¿Qué es Multimodal AI? Un modelo para todo tu contenido
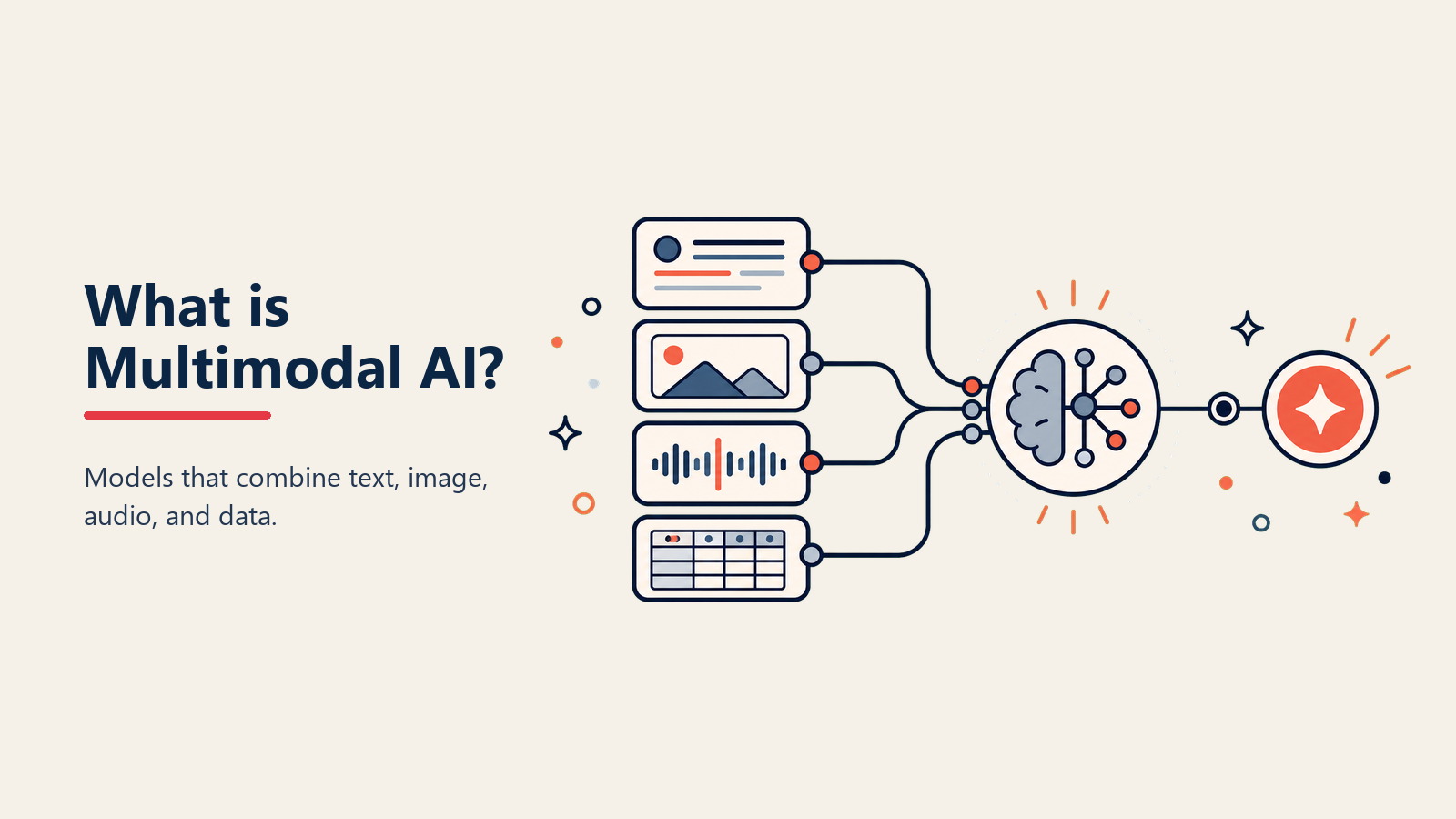 Imagina una IA que puede leer tu email, analizar la hoja de cálculo adjunta, ver el video demo y responder con insights de los tres. Sin cambiar entre herramientas. Sin resúmenes manuales. Solo un sistema inteligente que entiende todo lo que le lanzas. Eso es la IA multimodal.
