Clusteringとは?データに隠された部族を発見する
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
企業の87%が顧客セグメンテーションを間違っています。年齢、収入、場所などの基本的な人口統計を使用していますが、本当の金鉱は行動パターンにあります。そこでClusteringの登場です。データの自然なグループを見つけるAIで、存在を知らなかったセグメントを明らかにします。「日曜日の朝のヨーグルト購入者」が最も収益性の高いセグメントであることを発見した小売業者のようなものです。
Clusteringを理解する
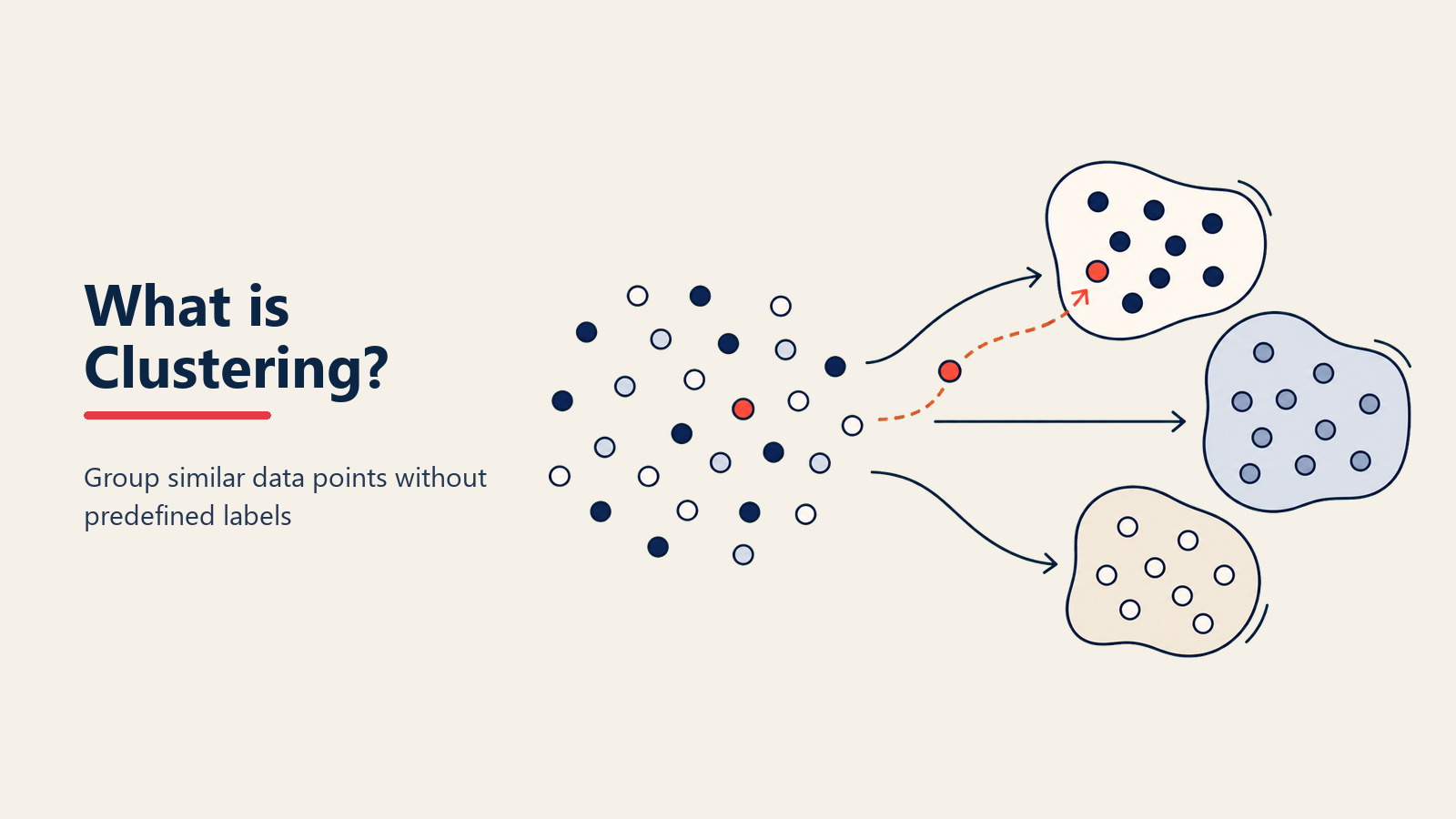
パーティーで人々が自然にグループを形成する様子を知っていますか?スポーツファンが集まり、親が互いを見つけ、技術者がコーナーに集まります。Clusteringアルゴリズムはデータで同じことを行います - 何を探すべきか指示されることなく、自然なグループを見つけます。
より技術的には、Clusteringは特性に基づいて類似のデータポイントをグループ化する教師なし機械学習技術です。分類(ラベルが必要)とは異なり、Clusteringは独自にパターンを発見します。
重要な違いは発見 vs. 予測です。教師あり学習分類は、高価値が何を意味するかすでに知っているときに「この顧客は高価値ですか?」と尋ねます。Clusteringは「どんな種類の顧客がいますか?」と尋ね、データに答えを明らかにさせます。
Clusteringの実際の動作
Clusteringは類似性を測定することで動作します。まず、各データポイントを数学的空間で表現 - 顧客年齢が1次元、購入頻度が別の次元、平均注文額が3番目。多次元マップにポイントをプロットするようなものです。
次に、アルゴリズムがすべてのポイント間の距離を計算します。類似のアイテムは近くにあり、異なるアイテムは遠くにあります。高級品購入者と予算買い物客は、同じ年齢と場所であっても遠く離れているかもしれません。
最後に、近接性に基づいてグループが形成されます。アルゴリズムは類似のポイントの密集領域の周りに境界を描きます。2つだと思っていたところに、5つの異なる顧客セグメントを発見するかもしれません。
魔法は「類似性」を定義することで起こります - 現代の機械学習アルゴリズムは、人間が視覚化できない数百の次元と複雑な関係を処理できます。
実世界のClustering応用
小売顧客セグメンテーション ファッション小売業者が購入履歴、閲覧行動、返品パターンにClusteringを適用。「トレンドフォロワー」(発売直後に購入)と「セールハンター」(割引品のみ購入)を含む7つのセグメントを発見。各セグメントへのパーソナライズされたマーケティングで収益が34%増加。
医療患者グループ 病院が従来のリスク要因を超えて患者データをClustering。治療に異なる反応を示すサブグループを発見。1つの糖尿病クラスターは、薬物療法よりもライフスタイル介入に3倍良く反応。治療のパーソナライゼーションで結果が40%改善。
財務リスク評価 銀行が財務指標、業界データ、トランザクションパターンを使用して中小企業ローン申請者をClustering。従来のスコアリングが見逃したリスククラスターを特定。デフォルト率が25%減少し、承認率が15%増加。
