Why RevOps Fails: 9 Failure Modes That Break Revenue Operations
RevOps rarely fails because the team cannot build a dashboard.
It fails because the company gives RevOps responsibility without authority. Or starts with automation before process is clear. Or lets every function keep its own definitions. Or turns RevOps into a ticket queue and still expects it to redesign the revenue system.
The title is easy. The operating mandate is hard.
Use this article as a failure-mode checklist after reading What Is Revenue Operations? and the Revenue Operations Framework.
Forrester has written that successful revenue operations structures can range from decentralized to fully centralized. That is a useful reminder: RevOps failure is not caused by picking the wrong org chart alone. It is usually caused by weak operating rules.
Key operating facts
- RevOps usually fails from weak mandate, unclear authority, fragmented definitions, poor data governance, and local optimization across functions.
- Dashboards, automation, and tooling do not fix unclear process. They often make confusion more visible or faster.
- The most important early protection is a written charter, RACI, source-of-truth model, and operating cadence.
- Failure should be diagnosed by operating symptom: slow decisions, conflicting numbers, handoff leakage, forecast mistrust, or backlog overload.
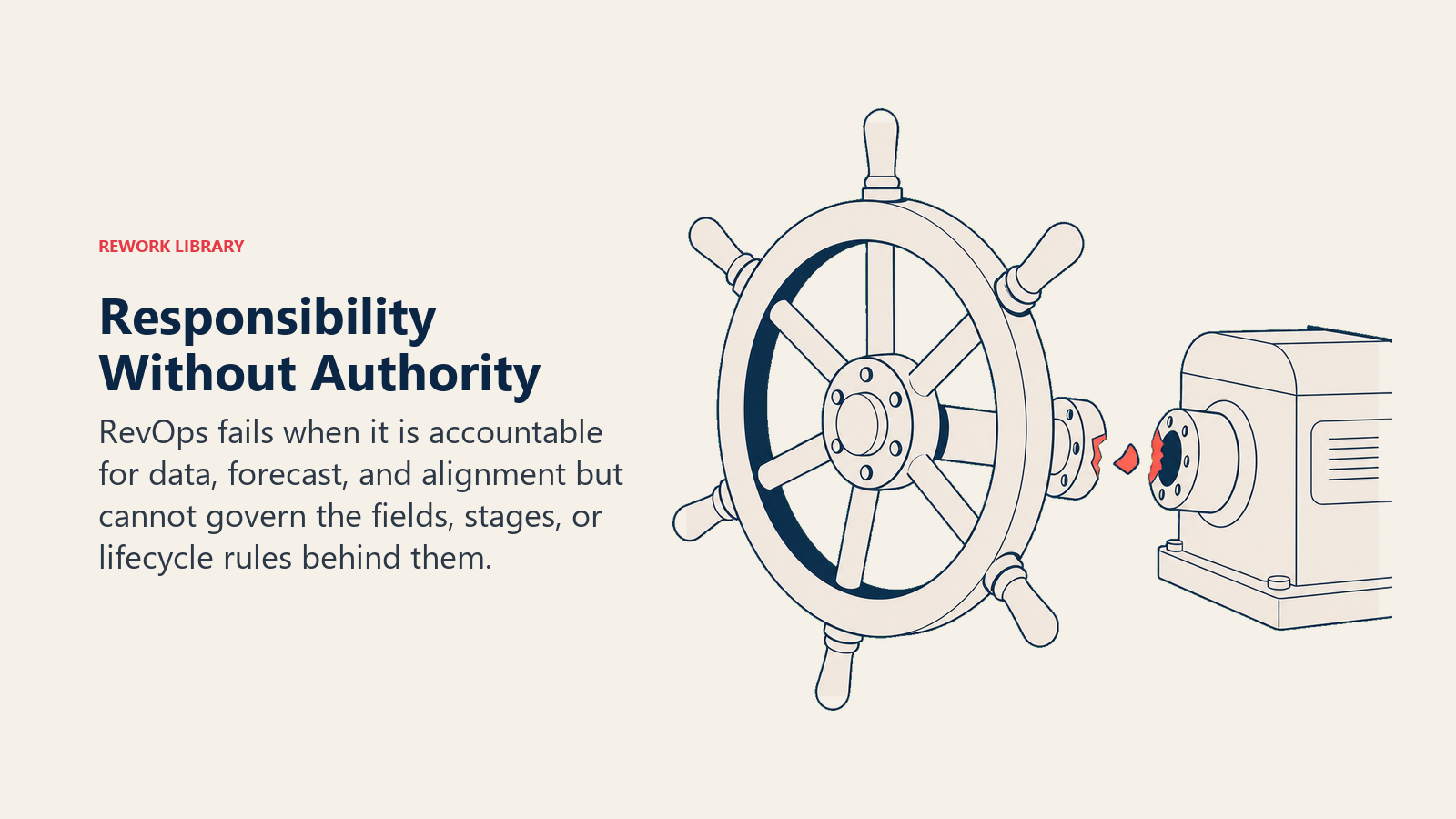
1. RevOps has responsibility without authority
This is the most common failure.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
RevOps is told to improve data quality, but cannot enforce required fields. It is told to improve forecast accuracy, but cannot change stage definitions. It is told to align marketing and sales, but cannot govern lifecycle rules.
