O que é Clustering? Descobrindo as Tribos Ocultas em Seus Dados
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
87% das empresas segmentam clientes incorretamente. Elas usam dados demográficos básicos - idade, renda, localização - quando o verdadeiro ouro está nos padrões comportamentais. É aí que entra o clustering. É IA que encontra grupos naturais em seus dados, revelando segmentos que você nunca soube que existiam. Como o varejista que descobriu que seus "compradores de iogurte de domingo de manhã" eram seu segmento mais lucrativo.
Entendendo Clustering
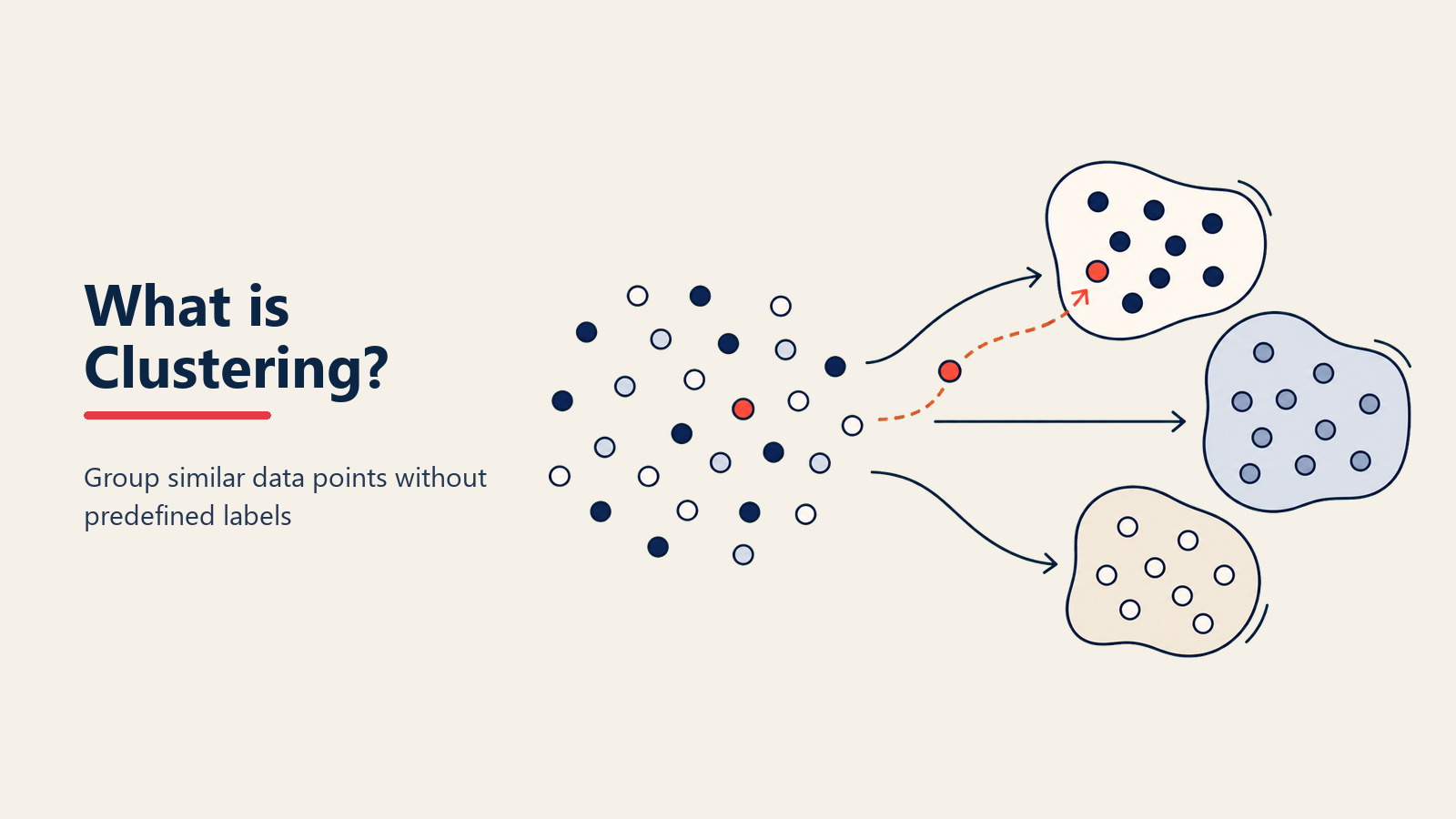
Você sabe como as pessoas naturalmente formam grupos em festas? Fãs de esportes gravitam juntos, pais se encontram, pessoal de tecnologia se agrupa nos cantos. Algoritmos de clustering fazem a mesma coisa com dados - encontrando agrupamentos naturais sem serem instruídos sobre o que procurar.
