Was ist Multimodal AI? Ein Modell für all Ihre Inhalte
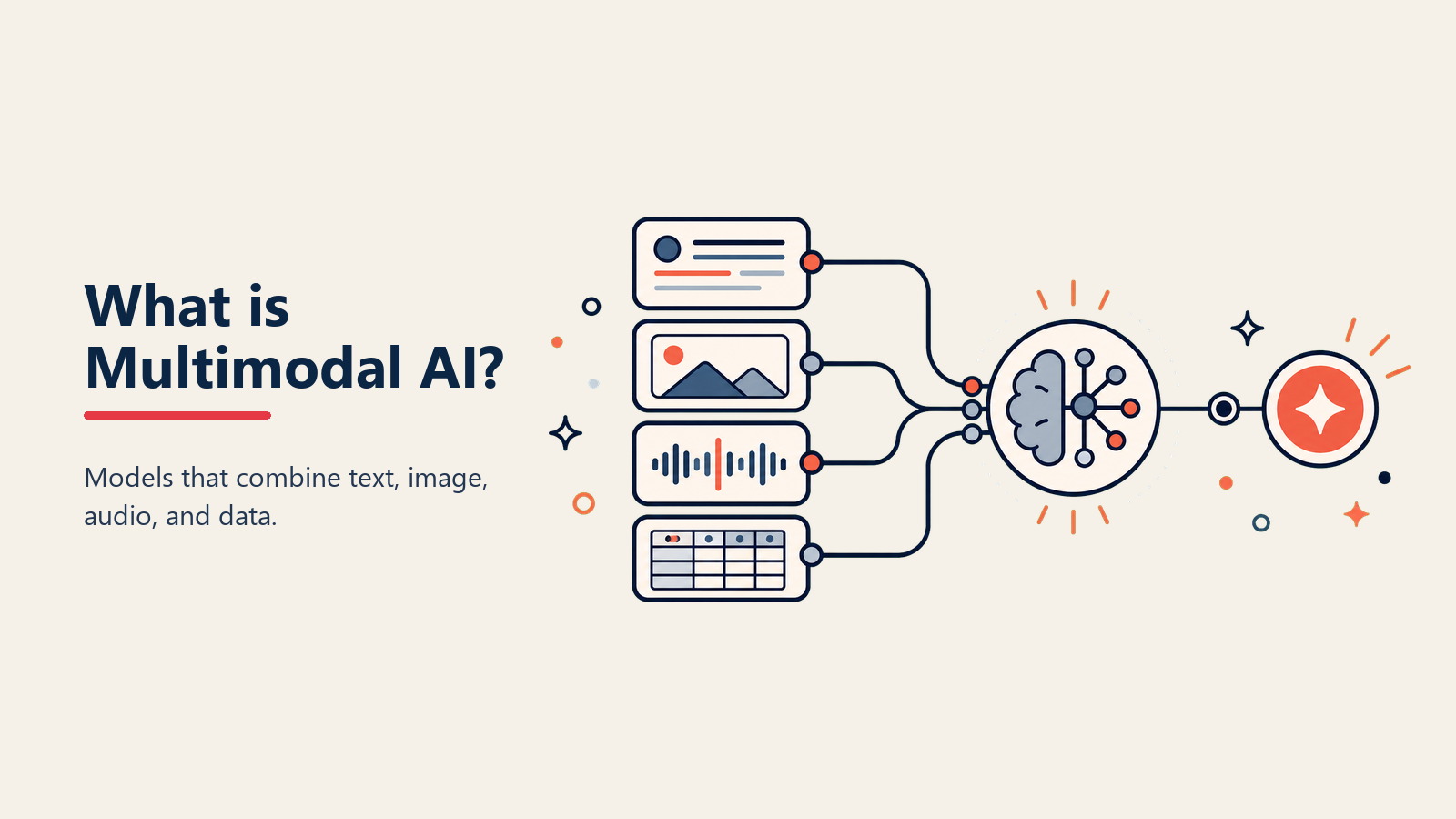 Stellen Sie sich eine KI vor, die Ihre E-Mail lesen, die angehängte Tabelle analysieren, das Demo-Video ansehen und mit Insights aus allen dreien antworten kann. Kein Wechsel zwischen Tools. Keine manuelle Zusammenfassung. Nur ein intelligentes System, das alles versteht, was Sie ihm vorsetzen. Das ist Multimodal AI.
