Bahasa Indonesia
Apa itu RLHF? Mengajarkan AI Apa yang Benar-Benar Diinginkan Manusia
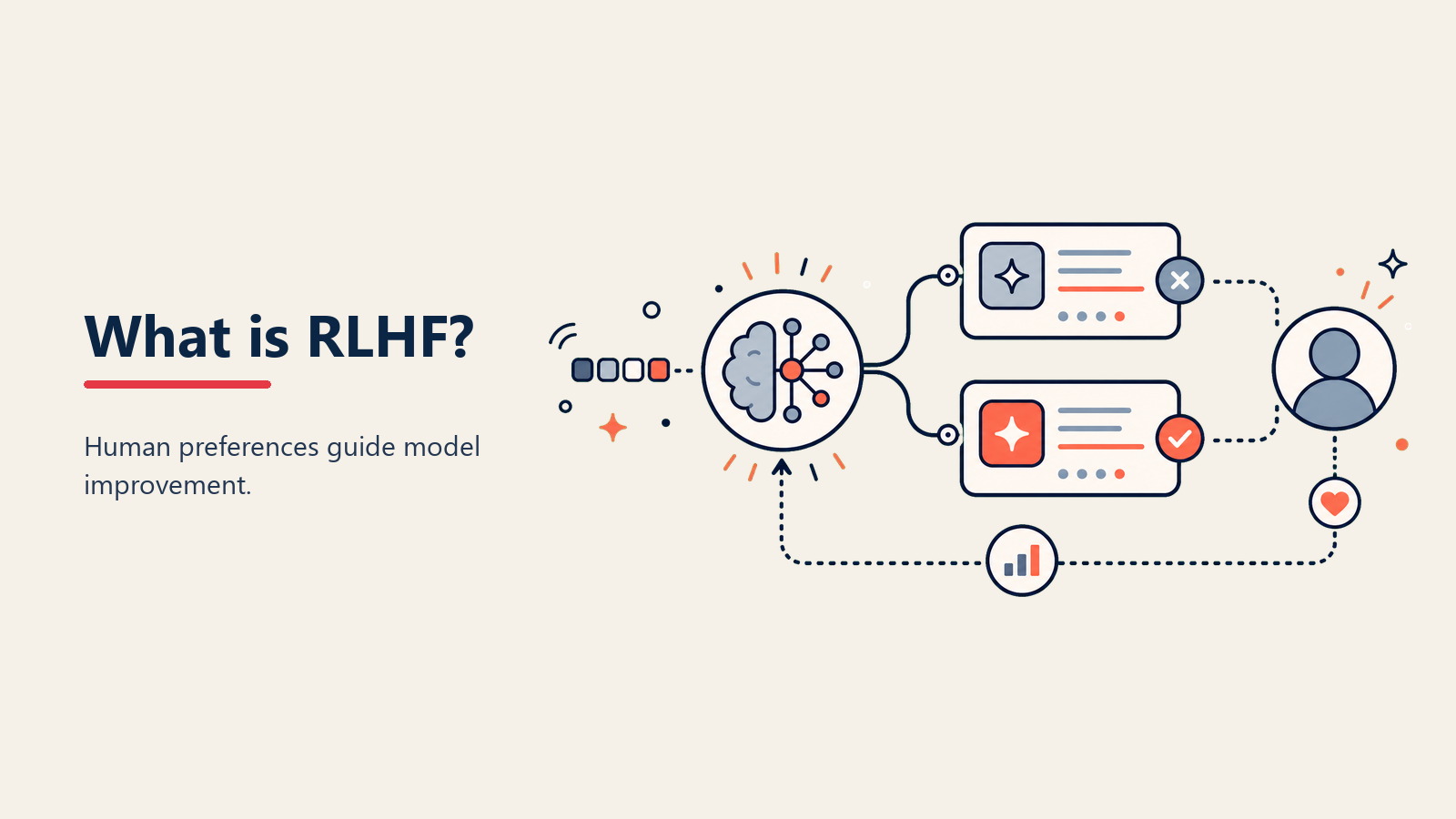 ChatGPT tidak menjadi bermanfaat secara kebetulan. Di balik respons yang sopan dan berguna adalah teknik training yang membuat AI peduli dengan apa yang benar-benar diinginkan manusia, bukan hanya yang secara teknis benar. Teknik itu adalah RLHF—dan inilah alasan mengapa AI modern terasa sangat berbeda dari versi sebelumnya.