サプライチェーン最適化 メーカーが配送パフォーマンス、品質指標、コミュニケーションパターンによってサプライヤーをClustering。隠れた信頼性パターンを明らかに。サプライヤー関係を再構築し、遅延を30%削減。
Clusteringアルゴリズムのタイプ
K-Means Clustering Clusteringの主力。必要なクラスター数を指定すると、最適なグループを見つけます。明確で重複しないグループが必要な顧客セグメンテーションに最適。高速でスケーラブル。
階層的Clustering クラスターのツリーを構築 - 企業を部門からチームから個人へと組織するようなものです。異なるレベルの粒度が必要な場合に最適。小売チェーンが店舗グループにこれを使用。
DBSCAN(密度ベース) 任意の形状のクラスターを見つけ、外れ値を特定します。不正検出と異常検知に優れています - 通常のトランザクションはクラスター化し、不正なものは外れ値として際立ちます。
ガウス混合モデル データが複数の統計分布から来ると仮定します。洗練されていますが強力。製造で生産の異なる品質状態を特定するために使用されます。
Clusteringの違い
Clustering前: マーケティングが「25-34歳の女性」に同じキャンペーンを送信 Clustering後: 5つの異なるセグメントを特定:
- キャリア重視の専門家(効率メッセージに反応)
- 新米ママ(安全性と利便性を重視)
- フィットネス愛好家(パフォーマンス機能を求める)
- 予算重視の学生(価格に敏感)
- エコ意識の高い購入者(持続可能性が重要)
結果:クリック率が250%増加。同じオーディエンス、よりスマートなセグメンテーション。
Clusteringが意味を持つ時
何千もの製品があるが、どのように整理すればよいかわからないと想像してください。従来のカテゴリー(電子機器、衣類)は広すぎます。Clusteringは、顧客が実際にどのように買い物をするかに基づいて自然なグループを明らかにします - 「つかんで行く必需品」または「リサーチが多い購入」。
または、新しい市場に参入しているとします。まだ顧客セグメントがわかりません。Clusteringが早期採用者を分析し、ターゲットにする明確なユーザータイプを明らかにします。
実装ロードマップ
週1:データ準備
- 関連機能を収集(行動 > 人口統計)
- 適切なデータキュレーションでデータをクリーンアップして正規化(Clusteringに重要)
- 明らかな外れ値を削除
- 派生機能を作成(比率、頻度)
週2:探索
- 複数のアルゴリズムを試す
- 異なる数のクラスターで実験
- 結果がビジネス的に意味をなすか検証
- グループについてステークホルダーの意見を得る
週3-4:検証
- 時間経過でのクラスターの安定性をテスト
- クラスターが実行可能であることを確認
- クラスターごとのビジネス指標を計算
- クラスター固有の戦略を設計
月2以降:運用化
- MLOpsプラクティスを通じて新しいデータの自動クラスター割り当て
- 監視Dashboardを作成
- クラスター固有の治療を開発
- インパクトを測定し改良
Clusteringのためのツール
ノーコードソリューション:
