Self-Attentionとは?AIの言語理解力を支える秘密の技術
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
「The bank was steep」と「The bank was closed」を読んだとき、前者が川岸を意味し、後者が金融機関を意味することを瞬時に理解できますよね。人間の脳は文脈を使い、全ての単語を順番にではなく、一緒に考慮しています。これがまさにSelf-AttentionがAIに対して行うことであり、ChatGPTが実際にあなたの意図を理解できる理由です。
Self-Attentionの歴史
2017年以前、AIモデルはスピードリーディングをする視野狭窄者のように、一度に一語ずつテキストを読み、以前の文脈を忘れていました。翻訳は不器用で、理解は浅いものでした。その後、GoogleのResearchersが「Attention Is All You Need」論文でSelf-Attentionを導入しました。
現在に至るまで:Self-Attentionは、AIが言語、画像、さらにはDNA配列を理解する方法を革命的に変えました。GPT、BERT、そしてnatural language processingにおける実質的にすべてのブレークスルーAIモデルの基盤となっています。
現代のビジネスにとって、これは文脈を本当に把握し、ニュアンスを理解し、人間のような応答を提供するAIを意味します。カスタマーサービスBotが突然賢くなり、AIが今や一貫性のあるマーケティングコピーを書ける理由です。
Self-Attentionの実際の仕組み
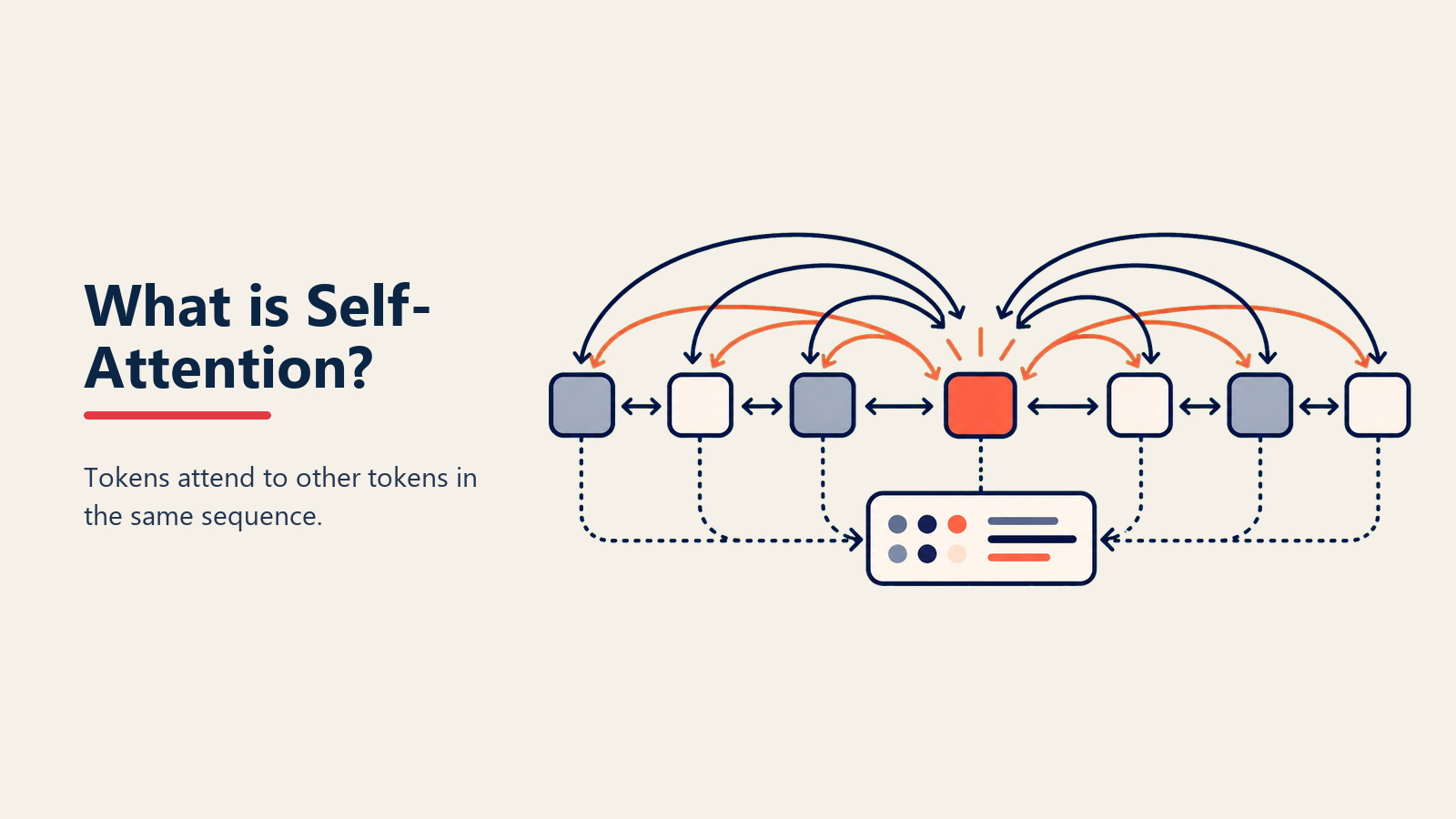
Self-Attentionはエレガントにシンプルなプロセスで動作します。まず、入力内のすべての単語(またはtoken)を順次ではなく、同時に見ます。複数のものに同時に焦点を当てられる目を持っているようなものです。
次に、各単語について、他のすべての単語にどれだけ注意を払うべきかを計算します。「The cat sat on the mat」を処理する際、「cat」は「sat」(猫は何をした?)と「mat」(どこに座った?)に多くの注意を払うべきだとわかります。
最後に、各単語が他のすべての単語との関係についての情報を含む豊富な表現を作成します。「Bank」は「river」または「money」の近くにあるかどうかを理解します。
これらの関係性を採点する数学的演算により、個々の単語を超えた意味を捉えるAttention Mapが作成されることで、魔法が起こります。
Self-Attentionのビジネスへの影響
カスタマーサービスの革命 Self-Attention以前:「アカウントにログインできません」→ 汎用的なパスワードリセット手順。 Self-Attention以後:AIは完全な文脈を理解し、関連するフォローアップ質問をし、具体的なソリューションを提供。解決率が45%向上しました。
コンテンツ生成 マーケティングチームは現在、Self-Attention対応ツールを使用して文脈に関連したコンテンツを作成しています。ある代理店では、手動作成よりも10倍多くのパーソナライズされたEmailキャンペーンを、より高いEngagementで作成しています。
文書分析 法律事務所はSelf-Attentionモデルを使用して契約書をレビューしています。AIは条項間の関係性を理解し、人間のレビュアーが見逃す問題を捉えます。レビュー時間が70%削減され、正確性が25%向上しました。
コード理解 開発プラットフォームはSelf-Attentionを使用してプログラミング意図を理解します。オートコンプリートの提案が文脈を認識するようになり、開発者の生産性が40%向上しました。
Attentionメカニズムの種類
Single-Head Attention 関係性の一つの側面にスポットライトを当てるようなもの。シンプルなタスクには適していますが、視点が限定的です。
Multi-Head Attention 異なる関係タイプを同時に調べる複数のスポットライト。あるHeadは文法に焦点を当て、別のHeadは意味に、また別のHeadはスタイルに焦点を当てる可能性があります。これは、ほとんどの現代的なneural networksが使用するものです。
