Meta-Learningとは?数ヶ月ではなく数分で新しいスキルを習得するAIの構築
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AIプロジェクトの87%が、モデルが新しいシナリオに十分速く適応できないために失敗しています。しかし、AIがわずか数例で新しいタスクを学習できるとしたらどうでしょうか?それはSFではありません - それがMeta-learningであり、企業がAIを展開する方法を変革しています。
Meta-Learning:究極の効率化手法
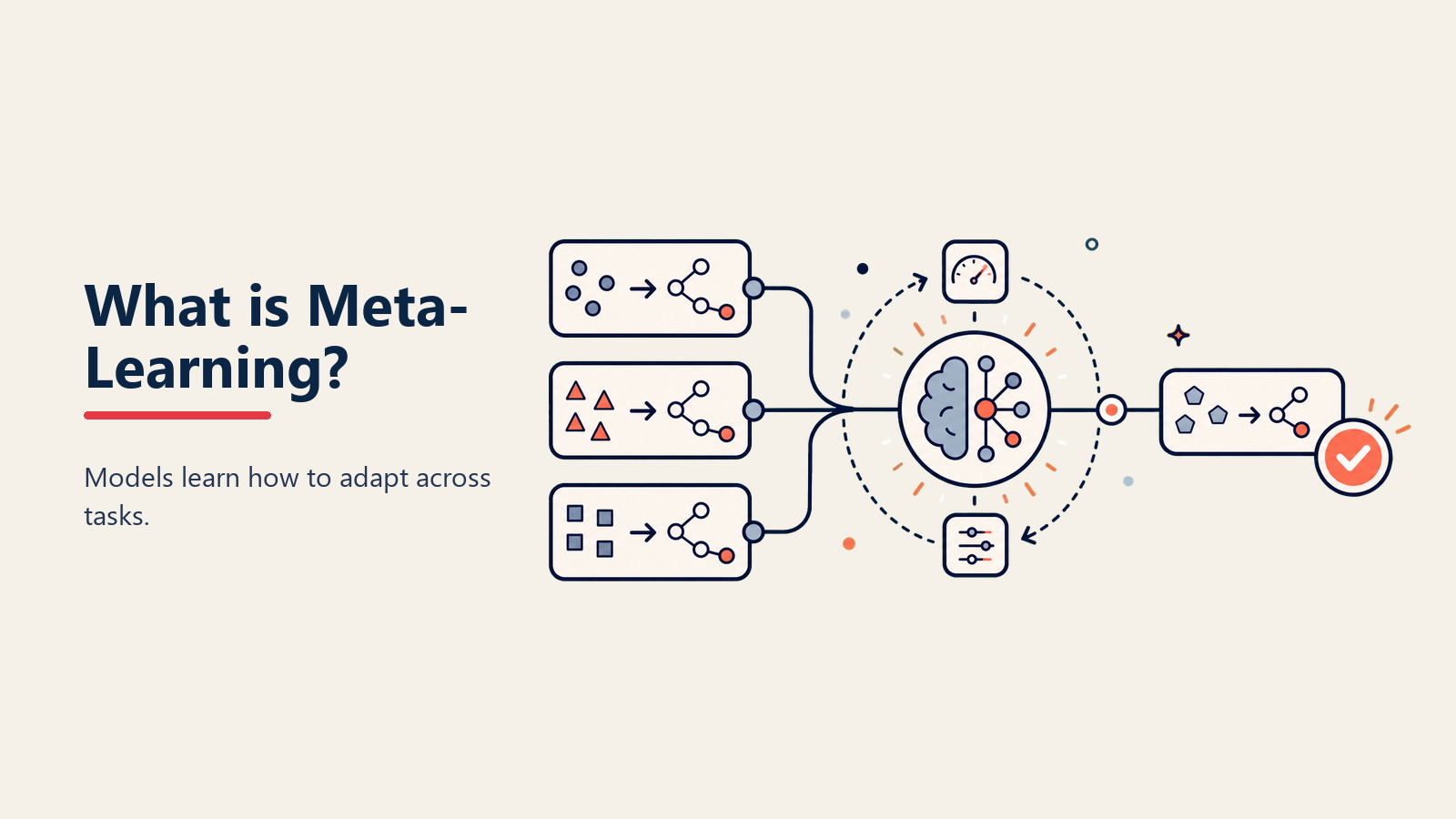
簡単に言えば:Meta-learningは学習方法を学ぶAIであり、最小限のトレーニングデータで新しいタスクに適応します。
こう考えてみてください:従来のMachine Learningは、すべての単一タスクのためにゼロから新しい従業員をトレーニングするようなものです。Meta-learningは、学習スキル自体をマスターした人を雇うようなものです - いくつかの例を示せば、残りは自分で理解します。
現代のビジネスにとって、これは数ヶ月の再トレーニングなしに、新しい製品、市場、または顧客行動に適応できるAIシステムを意味します。それは、硬直した自動化と真に知的なシステムとの違いです。
Meta-Learningの実際の動作
Meta-learningは見事にシンプルな原理で動作します。まず、学習自体のパターンを理解するために、多くの異なるタスクでトレーニングします。何百ものビジネスを見てきたベテランコンサルタントのように、異なる問題に共通するパターンを認識します。
次に、新しいタスクに直面したとき、システムはこれらのメタパターンを適用します。「これはどんな種類の問題か?類似の課題にどの学習戦略が効果的だったか?」と問います。
これが強力なのは、適応のスピードです。従来のMLが数千の例を必要とするかもしれない一方で、Meta-learningは5-10のサンプルで動作できます。これは、稀なイベント、新製品、またはニッチ市場を扱う企業にとってゲームチェンジャーです。
Meta-Learningの2つのタイプ
ほとんどの企業は、最適化ベースまたはメトリックベースのアプローチのいずれかを使用しています。
最適化ベースのMeta-learning(MAML - Model-Agnostic Meta-Learningなど)は、真の汎化が必要な場合に最適です。あらゆるタスクに素早く特化できるスイスアーミーナイフAIを作成するようなものです。金融企業は、新しい詐欺スキームを識別するためのAnomaly Detectionの適応にこれを使用しています。
メトリックベースのMeta-learning(Prototypical Networksなど)は、迅速な分類が必要な場合に輝きます。Deep Learningアーキテクチャを基盤とした、ステロイド版のパターンマッチングと考えてください。Eコマース企業は、わずか数例に基づいて新製品を分類するためにこれを使用しています。
Meta-Learningの実践
製薬会社が創薬のためにMeta-learningを実装しました。数千の分子相互作用でトレーニングした後、彼らのAIはわずか10-20のテスト結果で新しい薬物の動作を予測できました。初期スクリーニングの開発時間は18ヶ月から3ヶ月に短縮されました。