Stellen Sie sich eine KI vor, die Ihre E-Mail lesen, die angehängte Tabelle analysieren, das Demo-Video ansehen und mit Insights aus allen dreien antworten kann. Kein Wechsel zwischen Tools. Keine manuelle Zusammenfassung. Nur ein intelligentes System, das alles versteht, was Sie ihm vorsetzen. Das ist Multimodal AI.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die Unified AI Revolution
Multimodal AI entstand, als Forscher die Grenzen von Single-Input-Systemen erkannten. Frühe KI-Modelle konnten nur Text oder nur Bilder verarbeiten. Bis 2023 änderten Durchbruch-Modelle wie GPT-4V und Googles Gemini alles.
Laut Google Research repräsentiert Multimodal AI "Modelle, die mehrere Arten von Input-Daten verarbeiten und darüber nachdenken können - einschließlich Text, Bilder, Audio und Video - in einer einzigen vereinheitlichten Architektur, die widerspiegelt, wie Menschen natürlich die Welt wahrnehmen und verstehen."
Der Durchbruch kam, als OpenAI im September 2023 GPT-4 mit Vision-Capabilities veröffentlichte, gefolgt von Googles Gemini im Dezember 2023 und Anthropics Claude 3 im März 2024, die jeweils demonstrierten, dass KI endlich die menschliche Fähigkeit erreichen konnte, mit gemischten Medien zu arbeiten.
Multimodal AI für Business Leaders
Für Business Leaders ist Multimodal AI wie einen Experten einzustellen, der Dokumente lesen, Charts interpretieren, Videos ansehen und Anrufe anhören kann - alles auf einmal - und dann Insights über alle Formate hinweg synthetisieren kann, die Ihr Business produziert.
Denken Sie an den Unterschied zwischen separaten Spezialisten für Text, Bilder und Audio versus einem Experten, der alle drei zusammen versteht. Der multimodale Experte sieht Muster, Verbindungen und Insights, die isoliert arbeitende Spezialisten verpassen würden.
Praktisch bedeutet das, dass Multimodal AI Kundenanrufe (Audio) analysieren, Produktbilder überprüfen, Support-Tickets (Text) lesen und Trends über alle Kanäle gleichzeitig identifizieren kann. Dies repräsentiert einen massiven Sprung über traditionelle Large Language Models hinaus, die nur Text bearbeiteten.
Kernkomponenten von Multimodal AI
Multimodal AI-Systeme bestehen aus diesen wesentlichen Elementen:
• Unified Encoder: Konvertiert verschiedene Datentypen - Text, Bilder, Audio, Video - in eine gemeinsame Repräsentation, die das Modell zusammen verarbeiten kann, wie ein universeller Übersetzer für Informationsformate
• Cross-Modal Attention: Mechanismus, der dem Modell ermöglicht, Beziehungen zwischen verschiedenen Inputtypen zu verstehen, wie das Verbinden gesprochener Worte in Audio mit Objekten in Bildern
• Shared Reasoning Layer: Gemeinsame Verarbeitungs-Engine, die über alle Inputtypen zusammen nachdenkt, echte Synthese statt separater Analyse ermöglichend
• Modal Adapters: Spezialisierte Komponenten, die die einzigartigen Eigenschaften jedes Inputtyps handhaben, während sie ins vereinheitlichte System einspeisen
• Output Generation: Fähigkeit, in mehreren Formaten zu antworten, von Text über Bilder bis zu strukturierten Daten, je nachdem, was den Use Case am besten bedient
Wie Multimodal AI funktioniert
Multimodal AI folgt diesem operativen Zyklus:
Simultaneous Ingestion: Modell empfängt Inputs über mehrere Formate - sagen wir, ein Produktbild, Customer Review-Text und Demo-Video - alles auf einmal
Unified Processing: Konvertiert alle Inputs in gemeinsame interne Repräsentationen, sodass das Modell Beziehungen über Modalitäten hinweg verstehen kann, wie das Bild mit schriftlichen Beschreibungen zusammenhängt
Cross-Modal Reasoning: Analysiert Muster und Insights, die mehrere Datentypen umspannen, wie das Bemerken, dass positive Audio-Stimmung mit spezifischen visuellen Produktmerkmalen korreliert
Dieser Zyklus setzt sich fort, wobei das Modell aus Feedback über alle Modalitäten lernt und geschickter darin wird zu verstehen, wie verschiedene Arten von Informationen zusammenhängen.