ChatGPT tidak menjadi bermanfaat secara kebetulan. Di balik respons yang sopan dan berguna adalah teknik training yang membuat AI peduli dengan apa yang benar-benar diinginkan manusia, bukan hanya yang secara teknis benar. Teknik itu adalah RLHF—dan inilah alasan mengapa AI modern terasa sangat berbeda dari versi sebelumnya.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Terobosan yang Mengubah AI
Reinforcement Learning from Human Feedback muncul dari riset OpenAI pada 2017, tetapi meledak menjadi perhatian mainstream ketika menjalankan ChatGPT pada 2022. Teknik ini memecahkan masalah kritis: bagaimana membuat AI tidak hanya pintar, tetapi benar-benar bermanfaat.
Menurut riset OpenAI, RLHF adalah "teknik machine learning yang melatih model AI untuk berperilaku sesuai preferensi manusia dengan belajar dari feedback komparatif, mengoptimalkan respons yang benar-benar dianggap berguna oleh manusia daripada hanya yang secara statistik mungkin."
Game-changer datang ketika peneliti menyadari bahwa memprediksi kata berikutnya (training language model tradisional) tidak secara natural mengarah pada perilaku yang bermanfaat. Anda perlu secara eksplisit mengajarkan AI apa yang manusia anggap sebagai respons yang baik, dan RLHF menyediakan bagian yang hilang.
RLHF untuk Pemimpin Bisnis
Untuk pemimpin bisnis, RLHF adalah proses training yang mengubah AI mentah menjadi alat bisnis yang berguna—mengajarkannya untuk bermanfaat, tidak berbahaya, dan jujur daripada hanya akurat secara teknis atau kemungkinan statistik.
Pikirkan perbedaan antara magang yang menjawab pertanyaan secara literal versus yang memahami apa yang benar-benar Anda butuhkan. RLHF seperti memiliki ribuan trainer ahli yang memberikan feedback pada setiap respons hingga AI belajar bukan hanya yang benar, tetapi yang benar-benar berguna.
Dalam istilah praktis, RLHF adalah alasan mengapa AI sekarang dapat menolak permintaan yang tidak pantas, menjelaskan topik kompleks dengan jelas, dan mengakui ketika tidak tahu sesuatu. Ini mewakili evolusi fundamental di luar pendekatan machine learning tradisional yang mengoptimalkan akurasi saja.
Komponen Inti RLHF
RLHF terdiri dari elemen-elemen esensial berikut:
• Supervised Fine-Tuning (SFT): Fase training awal di mana manusia mendemonstrasikan respons ideal untuk berbagai prompt, memberikan AI contoh output berkualitas tinggi untuk dipelajari
• Reward Modeling: Manusia membandingkan beberapa respons AI dan menunjukkan mana yang lebih baik, melatih model terpisah untuk memprediksi preferensi manusia secara otomatis
• Reinforcement Learning: AI berlatih menghasilkan respons dan menerima "reward" berdasarkan model preferensi, secara bertahap belajar menghasilkan output yang disukai manusia
• Human Evaluators: Tim reviewer yang memberikan feedback komparatif yang menggerakkan seluruh proses, seringkali dengan panduan detail tentang kegunaan, keamanan, dan akurasi
• Iterative Refinement: Siklus feedback dan training berkelanjutan yang secara progresif menyelaraskan model dengan nilai dan ekspektasi manusia
Cara Kerja RLHF
Proses RLHF mengikuti langkah-langkah berikut:
Demonstration Collection: Trainer manusia menulis contoh percakapan yang menunjukkan bagaimana AI seharusnya merespons berbagai query, menciptakan fondasi perilaku yang bermanfaat
Preference Learning: AI menghasilkan beberapa respons untuk prompt, dan manusia memberi peringkat dari terbaik hingga terburuk, mengajarkan sistem untuk membedakan output yang baik dari yang buruk
Policy Optimization: AI mempelajari policy—strategi untuk menghasilkan respons—yang memaksimalkan persetujuan manusia yang diharapkan berdasarkan preferensi yang dipelajari, menggunakan algoritma reinforcement learning
Siklus ini berulang ribuan kali, dengan AI secara bertahap menginternalisasi apa yang membuat respons bermanfaat, aman, dan selaras dengan intensi manusia.