The work becomes performative. RevOps is accountable for outcomes it cannot control.
Fix it by writing a RevOps Charter. The charter should define scope, decision rights, escalation paths, and what RevOps can change without asking every functional leader.
Failure diagnosis table
Use symptoms to identify the failure mode.
| Symptom | Likely failure mode | First fix |
|---|---|---|
| RevOps owns data quality but fields keep multiplying | No field governance authority | Define field intake and approval rights |
| Leaders debate which number is correct | No source-of-truth model | Map winning systems and report definitions |
| Forecast calls spend time cleaning CRM | Inspection happens too late | Move hygiene into pipeline inspection cadence |
| Marketing and sales argue about lead quality every month | Lifecycle criteria are unclear | Rewrite MQL, SQL, rejection, and acceptance rules |
| RevOps backlog grows but strategy does not improve | RevOps is a ticket queue | Add roadmap governance and impact scoring |
| CS learning never changes acquisition | Post-sale data is disconnected | Add churn and expansion feedback loops |
This table helps avoid generic advice. "RevOps is failing" is too broad to fix. The operating symptom tells you whether the first repair is authority, definition, cadence, data, or ownership.
2. The company starts with dashboards
Dashboards look like progress. They are visible, shareable, and executive-friendly.
But dashboards built on unclear stages and bad fields only make bad data easier to see.
If "pipeline created" means one thing to sales and another thing to marketing, a dashboard will not fix the debate. If opportunity stages are subjective, a forecast dashboard will not make the forecast trustworthy.
Fix definitions before charts. Define lifecycle stages, entry criteria, owners, and source-of-truth rules. Then build reporting.
3. Sales Ops gets renamed RevOps
Sales Ops is valuable, but renaming it does not create cross-functional authority.
If the team still only owns sales reports, sales stages, and CRM admin, then it is Sales Ops with a broader title. RevOps requires authority across marketing, sales, CS, finance, data, and systems.
See RevOps vs Sales Ops for the distinction.
4. Every team keeps its own source of truth
Marketing reports from the MAP. Sales reports from CRM. CS reports from a customer success platform. Finance reports from billing and spreadsheets.
Each system may be useful locally, but the company cannot run revenue from four conflicting truths.
This failure shows up in leadership meetings. Marketing says one campaign influenced a deal. Sales says the opportunity source is outbound. Finance says neither number matches the bookings report. The meeting becomes data reconciliation instead of decision-making.
Fix it with Source of Truth for Revenue Data and a Revenue Data Dictionary.
5. Automation scales broken process
Automation is not a substitute for operating design.

If the lead qualification rule is unclear, automated routing creates faster confusion. If stage criteria are weak, automated forecast scoring produces confident noise. If handoff data is incomplete, workflow automation sends incomplete records faster.
Good automation enforces a clear rule. Bad automation hides an unclear one.
Fix the workflow first. Automate second. Start with Full-Funnel SLA Model, Stage Exit Criteria, and RevOps Automation.
6. RevOps becomes a ticket queue
Field request. Report request. Dashboard request. Import request. Integration request.
All of that work may be necessary, but if it consumes all capacity, RevOps cannot improve the system. It becomes a help desk.
The symptom is that every week is busy and nothing systemic gets better. The same data problems return. The same handoff issues return. The same meetings produce the same complaints.
Protect proactive capacity. A healthy RevOps roadmap should include governance, process improvement, data quality, and cadence work, not only requests.
7. Cadence is confused with meetings
More meetings do not create operating discipline.
A revenue cadence needs a purpose, data packet, decision owner, and follow-up path. A forecast call should inspect revenue risk. A funnel review should inspect conversion and velocity. A systems governance review should approve or reject changes.
If a meeting ends without a decision, owner, or change in behavior, it is not cadence. It is discussion.
Fix meeting sprawl by designing a Revenue Cadence.
8. Data quality is treated as cleanup
Bad CRM data is not a quarterly cleanup problem. It is a continuous operating problem.
Salesforce research has found that sellers spend most of their time on non-selling tasks. If data capture is too painful or governance is weak, the CRM decays again after every cleanup.
