Was ist Clustering? Die verborgenen Stämme in Ihren Daten entdecken
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
87% der Unternehmen segmentieren Kunden falsch. Sie verwenden grundlegende Demografie – Alter, Einkommen, Standort – während das echte Gold in Verhaltensmustern liegt. Hier kommt Clustering ins Spiel. Es ist KI, die natürliche Gruppen in Ihren Daten findet und Segmente offenbart, von denen Sie nie wussten, dass sie existieren. Wie der Einzelhändler, der entdeckte, dass seine „Sonntagmorgen-Joghurt-Käufer" sein profitabelstes Segment waren.
Clustering verstehen
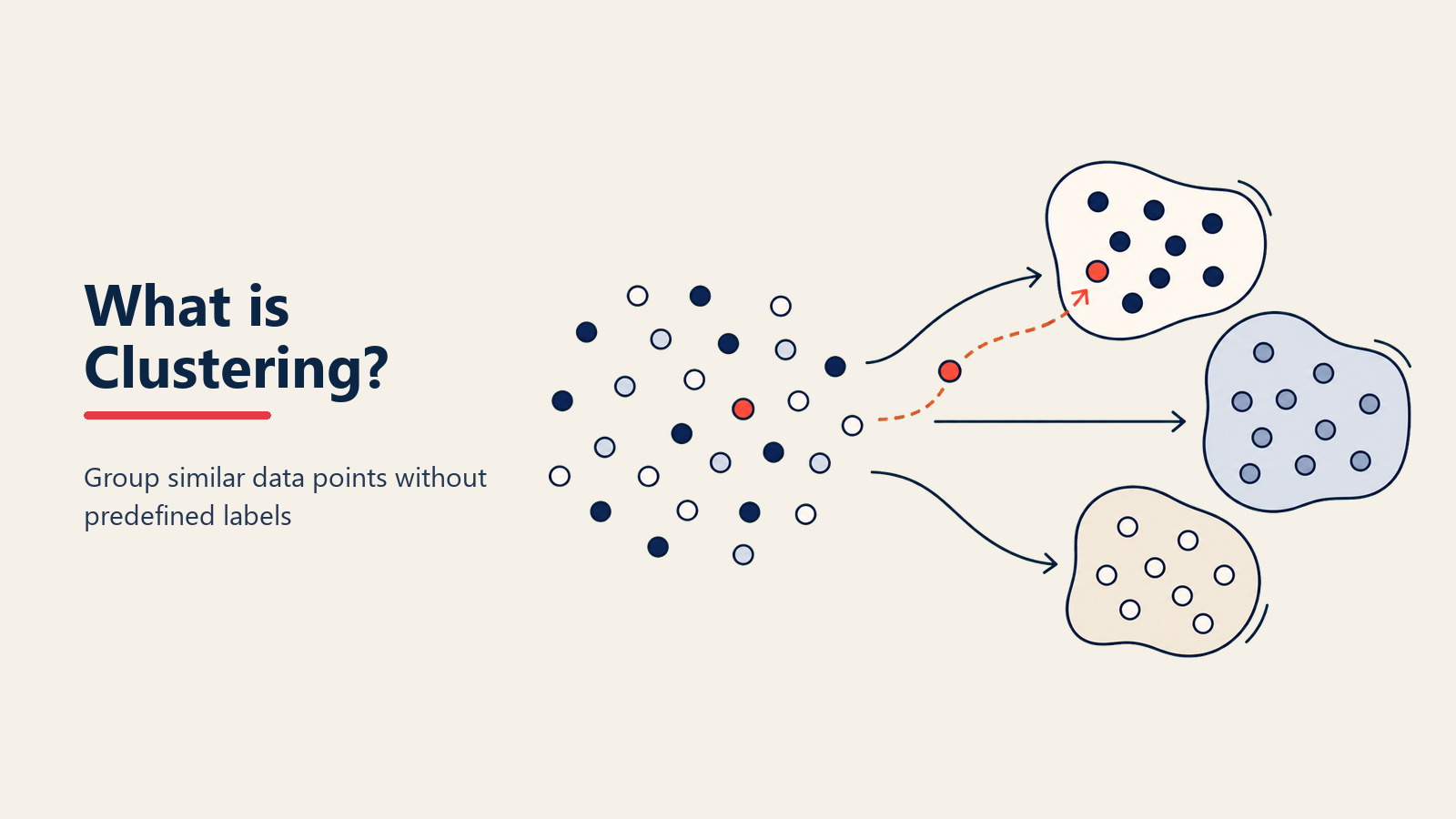
Sie wissen, wie Menschen auf Partys natürlich Gruppen bilden? Sportfans gravitieren zusammen, Eltern finden sich, Technikbegeisterte sammeln sich in Ecken. Clustering-Algorithmen machen dasselbe mit Daten – finden natürliche Gruppierungen, ohne gesagt zu bekommen, wonach sie suchen sollen.