Cross-Attention 質問と回答、または画像とキャプションのように、2つの異なるシーケンスを関連付けます。マルチモーダルAIに不可欠です。
Causal(Masked)Attention 前方のみを見て、後方は見ません。テキスト生成で、将来の単語を見ることによる「カンニング」を防ぐために使用されます。
Self-Attentionの実例
言語翻訳 従来の方法:「The spirit is willing but the flesh is weak」→「The vodka is good but the meat is rotten」(実際の初期翻訳の失敗例)。 Self-Attention使用:完璧な文脈理解。プロフェッショナル品質の翻訳。ニュアンスが保持されます。
検索理解 クエリ:「Apple stock performance not the fruit」 Self-Attentionは「not the fruit」が「Apple」を修飾することを理解し、金融結果のみを配信します。検索関連性が60%向上しました。
Sentiment Analysis 「I don't think this product is not worth avoiding.」 Self-Attentionは二重否定を解きほぐし、これが実際には推奨であることを理解します。Sentiment精度:94%。
Self-Attentionが従来の方法を凌駕する理由
並列処理 従来のモデルは順次(単語ごとに)処理します。Self-Attentionはすべての単語を同時に処理します。結果:100倍速いトレーニング。
長距離依存関係 数百語離れた関連概念を接続できます。従来のモデルは忘れます。Self-Attentionはすべてを覚えています。
計算効率 より多くの関係性を処理するにもかかわらず、現代の実装は高度に最適化されています。合理的な計算コストでより良い結果が得られます。
Transfer Learning Self-Attentionでトレーニングされたモデルは、新しいタスクに知識をより良く転送します。一度トレーニングすれば、どこでも適用できます。
ビジネスでのSelf-Attention実装
オプション1:事前トレーニング済みモデルを使用 すでにSelf-Attentionが組み込まれているGPTやBERTなどのモデルを活用します。最速の価値実現パス。
- OpenAI API:1K tokensあたり$0.002-0.03
- Hugging Faceモデル:無料から$20/時間
- Google Cloud AI:使用量に応じた支払い
オプション2:既存モデルをfine-tune 事前トレーニング済みモデルを取得し、特定のニーズに適応させます。カスタマイズと効率の最良のバランス。
- 必要:1,000-10,000の例
- 時間:1-2週間
- コスト:コンピューティングで$500-5,000
オプション3:カスタムモデルを構築 既存のモデルでは対応できない特定のニーズの場合のみ。重要な専門知識とリソースが必要です。
- チーム:MLエンジニアが必要
- 時間:3-6ヶ月
- コスト:$50K-500K以上
よくある誤解
「ビジネス利用には複雑すぎる」 現実:数学を理解する必要はありません。事前構築されたモデルとAPIにより、Self-Attentionはすべての開発者がアクセスできます。
「大規模な計算能力が必要」 現実:推論(モデルの使用)は軽量です。トレーニングは高コストですが、ゼロからトレーニングする必要はめったにありません。
「言語のみ」 現実:Self-Attentionは、任意のシーケンシャルまたは関係データに機能します。computer visionによる画像、時系列、グラフ - すべてが恩恵を受けます。
技術的な優位性(簡略化)
以下は、PhD不要で、Self-Attentionを特別にするものです:
Query-Key-Valueシステム
- Query:「何を探しているか?」
- Key:「どんな情報を持っているか?」
- Value:「何を覚えておくべきか?」
文脈に基づいて正確に何を取得するかを知っているスマートなファイリングシステムのようなものです。
Attentionスコア 単語間の数学的類似性。高スコア = 注意を払う。低スコア = 無視。すべての単語ペアについて計算されます。