- Tableau - 組み込みClustering($70/ユーザー/月)
- Microsoft Power BI - 自動Clustering機能($10/ユーザー/月)
- Google Analytics 4 - オーディエンス発見(制限付き無料)
Pythonライブラリ(無料):
- scikit-learn - すべての主要アルゴリズム
- HDBSCAN - 高度な密度Clustering
- pyclustering - 専門アルゴリズム
エンタープライズプラットフォーム:
- SAS Enterprise Miner - 完全Clusteringスイート(カスタム価格)
- IBM SPSS Modeler - ビジュアルClustering($99/ユーザー/月)
- DataRobot - 自動化Clustering($75K+/年)
クラウドサービス:
- AWS SageMaker - 組み込みClustering($0.05/時)
- Google Vertex AI - AutoML Clustering($20/時)
- Azure ML - Clusteringモジュール($9.90/計算時間)
一般的なClusteringの落とし穴
落とし穴1:間違ったクラスター数を強制 CEOは競合が5つあるため5つの顧客セグメントを望む。データは明らかに3つまたは8つの自然なグループを示しています。 解決策: データにクラスター数をガイドさせる。エルボープロットとシルエットスコアを使用。ビジネスロジックは改良すべきで、定義すべきではありません。
落とし穴2:間違った機能を使用 購入行動がライフスタイルと価値観によってより変化するのに、年齢と収入で顧客をClustering。 解決策: 行動的およびトランザクション的機能に焦点を当てる。人口統計は脇役であり、主役ではありません。
落とし穴3:クラスターの進化を無視 2019年に定義された顧客セグメント、更新されていない。COVIDがすべてを変えました。 解決策: 四半期ごとまたは主要なイベントが発生したときに再Clustering。クラスタードリフトを追跡するためにモデル監視を実装。
高度なClustering戦略
マルチビューClustering 異なるデータの視点を組み合わせる。顧客を購入行動ANDサポートインタラクションAND Webサイトアクティビティでクラスター化。より豊かなセグメントを明らかに。
半教師ありClustering いくつかの既知のラベルを組み込んでClusteringをガイド。「これらがVIP顧客であることがわかっています、類似のグループを見つけてください。」発見とビジネス知識のバランスを取ります。
動的Clustering 時間とともに進化するクラスター。顧客がセグメント間をどのように移動するかを追跡。時系列分析を使用してセグメント遷移を予測。プロアクティブな介入を可能にします。
Clusteringの成功を測定する
技術的指標:
- シルエット係数(クラスター分離)
- Davies-Bouldinインデックス(クラスターコンパクトネス)
- Calinski-Harabaszスコア(クラスター定義)
ビジネス指標:
- クラスターあたりの収益
- クラスター別マーケティング反応率
- クラスター間の定着率の違い
