¿Qué es Mixture of Experts? La IA que activa solo lo que necesita
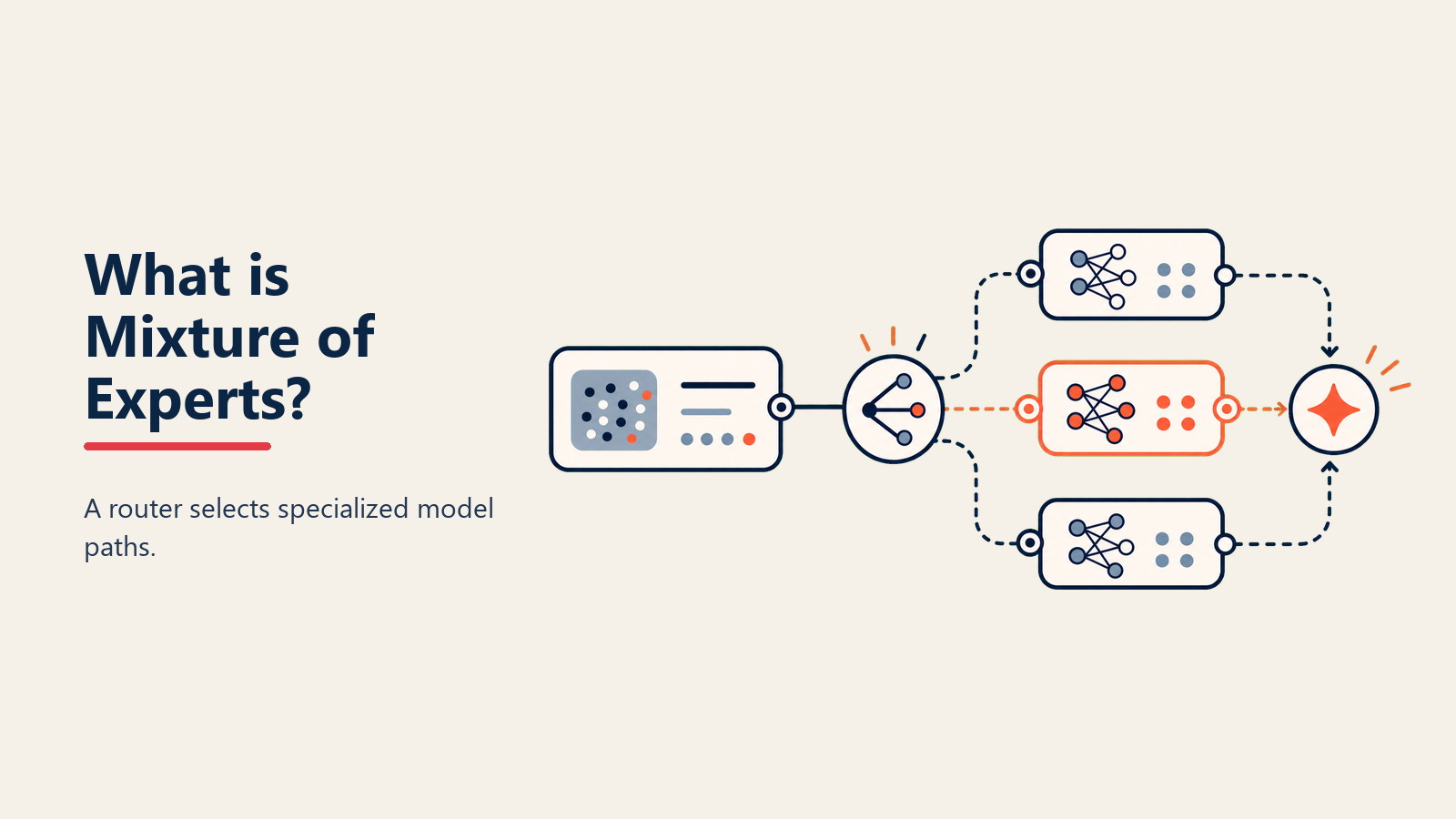 Imagina si tu cerebro activara cada neurona para cada pensamiento: leer un email consumiría tanta energía como resolver cálculo. En su lugar, tu cerebro activa solo las regiones que necesita. Mixture of Experts (MoE) trae esta eficiencia a la IA, usando sub-modelos especializados que se activan solo cuando se requiere su experiencia.