Positional Encoding 単語順序情報を追加します。「dog bites man」が「man bites dog」と異なることを、すべての単語を同時に処理しながらも理解します。
実際の実装例
Eコマース検索 以前:キーワードマッチング。「Blue running shoes」は「azure athletic footwear」を見逃しました。 以後:Self-Attentionは意味を理解するsemantic searchを可能にします。35%より関連性の高い結果。
顧客Email分類 以前:ルールベースのルーティング。65%の精度。 以後:Self-Attentionモデルは文脈と意図を理解します。92%の正確なルーティング。
財務報告分析 以前:決算説明会の手動読み取り。数日の作業。 以後:Self-Attentionが主要な洞察、Sentiment、将来のガイダンスを抽出します。数日ではなく数分。
Self-Attention戦略
Self-Attentionについて、より理解が深まりましたね。
次に、Self-Attention上に構築された完全なフレームワークであるtransformer architectureを理解したいと思うでしょう。さらに、large language modelsに関するガイドでは、Self-AttentionがどのようにスケールしてChatGPTや類似システムを強化するかを示しています。
Self-Attentionに関するよくある質問
Self-Attentionとは何ですか?
Self-Attentionは、モデルが各単語が他のすべての単語とどのように関連しているかを同時に調べることで、文脈と関係性を理解できるようにするAIメカニズムです。順次処理するのではありません。
Self-Attentionと従来のAIテキスト処理の違いは何ですか?
従来のモデルはテキストを順次(単語ごとに)読み、しばしば以前の文脈を忘れます。Self-Attentionはすべての単語を同時に処理し、テキストのすべての部分間の関係性を維持することで、より良い理解を可能にします。
主なAttentionメカニズムの種類は何ですか?
Single-Head Attention(1つの側面に焦点)、Multi-Head Attention(複数の関係タイプを同時に調査)、Cross-Attention(2つの異なるシーケンスを関連付け)、Causal Attention(テキスト生成のために後方のみを見る)があります。
Self-Attentionは実際にどのように機能しますか?
Query-Key-Valueシステムを使用し、各単語が「何を探しているか?」(Query)、「どんな情報を持っているか?」(Key)、「何を覚えておくべきか?」(Value)を尋ね、すべての単語ペア間でAttentionスコアを計算します。
Self-Attentionはなぜ現代AIにとって重要ですか?
並列処理(100倍速いトレーニング)を可能にし、長距離依存関係を処理し、より良いTransfer Learningを強化し、文脈とニュアンスを実際に理解するGPT、BERT、ChatGPTなどのブレークスルーモデルの基盤となっています。
外部リソース
Self-Attentionに関する権威ある研究とドキュメントを探索:
- Google's "Attention Is All You Need" Paper - Transformer Architectureを導入した2017年の画期的な論文
- The Illustrated Transformer - Self-AttentionとTransformerを理解するための視覚的ガイド
- Stanford CS224N: NLP with Deep Learning - Attentionメカニズムに関する包括的なコース資料
さらに学ぶ
理解を深めるために、関連するAI概念を探索:
- Attention Mechanism - Self-Attentionを含む技術のより広いファミリー
- Deep Learning - Self-Attentionを可能にする基盤
- Embeddings - Self-Attentionが処理する前に単語がどのように表現されるか
- Generative AI - Self-Attentionメカニズムによって強化されるアプリケーション
AI Terms Collectionの一部。最終更新:2026-07-21