Typen von Multimodal AI-Systemen
Multimodal AI dient verschiedenen Business-Funktionen:
Typ 1: Vision-Language Models Am besten für: Document Understanding und Visual Analysis Schlüsselmerkmal: Kombinieren Text und Bilder nahtlos Beispiel: GPT-4V analysiert Charts und Reports
Typ 2: Audio-Visual Models Am besten für: Video-Analyse und Meeting Intelligence Schlüsselmerkmal: Verstehen Speech im Kontext von visuellem Inhalt Beispiel: Automatisierte Meeting-Zusammenfassungen mit Speaker Identification
Typ 3: Text-Image-Audio Systems Am besten für: Comprehensive Content Analysis Schlüsselmerkmal: Verarbeiten alle großen Medientypen zusammen mit Generative AI Beispiel: Google Gemini handhabt Mixed-Format-Queries
Typ 4: Sensor-Fusion Models Am besten für: IoT und Real-World Applications Schlüsselmerkmal: Kombinieren strukturierte Sensor-Daten mit Medien Beispiel: Manufacturing Quality Control mit Kameras und Messungen
Multimodal AI liefert Ergebnisse
So deployen Unternehmen Multimodal AI:
Healthcare-Beispiel: Siemens Healthineers nutzt Multimodal AI, um medizinische Bilder, Laborbefunde und klinische Notizen zusammen zu analysieren, reduziert diagnostische Zeit um 40 %, während Probleme erkannt werden, die Single-Modality-Systeme verpassten.
Retail-Beispiel: Amazons Produktsuche nutzt jetzt Multimodal AI, um Queries wie "zeig mir Schuhe wie auf diesem Foto, aber in Blau" zu verstehen, kombiniert Image Recognition mit Text Understanding, um 35 % genauere Ergebnisse zu liefern.
Financial Services-Beispiel: JPMorgan analysiert Earnings Calls mit Multimodal AI, die gesprochene Sprache, Präsentations-Slides und Finanzdokumente gleichzeitig verarbeitet, identifiziert Investment-Insights 50 % schneller als Analystteams.
Multimodal AI implementieren
Bereit, Ihre KI-Capabilities zu vereinheitlichen?
- Starten Sie mit Large Language Models Fundamentals
- Verstehen Sie Computer Vision Basics
- Lernen Sie über Natural Language Processing
- Erwägen Sie AI Orchestration für komplexe Workflows
FAQ Section
Häufig gestellte Fragen zu Multimodal AI
Was ist Multimodal AI?
Multimodal AI bezeichnet Modelle, die mehrere Arten von Input-Daten verarbeiten und darüber nachdenken können - einschließlich Text, Bilder, Audio und Video - in einer einzigen vereinheitlichten Architektur, ähnlich wie Menschen natürlich die Welt verstehen.
Was ist der Unterschied zwischen Multimodal AI und traditioneller KI?
Traditionelle KI-Modelle verarbeiten einen Datentyp (nur Text oder nur Bilder). Multimodal AI verarbeitet mehrere Datentypen gleichzeitig, versteht Beziehungen zwischen ihnen und generiert Insights über Formate hinweg.
Was sind die Haupttypen von Multimodal AI-Systemen?
Vision-Language Models (Text und Bilder), Audio-Visual Models (Speech und Video), Text-Image-Audio Systems (alle großen Medientypen) und Sensor-Fusion Models (strukturierte Daten plus Medien).
Was sind Beispiele für Multimodal AI-Modelle?
GPT-4V (OpenAI), Gemini (Google), Claude 3 (Anthropic) und spezialisierte Modelle wie CLIP (Image-Text), Whisper (Audio) und ImageBind (alle Modalitäten).
Verwandte Ressourcen
Erkunden Sie diese verwandten Konzepte, um Ihr Verständnis von Multimodal AI zu vertiefen:
- Computer Vision - Wie KI Bilder verarbeitet und versteht
- Neural Networks - Die fundamentale Architektur hinter multimodalen Systemen
- Transformer Architecture - Die technische Grundlage hinter modernen multimodalen Modellen
- Embeddings - Wie verschiedene Datentypen in gemeinsame Repräsentationen konvertiert werden
Externe Ressourcen
- Google Research - Multimodal AI - Neueste Fortschritte in vereinheitlichten KI-Modellen
- Meta AI - Vision and Language - Forschung zu Cross-Modal Understanding
- Microsoft Research - Multimodal Systems - Enterprise Multimodal Applications
Teil der AI Terms Collection. Zuletzt aktualisiert: 2026-02-09

Co-Founder, Rework.com