Pola Implementasi RLHF
Sistem RLHF hadir dalam beberapa variasi:
Type 1: Vanilla RLHF Terbaik untuk: Conversational AI umum Fitur utama: Preference learning standar dari perbandingan Contoh: Perilaku asisten ChatGPT yang bermanfaat
Type 2: Constitutional AI Terbaik untuk: Aplikasi critical-safety Fitur utama: Melatih terhadap prinsip dan nilai eksplisit (lihat AI Alignment) Contoh: Claude dari Anthropic dengan pencegahan bahaya
Type 3: RLAIF (RL from AI Feedback) Terbaik untuk: Preference learning yang scalable Fitur utama: Menggunakan AI untuk menghasilkan label preferensi Contoh: Safety training otomatis dalam skala besar
Type 4: Domain-Specific RLHF Terbaik untuk: Aplikasi bisnis khusus Fitur utama: Preferensi disetel untuk kebutuhan industri Contoh: AI medis yang dilatih pada kelayakan klinis
Kisah Sukses RLHF
Berikut bagaimana RLHF menjalankan aplikasi nyata:
Contoh Customer Service: Intercom melatih agen customer service AI mereka menggunakan RLHF berdasarkan feedback tim support, mengurangi eskalasi sebesar 45% sambil mempertahankan kepuasan pelanggan 90%, karena AI mempelajari preferensi komunikasi yang nuanced.
Contoh Code Generation: GitHub Copilot menggunakan RLHF untuk menghasilkan kode yang benar-benar digunakan developer daripada saran yang secara teknis benar tetapi tidak praktis, menghasilkan 46% kode yang diterima versus 26% tanpa RLHF.
Contoh Content Moderation: GPT-4 dari OpenAI menggunakan RLHF untuk menavigasi keputusan kebijakan konten yang kompleks, mengurangi false positive sebesar 40% dibanding sistem berbasis aturan dengan memahami nuansa kontekstual.
Mengimplementasikan RLHF
Siap menyelaraskan AI Anda dengan preferensi manusia?
- Pahami fondasi dengan Large Language Models
- Pelajari dasar Reinforcement Learning
- Jelajahi Prompt Engineering untuk panduan
- Pertimbangkan Fine-Tuning sebagai pendekatan pelengkap
FAQ Section
Frequently Asked Questions about RLHF
Apa itu RLHF (Reinforcement Learning from Human Feedback)?
RLHF adalah teknik machine learning yang melatih model AI untuk berperilaku sesuai preferensi manusia dengan belajar dari feedback komparatif, mengoptimalkan respons yang berguna daripada hanya yang secara statistik mungkin.
Apa perbedaan antara RLHF dan training AI tradisional?
Training tradisional mengajarkan AI untuk memprediksi pola dalam data. RLHF mengajarkan AI untuk menghasilkan output yang benar-benar disukai manusia, membuatnya bermanfaat dan selaras dengan nilai manusia daripada hanya akurat.
Apa saja jenis pendekatan RLHF utama?
Vanilla RLHF (preference learning standar), Constitutional AI (training berbasis prinsip), RLAIF (feedback yang dihasilkan AI), dan Domain-Specific RLHF (preferensi yang disetel industri).
Apa komponen inti RLHF?
Supervised fine-tuning (demonstrasi), reward modeling (preference learning), reinforcement learning (policy optimization), human evaluators (penyedia feedback), dan iterative refinement (perbaikan berkelanjutan).
External Resources
Jelajahi riset dan dokumentasi otoritatif tentang RLHF:
- OpenAI RLHF Research - Riset fondasi tentang belajar dari preferensi manusia
- Anthropic's Constitutional AI Paper - Pendekatan RLHF lanjutan menggunakan feedback yang dihasilkan AI
- Hugging Face RLHF Blog - Panduan komprehensif untuk mengimplementasikan RLHF dalam praktik
Related Resources
Jelajahi konsep terkait untuk memperdalam pemahaman Anda tentang RLHF:
- Reinforcement Learning - Paradigma pembelajaran fondasi yang menjadi basis RLHF
- AI Alignment - Tujuan yang lebih luas untuk membuat AI berperilaku sesuai keinginan
- Fine-Tuning - Pendekatan alternatif untuk menyesuaikan perilaku AI
- Prompt Engineering - Teknik pelengkap untuk memandu respons AI
Bagian dari AI Terms Collection. Terakhir diperbarui: 2026-02-09
