Apakah Clustering? Menemui Puak Tersembunyi dalam Data Anda
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
87% perniagaan mensegmen pelanggan dengan salah. Mereka menggunakan demografik asas - umur, pendapatan, lokasi - apabila emas sebenar terletak pada corak tingkah laku. Di sinilah clustering masuk. Ia adalah AI yang mencari kumpulan semula jadi dalam data anda, mendedahkan segmen yang anda tidak pernah tahu wujud. Seperti peruncit yang menemui "pembeli yogurt pagi Ahad" mereka adalah segmen paling menguntungkan.
Memahami Clustering
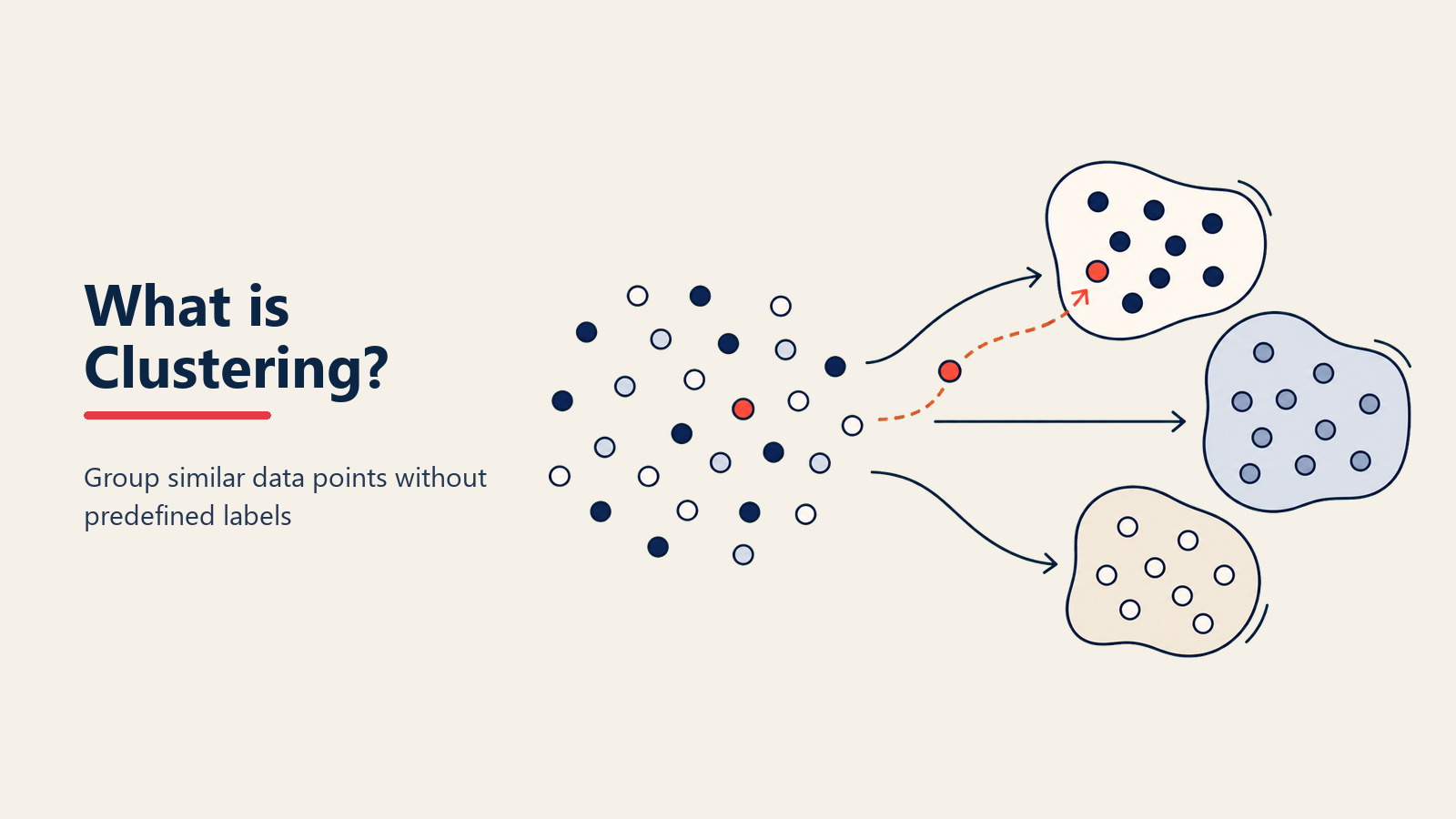
Anda tahu bagaimana orang secara semula jadi membentuk kumpulan di majlis? Peminat sukan tertarik bersama, ibu bapa mencari satu sama lain, orang teknologi berkumpul di sudut. Algoritma clustering melakukan perkara yang sama dengan data - mencari kumpulan semula jadi tanpa diberitahu apa yang perlu dicari.