一方、カスタマーサービスプラットフォームは、新しいクライアントのオンボーディングを処理するためにMeta-learningを使用しました。各クライアントの独自の製品に対して別々のConversational AIチャットボットをトレーニングする代わりに、1つのMeta-learningシステムを構築しました。新しいクライアントは数週間ではなく数日で運用可能になりました。
ビジネスへの影響
迅速な展開: AIソリューションを10倍速く立ち上げ
- 新製品レコメンデーション:2日 vs 3週間
- 顧客セグメントモデリング:1週間 vs 2ヶ月
- 新部品の品質検査:当日 vs 1ヶ月
コスト削減: AI開発コストを75%削減
- 必要なデータアノテーションが少ない
- モデルトレーニングサイクルが少ない
- クラウドコンピューティング費用の削減
競争優位性: 競合他社より速く適応
- AI機能で市場に最初に参入
- 市場の変化に基づく迅速なピボット
- 大規模なパーソナライゼーション
Meta-Learningが意味をなすとき
1,000人の顧客がいて、それぞれがわずかに異なるニーズを持っていると想像してください。1,000の別々のモデルをトレーニング?不可能です。1つの汎用モデル?不正確すぎます。これがMeta-learningが輝く場面です。
または、ビジネスが月に50の新製品を立ち上げるとします。従来のAIは各製品に対して広範なトレーニングデータを必要とします。Meta-learningは初期の販売データだけで新製品に適応します。
実装ブループリント
フェーズ1:基盤(1ヶ月目) 限られたデータながら共通の基本パターンを持つタスクを特定することから始めます。異なるセグメント全体での顧客離脱。さまざまなライン全体での製品欠陥。これらは完璧なMeta-learning候補です。
フェーズ2:パイロット(2-3ヶ月目) 高い影響力で低リスクの領域を1つ選択します。多くはPredictive Analyticsを使用したレコメンデーションシステムから始めます - 最悪のケースは少しずれた提案で、ビジネスクリティカルな失敗ではありません。
フェーズ3:スケール(4ヶ月目以降) 証明されたら、コアビジネスプロセスに拡大します。MLOpsプラクティスを活用して、同じMeta-learningインフラストラクチャが複数のアプリケーションを動かし、ROIを最大化できるようにします。
Meta-Learningのためのツール
研究グレードのフレームワーク:
- learn2learn(無料、PyTorchベース)
- Meta-Dataset by Google(無料、TensorFlow)
- Reptile by OpenAI(無料、フレームワーク非依存)
ビジネス対応プラットフォーム:
- Amazon SageMaker with Few-shot Learning(トレーニング$0.05/時間)
- Google Vertex AI with AutoML(トレーニング$20/時間)
- H2O.ai with Meta-learningモジュール(エンタープライズ価格)
専門ソリューション:
- Snorkel.ai for Weak Supervision(カスタム価格)
- Obviously.ai for No-code Meta-learning($75/月)
一般的な課題と解決策
