), Constitutional AI (principle-based training), RLAIF (AI-generated feedback), and Domain-Specific RLHF (industry-tuned preferences).
What are the core components of RLHF?
Supervised fine-tuning (demonstration), reward modeling (preference learning), reinforcement learning (policy optimization), human evaluators (feedback providers), and iterative refinement (continuous improvement).
External Resources
Explore authoritative research and documentation on RLHF:
- OpenAI RLHF Research - Foundational research on learning from human feedback
- Anthropic's Constitutional AI Paper - Advanced RLHF approach using AI-generated feedback
- Hugging Face RLHF Blog - Comprehensive guide to implementing RLHF in practice
Related Resources
Explore these related concepts to deepen your understanding of RLHF:
- Reinforcement Learning - The foundational learning paradigm RLHF builds on
- AI Alignment - The broader goal of making AI behave as intended
- Fine-Tuning - Alternative approach to customizing AI behavior
- Prompt Engineering - Complementary technique for guiding AI responses
Part of the AI Terms Collection. Last updated: 2026-02-09