Lebih teknikal, clustering adalah teknik unsupervised machine learning yang mengumpulkan titik data yang serupa berdasarkan ciri-ciri mereka. Tidak seperti klasifikasi (yang perlukan label), clustering menemui corak sendiri.
Perbezaan utama adalah penemuan berbanding ramalan. Klasifikasi supervised learning bertanya "Adakah pelanggan ini bernilai tinggi?" apabila anda sudah tahu apa maksud bernilai tinggi. Clustering bertanya "Apakah jenis pelanggan yang kita ada?" dan biarkan data mendedahkan jawapannya.
Bagaimana Clustering Sebenarnya Berfungsi
Clustering beroperasi melalui pengukuran kesamaan. Pertama, ia mewakili setiap titik data dalam ruang matematik - umur pelanggan mungkin satu dimensi, kekerapan pembelian satu lagi, nilai pesanan purata yang ketiga. Seperti memplot titik pada peta berbilang dimensi.
Kemudian, algoritma mengira jarak antara semua titik. Item yang serupa dekat bersama, item berbeza jauh. Pembeli mewah dan pembeli bajet mungkin jauh walaupun mereka umur dan lokasi yang sama.
Akhirnya, kumpulan terbentuk berdasarkan kedekatan. Algoritma melukis sempadan di sekitar kawasan padat titik yang serupa. Anda mungkin menemui lima segmen pelanggan yang berbeza di mana anda fikir anda ada dua.
Keajaiban berlaku dalam menentukan "kesamaan" - algoritma machine learning moden boleh mengendalikan beratus dimensi dan hubungan kompleks yang manusia tidak dapat visualisasikan.
Aplikasi Clustering Dunia Sebenar
Segmentasi Pelanggan Runcit Peruncit fesyen mengaplikasikan clustering pada sejarah pembelian, tingkah laku melayari, dan corak pemulangan. Menemui tujuh segmen termasuk "pengikut trend" (beli segera selepas pelancaran) dan "pemburu jualan" (hanya membeli item diskaun). Pemasaran diperibadikan kepada setiap segmen meningkatkan hasil 34%.
Kumpulan Pesakit Penjagaan Kesihatan Hospital mengkelompokkan data pesakit melebihi faktor risiko tradisional. Menemui subkumpulan yang bertindak balas berbeza kepada rawatan. Satu kelompok diabetes bertindak balas 3x lebih baik kepada campur tangan gaya hidup daripada ubat. Pemperibadian rawatan meningkatkan hasil 40%.
Penilaian Risiko Kewangan Bank mengkelompokkan pemohon pinjaman perniagaan kecil menggunakan metrik kewangan, data industri, dan corak transaksi. Mengenal pasti kelompok risiko yang terlepas oleh pemarkahan tradisional. Kadar mungkir menurun 25% manakala kadar kelulusan meningkat 15%.
Pengoptimuman Rantaian Bekalan Pengilang mengkelompokkan pembekal mengikut prestasi penghantaran, metrik kualiti, dan corak komunikasi. Mendedahkan corak kebolehpercayaan tersembunyi. Menstruktur semula hubungan pembekal, mengurangkan kelewatan sebanyak 30%.
Jenis Algoritma Clustering
K-Means Clustering Kuda beban clustering. Anda tentukan berapa banyak kelompok yang anda mahu, ia mencari kumpulan terbaik. Sempurna untuk segmentasi pelanggan di mana anda perlukan kumpulan berbeza yang tidak bertindih. Pantas dan boleh diskalakan.
Hierarchical Clustering Membina pokok kelompok - seperti mengatur syarikat daripada jabatan kepada pasukan kepada individu. Hebat apabila anda perlukan tahap keperincian yang berbeza. Rangkaian runcit menggunakan ini untuk kumpulan kedai.
DBSCAN (Berasaskan Kepadatan) Mencari kelompok bentuk sewenang-wenangnya dan mengenal pasti outlier. Cemerlang untuk pengesanan penipuan dan anomaly detection - transaksi normal berkumpul bersama, yang penipuan menonjol sebagai outlier.
Gaussian Mixture Models Menganggap data datang daripada pelbagai taburan statistik. Canggih tetapi berkuasa. Digunakan dalam pembuatan untuk mengenal pasti keadaan kualiti berbeza dalam pengeluaran.
