What is Knowledge Distillation? Getting GPT-4 Performance on a Budget

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GPT-4 is brilliant but costs $20 per million tokens. A tiny specialized model costs $0.20 for the same work but can't match GPT-4's capabilities. Or can it? Knowledge distillation has emerged as the technique that lets you transfer the intelligence of massive large language models into compact, fast, affordable versions, delivering 90% of the performance at 10% of the cost for specific use cases.
From Big Model Monopoly to Efficient Intelligence
Knowledge distillation emerged as a breakthrough technique in 2015 when researchers discovered that small neural networks could learn to mimic large ones by studying their behavior rather than relearning from raw data. What started as an academic curiosity became a production necessity.
Google Research defines knowledge distillation as "the process of transferring knowledge from a large, complex teacher model to a smaller, more efficient student model by training the student to reproduce the teacher's outputs and internal representations."
The field exploded when companies realized they could create specialized models that matched GPT-3 performance for specific tasks while running 100x faster on local hardware, turning expensive cloud APIs into affordable edge deployments.
Making Sense for Business Leaders
For business leaders, knowledge distillation means capturing the intelligence of state-of-the-art AI models in smaller, faster, cheaper versions optimized for your specific use case, reducing costs by 80-95% while maintaining quality for the tasks that matter to your business.
Think of it as hiring a senior expert to train a specialist team. The team won't know everything the expert knows, but they'll excel at the specific tasks you need, and you can afford 10 of them for the cost of one expert.
In practical terms, knowledge distillation enables you to run GPT-4 class intelligence on smartphones, process customer queries for pennies instead of dollars, and deploy AI that works offline without sacrificing accuracy for your use case.
Key Elements of Knowledge Distillation
Knowledge distillation consists of these essential components:

• Teacher Model: A large, powerful model (like GPT-4 or Claude) that achieves state-of-the-art performance but is too expensive or slow for production deployment
• Student Model: A smaller, faster model designed to learn from the teacher's knowledge rather than from raw training data, optimized for efficiency
• Soft Targets: The teacher's probability distributions over possible answers (not just the final answer), providing richer learning signals about uncertainty and nuance
