Data Pipelineとは?ビジネスの情報ハイウェイ
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
「私たちのデータはあらゆる場所にあります - CRM、ウェブサイト、在庫システム、ソーシャルメディア。しかし、分析する頃にはすでに古くなっています。」聞き覚えがありますか?このCEOのフラストレーションが、Data Pipelineが存在する理由です。それらは、カオスを自動的にインサイトに変える見えないインフラストラクチャです。核心において、Data PipelineはAI自動化戦略の重要なコンポーネントです。
Data Pipelineを理解する
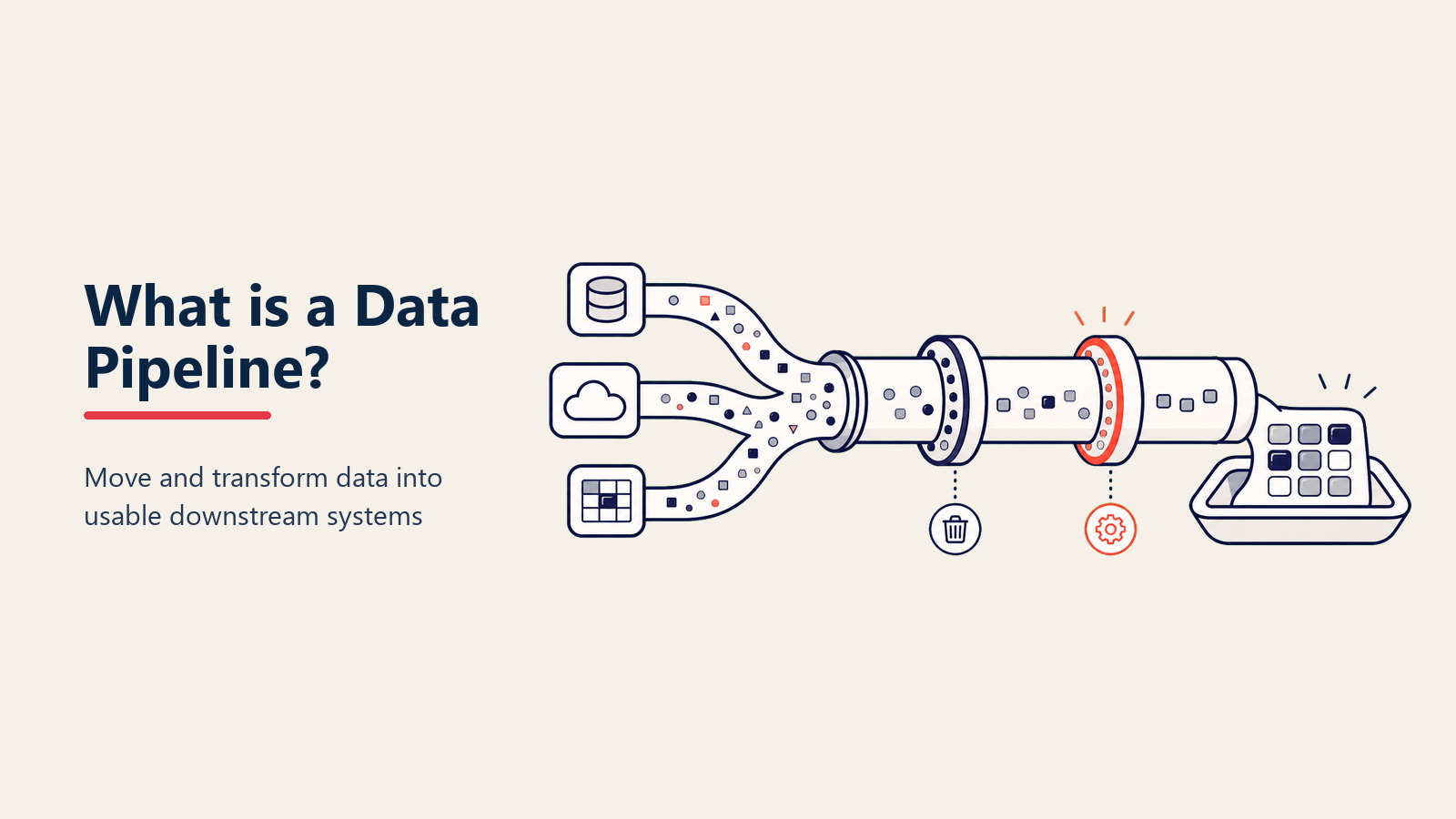
工場の組立ラインが異なる段階を経て製品を移動させる方法をご存知ですか?Data Pipelineは似ていますが、情報に対してです。様々なソースからデータを自動的に収集し、クリーンアップし、有用なフォーマットに変換し、必要な場所に配信します。
より技術的には、Data Pipelineは、ソースシステムから宛先システムにデータを移動し、途中で変換する自動化されたプロセスのセットです。デジタル運用のための配管と考えてください。
重要な違いは自動化です。パイプラインなしでは、誰かが手動でCSVをエクスポートし、Excelでデータをクリーニングし、異なるシステムにアップロードします。パイプラインがあれば?自動的に、継続的に、正確に発生します。
Data Pipelineの構成要素
核心として、Data Pipelineには3つの主要な部分があります:
ソースコネクタ - これらがシステムからデータを取得 これらを吸気バルブと考えてください。CRM、データベース、API、ファイル、IoTセンサー - データがある場所に接続します。最新のコネクタは数百のソースを処理できます。
処理エンジン - これがデータをクリーニングして変換 本質的に、原材料が製品になる工場のフロアです。このレイヤーは重複を削除し、フォーマットを修正し、新しいフィールドを計算し、追加のコンテキストでデータを強化します。
宛先ハンドラー - これらが処理されたデータを配信 ここに変換されたデータが到着します - データウェアハウス、ビジネスインテリジェンスツール、別のアプリケーション、またはAIモデルの可能性があります。重要なのは、データがさらなるクリーンアップを必要とせず、使用準備ができた状態で到着することです。
異なる業界でのData Pipelineの使用
Eコマース あるオンライン小売業者は、Shopifyストア、Google Analytics、Facebook Ads、在庫システムを接続するパイプラインを構築しました。現在、広告費と配送コストを含む製品ごとのリアルタイムの収益性を確認できます。訪問者あたりの収益が23%増加しました。
ヘルスケア あるクリニックネットワークは、患者記録、予約システム、請求データを組み合わせるためにパイプラインを使用しています。予測分析を使用して、85%の精度でノーショーを予測し、自動的にターゲットを絞ったリマインダーを送信します。患者の出席率が30%向上しました。
金融サービス あるフィンテックスタートアップは、リアルタイムの不正防止のために異常検出モデルを通じて取引データをパイプライン処理します。疑わしいアクティビティが即座にアラートをトリガーします。サブセカンドの処理を維持しながら、240万ドルの不正取引を防止しました。
