Supervised Learningとは?例から学ぶAI
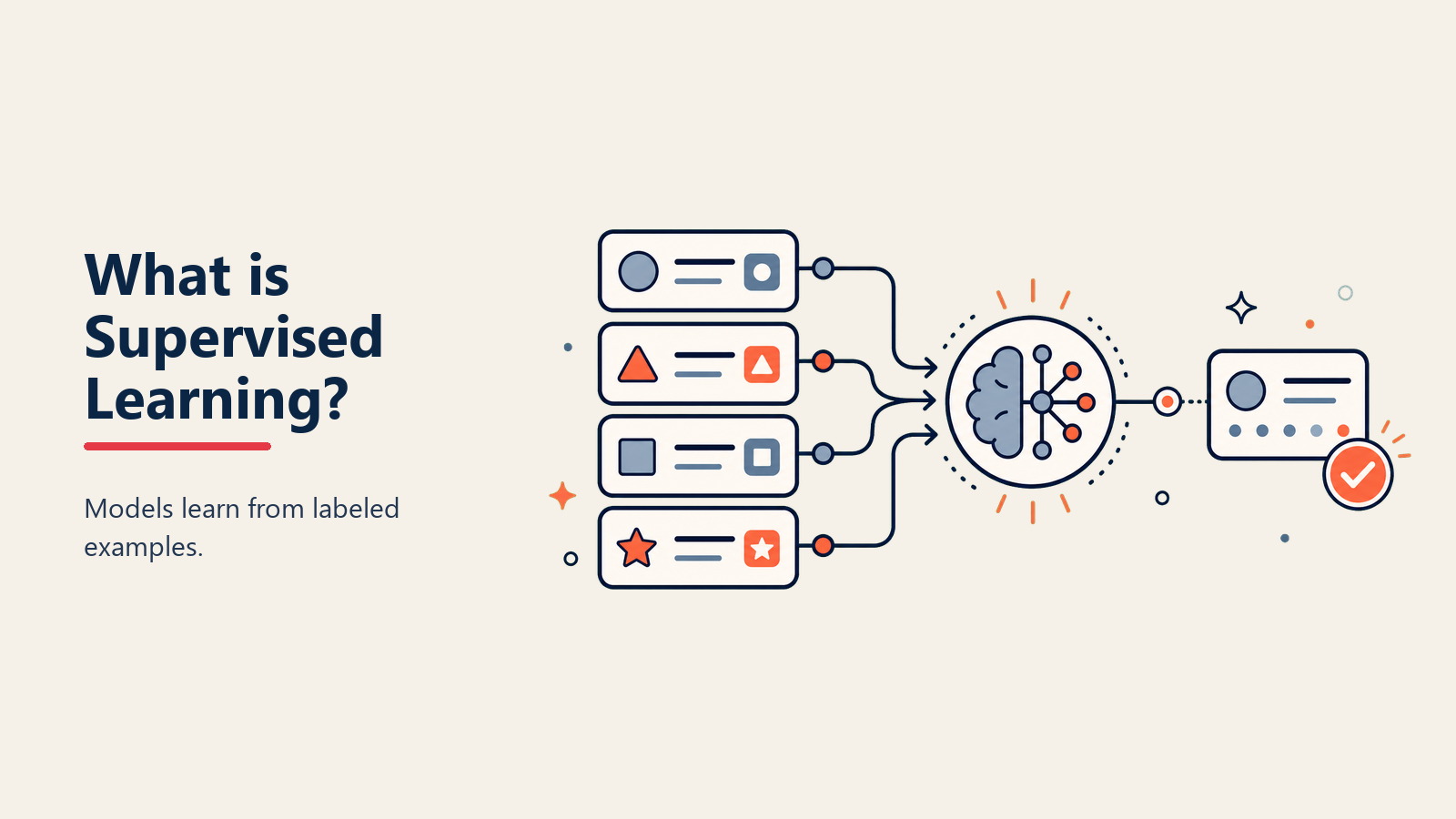 新しい従業員に何千もの例を示して教えることを想像してください:「これは良い顧客、これはリスクのある顧客」。それがSupervised Learningです:最も実用的で広く使用されているmachine learningの形式であり、ラベル付きの例から学習することで、Spamフィルターから医療診断まで、すべてを強化します。
新しい従業員に何千もの例を示して教えることを想像してください:「これは良い顧客、これはリスクのある顧客」。それがSupervised Learningです:最も実用的で広く使用されているmachine learningの形式であり、ラベル付きの例から学習することで、Spamフィルターから医療診断まで、すべてを強化します。
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
起源と定義
Supervised Learningの基盤は、1960年代の統計的パターン認識にさかのぼります。「Supervised」という用語は、Unsupervised手法と区別するために作られ、トレーニング中に正しい答えを提供する「教師」の存在を強調しています。
Tom Mitchellの基礎的定義によると、Supervised Learningは「アルゴリズムが、例示的な入力-出力ペアに基づいて、入力を出力にマッピングする関数を学習する」ときに発生します。Supervisionは、各トレーニング例の正しい答えを知っていることから来ています。
このアプローチは、1990年代のデジタルデータの台頭とともに実用的な重要性を獲得し、企業が実世界のアプリケーションのために効果的なモデルをトレーニングするのに十分なラベル付きの例を蓄積したときです。
ビジネスにとっての意味
ビジネスリーダーにとって、Supervised Learningは、結果がすでにわかっている履歴データを使用してAIシステムをトレーニングし、過去の例に基づいて将来の結果を予測するようにマシンに教えることを意味します。
大規模な見習いトレーニングと考えてください。信用アナリストに、「デフォルト」または「返済」とラベル付けされた何千もの過去のローン申請を示してトレーニングするのと同じように、Supervised LearningはAIをトレーニングしてパターンを認識し、新しい申請について同様の決定を行います。
実用的には、これは、履歴の例がある任意のビジネスプロセスに対して自動化された意思決定を可能にします:ローンの承認、詐欺の検出、売上の予測、または顧客Churnリスクの特定。
必須コンポーネント
Supervised Learningは、これらの必須要素で構成されています:
• **トレーニングデータ:**詐欺/正当とラベル付けされた過去の取引、Churn/残留した顧客、成功/失敗した製品など、既知の結果を持つ履歴例
• **Features:**結果を予測する可能性のある入力変数。顧客Churnの場合:使用パターン、サポートTicket、支払い履歴、Engagement Metrics
• **ラベル:**トレーニング例の既知の正しい答え、モデルが予測すべきものを示す「Supervised」部分
• **アルゴリズム:**解釈可能性のためのDecision Tree、複雑性のためのneural networks、連続値のためのRegressionなど、パターンを見つける数学的方法
• **モデル:**学習されたパターン抽出器、新しい、未見の例のラベルを予測できる数学的関数
トレーニングプロセス
Supervised Learningプロセスは、次のステップに従います:
**データ準備:**既知の結果を持つ履歴例を収集し、関連するFeaturesを選択し、ラベルが正確であることを確認します。成功に影響を与えた要因を持つ過去の売上データを収集するようなものです
**トレーニングフェーズ:**アルゴリズムは例を分析してFeaturesとラベルをリンクするパターンを見つけます。最初の月に3回以上サポートに連絡した顧客が70%のChurn率を持つことを発見します
**予測フェーズ:**トレーニング済みモデルをラベルのない新しいデータに適用し、学習したパターンを使用して結果を予測します。行動パターンに基づいてChurnする可能性の高い現在の顧客にフラグを付けます
重要なのは、本番環境でモデルが遭遇するシナリオの全範囲を代表する十分な品質の例を持つことです。