• Distillation Training: The student learns to match both the teacher's final answers and its reasoning patterns, capturing the teacher's decision-making approach
• Task Specialization: The student model focuses on specific use cases where it can achieve near-teacher performance rather than attempting general intelligence
The Knowledge Distillation Process
Implementing knowledge distillation follows these steps:
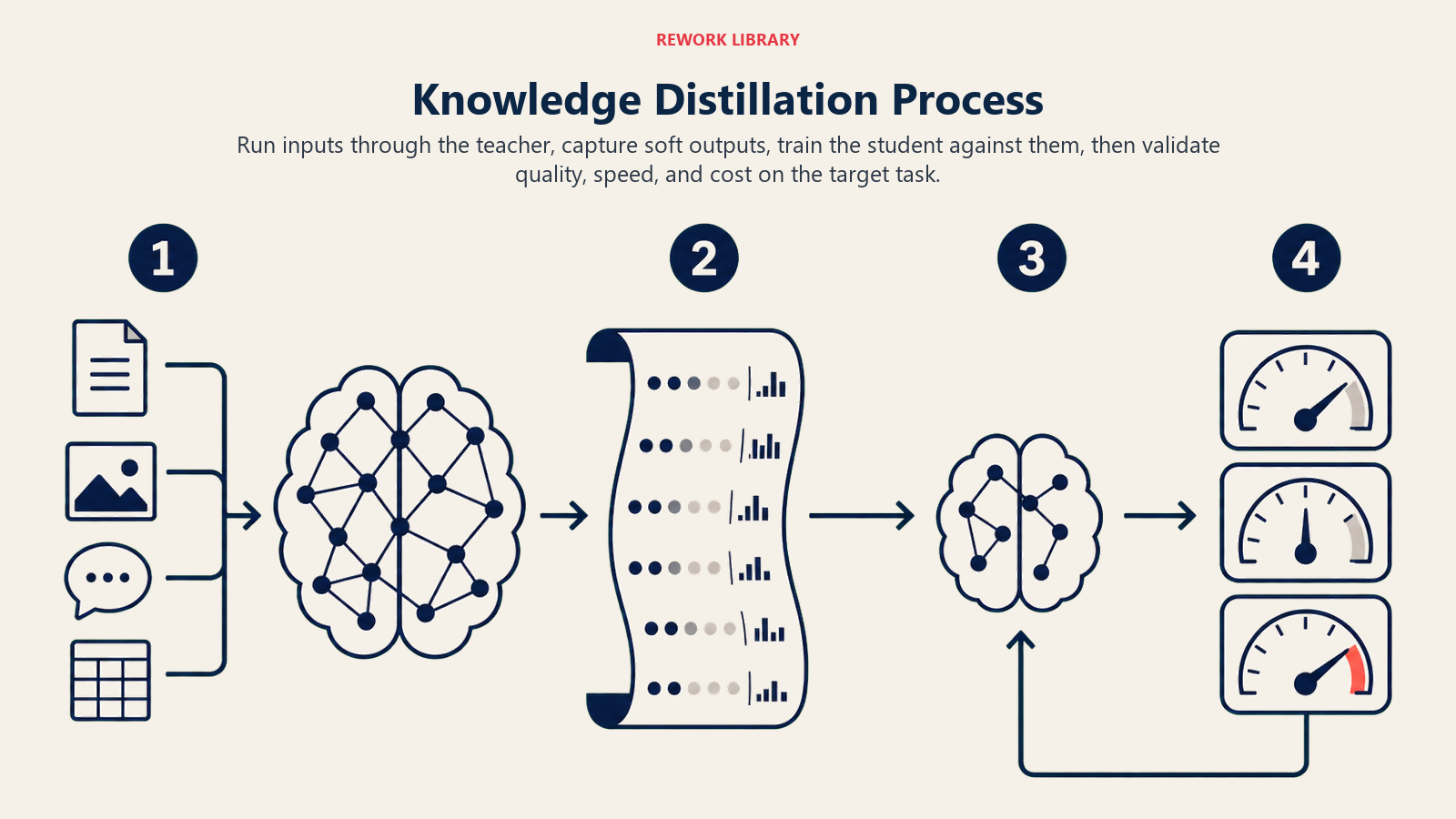
Select Teacher and Student: Choose a powerful teacher model for your domain and design a smaller student architecture (10-100x fewer parameters) that can run efficiently in your environment
Generate Training Data: Run your training examples through the teacher model, collecting its outputs, probability distributions, and intermediate activations to capture its decision-making patterns
Train Student to Mimic: Train the student model to reproduce the teacher's outputs and reasoning, using both correct answers and the teacher's confidence levels to transfer nuanced understanding
This process transforms a 175-billion parameter model that costs $50/hour to run into a 1-billion parameter model that achieves 95% of the performance at $0.50/hour.
Types of Knowledge Distillation
Knowledge distillation comes in several approaches:
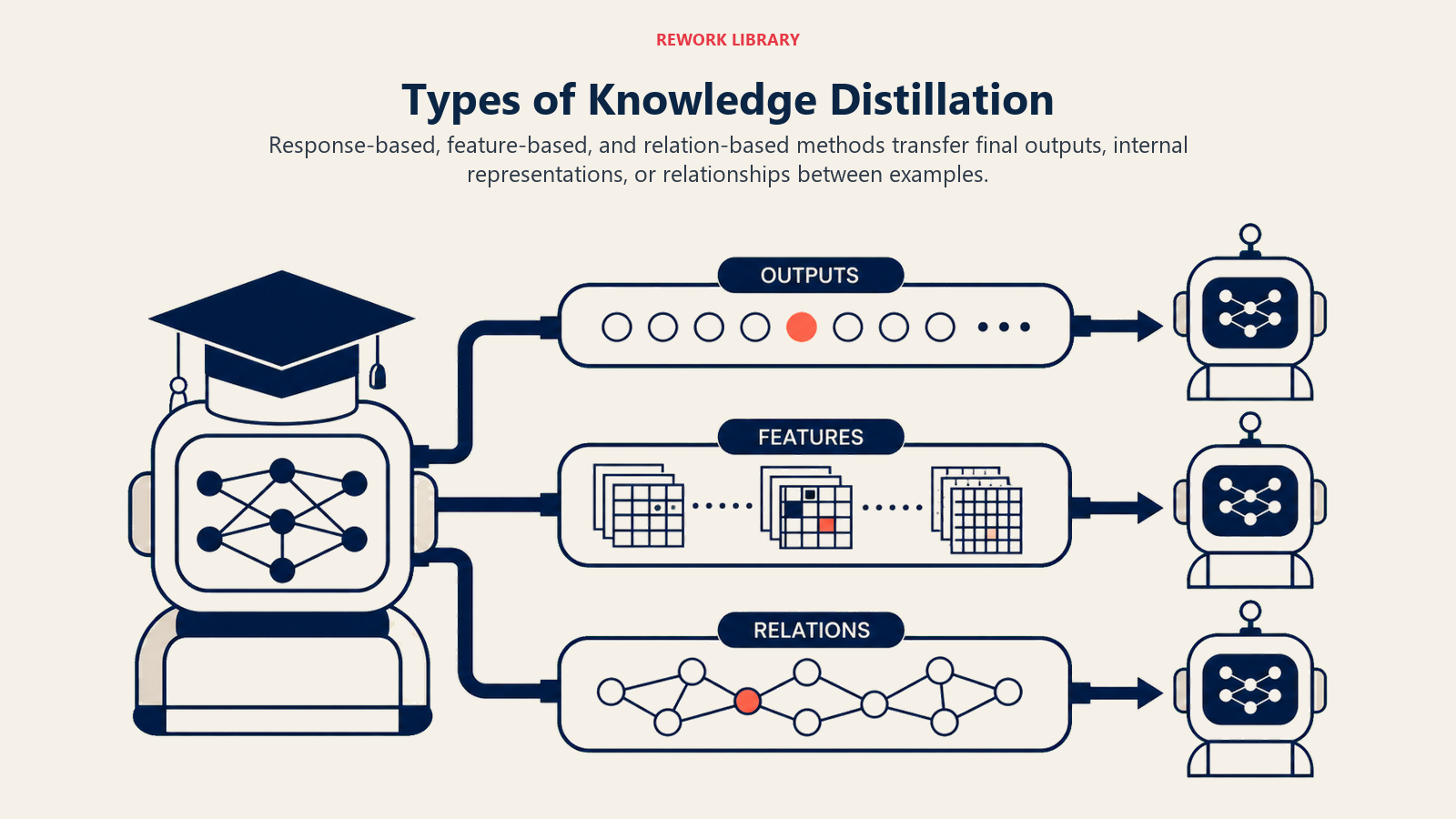
Type 1: Response-Based Distillation Best for: Quick implementation and simple tasks Key feature: Student learns from teacher's final outputs Example: Training a customer service chatbot to match GPT-4's answers for common questions
Type 2: Feature-Based Distillation Best for: Capturing deeper understanding Key feature: Student learns from teacher's internal representations Example: Creating a specialized image classifier that mimics a large vision model's feature extraction
Type 3: Relation-Based Distillation Best for: Complex reasoning tasks Key feature: Student learns relationships between concepts Example: Building a contract analysis model that captures a large model's understanding of legal clause interactions
Type 4: Multi-Teacher Distillation Best for: Combining multiple capabilities Key feature: Student learns from several specialized teachers Example: Creating a business intelligence assistant trained by separate experts in finance, operations, and sales
Knowledge Distillation in Action
Here's how businesses actually use knowledge distillation:
Customer Support Example: Intercom distilled GPT-3.5 knowledge into a 125-million parameter model for answering product questions. The distilled model achieves 92% of GPT-3.5's accuracy while running 40x faster and costing 95% less, enabling real-time responses on edge servers.