Imagina una IA que puede leer tu email, analizar la hoja de cálculo adjunta, ver el video demo y responder con insights de los tres. Sin cambiar entre herramientas. Sin resúmenes manuales. Solo un sistema inteligente que entiende todo lo que le lanzas. Eso es la IA multimodal.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La revolución de la IA unificada
La IA multimodal surgió cuando los investigadores se dieron cuenta de las limitaciones de sistemas de entrada única. Los modelos de IA tempranos podían procesar solo texto o solo imágenes. Para 2023, modelos revolucionarios como GPT-4V y Gemini de Google cambiaron todo.
Según Google Research, la IA multimodal representa "modelos que pueden procesar y razonar sobre múltiples tipos de datos de entrada—incluyendo texto, imágenes, audio y video—en una sola arquitectura unificada, reflejando cómo los humanos naturalmente perciben y entienden el mundo."
El avance llegó cuando OpenAI lanzó GPT-4 con capacidades de visión en septiembre de 2023, seguido por Gemini de Google en diciembre de 2023 y Claude 3 de Anthropic en marzo de 2024, cada uno demostrando que la IA finalmente podía igualar la habilidad humana para trabajar con medios mixtos.
IA multimodal para líderes empresariales
Para líderes empresariales, la IA multimodal es como contratar a un experto que puede leer documentos, interpretar gráficos, ver videos y escuchar llamadas—todo a la vez—luego sintetizar insights en cada formato que tu negocio produce.
Piensa en la diferencia entre tener especialistas separados para texto, imágenes y audio versus un experto que entiende los tres juntos. El experto multimodal ve patrones, conexiones e insights que especialistas trabajando aislados perderían.
En términos prácticos, la IA multimodal puede analizar llamadas de clientes (audio), revisar imágenes de productos, leer tickets de soporte (texto) e identificar tendencias en todos los canales simultáneamente. Esto representa un salto masivo más allá de los large language models tradicionales que manejaban solo texto.
Componentes centrales de la IA multimodal
Los sistemas de IA multimodal consisten en estos elementos esenciales:
• Unified Encoder: Convierte diferentes tipos de datos—texto, imágenes, audio, video—en una representación común que el modelo puede procesar juntos, como un traductor universal para formatos de información
• Cross-Modal Attention: Mecanismo que permite al modelo entender relaciones entre diferentes tipos de entrada, como conectar palabras habladas en audio a objetos en imágenes
• Shared Reasoning Layer: Motor de procesamiento común que piensa sobre todos los tipos de entrada juntos, habilitando síntesis verdadera en lugar de análisis separado
• Modal Adapters: Componentes especializados que manejan las características únicas de cada tipo de entrada mientras alimentan al sistema unificado
• Output Generation: Capacidad de responder en múltiples formatos, desde texto a imágenes a datos estructurados, dependiendo de lo que mejor sirva al caso de uso
Cómo opera la IA multimodal
La IA multimodal sigue este ciclo operativo:
Simultaneous Ingestion: El modelo recibe entradas en múltiples formatos—digamos, una imagen de producto, texto de reseña de cliente y video demo—todo a la vez
Unified Processing: Convierte todas las entradas en representaciones internas comunes, permitiendo al modelo entender relaciones entre modalidades, como cómo la imagen se relaciona con descripciones escritas
Cross-Modal Reasoning: Analiza patrones e insights que abarcan múltiples tipos de datos, como notar que el sentimiento de audio positivo se correlaciona con características visuales específicas del producto
Este ciclo continúa con el modelo aprendiendo de retroalimentación en todas las modalidades, volviéndose más hábil en entender cómo se conectan diferentes tipos de información.
