Transformer Architectureとは?AIを永遠に変えた設計図
 2017年以前、AIは長いドキュメントに苦労し、文脈を迅速に失いました。次にTransformerが登場しました - ChatGPT、BERT、そして現代AIにおける実質的にすべてのブレークスルーの背後にあるアーキテクチャです。この革新を理解することは、今日のgenerative AIがなぜ強力であり、ビジネスにとって何が可能かを理解するのに役立ちます。
2017年以前、AIは長いドキュメントに苦労し、文脈を迅速に失いました。次にTransformerが登場しました - ChatGPT、BERT、そして現代AIにおける実質的にすべてのブレークスルーの背後にあるアーキテクチャです。この革新を理解することは、今日のgenerative AIがなぜ強力であり、ビジネスにとって何が可能かを理解するのに役立ちます。
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
技術的ブレークスルー
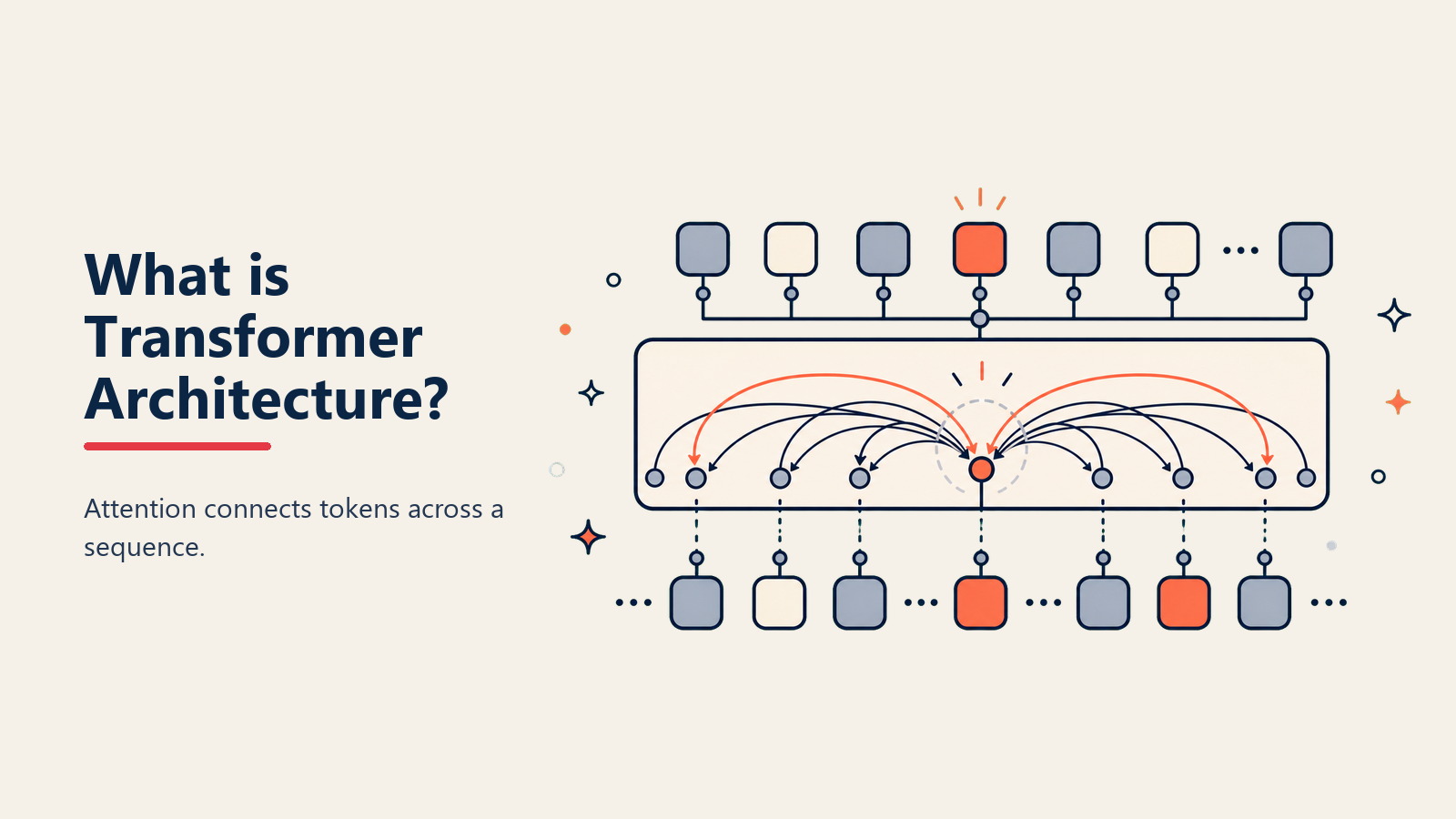
TransformerはGoogleの研究者による画期的な論文「Attention Is All You Need」(2017年)で導入されたneural network Architectureです。単語ごとではなくシーケンス全体を同時に処理し、self-attentionと呼ばれるメカニズムを使用して、入力のすべての部分間の関係性を理解することで、AIを革命的に変えました。
元の論文によると、「Transformerは再帰と畳み込みを完全に排除し、入力と出力間のグローバル依存関係を描くためにAttentionメカニズムのみに依存しています」。この並列処理により、品質を向上させながらトレーニングが100倍速くなりました。
Architectureの効率性と有効性は、私たちが経験しているAIルネッサンスにつながり、これまでにないほど文脈を理解する数十億のParametersを持つモデルを可能にしました。
ビジネスへの影響
ビジネスリーダーにとって、Transformer Architectureは、現代AIが契約書全体を読み、長い会話で文脈を維持し、一貫性のあるレポートを生成できる理由です - AIを複雑なビジネスタスクに真に有用にした工学的ブレークスルーです。
以前のAIを鍵穴を通して本を読む誰かのように考えてください。一度に1語を見て、以前の部分を忘れます。Transformerは、ページ全体を一度に読み、すべての単語が他のすべての単語とどのように関連しているかを瞬時に理解するようなものです。
実用的には、Transformerは会話全体を覚えているカスタマーサービスBot、複雑な関係性を理解する文書分析、ページ全体で一貫性を維持するコンテンツ生成を可能にします。
コアコンポーネント
Transformerは主要な革新で構成されています:
• **Self-Attentionメカニズム:**すべての単語が他のすべての単語に「Attend」できるようにし、以前の名詞を参照する代名詞などの関係性を理解
• **Positional Encoding:**Transformerはすべての単語を順次ではなく同時に処理するため、単語順序に関する情報を追加
• **Multi-Head Attention:**並行して実行される複数のAttentionメカニズム、それぞれが異なる種類の関係性を学習