Mais tecnicamente, clustering é uma técnica de unsupervised machine learning que agrupa pontos de dados semelhantes com base em suas características. Diferentemente da classificação (que precisa de rótulos), o clustering descobre padrões por conta própria.
A diferença chave é descoberta versus previsão. Classificação de supervised learning pergunta "Este cliente é de alto valor?" quando você já sabe o que alto valor significa. Clustering pergunta "Que tipos de clientes temos?" e deixa os dados revelarem a resposta.
Como Clustering Realmente Funciona
Clustering opera através da medição de similaridade. Primeiro, ele representa cada ponto de dados em espaço matemático - idade do cliente pode ser uma dimensão, frequência de compra outra, valor médio do pedido uma terceira. Como plotar pontos em um mapa multi-dimensional.
Então, algoritmos calculam distâncias entre todos os pontos. Itens similares ficam próximos, itens diferentes distantes. Um comprador de luxo e um comprador econômico podem estar distantes mesmo se tiverem a mesma idade e localização.
Finalmente, grupos se formam com base na proximidade. O algoritmo desenha limites ao redor de áreas densas de pontos similares. Você pode descobrir cinco segmentos distintos de clientes onde pensava ter dois.
A mágica acontece ao definir "similaridade" - algoritmos modernos de machine learning conseguem lidar com centenas de dimensões e relações complexas que humanos não conseguem visualizar.
Aplicações Reais de Clustering
Segmentação de Clientes no Varejo Um varejista de moda aplicou clustering ao histórico de compras, comportamento de navegação e padrões de devolução. Descobriu sete segmentos incluindo "seguidores de tendências" (compram imediatamente após lançamento) e "caçadores de promoção" (só compram itens com desconto). Marketing personalizado para cada segmento aumentou receita em 34%.
Grupos de Pacientes em Saúde Hospital agrupou dados de pacientes além dos fatores de risco tradicionais. Encontrou subgrupos respondendo diferentemente a tratamentos. Um cluster de diabetes respondeu 3x melhor a intervenções de estilo de vida que medicação. Personalização de tratamento melhorou resultados em 40%.
Avaliação de Risco Financeiro Banco agrupou solicitantes de empréstimo de pequenos negócios usando métricas financeiras, dados do setor e padrões de transação. Identificou clusters de risco que scoring tradicional perdia. Taxas de inadimplência caíram 25% enquanto taxas de aprovação aumentaram 15%.
Otimização da Cadeia de Suprimentos Fabricante agrupou fornecedores por desempenho de entrega, métricas de qualidade e padrões de comunicação. Revelou padrões ocultos de confiabilidade. Reestruturou relacionamentos com fornecedores, reduzindo atrasos em 30%.
Tipos de Algoritmos de Clustering
K-Means Clustering O cavalo de batalha do clustering. Você especifica quantos clusters quer, ele encontra os melhores agrupamentos. Perfeito para segmentação de clientes onde você precisa de grupos distintos e não sobrepostos. Rápido e escalável.
Hierarchical Clustering Constrói uma árvore de clusters - como organizar uma empresa de departamentos a equipes a indivíduos. Ótimo quando você precisa de diferentes níveis de granularidade. Redes de varejo usam isso para agrupamentos de lojas.
DBSCAN (Baseado em Densidade) Encontra clusters de forma arbitrária e identifica outliers. Excelente para detecção de fraude e anomaly detection - transações normais se agrupam, fraudulentas se destacam como outliers.
Gaussian Mixture Models Assume que dados vêm de múltiplas distribuições estatísticas. Sofisticado mas poderoso. Usado em manufatura para identificar diferentes estados de qualidade na produção.