Imagina si tu cerebro activara cada neurona para cada pensamiento: leer un email consumiría tanta energía como resolver cálculo. En su lugar, tu cerebro activa solo las regiones que necesita. Mixture of Experts (MoE) trae esta eficiencia a la IA, usando sub-modelos especializados que se activan solo cuando se requiere su experiencia.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La arquitectura que cambió la economía de la IA
Mixture of Experts surgió de la investigación académica en los años 90, pero se volvió prácticamente importante en 2024 cuando OpenAI reveló que GPT-4 usa arquitectura MoE. El avance demostró que más grande no siempre es mejor: el enrutamiento inteligente supera la fuerza bruta.
Según Google Research, MoE es "una arquitectura de red neuronal que contiene múltiples sub-redes especializadas (expertos), donde un mecanismo de enrutamiento (gating) direcciona dinámicamente cada entrada a los expertos más relevantes, activando solo una fracción de la capacidad total del modelo para cualquier inferencia individual."
El cambio de juego llegó cuando Mistral AI lanzó Mixtral 8x7B en diciembre de 2023, demostrando que un modelo MoE podía igualar el rendimiento de modelos mucho más grandes usando 5 veces menos computación, haciendo la IA poderosa accesible para organizaciones más pequeñas.
Mixture of Experts para líderes empresariales
Para líderes empresariales, MoE significa obtener rendimiento nivel GPT-4 a una fracción del costo y velocidad, ya que la IA activa inteligentemente solo los componentes especializados necesarios para cada consulta en lugar de ejecutar todo el modelo masivo.
Piensa en la diferencia entre consultar a cada departamento por cada pregunta versus enrutar preguntas a los especialistas correctos. MoE es como tener un coordinador brillante que sabe instantáneamente qué experto activar, evitando el desperdicio de involucrar a todos.
En términos prácticos, los modelos MoE entregan respuestas más rápidas, costos de infraestructura más bajos y mejor rendimiento por dólar que los modelos densos tradicionales, haciendo que los large language models sofisticados sean económicamente viables para más casos de uso.
Componentes centrales de Mixture of Experts
Los sistemas MoE consisten en estos elementos esenciales:
• Expert Networks: Múltiples sub-modelos especializados, cada uno sobresaliendo en tipos particulares de entradas o tareas, como tener departamentos que cada uno domina diferentes dominios
• Gating Network: El sistema de enrutamiento que decide qué expertos activar para cada entrada, analizando la consulta y seleccionando los especialistas más relevantes
• Sparse Activation: Solo se activan 1-3 expertos por entrada en lugar de todos, reduciendo dramáticamente la computación mientras se mantiene la calidad mediante selección inteligente
• Load Balancing: Mecanismos que aseguran que los expertos sean usados aproximadamente por igual con el tiempo, evitando que algunos estén sobrecargados mientras otros permanecen inactivos
• Expert Specialization: A través del entrenamiento, diferentes expertos desarrollan naturalmente enfoque en diferentes patrones: uno puede sobresalir en código, otro en escritura creativa, otro en análisis
Cómo opera Mixture of Experts
Los modelos MoE siguen este ciclo operativo:
Análisis de entrada: Cuando envías una consulta, el gating network la analiza para entender qué tipo de experiencia se necesita, examinando patrones lingüísticos y contenido
Selección de expertos: Basándose en el análisis, el gating network enruta tu entrada a los 1-3 expertos más relevantes de potencialmente cientos disponibles
Procesamiento especializado: Solo los expertos seleccionados se activan y procesan tu entrada, cada uno contribuyendo su conocimiento especializado mientras el resto permanece inactivo, ahorrando computación masiva
Este enrutamiento dinámico ocurre en milisegundos, con el gating network aprendiendo con el tiempo qué expertos manejan qué tipos de consultas más efectivamente.