• **Feed-Forward Networks:**Attendedした情報を処理して意味を抽出し、出力を生成
• **レイヤースタッキング:**深くスタックされた複数のTransformer Block、それぞれが段階的に理解を洗練
Transformerの仕組み
Transformerプロセスの簡略化:
**入力エンコーディング:**テキストがシーケンス順序を保持するために位置情報が追加されたembeddingsに変換
**Self-Attention計算:**すべてのTokenが他のすべてのTokenとの関係を計算し、Attention重みを作成
**Context統合:**Attention重みが各位置の入力の関連部分からの情報を組み合わせる
**レイヤー処理:**複数のレイヤーが理解を洗練し、各レイヤーが以前の洞察に基づいて構築
**出力生成:**Classification、翻訳、テキスト生成などのタスクに使用される最終表現
この並列処理が、Transformerがより速くトレーニングし、よりよくスケールする理由です。
Transformerバリアント
異なるニーズに対する異なる設計:
BERT(Bidirectional) 焦点:両方向からの文脈理解 最適:検索、Classification、質問応答 例:Google Search理解
GPT(Autoregressive) 焦点:左から右へテキスト生成 最適:コンテンツ作成、会話 例:ChatGPT、執筆アシスタント
T5(Text-to-Text) 焦点:すべてのタスクをテキスト生成としてフレーム化 最適:汎用アプリケーション 例:翻訳、要約
Vision Transformer(ViT) 焦点:画像へのTransformerの適用 最適:Computer visionタスク 例:画像Classification、医療画像
ビジネスアプリケーション
Transformerがソリューションを強化:
**法律技術の例:**法律事務所はBERTベースのシステムを使用して契約書を分析し、キーワード検索が見逃す文脈を理解して、100ページのドキュメント全体で関連する条項を数秒で見つけ、レビュー時間を90%削減します。
**ヘルスケアの例:**GoogleのMed-PaLM 2(Transformerベース)は、複雑な医療文脈を理解することでエキスパートレベルの医療試験パフォーマンスを達成し、診断と治療計画のためのAI支援を可能にします。
**金融の例:**JPMorganのDocAIはTransformerを使用して何百万もの金融文書を処理し、ページ全体の文脈を理解して取引決定とリスク評価を推進する洞察を抽出します。
Transformerが支配する理由
採用を推進する主な利点:
並列化:
- シーケンス全体を同時に処理
- RNNよりも100倍速いトレーニング
- ハードウェアで効率的にスケール
長距離依存関係:
- 何千ものTokenにわたって文脈を維持
- ドキュメントレベルの関係性を理解
- 複雑な推論タスクを処理
- 一度事前トレーニング、多くのタスクのためにFine-tune
- データ要件を劇的に削減
- 迅速な展開を可能に
汎用性:
- テキスト、画像、オーディオ、コードに機能
- 同じArchitecture、異なるアプリケーション
- AIへの統一アプローチ
Transformerの制限
制約の理解:
• **計算コスト:**Attentionはシーケンス長で二次的にスケール→ソリューション:効率的なAttentionバリアント
• **Contextウィンドウ:**依然として数千Tokenに制限→ソリューション:階層的処理、retrieval augmentation
• **データ飢餓:**大規模な事前トレーニングデータセットが必要→ソリューション:Few-shot Learning、効率的なFine-tuning
• **解釈可能性:**複雑なAttentionパターンの説明が困難→ソリューション:Attention可視化ツール
将来の方向性
Transformerが向かっている方向:
- より長いContextウィンドウ(1M以上のToken)
- より効率的なAttentionメカニズム
- マルチモーダル理解
- Edgeデバイス展開
- 生物学的シーケンスモデリング
さらに学ぶ
理解を深めるために関連概念を探索:
- Attention Mechanism - Transformerを強化するコアイノベーション
- Large Language Models - Transformerが数十億のParametersにどのようにスケールするか
- Fine-tuning - ユースケースのためにTransformerモデルをカスタマイズ
- Deep Learning - Transformerが革命的に変えたより広い分野
外部リソース
- Jay Alammar's Blog - Transformer ArchitectureとAttentionメカニズムの最良の視覚的説明
- Hugging Face Blog - Transformerモデルの実装とFine-tuningに関する実用的なガイド
- Google AI Research - 元のTransformer研究と最新のArchitectureイノベーション
FAQ
Transformer Architectureに関するよくある質問
Transformer Architectureとは何ですか?
TransformerはAttentionメカニズムを使用してシーケンス全体を同時に処理するNeural Network Architectureであり、以前のシーケンシャルモデルよりも並列処理とより良い文脈理解を可能にします。
Transformerと以前のAI Architectureの違いは何ですか?
以前のArchitecture(RNN、LSTM)はシーケンスを単語ごとに順次処理しました。TransformerはSelf-Attentionを使用してすべての単語を同時に処理し、トレーニングが100倍速く、長距離依存関係により優れています。
主なTransformerモデルの種類は何ですか?
BERT(Bidirectional理解)、GPT(テキスト生成)、T5(Text-to-Text)、Vision Transformer/ViT(画像処理)。それぞれ異なるタスクに最適化されています。
TransformerにおけるSelf-Attentionとは何ですか?
Self-Attentionは、すべてのToken(単語)がシーケンス内の他のすべてのTokenに直接Attendでき、単語間の距離に関係なく関係性を理解できるメカニズムです。
[AI Terms Collection]の一部。最終更新:2026-01-11

Co-Founder, Rework.com