Technischer ausgedrückt ist Clustering eine Unsupervised Machine Learning-Technik, die ähnliche Datenpunkte basierend auf ihren Eigenschaften gruppiert. Anders als Klassifizierung (die Labels benötigt), entdeckt Clustering Muster selbstständig.
Der Hauptunterschied ist Entdeckung versus Vorhersage. Supervised Learning-Klassifizierung fragt „Ist dieser Kunde wertvoll?", wenn Sie bereits wissen, was wertvoll bedeutet. Clustering fragt „Welche Arten von Kunden haben wir?" und lässt die Daten die Antwort enthüllen.
Wie Clustering tatsächlich funktioniert
Clustering arbeitet durch Ähnlichkeitsmessung. Zuerst repräsentiert es jeden Datenpunkt im mathematischen Raum – Kundenalter könnte eine Dimension sein, Kauffrequenz eine andere, durchschnittlicher Bestellwert eine dritte. Wie das Zeichnen von Punkten auf einer mehrdimensionalen Karte.
Dann berechnen Algorithmen Abstände zwischen allen Punkten. Ähnliche Elemente sind nah beieinander, unterschiedliche Elemente weit auseinander. Ein Luxuskäufer und Budget-Shopper könnten weit entfernt sein, selbst wenn sie dasselbe Alter und denselben Standort haben.
Schließlich bilden sich Gruppen basierend auf Nähe. Der Algorithmus zieht Grenzen um dichte Bereiche ähnlicher Punkte. Sie könnten fünf verschiedene Kundensegmente entdecken, wo Sie dachten, Sie hätten zwei.
Die Magie passiert bei der Definition von „Ähnlichkeit" – moderne Machine Learning-Algorithmen können Hunderte von Dimensionen und komplexe Beziehungen handhaben, die Menschen nicht visualisieren können.
Clustering-Anwendungen aus der Praxis
Einzelhandel-Kundensegmentierung Ein Modehändler wandte Clustering auf Kaufhistorie, Browsing-Verhalten und Retourenmuster an. Entdeckte sieben Segmente einschließlich „Trendfolger" (kaufen sofort nach Launch) und „Schnäppchenjäger" (kaufen nur reduzierte Artikel). Personalisiertes Marketing für jedes Segment steigerte Umsatz um 34%.
Gesundheitswesen-Patientengruppen Krankenhaus clusterte Patientendaten über traditionelle Risikofaktoren hinaus. Fand Untergruppen, die unterschiedlich auf Behandlungen reagieren. Ein Diabetes-Cluster reagierte 3x besser auf Lifestyle-Interventionen als auf Medikamente. Behandlungspersonalisierung verbesserte Ergebnisse um 40%.
Finanzielle Risikobewertung Bank clusterte Kleinunternehmen-Kreditantragsteller mit Finanzkennzahlen, Branchendaten und Transaktionsmustern. Identifizierte Risikocluster, die traditionelles Scoring verfehlte. Ausfallraten sanken um 25%, während Genehmigungsraten um 15% stiegen.