- クラスターあたりの運用コスト
実行可能性テスト: クラスターごとに異なる戦略を作成できますか?すべてのクラスターが同じ治療を受ける場合、Clusteringは失敗しました。
業界固有のClustering
E-commerce:
- 製品親和性グループ
- ショッピング行動セグメント
- 季節的購入者クラスター
- 価格感度グループ
B2B:
- アカウントセグメンテーション
- 使用パターングループ
- 予測分析で強化された成長可能性クラスター
- リスクプロファイルセグメント
医療:
- 患者リスクグループ
- 治療反応クラスター
- リソース利用セグメント
- 結果予測グループ
Clusteringをあなたのために機能させる
Clusteringは魔法ではありません。しかし、すべての顧客を同じように扱っているなら、お金をテーブルに残しています。
小さく始めましょう:購入行動でトップ1000顧客をクラスター化。想像もしなかったセグメントを見つけるでしょう。
さらに学ぶ
Clusteringとデータ駆動型発見の理解を深めるために関連概念を探索:
- 教師なし学習 - ラベルなしでパターンを発見するML技術の広いカテゴリー
- ディープラーニング - 複雑なClusteringタスクのための高度なニューラルアプローチ
- ニューラルネットワーク - 現代のClusteringアルゴリズムを支える基盤アーキテクチャ
- Business Intelligence - Clusteringインサイトが戦略的意思決定にどのように供給されるか
外部リソース
- Stanford HAI: Clustering Research - Clusteringアルゴリズムの学術研究
- Scikit-learn Clustering Guide - 実用的な実装ドキュメント
- Papers With Code: Clustering - 最新のClustering技術とベンチマーク
FAQセクション
Clusteringに関するよくある質問
Clusteringとは何ですか?
Clusteringは、特性に基づいて類似のデータポイントをグループ化する教師なし機械学習技術で、何を探すべきか指示されることなく自然なパターンを発見します。
Clusteringと分類の違いは何ですか?
分類は、どのカテゴリーが存在するかすでに知っているときにカテゴリーを予測します。Clusteringは、事前定義されたラベルやカテゴリーなしでデータの未知のグループを発見します。
4つの主要なClusteringアルゴリズムのタイプは何ですか?
K-Means(クラスター数を指定)、階層的(クラスターのツリーを構築)、DBSCAN(任意の形状と外れ値を見つける)、ガウス混合モデル(統計分布を仮定)。
ビジネスにおけるClusteringの主な利点は何ですか?
隠れた顧客セグメントの発見、パーソナライゼーションの改善、より良い市場理解、リソース最適化、従来のセグメンテーションが見逃すパターンの特定。
Clustering実装における一般的な落とし穴は何ですか?
間違ったクラスター数を強制(データにガイドさせる)、間違った機能を使用(人口統計より行動に焦点)、クラスターの進化を無視(セグメントは時間とともに変化)。
[AIターム集]の一部。最終更新:2026-07-21