製造 ある工場は、設備からのセンサーデータを予測保全モデルにストリーミングし、リアルタイム監視のためにIoT AIをしばしば活用します。数日前に潜在的な故障を発見します。計画外のダウンタイムが45%減少しました。
Data Pipelineのタイプ
バッチ処理パイプライン これらはスケジュールで実行されます - 毎時、毎日、毎週。レポート、データウェアハウジング、リアルタイムが重要でないシナリオに最適です。定時に乗客を拾う定期列車のようなものです。
ストリーミングパイプライン これらは到着すると同時にデータを即座に処理します。不正検出、リアルタイムパーソナライゼーション、運用監視に不可欠です。決して止まらないコンベヤーベルトのようなものです。
ハイブリッドパイプライン 柔軟性のためにバッチとストリーミングを組み合わせます。履歴分析をバッチ処理しながら、重要なデータをストリーミングします。ほとんどの企業は最終的にここに到達します。
ETL対ELTの議論
ETL(抽出、変換、ロード) 従来のアプローチ:保存前にデータを変換します。冷蔵庫に入れる前に材料を調理するようなものです。構造化データとストレージが高価な場合に適しています。
ELT(抽出、ロード、変換) 最新のアプローチ:生データを保存し、後で変換します。材料を購入して後で何を料理するかを決めるようなものです。ビッグデータとストレージが安価な場合に優れています。
ほとんどのクラウドネイティブビジネスは柔軟性のためにELTを好みますが、データガバナンスが必要な規制産業ではETLが依然として支配的です。
実装ロードマップ
1-2週目:データ監査
- すべてのデータソースをマッピング
- 現在の手動プロセスを文書化
- 最も影響の大きいパイプライン機会を特定
- 手動データタスクに費やされた時間を計算
3-4週目:パイロットパイプライン
- 1つのシンプルなフロー(販売データからダッシュボードなど)から始める
- 迅速な成果のためにノーコードツールを使用
- 節約された時間と改善された精度を測定
- 学んだ教訓を文書化
2か月目:カバレッジの拡大
- より多くのデータソースを追加
- 基本的な変換を導入
- 監視とアラートを設定
- メンテナンスについてチームをトレーニング
3か月目以降:高度な機能
- 必要に応じてリアルタイムストリーミングを実装
- データ品質チェックを追加
- 複雑な変換を構築
- AI/MLモデルと統合
ツールとプラットフォーム
ノーコードソリューション:
- Zapier - 5,000以上のアプリを接続(19.99ドル/月)
- Make.com(旧Integromat) - ビジュアル自動化(9ドル/月)
- Fivetran - 自動化されたデータコネクタ(120ドル/月)
開発者フレンドリー:
- Apache Airflow - オープンソースオーケストレーション(無料)
- Prefect - 最新のワークフロー自動化(無料ティアあり)
- Dagster - データオーケストレーションプラットフォーム(無料オープンソース)
エンタープライズプラットフォーム:
- Informatica - 完全なデータ管理(カスタム価格)
- Talend - 包括的なデータプラットフォーム(1,170ドル/ユーザー/年)
- Azure Data Factory - Microsoftのソリューション(アクティビティあたり0.001ドル)
一般的な落とし穴
落とし穴1:複雑すぎる開始 ある小売チェーンは、一度に50のシステムを接続するマスターパイプラインの構築を試みました。壮大に失敗しました。 解決策: 2-3のシステムから始めます。価値を証明します。その後拡大します。