課題1:タスクの多様性 Meta-learningは、タスクが基本的な構造を共有している場合に最適に機能します。大きく異なるタスクはシステムを混乱させます。 解決策: 類似のタスクをグループ化します。異なるドメインに対して別々のMeta-learnerを作成します。
課題2:評価の複雑さ 「学習方法を学ぶ」ことをどう測定しますか?従来のメトリックは不十分です。 解決策: Few-shot精度メトリックと適応速度ベンチマークを使用します。
Meta-Learningの利点
見てください、Meta-learningは魔法ではありません。しかし、すべてのビジネスバリエーションに対して新しいモデルをトレーニングすることにうんざりしているなら、探求する価値があります。
小さく始めましょう:複数のバリエーションがあるが、各バリエーションに対するデータが限られている1つのプロセスを特定します。次に、Few-shot Learningに飛び込んで基礎を理解します。Transfer Learningに関するガイドも、モデル適応のための関連技術を示しています。
さらに詳しく
理解を深めるために、これらの関連AI概念を探索してください:
- Neural Networks - Meta-learningシステムを動かす基盤アーキテクチャ
- Model Optimization - Meta-learningパフォーマンスを向上させる技術
- Fine-tuning - Meta-learningが改善するモデル適応への従来のアプローチ
外部リソース
- Google Research - Meta-Learning - Learning-to-learnアルゴリズムに関する最新の研究
- Meta AI Research - Few-shot Learningとモデル適応の進歩
- Microsoft Research - Few-Shot Learning - Meta-learningの実用的な応用
Meta-Learningに関するよくある質問
Meta-Learningとは何ですか?
Meta-learningは学習方法を学ぶAIであり、多くの異なるタスク全体で学習自体のパターンを理解することで、最小限のトレーニングデータで新しいタスクに適応します。
Meta-Learningと従来のMachine Learningの違いは何ですか?
従来のMLは各特定のタスクに対してゼロからモデルをトレーニングします。Meta-learningは、わずか数例を使用して新しいタスクに素早く適応できるシステムをトレーニングし、学習スキル自体をマスターした人を雇うようなものです。
Meta-Learningへの2つの主なアプローチは何ですか?
真の汎化のための適応可能なモデルを作成する最適化ベースのMeta-learning(MAMLなど)と、高度なパターンマッチングによる迅速な分類に優れるメトリックベースのMeta-learning(Prototypical Networksなど)です。
Meta-Learningが最も意味をなすのはいつですか?
それぞれが限られたデータを持つ複数の類似タスクがある場合 - 異なるニーズを持つ1,000人の顧客、月に50の新製品の立ち上げ、または異なるセグメント全体での顧客離脱の処理など。
Meta-Learningの主なビジネス上の利点は何ですか?
迅速な展開(AIソリューションを10倍速く立ち上げ)、コスト削減(AI開発コストを75%削減)、競争優位性(市場の変化に競合他社より速く適応)です。
[AI Terms Collection]の一部。最終更新:2026-07-21
