Bahasa Indonesia
Apa itu Multimodal AI? Satu Model untuk Semua Konten Anda
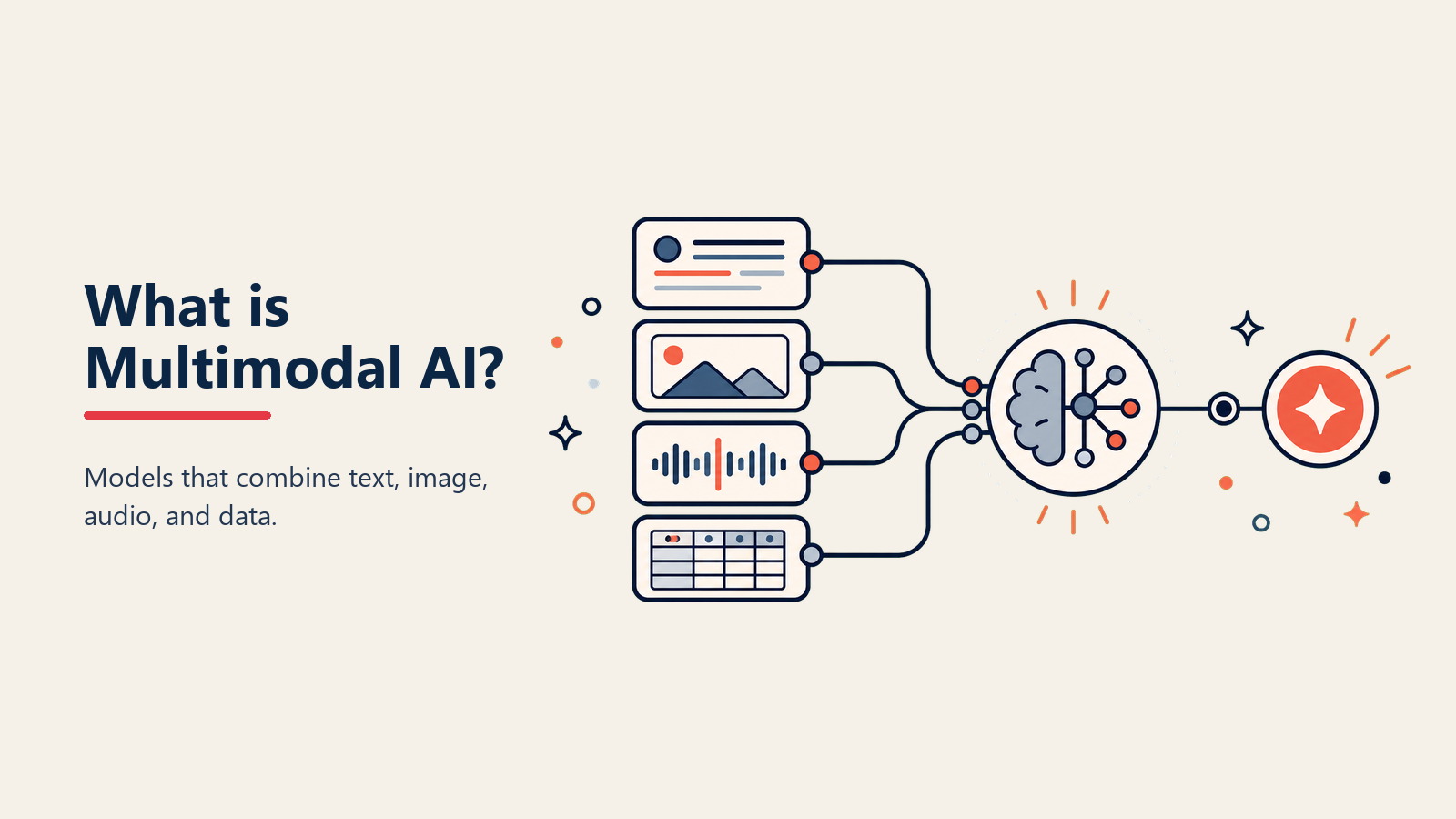 Bayangkan AI yang dapat membaca email Anda, menganalisis spreadsheet yang dilampirkan, menonton video demo, dan merespons dengan insight dari ketiganya. Tidak perlu beralih antar tools. Tidak ada summarization manual. Hanya satu sistem cerdas yang memahami semua yang Anda berikan padanya. Itulah multimodal AI.