Perbezaan Clustering
Sebelum Clustering: Pemasaran menghantar kempen sama kepada "Wanita 25-34" Selepas Clustering: Lima segmen berbeza dikenal pasti:
- Profesional fokus kerjaya (bertindak balas kepada mesej kecekapan)
- Ibu baru (nilai keselamatan dan kemudahan)
- Peminat kecergasan (mahu ciri prestasi)
- Pelajar prihatin bajet (sensitif harga)
- Pembeli prihatin eko (kemampanan penting)
Hasilnya: Kadar klik meningkat 250%. Khalayak sama, segmentasi lebih bijak.
Bila Clustering Masuk Akal
Bayangkan anda ada beribu-ribu produk tetapi tidak tahu bagaimana mengaturnya. Kategori tradisional (elektronik, pakaian) terlalu luas. Clustering mendedahkan kumpulan semula jadi berdasarkan cara pelanggan sebenarnya membeli-belah - "keperluan ambil-dan-pergi" atau "pembelian penyelidikan berat."
Atau katakan anda memasuki pasaran baru. Anda tidak tahu segmen pelanggan lagi. Clustering menganalisis pengguna awal dan mendedahkan jenis pengguna berbeza untuk disasarkan.
Peta Jalan Pelaksanaan
Minggu 1: Penyediaan Data
- Kumpul ciri yang relevan (tingkah laku > demografik)
- Bersih dan normalkan data melalui data curation yang betul (kritikal untuk clustering)
- Keluarkan outlier yang jelas
- Cipta ciri terbitan (nisbah, kekerapan)
Minggu 2: Penerokaan
- Cuba pelbagai algoritma
- Eksperimen dengan bilangan kelompok berbeza
- Sahkan hasil masuk akal perniagaan
- Dapatkan input pihak berkepentingan tentang kumpulan
Minggu 3-4: Pengesahan
- Uji kestabilan kelompok dari masa ke masa
- Pastikan kelompok boleh diambil tindakan
- Kira metrik perniagaan setiap kelompok
- Reka strategi khusus kelompok
Bulan 2+: Operasionalisasi
- Automasikan tugasan kelompok untuk data baru melalui amalan MLOps
- Cipta dashboard pemantauan
- Bangunkan rawatan khusus kelompok
- Ukur kesan dan perhalusi
Alat untuk Clustering
Penyelesaian Tanpa Kod:
- Tableau - Clustering terbina dalam ($70/pengguna/bulan)
- Microsoft Power BI - Ciri auto-clustering ($10/pengguna/bulan)
- Google Analytics 4 - Penemuan khalayak (Percuma dengan had)
Perpustakaan Python (Percuma):
- scikit-learn - Semua algoritma utama
- HDBSCAN - Clustering kepadatan lanjutan
- pyclustering - Algoritma khusus
Platform Perusahaan:
- SAS Enterprise Miner - Suite clustering penuh (Harga tersuai)
- IBM SPSS Modeler - Clustering visual ($99/pengguna/bulan)
- DataRobot - Clustering automatik ($75K+/tahun)
Perkhidmatan Cloud:
- AWS SageMaker - Clustering terbina dalam ($0.05/jam)
- Google Vertex AI - AutoML clustering ($20/jam)
- Azure ML - Modul clustering ($9.90/jam pengiraan)
Perangkap Clustering Biasa
Perangkap 1: Memaksa Bilangan Kelompok Yang Salah CEO mahu 5 segmen pelanggan kerana pesaing ada 5. Data dengan jelas menunjukkan 3 atau 8 kumpulan semula jadi. Penyelesaian: Biarkan data membimbing nombor kelompok. Gunakan plot elbow dan skor silhouette. Logik perniagaan patut memperhalusi, bukan menentukan.
Perangkap 2: Menggunakan Ciri Yang Salah Mengkelompokkan pelanggan mengikut umur dan pendapatan apabila tingkah laku pembelian berbeza lebih mengikut gaya hidup dan nilai. Penyelesaian: Fokus pada ciri tingkah laku dan transaksi. Demografik adalah pelakon sokongan, bukan peneraju.
Perangkap 3: Mengabaikan Evolusi Kelompok Segmen pelanggan ditentukan pada 2019, tidak pernah dikemaskini. COVID mengubah segalanya. Penyelesaian: Reclustering suku tahunan atau apabila peristiwa besar berlaku. Laksanakan model monitoring untuk menjejak drift kelompok.
Strategi Clustering Lanjutan
Multi-View Clustering Gabungkan perspektif data berbeza. Kelompokkan pelanggan mengikut tingkah laku pembelian DAN interaksi sokongan DAN aktiviti laman web. Mendedahkan segmen lebih kaya.
Semi-Supervised Clustering Masukkan beberapa label yang diketahui untuk membimbing clustering. "Kami tahu ini adalah pelanggan VIP, cari kumpulan yang serupa." Mengimbangi penemuan dengan pengetahuan perniagaan.