Supply Chain-Optimierung Hersteller clusterte Lieferanten nach Lieferleistung, Qualitätsmetriken und Kommunikationsmustern. Offenbarte verborgene Zuverlässigkeitsmuster. Restrukturierte Lieferantenbeziehungen, reduzierte Verzögerungen um 30%.
Arten von Clustering-Algorithmen
K-Means Clustering Das Arbeitspferd des Clusterings. Sie geben an, wie viele Cluster Sie möchten, es findet die besten Gruppierungen. Perfekt für Kundensegmentierung, wo Sie unterschiedliche, nicht überlappende Gruppen benötigen. Schnell und skalierbar.
Hierarchisches Clustering Baut einen Baum von Clustern – wie das Organisieren eines Unternehmens von Abteilungen zu Teams zu Individuen. Großartig, wenn Sie verschiedene Granularitätsebenen benötigen. Einzelhandelsketten nutzen dies für Geschäftsgruppierungen.
DBSCAN (Density-Based) Findet Cluster beliebiger Form und identifiziert Ausreißer. Hervorragend für Betrugserkennung und Anomaly Detection – normale Transaktionen clustern zusammen, betrügerische stechen als Ausreißer hervor.
Gaussian Mixture Models Nimmt an, dass Daten aus mehreren statistischen Verteilungen stammen. Anspruchsvoll, aber mächtig. Verwendet in der Fertigung zur Identifizierung verschiedener Qualitätszustände in der Produktion.
Der Clustering-Unterschied
Vor Clustering: Marketing sendet dieselbe Kampagne an „Frauen 25-34" Nach Clustering: Fünf unterschiedliche Segmente identifiziert:
- Karriereorientierte Professionals (reagieren auf Effizienz-Messaging)
- Neue Mütter (schätzen Sicherheit und Komfort)
- Fitness-Enthusiasten (wollen Leistungsmerkmale)
- Budgetbewusste Studenten (preissensitiv)
- Umweltbewusste Käufer (Nachhaltigkeit zählt)
Ergebnis: Click-Through-Raten stiegen um 250%. Dieselbe Zielgruppe, intelligentere Segmentierung.
Wann Clustering Sinn macht
Stellen Sie sich vor, Sie haben Tausende von Produkten, wissen aber nicht, wie Sie sie organisieren sollen. Traditionelle Kategorien (Elektronik, Kleidung) sind zu breit. Clustering enthüllt natürliche Gruppierungen basierend darauf, wie Kunden tatsächlich einkaufen – „Grab-and-Go Essentials" oder „recherche-intensive Käufe".
Oder sagen wir, Sie betreten einen neuen Markt. Sie kennen die Kundensegmente noch nicht. Clustering analysiert Early Adopters und enthüllt unterschiedliche Nutzertypen zum Targeting.