A Diferença do Clustering
Antes do Clustering: Marketing envia mesma campanha para "Mulheres 25-34" Depois do Clustering: Cinco segmentos distintos identificados:
- Profissionais focadas na carreira (respondem a mensagens de eficiência)
- Novas mães (valorizam segurança e conveniência)
- Entusiastas de fitness (querem recursos de desempenho)
- Estudantes conscientes do orçamento (sensíveis a preço)
- Compradores eco-conscientes (sustentabilidade importa)
Resultado: Taxas de cliques aumentaram 250%. Mesma audiência, segmentação mais inteligente.
Quando Clustering Faz Sentido
Imagine que você tem milhares de produtos mas não sabe como organizá-los. Categorias tradicionais (eletrônicos, roupas) são muito amplas. Clustering revela agrupamentos naturais baseados em como clientes realmente compram - "essenciais rápidos" ou "compras que exigem pesquisa."
Ou digamos que você está entrando em um novo mercado. Você não conhece os segmentos de clientes ainda. Clustering analisa early adopters e revela tipos distintos de usuários para atingir.
Roteiro de Implementação
Semana 1: Preparação de Dados
- Coletar recursos relevantes (comportamento > demografias)
- Limpar e normalizar dados através de data curation adequada (crítico para clustering)
- Remover outliers óbvios
- Criar recursos derivados (razões, frequências)
Semana 2: Exploração
- Testar múltiplos algoritmos
- Experimentar com diferentes números de clusters
- Validar que resultados fazem sentido empresarial
- Obter input de stakeholders sobre agrupamentos
Semana 3-4: Validação
- Testar estabilidade de cluster ao longo do tempo
- Garantir que clusters são acionáveis
- Calcular métricas empresariais por cluster
- Projetar estratégias específicas por cluster
Mês 2+: Operacionalização
- Automatizar atribuição de cluster para novos dados via práticas de MLOps
- Criar dashboards de monitoramento
- Desenvolver tratamentos específicos por cluster
- Medir impacto e refinar
Ferramentas para Clustering
Soluções No-Code:
- Tableau - Clustering integrado ($70/usuário/mês)
- Microsoft Power BI - Recursos de auto-clustering ($10/usuário/mês)
- Google Analytics 4 - Descoberta de audiência (Gratuito com limites)
Bibliotecas Python (Gratuitas):
- scikit-learn - Todos os principais algoritmos
- HDBSCAN - Clustering de densidade avançado
- pyclustering - Algoritmos especializados
Plataformas Empresariais:
- SAS Enterprise Miner - Suíte completa de clustering (Preço customizado)
- IBM SPSS Modeler - Clustering visual ($99/usuário/mês)
- DataRobot - Clustering automatizado ($75K+/ano)
Serviços Cloud:
- AWS SageMaker - Clustering integrado ($0.05/hora)
- Google Vertex AI - AutoML clustering ($20/hora)
- Azure ML - Módulos de clustering ($9.90/hora de computação)
Armadilhas Comuns de Clustering
Armadilha 1: Forçar Número Errado de Clusters CEO quer 5 segmentos de clientes porque concorrentes têm 5. Dados claramente mostram 3 ou 8 grupos naturais. Solução: Deixe os dados guiarem números de cluster. Use gráficos de elbow e scores de silhueta. Lógica de negócio deve refinar, não definir.
Armadilha 2: Usar Recursos Errados Agrupar clientes por idade e renda quando comportamento de compra varia mais por estilo de vida e valores. Solução: Focar em recursos comportamentais e transacionais. Demografias são coadjuvantes, não protagonistas.
Armadilha 3: Ignorar Evolução de Cluster Segmentos de clientes definidos em 2019, nunca atualizados. COVID mudou tudo. Solução: Reclustering trimestral ou quando eventos importantes ocorrem. Implementar model monitoring para rastrear drift de cluster.
Estratégias Avançadas de Clustering
Multi-View Clustering Combinar diferentes perspectivas de dados. Agrupar clientes por comportamento de compra E interações de suporte E atividade no site. Revela segmentos mais ricos.
Semi-Supervised Clustering Incorporar alguns rótulos conhecidos para guiar clustering. "Sabemos que estes são clientes VIP, encontre grupos similares." Equilibra descoberta com conhecimento de negócio.