Bayangkan AI yang dapat membaca email Anda, menganalisis spreadsheet yang dilampirkan, menonton video demo, dan merespons dengan insight dari ketiganya. Tidak perlu beralih antar tools. Tidak ada summarization manual. Hanya satu sistem cerdas yang memahami semua yang Anda berikan padanya. Itulah multimodal AI.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Revolusi AI Terpadu
Multimodal AI muncul ketika peneliti menyadari keterbatasan sistem input tunggal. Model AI awal hanya bisa memproses teks saja atau gambar saja. Pada tahun 2023, model terobosan seperti GPT-4V dan Gemini Google mengubah segalanya.
Menurut Google Research, multimodal AI merepresentasikan "model yang dapat memproses dan bernalar di berbagai jenis data input—termasuk teks, gambar, audio, dan video—dalam satu arsitektur terpadu, mencerminkan bagaimana manusia secara alami mempersepsikan dan memahami dunia."
Terobosan terjadi ketika OpenAI merilis GPT-4 dengan kemampuan vision pada September 2023, diikuti oleh Gemini Google pada Desember 2023 dan Claude 3 Anthropic pada Maret 2024, masing-masing mendemonstrasikan bahwa AI akhirnya bisa menyamai kemampuan manusia untuk bekerja dengan mixed media.
Multimodal AI untuk Pemimpin Bisnis
Untuk pemimpin bisnis, multimodal AI seperti mempekerjakan ahli yang dapat membaca dokumen, menginterpretasi grafik, menonton video, dan mendengarkan panggilan—semuanya sekaligus—kemudian mensintesis insight di setiap format yang diproduksi bisnis Anda.
Pikirkan perbedaan antara memiliki spesialis terpisah untuk teks, gambar, dan audio versus satu ahli yang memahami ketiganya bersama. Ahli multimodal melihat pola, koneksi, dan insight yang akan dilewatkan spesialis yang bekerja terisolasi.
Dalam istilah praktis, multimodal AI dapat menganalisis panggilan pelanggan (audio), meninjau gambar produk, membaca support ticket (teks), dan mengidentifikasi tren di semua channel secara bersamaan. Ini merepresentasikan lompatan besar melampaui large language models tradisional yang hanya menangani teks.
Komponen Inti Multimodal AI
Sistem multimodal AI terdiri dari elemen esensial ini:
• Unified Encoder: Mengonversi berbagai jenis data—teks, gambar, audio, video—menjadi representasi umum yang dapat diproses model bersama, seperti penerjemah universal untuk format informasi
• Cross-Modal Attention: Mekanisme yang memungkinkan model memahami hubungan antara berbagai jenis input, seperti menghubungkan kata-kata yang diucapkan dalam audio dengan objek dalam gambar
• Shared Reasoning Layer: Mesin pemrosesan umum yang memikirkan semua jenis input bersama, memungkinkan sintesis sejati daripada analisis terpisah
• Modal Adapters: Komponen khusus yang menangani karakteristik unik setiap jenis input sambil menyuburkan ke sistem terpadu
• Output Generation: Kemampuan untuk merespons dalam berbagai format, dari teks ke gambar ke data terstruktur, tergantung pada apa yang paling melayani use case
Bagaimana Multimodal AI Beroperasi
Multimodal AI mengikuti siklus operasional ini:
Simultaneous Ingestion: Model menerima input di berbagai format—katakanlah, gambar produk, teks review pelanggan, dan video demo—semuanya sekaligus
Unified Processing: Mengonversi semua input menjadi representasi internal umum, memungkinkan model memahami hubungan antar modalitas, seperti bagaimana gambar berhubungan dengan deskripsi tertulis
Cross-Modal Reasoning: Menganalisis pola dan insight yang mencakup berbagai jenis data, seperti memperhatikan bahwa sentimen audio positif berkorelasi dengan fitur produk visual tertentu
Siklus ini berlanjut dengan model belajar dari feedback di semua modalitas, menjadi lebih terampil dalam memahami bagaimana berbagai jenis informasi terhubung.