Tipos de sistemas de IA multimodal
La IA multimodal sirve diferentes funciones empresariales:
Tipo 1: Vision-Language Models Mejor para: Comprensión de documentos y análisis visual Característica clave: Combina texto e imágenes sin problemas Ejemplo: GPT-4V analizando gráficos e informes
Tipo 2: Audio-Visual Models Mejor para: Análisis de video e inteligencia de reuniones Característica clave: Entiende habla en contexto de contenido visual Ejemplo: Resúmenes automatizados de reuniones con identificación de hablantes
Tipo 3: Text-Image-Audio Systems Mejor para: Análisis completo de contenido Característica clave: Procesa todos los principales tipos de medios juntos usando generative AI Ejemplo: Google Gemini manejando consultas de formato mixto
Tipo 4: Sensor-Fusion Models Mejor para: IoT y aplicaciones del mundo real Característica clave: Combina datos estructurados de sensores con medios Ejemplo: Control de calidad manufacturero con cámaras y mediciones
IA multimodal entregando resultados
Así es como las empresas despliegan IA multimodal:
Ejemplo de salud: Siemens Healthineers usa IA multimodal para analizar imágenes médicas, resultados de laboratorio y notas clínicas juntos, reduciendo tiempo de diagnóstico en 40% mientras detecta problemas que sistemas de modalidad única perdieron.
Ejemplo retail: La búsqueda de productos de Amazon ahora usa IA multimodal para entender consultas como "muéstrame zapatos como en esta foto pero en azul," combinando reconocimiento de imagen con comprensión de texto para entregar resultados 35% más precisos.
Ejemplo de servicios financieros: JPMorgan analiza llamadas de earnings usando IA multimodal que procesa lenguaje hablado, diapositivas de presentación y documentos financieros simultáneamente, identificando insights de inversión 50% más rápido que equipos de analistas.
Implementando IA multimodal
¿Listo para unificar tus capacidades de IA?
- Comienza con fundamentos de Large Language Models
- Entiende conceptos básicos de Computer Vision
- Aprende sobre Natural Language Processing
- Considera AI Orchestration para workflows complejos
Sección de FAQ
Preguntas frecuentes sobre Multimodal AI
¿Qué es Multimodal AI?
Multimodal AI se refiere a modelos que pueden procesar y razonar sobre múltiples tipos de datos de entrada—incluyendo texto, imágenes, audio y video—en una sola arquitectura unificada, similar a cómo los humanos naturalmente entienden el mundo.
¿Cuál es la diferencia entre IA multimodal e IA tradicional?
Los modelos de IA tradicionales procesan un tipo de datos (solo texto o solo imagen). La IA multimodal procesa múltiples tipos de datos simultáneamente, entendiendo relaciones entre ellos y generando insights entre formatos.
¿Cuáles son los principales tipos de sistemas de IA multimodal?
Vision-Language Models (texto e imágenes), Audio-Visual Models (habla y video), Text-Image-Audio Systems (todos los principales tipos de medios), y Sensor-Fusion Models (datos estructurados más medios).
¿Cuáles son ejemplos de modelos de IA multimodal?
GPT-4V (OpenAI), Gemini (Google), Claude 3 (Anthropic), y modelos especializados como CLIP (imagen-texto), Whisper (audio), e ImageBind (todas las modalidades).
Recursos relacionados
Explora estos conceptos relacionados para profundizar tu comprensión de la IA multimodal:
- Computer Vision - Cómo la IA procesa y entiende imágenes
- Neural Networks - La arquitectura fundamental que impulsa sistemas multimodales
- Transformer Architecture - La base técnica detrás de modelos multimodales modernos
- Embeddings - Cómo diferentes tipos de datos se convierten en representaciones comunes
Recursos externos
- Google Research - Multimodal AI - Últimos avances en modelos de IA unificados
- Meta AI - Vision and Language - Investigación sobre comprensión cross-modal
- Microsoft Research - Multimodal Systems - Aplicaciones multimodales empresariales
Parte de la Colección de Términos de IA. Última actualización: 2026-02-09

Co-Founder, Rework.com