Implementierungs-Roadmap
Woche 1: Datenvorbereitung
- Sammeln Sie relevante Features (Verhalten > Demografie)
- Bereinigen und normalisieren Sie Daten durch ordnungsgemäße Data Curation (kritisch für Clustering)
- Entfernen Sie offensichtliche Ausreißer
- Erstellen Sie abgeleitete Features (Verhältnisse, Frequenzen)
Woche 2: Exploration
- Probieren Sie mehrere Algorithmen aus
- Experimentieren Sie mit verschiedenen Clusteranzahlen
- Validieren Sie, dass Ergebnisse geschäftlich sinnvoll sind
- Holen Sie Stakeholder-Input zu Gruppierungen ein
Woche 3-4: Validierung
- Testen Sie Cluster-Stabilität über Zeit
- Stellen Sie sicher, dass Cluster umsetzbar sind
- Berechnen Sie Geschäftsmetriken pro Cluster
- Gestalten Sie clusterspezifische Strategien
Monat 2+: Operationalisierung
- Automatisieren Sie Cluster-Zuweisung für neue Daten über MLOps-Praktiken
- Erstellen Sie Monitoring-Dashboards
- Entwickeln Sie clusterspezifische Behandlungen
- Messen Sie Impact und verfeinern Sie
Tools für Clustering
No-Code-Lösungen:
- Tableau - Eingebautes Clustering ($70/Nutzer/Monat)
- Microsoft Power BI - Auto-Clustering-Features ($10/Nutzer/Monat)
- Google Analytics 4 - Audience Discovery (Kostenlos mit Limits)
Python-Bibliotheken (Kostenlos):
- scikit-learn - Alle wichtigen Algorithmen
- HDBSCAN - Fortgeschrittenes Density-Clustering
- pyclustering - Spezialisierte Algorithmen
Enterprise-Plattformen:
- SAS Enterprise Miner - Vollständige Clustering-Suite (Custom Pricing)
- IBM SPSS Modeler - Visuelles Clustering ($99/Nutzer/Monat)
- DataRobot - Automatisiertes Clustering ($75K+/Jahr)
Cloud-Services:
- AWS SageMaker - Eingebautes Clustering ($0,05/Stunde)
- Google Vertex AI - AutoML Clustering ($20/Stunde)
- Azure ML - Clustering-Module ($9,90/Compute-Stunde)
Häufige Clustering-Fallstricke
Fallstrick 1: Falsche Clusteranzahl erzwingen CEO will 5 Kundensegmente, weil Wettbewerber 5 haben. Daten zeigen klar 3 oder 8 natürliche Gruppen. Lösung: Lassen Sie Daten die Clusteranzahl leiten. Nutzen Sie Elbow Plots und Silhouette Scores. Geschäftslogik sollte verfeinern, nicht definieren.
Fallstrick 2: Falsche Features verwenden Kunden nach Alter und Einkommen clustern, wenn Kaufverhalten mehr nach Lifestyle und Werten variiert. Lösung: Fokussieren Sie auf verhaltens- und transaktionale Features. Demografie sind Nebendarsteller, nicht Hauptrollen.
Fallstrick 3: Cluster-Evolution ignorieren Kundensegmente 2019 definiert, nie aktualisiert. COVID änderte alles. Lösung: Reclustering vierteljährlich oder bei großen Ereignissen. Implementieren Sie Model Monitoring, um Cluster-Drift zu verfolgen.
Fortgeschrittene Clustering-Strategien
Multi-View Clustering Kombinieren Sie verschiedene Datenperspektiven. Clustern Sie Kunden nach Kaufverhalten UND Support-Interaktionen UND Website-Aktivität. Offenbart reichhaltigere Segmente.
Semi-Supervised Clustering Integrieren Sie einige bekannte Labels zur Führung des Clusterings. „Wir wissen, dass dies VIP-Kunden sind, finde ähnliche Gruppen." Balanciert Entdeckung mit Geschäftswissen.
Dynamisches Clustering Cluster, die sich über Zeit entwickeln. Verfolgen Sie, wie Kunden zwischen Segmenten wechseln. Nutzen Sie Time Series Analysis, um Segmentübergänge vorherzusagen. Ermöglichen Sie proaktive Interventionen.
Clustering-Erfolg messen
Technische Metriken:
- Silhouette-Koeffizient (Cluster-Trennung)
- Davies-Bouldin-Index (Cluster-Kompaktheit)
- Calinski-Harabasz-Score (Cluster-Definition)
Geschäftsmetriken:
- Umsatz pro Cluster
- Marketing-Responseraten nach Cluster
- Retention-Unterschiede zwischen Clustern
- Betriebskosten pro Cluster
Umsetzbarkeitstest: Können Sie unterschiedliche Strategien pro Cluster erstellen? Wenn alle Cluster dieselbe Behandlung erhalten, ist Clustering gescheitert.