Dynamic Clustering Kelompok yang berkembang dari masa ke masa. Jejaki bagaimana pelanggan bergerak antara segmen. Gunakan time series analysis untuk meramal peralihan segmen. Membolehkan campur tangan proaktif.
Mengukur Kejayaan Clustering
Metrik Teknikal:
- Pekali silhouette (pemisahan kelompok)
- Indeks Davies-Bouldin (kekompakan kelompok)
- Skor Calinski-Harabasz (definisi kelompok)
Metrik Perniagaan:
- Hasil setiap kelompok
- Kadar respons pemasaran mengikut kelompok
- Perbezaan pengekalan antara kelompok
- Kos operasi setiap kelompok
Ujian Kebolehambiltindakan: Bolehkah anda cipta strategi berbeza setiap kelompok? Jika semua kelompok dapat rawatan sama, clustering gagal.
Clustering Khusus Industri
E-commerce:
- Kumpulan pertalian produk
- Segmen tingkah laku membeli-belah
- Kelompok pembeli bermusim
- Kumpulan kepekaan harga
B2B:
- Segmentasi akaun
- Kumpulan corak penggunaan
- Kelompok potensi pertumbuhan dipertingkatkan oleh predictive analytics
- Segmen profil risiko
Penjagaan Kesihatan:
- Kumpulan risiko pesakit
- Kelompok respons rawatan
- Segmen penggunaan sumber
- Kumpulan ramalan hasil
Menjadikan Clustering Berfungsi untuk Anda
Lihat, clustering bukan sihir. Tetapi jika anda merawat semua pelanggan sama, anda meninggalkan wang di atas meja.
Mulakan kecil: kelompokkan 1000 pelanggan teratas anda mengikut tingkah laku pembelian. Anda akan menemui segmen yang anda tidak pernah bayangkan.
Ketahui Lebih Lanjut
Terokai konsep berkaitan untuk memperdalam pemahaman anda tentang clustering dan penemuan berdasarkan data:
- Unsupervised Learning - Kategori lebih luas teknik ML yang menemui corak tanpa label
- Deep Learning - Pendekatan neural lanjutan untuk tugas clustering kompleks
- Neural Networks - Seni bina asas yang menggerakkan algoritma clustering moden
- Business Intelligence - Bagaimana insight clustering dimasukkan ke dalam pembuatan keputusan strategik
Sumber Luar
- Stanford HAI: Clustering Research - Penyelidikan akademik tentang algoritma clustering
- Scikit-learn Clustering Guide - Dokumentasi pelaksanaan praktikal
- Papers With Code: Clustering - Teknik clustering terkini dan penanda aras
Bahagian FAQ
Soalan Lazim tentang Clustering
Apakah Clustering?
Clustering adalah teknik unsupervised machine learning yang mengumpulkan titik data yang serupa berdasarkan ciri-ciri mereka, menemui corak semula jadi tanpa diberitahu apa yang perlu dicari.
Apakah perbezaan antara clustering dan classification?
Classification meramal kategori apabila anda sudah tahu kategori apa yang wujud. Clustering menemui kumpulan yang tidak diketahui dalam data tanpa label atau kategori yang telah ditentukan.
Apakah empat jenis utama algoritma clustering?
K-Means (tentukan bilangan kelompok), Hierarchical (membina pokok kelompok), DBSCAN (mencari bentuk sewenang-wenangnya dan outlier), dan Gaussian Mixture Models (mengandaikan taburan statistik).
Apakah faedah utama clustering untuk perniagaan?
Penemuan segmen pelanggan tersembunyi, pemperibadian ditingkatkan, pemahaman pasaran lebih baik, pengoptimuman sumber, dan pengenalan corak yang terlepas oleh segmentasi tradisional.
Apakah perangkap biasa dalam pelaksanaan clustering?
Memaksa bilangan kelompok yang salah (biarkan data membimbing), menggunakan ciri yang salah (fokus pada tingkah laku berbanding demografik), dan mengabaikan evolusi kelompok (segmen berubah dari masa ke masa).
Sebahagian daripada [Koleksi Istilah AI]. Dikemaskini terakhir: 2026-07-21

Co-Founder, Rework.com
On this page
- Memahami Clustering
- Bagaimana Clustering Sebenarnya Berfungsi
- Aplikasi Clustering Dunia Sebenar
- Jenis Algoritma Clustering
- Perbezaan Clustering
- Bila Clustering Masuk Akal
- Peta Jalan Pelaksanaan
- Alat untuk Clustering
- Perangkap Clustering Biasa
- Strategi Clustering Lanjutan
- Mengukur Kejayaan Clustering
- Clustering Khusus Industri
- Menjadikan Clustering Berfungsi untuk Anda
- Ketahui Lebih Lanjut
- Sumber Luar
- Bahagian FAQ