落とし穴2:データ品質を無視 ゴミが入れば、ゴミが出る - しかしより速く!悪いデータが迅速に移動することは、遅い手動プロセスよりも悪いです。 解決策: すべてのパイプライン段階に品質チェックを組み込みます。
落とし穴3:エラー処理なし 1つの悪いレコードがパイプライン全体をクラッシュさせ、1日分のデータを失いました。 解決策: 失敗を優雅に処理するパイプラインを設計します。エラーをログに記録し、悪いレコードをスキップし、人間にアラートします。
Data Pipelineのビジネスケース
時間の節約:
- 手動データ処理:20時間/週
- パイプラインあり:2時間/週
- ROI:分析のために18時間解放
精度の向上:
- 手動エラー率:5-10%
- パイプラインエラー率:<0.1%
- 影響:より良い意思決定、より少ない修正
インサイトまでの速度:
- 手動:2-3日の遅れ
- パイプライン:リアルタイムから毎時
- 結果:機会へのより速い対応
これでパイプライン準備完了
これでData Pipelineが要約できました。今はもっと理解できましたよね?
次に、Data Curationを理解したいでしょう - クリーンなデータがより良いパイプラインを作るからです。さらに、MLOpsのガイドは、パイプラインが本番環境での機械学習をどのように強化するかを示します。
関連リソース
Data Pipelineとその役割の理解を深めるために、これらの関連概念を探索してください:
- Machine Learning - 多くのパイプライン駆動型予測の基礎
- AI Integration - パイプラインを既存システムと接続する方法
- Model Monitoring - 時間の経過に伴うパイプラインパフォーマンスとモデル精度を追跡
外部リソース
- Apache Airflow Documentation - オープンソースワークフローオーケストレーションプラットフォーム
- AWS Data Pipeline Guide - クラウドベースのETLサービスチュートリアル
- Databricks: Data Engineering - 最新のデータパイプラインアーキテクチャパターン
FAQ
Data Pipelineに関するよくある質問
Data Pipelineとは何ですか?
Data Pipelineは、ソースシステムから宛先システムにデータを移動し、途中で変換とクリーニングを行う自動化されたプロセスのセットで、ビジネス情報のための組立ラインのようなものです。
ETLとELTの違いは何ですか?
ETL(抽出、変換、ロード)は保存前にデータを変換します。ELT(抽出、ロード、変換)は最初に生データを保存し、その後変換します。ELTはより柔軟性を提供しますが、より多くのストレージが必要です。
Data Pipelineの3つの主要コンポーネントは何ですか?
ソースコネクタ(システムからデータを取得)、処理エンジン(データをクリーニングして変換)、宛先ハンドラー(分析ツール、データベース、またはアプリケーションにデータを配信)です。
Data Pipelineの3つのタイプは何ですか?
バッチ処理パイプライン(スケジュールで実行)、ストリーミングパイプライン(データを即座に処理)、ハイブリッドパイプライン(柔軟性のためにバッチとストリーミングを組み合わせ)です。
Data Pipeline実装における一般的な落とし穴は何ですか?
複雑すぎる開始(一度に多くのシステムを接続しようとする)、データ品質を無視する(ゴミが入れば、ゴミが出る)、エラー処理なし(1つの悪いレコードがすべてをクラッシュさせる)です。
[AI用語集]の一部。最終更新:2026-07-21