Branchenspezifisches Clustering
E-Commerce:
- Produktaffinitätsgruppen
- Shopping-Verhaltenssegmente
- Saisonale Käufer-Cluster
- Preissensitivitätsgruppen
B2B:
- Kontosegmentierung
- Nutzungsmuster-Gruppen
- Wachstumspotential-Cluster verbessert durch Predictive Analytics
- Risikoprofilsegmente
Gesundheitswesen:
- Patienten-Risikogruppen
- Behandlungsresponse-Cluster
- Ressourcennutzungssegmente
- Ergebnisprognose-Gruppen
Clustering für Sie arbeiten lassen
Schauen Sie, Clustering ist keine Magie. Aber wenn Sie alle Kunden gleich behandeln, lassen Sie Geld auf dem Tisch.
Starten Sie klein: Clustern Sie Ihre Top-1000-Kunden nach Kaufverhalten. Sie werden Segmente finden, die Sie nie für möglich gehalten haben.
Mehr erfahren
Erkunden Sie verwandte Konzepte, um Ihr Verständnis von Clustering und datengetriebener Entdeckung zu vertiefen:
- Unsupervised Learning - Die breitere Kategorie von ML-Techniken, die Muster ohne Labels entdecken
- Deep Learning - Fortgeschrittene neuronale Ansätze für komplexe Clustering-Aufgaben
- Neural Networks - Die zugrunde liegende Architektur moderner Clustering-Algorithmen
- Business Intelligence - Wie Clustering-Erkenntnisse in strategische Entscheidungsfindung einfließen
Externe Ressourcen
- Stanford HAI: Clustering Research - Akademische Forschung zu Clustering-Algorithmen
- Scikit-learn Clustering Guide - Praktische Implementierungsdokumentation
- Papers With Code: Clustering - Neueste Clustering-Techniken und Benchmarks
FAQ-Bereich
Häufig gestellte Fragen zu Clustering
Was ist Clustering?
Clustering ist eine Unsupervised Machine Learning-Technik, die ähnliche Datenpunkte basierend auf ihren Eigenschaften gruppiert und natürliche Muster entdeckt, ohne gesagt zu bekommen, wonach sie suchen soll.
Was ist der Unterschied zwischen Clustering und Klassifizierung?
Klassifizierung prognostiziert Kategorien, wenn Sie bereits wissen, welche Kategorien existieren. Clustering entdeckt unbekannte Gruppen in Daten ohne vordefinierte Labels oder Kategorien.
Was sind die vier Haupttypen von Clustering-Algorithmen?
K-Means (spezifiziere Clusteranzahl), Hierarchisch (baut Cluster-Baum), DBSCAN (findet beliebige Formen und Ausreißer) und Gaussian Mixture Models (nimmt statistische Verteilungen an).
Was sind die wichtigsten Vorteile von Clustering für Unternehmen?
Entdeckung verborgener Kundensegmente, verbesserte Personalisierung, besseres Marktverständnis, Ressourcenoptimierung und Identifizierung von Mustern, die traditionelle Segmentierung verpasst.
Was sind häufige Fallstricke bei der Clustering-Implementierung?
Falsche Clusteranzahl erzwingen (Daten leiten lassen), falsche Features verwenden (Fokus auf Verhalten über Demografie) und Cluster-Evolution ignorieren (Segmente ändern sich über Zeit).
Teil der [AI Terms Collection]. Zuletzt aktualisiert: 2026-07-21

Co-Founder, Rework.com
On this page
- Clustering verstehen
- Wie Clustering tatsächlich funktioniert
- Clustering-Anwendungen aus der Praxis
- Arten von Clustering-Algorithmen
- Der Clustering-Unterschied
- Wann Clustering Sinn macht
- Implementierungs-Roadmap
- Tools für Clustering
- Häufige Clustering-Fallstricke
- Fortgeschrittene Clustering-Strategien
- Clustering-Erfolg messen
- Branchenspezifisches Clustering
- Clustering für Sie arbeiten lassen
- Mehr erfahren
- Externe Ressourcen
- FAQ-Bereich