Jenis Sistem Multimodal AI
Multimodal AI melayani berbagai fungsi bisnis:
Tipe 1: Vision-Language Models Terbaik untuk: Pemahaman dokumen dan analisis visual Fitur kunci: Menggabungkan teks dan gambar dengan mulus Contoh: GPT-4V menganalisis grafik dan laporan
Tipe 2: Audio-Visual Models Terbaik untuk: Analisis video dan meeting intelligence Fitur kunci: Memahami ucapan dalam konteks konten visual Contoh: Ringkasan meeting otomatis dengan identifikasi speaker
Tipe 3: Text-Image-Audio Systems Terbaik untuk: Analisis konten komprehensif Fitur kunci: Memproses semua jenis media utama bersama menggunakan generative AI Contoh: Google Gemini menangani query format campuran
Tipe 4: Sensor-Fusion Models Terbaik untuk: IoT dan aplikasi dunia nyata Fitur kunci: Menggabungkan data sensor terstruktur dengan media Contoh: Quality control manufaktur dengan kamera dan pengukuran
Multimodal AI Memberikan Hasil
Inilah bagaimana bisnis mendeploy multimodal AI:
Healthcare Example: Siemens Healthineers menggunakan multimodal AI untuk menganalisis gambar medis, hasil lab, dan catatan klinis bersama, mengurangi waktu diagnostik sebesar 40% sambil menangkap masalah yang dilewatkan sistem single-modality.
Retail Example: Pencarian produk Amazon sekarang menggunakan multimodal AI untuk memahami query seperti "tunjukkan sepatu seperti di foto ini tapi berwarna biru," menggabungkan image recognition dengan pemahaman teks untuk memberikan hasil 35% lebih akurat.
Financial Services Example: JPMorgan menganalisis earnings call menggunakan multimodal AI yang memproses spoken language, presentation slide, dan financial document secara bersamaan, mengidentifikasi investment insight 50% lebih cepat dari tim analis.
Mengimplementasikan Multimodal AI
Siap menyatukan kemampuan AI Anda?
- Mulai dengan fundamental Large Language Models
- Pahami dasar Computer Vision
- Pelajari tentang Natural Language Processing
- Pertimbangkan AI Orchestration untuk workflow kompleks
FAQ Section
Frequently Asked Questions tentang Multimodal AI
Apa itu Multimodal AI?
Multimodal AI mengacu pada model yang dapat memproses dan bernalar di berbagai jenis data input—termasuk teks, gambar, audio, dan video—dalam satu arsitektur terpadu, mirip dengan bagaimana manusia secara alami memahami dunia.
Apa perbedaan antara multimodal AI dan AI tradisional?
Model AI tradisional memproses satu jenis data (hanya teks atau hanya gambar). Multimodal AI memproses berbagai jenis data secara bersamaan, memahami hubungan di antara mereka dan menghasilkan insight di berbagai format.
Apa saja jenis utama sistem multimodal AI?
Vision-Language Models (teks dan gambar), Audio-Visual Models (ucapan dan video), Text-Image-Audio Systems (semua jenis media utama), dan Sensor-Fusion Models (data terstruktur plus media).
Apa contoh model multimodal AI?
GPT-4V (OpenAI), Gemini (Google), Claude 3 (Anthropic), dan model khusus seperti CLIP (image-text), Whisper (audio), dan ImageBind (semua modalitas).
Related Resources
Eksplorasi konsep terkait ini untuk memperdalam pemahaman Anda tentang multimodal AI:
- Computer Vision - Bagaimana AI memproses dan memahami gambar
- Neural Networks - Arsitektur foundational yang menggerakkan sistem multimodal
- Transformer Architecture - Fondasi teknis di balik model multimodal modern
- Embeddings - Bagaimana berbagai jenis data dikonversi ke representasi umum
External Resources
- Google Research - Multimodal AI - Kemajuan terbaru dalam model AI terpadu
- Meta AI - Vision and Language - Riset tentang pemahaman cross-modal
- Microsoft Research - Multimodal Systems - Aplikasi multimodal enterprise
Bagian dari AI Terms Collection. Terakhir diperbarui: 2026-02-09