2つの主要なタイプ
Supervised Learningは一般的に2つの主要なカテゴリに分類されます:
タイプ1:Classification 最適:詐欺/正当、Churn/維持、購入/非購入などのグループへの分類 主な機能:離散的なカテゴリーまたはクラスを予測 例:Spam/Not Spamとマークされたメッセージから学習するEmailSpamフィルター
タイプ2:Regression 最適:価格、スコア、数量などの数値の予測 主な機能:連続的な数値予測を出力 例:サイズ、場所、Featuresに基づく住宅価格予測
一般的なアルゴリズム:
- **線形モデル:**シンプル、解釈可能、高速、明確な関係に適している
- **Treeベース:**非線形パターンを処理し、Feature重要度を提供
- **Neural Networks:**複雑なパターンだが、より多くのデータが必要(deep learningを参照)
- **Support Vector Machines:**高次元データに効果的
Supervised Learningの実例
ビジネスが実際にSupervised Learningを使用する方法は次のとおりです:
**銀行の例:**American ExpressはSupervised Learningを詐欺検出に使用し、数百万のラベル付き取引でトレーニングしてanomaly detectionを通じて疑わしいパターンを識別し、偽陽性を50%削減しながら、詐欺の90%を捕捉します。
**小売の例:**Targetの需要予測は、履歴売上、天候、プロモーションデータでトレーニングされたSupervised Learningを使用して、製品需要のpredictive analyticsを強化し、過剰在庫を30%削減します。
**ヘルスケアの例:**Mount Sinai Hospitalは患者記録でトレーニングされたSupervised Learningを使用して、6ヶ月早く84%の精度で疾患の発症を予測し、予防的介入を可能にします。
外部リソース
Supervised Learningに関する権威あるリソースを探索:
- Google's Machine Learning Crash Course - Supervised Learningへの無料包括的ガイド
- Scikit-learn Documentation - Supervised Learningアルゴリズムの実用的な実装
- Stanford CS229: Machine Learning - Supervised Learning理論の基礎コース資料
さらに学ぶ
AI学習方法と関連概念の理解を深める:
- Unsupervised Learning - ラベル付きデータなしでパターンを発見
- Reinforcement Learning - 試行と報酬を通じて決定を最適化
- Transfer Learning - あるタスクから別のタスクへ知識を適用
- MLOps - 本番環境でMachine Learningモデルを展開および管理
FAQ
Supervised Learningに関するよくある質問
Supervised Learningとは何ですか?
Supervised Learningは、AIがラベル付きの例(入力-出力ペア)から学習して、新しい、未見のデータの結果を予測するMachine Learningアプローチです。
Supervised LearningでのClassificationとRegressionの違いは何ですか?
Classificationは離散的なカテゴリーを予測します(Spam/Not Spam、詐欺/正当)。Regressionは連続的な数値を予測します(価格、温度、スコア)。
Supervised Learningの主要コンポーネントは何ですか?
トレーニングデータ(履歴例)、Features(入力変数)、ラベル(既知の正しい答え)、アルゴリズム(パターン発見方法)、モデル(学習された予測器)です。
Supervised Learningで使用されるアルゴリズムの種類は何ですか?
線形モデル(シンプル、解釈可能)、Treeベース(非線形パターンを処理)、Neural Networks(複雑なパターン)、Support Vector Machines(高次元データ)があります。
[AI Terms Collection]の一部。最終更新:2026-01-10

Co-Founder, Rework.com