Legal Tech Example: LawGeex created a specialized contract review model by distilling knowledge from GPT-4 across 50,000 legal documents. The resulting model matches GPT-4's accuracy for contract analysis while running on-premise, protecting client confidentiality at 10% the cost.
E-commerce Example: Amazon uses knowledge distillation to create product recommendation models that capture the intelligence of their massive deep learning systems while running efficiently on mobile apps, delivering personalized recommendations in 50ms instead of 2 seconds.
Your Path to Knowledge Distillation Mastery
Ready to create efficient, specialized AI models?
- Understand model efficiency with Quantization
- Explore production optimization via Inference Optimization
- Learn about model training with Transfer Learning
Learn More
Expand your understanding of related AI concepts:
- Model Compression - Other techniques for smaller models
- Fine-tuning - Customizing pre-trained models
- Pruning - Removing unnecessary model components
- Neural Architecture Search - Designing efficient model structures
External Resources
- Google Research on Model Compression - Academic papers on distillation techniques
- Hugging Face Distillation Tutorials - Practical guides for implementing knowledge distillation
- OpenAI Model Efficiency Research - Cost-effective AI deployment strategies
Frequently Asked Questions about Knowledge Distillation
What is Knowledge Distillation?
Knowledge distillation is the process of training a smaller, faster student model to mimic the behavior and knowledge of a larger, more powerful teacher model, achieving similar performance at a fraction of the computational cost.
How much smaller can the student model be?
Student models are typically 10-100x smaller than teachers. A common approach is distilling GPT-3 (175B parameters) into specialized models of 1-7B parameters that match performance for specific tasks while running 50-100x faster.
What's the difference between knowledge distillation and fine-tuning?
Fine-tuning adapts a pre-trained model to new data using the same model architecture. Knowledge distillation transfers knowledge from a large model to a smaller, different architecture, creating a more efficient model optimized for deployment.
Does the student model match teacher performance?
For narrow, well-defined tasks, student models typically achieve 85-95% of teacher performance. The trade-off is breadth: students excel at specific tasks but lack the teacher's general capabilities.
When should I use knowledge distillation?
Use knowledge distillation when you have high inference costs, need fast response times, want to deploy on edge devices, or need specific task performance without general model capabilities. It's essential for scaling AI applications profitably.
Part of the AI Terms Collection. Last updated: 2026-02-09

Co-Founder, Rework.com