Dynamic Clustering Clusters que evoluem ao longo do tempo. Rastrear como clientes se movem entre segmentos. Usar time series analysis para prever transições de segmento. Habilitar intervenções proativas.
Medindo Sucesso de Clustering
Métricas Técnicas:
- Coeficiente de silhueta (separação de cluster)
- Índice de Davies-Bouldin (compactação de cluster)
- Score de Calinski-Harabasz (definição de cluster)
Métricas de Negócio:
- Receita por cluster
- Taxas de resposta de marketing por cluster
- Diferenças de retenção entre clusters
- Custos operacionais por cluster
Teste de Acionabilidade: Você consegue criar estratégias distintas por cluster? Se todos os clusters recebem o mesmo tratamento, clustering falhou.
Clustering Específico por Setor
E-commerce:
- Grupos de afinidade de produto
- Segmentos de comportamento de compra
- Clusters de compradores sazonais
- Grupos de sensibilidade a preço
B2B:
- Segmentação de contas
- Grupos de padrões de uso
- Clusters de potencial de crescimento aprimorados por predictive analytics
- Segmentos de perfil de risco
Saúde:
- Grupos de risco de pacientes
- Clusters de resposta a tratamento
- Segmentos de utilização de recursos
- Grupos de previsão de resultados
Fazendo Clustering Funcionar para Você
Olha, clustering não é mágica. Mas se você está tratando todos os clientes da mesma forma, está deixando dinheiro na mesa.
Comece pequeno: agrupe seus 1000 principais clientes por comportamento de compra. Você encontrará segmentos que nunca imaginou.
Saiba Mais
Explore conceitos relacionados para aprofundar sua compreensão de clustering e descoberta orientada a dados:
- Unsupervised Learning - A categoria mais ampla de técnicas de ML que descobrem padrões sem rótulos
- Deep Learning - Abordagens neurais avançadas para tarefas complexas de clustering
- Neural Networks - A arquitetura subjacente que impulsiona algoritmos modernos de clustering
- Business Intelligence - Como insights de clustering alimentam tomada de decisão estratégica
Recursos Externos
- Stanford HAI: Clustering Research - Pesquisa acadêmica sobre algoritmos de clustering
- Scikit-learn Clustering Guide - Documentação de implementação prática
- Papers With Code: Clustering - Técnicas e benchmarks de clustering mais recentes
Seção de FAQ
Perguntas Frequentes sobre Clustering
O que é Clustering?
Clustering é uma técnica de machine learning não supervisionado que agrupa pontos de dados similares com base em suas características, descobrindo padrões naturais sem ser instruído sobre o que procurar.
Qual a diferença entre clustering e classificação?
Classificação prevê categorias quando você já sabe quais categorias existem. Clustering descobre grupos desconhecidos em dados sem rótulos ou categorias predefinidas.
Quais são os quatro tipos principais de algoritmos de clustering?
K-Means (especificar número de clusters), Hierarchical (constrói árvore de clusters), DBSCAN (encontra formas arbitrárias e outliers), e Gaussian Mixture Models (assume distribuições estatísticas).
Quais são os principais benefícios do clustering para negócios?
Descoberta de segmentos ocultos de clientes, personalização melhorada, melhor compreensão de mercado, otimização de recursos e identificação de padrões que segmentação tradicional perde.
Quais são armadilhas comuns na implementação de clustering?
Forçar número errado de clusters (deixe os dados guiarem), usar recursos errados (focar em comportamento sobre demografias), e ignorar evolução de cluster (segmentos mudam ao longo do tempo).
Parte da [Coleção de Termos de IA]. Última atualização: 2026-07-21

Co-Founder, Rework.com
On this page
- Entendendo Clustering
- Como Clustering Realmente Funciona
- Aplicações Reais de Clustering
- Tipos de Algoritmos de Clustering
- A Diferença do Clustering
- Quando Clustering Faz Sentido
- Roteiro de Implementação
- Ferramentas para Clustering
- Armadilhas Comuns de Clustering
- Estratégias Avançadas de Clustering
- Medindo Sucesso de Clustering
- Clustering Específico por Setor
- Fazendo Clustering Funcionar para Você
- Saiba Mais
- Recursos Externos
- Seção de FAQ