Tipos de implementaciones MoE
Las arquitecturas MoE sirven diferentes necesidades:
Tipo 1: Sparse MoE Mejor para: Inferencia eficiente a escala Característica clave: Enruta a pequeño subconjunto de expertos Ejemplo: GPT-4, Mixtral 8x7B para eficiencia de costos
Tipo 2: Dense MoE Mejor para: Rendimiento máximo Característica clave: Activa la mayoría o todos los expertos Ejemplo: Modelos de investigación priorizando calidad sobre velocidad
Tipo 3: Hierarchical MoE Mejor para: Tareas complejas multi-dominio Característica clave: Selección de expertos en cascada en múltiples niveles Ejemplo: Sistemas multi-modales manejando texto, visión, audio
Tipo 4: Soft MoE Mejor para: Mezcla suave de expertos Característica clave: Combinación ponderada de múltiples expertos Ejemplo: Sistemas requiriendo mezcla matizada de dominios
MoE entregando resultados
Así es como las organizaciones aprovechan MoE:
Ejemplo de herramientas para desarrolladores: Ghostwriter de Replit usa arquitectura MoE para proporcionar asistencia de código en docenas de lenguajes de programación, activando expertos específicos de lenguaje bajo demanda y reduciendo la latencia de respuesta en 60% comparado con modelos densos.
Ejemplo de soporte al cliente: El agente de IA de Intercom usa MoE para enrutar preguntas a expertos especializados para problemas técnicos, facturación, preguntas de producto e consultas generales, mejorando la precisión de resolución en 35% mientras maneja 3 veces más conversaciones por servidor.
Ejemplo de traducción: DeepL emplea modelos MoE donde diferentes expertos se especializan en pares de idiomas y dominios (legal, médico, técnico), logrando 25% mejor calidad de traducción que enfoques de modelo único en contenido especializado.
Implementando MoE
¿Listo para obtener más con menos?
- Comienza con fundamentos de Large Language Models
- Entiende la arquitectura de Neural Networks
- Aprende sobre técnicas de Model Optimization
- Considera Fine-Tuning para experiencia de dominio
Sección de FAQ
Preguntas frecuentes sobre Mixture of Experts
¿Qué es Mixture of Experts (MoE)?
Mixture of Experts es una arquitectura de red neuronal que contiene múltiples sub-redes especializadas (expertos), donde un mecanismo de enrutamiento direcciona dinámicamente cada entrada a los expertos más relevantes, activando solo una fracción de la capacidad total por inferencia.
¿Cuál es la diferencia entre MoE y las redes neuronales tradicionales?
Las redes densas tradicionales activan todos los parámetros para cada entrada. Las redes MoE activan solo expertos especializados relevantes, logrando mejor rendimiento con menos computación mediante enrutamiento inteligente.
¿Cuáles son los principales tipos de implementaciones MoE?
Sparse MoE (activa pocos expertos para eficiencia), Dense MoE (activa la mayoría para calidad), Hierarchical MoE (selección en cascada), y Soft MoE (mezcla ponderada de expertos).
¿Cuáles son ejemplos de modelos MoE?
GPT-4 (modelo insignia de OpenAI), Mixtral 8x7B (modelo eficiente de Mistral AI), Switch Transformer (modelo de un trillón de parámetros de Google), y varios modelos de dominio especializados usando enrutamiento de expertos.
Recursos relacionados
Explora estos conceptos relacionados para profundizar tu comprensión de Mixture of Experts:
- Large Language Models - Los sistemas que las arquitecturas MoE mejoran
- Neural Networks - La arquitectura fundamental para redes de expertos
- Model Optimization - Técnicas para despliegue eficiente de IA
- Transformer Architecture - La arquitectura base a menudo combinada con MoE
Recursos externos
- Google Research - Sparse Expert Models - Investigación sobre arquitecturas MoE eficientes
- Meta AI - Model Efficiency - Avances en activación dispersa y enrutamiento de expertos
- Microsoft Research - Scalable AI - Implementaciones empresariales de MoE
Parte de la Colección de Términos de IA. Última actualización: 2026-02-09

Co-Founder, Rework.com