Fix the capture process, required fields, duplicate rules, and adoption model. See CRM Data Hygiene, CRM Adoption Operating Model, and Required Fields vs Useful Fields.
9. RevOps is measured only by output
If RevOps is measured by number of reports shipped or tickets closed, the team will optimize for activity.
Better measures include forecast accuracy, stage hygiene, SLA compliance, handoff completeness, source-to-revenue visibility, field completeness, and reduction in manual reporting work.
Use RevOps Metrics to define those measures.
The failure pattern
Most RevOps failures follow the same sequence:
- Leadership sees cross-functional revenue friction.
- A RevOps person or team is assigned.
- The team is asked to fix reports and systems quickly.
- Decision rights remain unclear.
- Functional teams keep local control over shared definitions.
- RevOps becomes a request queue.
- Dashboards improve, but the operating system does not.
The fix is not to work harder. It is to reset the mandate.
How to detect failure early
RevOps failure usually shows up before executives name it.
Watch for these signals:
- Revenue leaders ask for the same report repeatedly because they do not trust the dashboard.
- Marketing and sales debate definitions in every funnel review.
- Finance maintains a separate forecast file.
- CS says customer handoff issues are "a sales discipline problem" but no workflow changes.
- RevOps spends more than half its week on one-off requests.
- CRM fields are added faster than they are retired.
- Automation is added to workflows no one has documented.
- Leadership praises RevOps activity but cannot name which revenue process has improved.
These signals do not mean the team is bad. They mean the operating model is weak.
What leaders should do differently
Executives often unintentionally cause RevOps failure.
They ask for dashboards before definitions. They ask for automation before agreeing on handoffs. They hold RevOps accountable for data quality while allowing every function to change fields. They call RevOps strategic but route every urgent report request to the same team.
The leadership fix is simple but uncomfortable: give RevOps real decision rights.
That includes the right to say:
- No to fields without owners.
- No to dashboards based on unclear definitions.
- No to automation before process design.
- No to system changes that break shared reporting.
- No to urgent requests that should enter governance cadence.
RevOps cannot be both the owner of revenue operating quality and an unlimited service desk. Leaders need to choose which role matters more.
Recovery example
Consider a company where the forecast is not trusted.
The weak response is to ask RevOps for a better forecast dashboard. The stronger response is to diagnose why the forecast is weak:
- Are stages evidence-based?
- Are close dates stale?
- Are commit criteria clear?
- Are managers inspecting next steps?
- Are required fields complete?
- Does finance agree with the forecast categories?
The fix might involve Forecast Governance, Commit Criteria, and Pipeline Inspection Cadence. The dashboard comes after the operating rules.
Failure mode by company stage
RevOps fails differently at different stages.
| Stage | Common failure |
|---|---|
| Early revenue team | RevOps is hired before the sales motion is stable |
| First marketing plus sales engine | Lead definitions are not shared |
| Scaling sales team | Sales Ops is renamed RevOps without cross-functional authority |
| Recurring revenue motion | CS data is left outside the revenue operating model |
| Multi-segment company | Dashboards do not split by segment, motion, or source |
| Mature mid-market company | Governance becomes slow and teams build workarounds |
The fix should match the stage. An early company may need less governance and more clarity. A mature company may need stronger change control and better intake discipline.
What healthy RevOps looks like instead
Healthy RevOps has a few observable traits:
- Leaders use the same revenue definitions.
- Forecast calls are about risk, not basic cleanup.
- Handoffs have owners and required data.
- Dashboards are tied to decisions.
- CRM changes have a governance path.
- RevOps has roadmap capacity every month.
- Functional teams know when they can act locally and when they need approval.
The simplest test: when something breaks between teams, does everyone know who owns the fix? If not, RevOps is still missing the authority or clarity it needs.
What to measure during recovery
Do not measure recovery by activity volume.
Track whether the operating system is getting healthier:
- Required-field completeness improves.
- MQL rejection reasons are captured consistently.
- Forecast cleanup time drops.
- Closed-won handoff completeness rises.
- Duplicate record rate falls.
- Fewer reports require manual reconciliation.
- Revenue meetings produce decisions instead of data debates.
These measures show whether RevOps is fixing root causes. A team can close many tickets and still leave the system weak. A recovery effort should make future work easier, not only clear the current backlog.
Review these measures monthly with the CRO, finance, and functional leaders. If the measures do not improve after a quarter, the recovery plan is probably treating symptoms. That is the point to revisit decision rights, reporting lines, and intake rules rather than asking the same RevOps team to work faster.
The review should be blunt. If leaders keep approving local exceptions that weaken shared definitions, RevOps will not recover. If every urgent dashboard request skips governance, reporting quality will not improve. Recovery requires leadership behavior to change, not only RevOps behavior across the company.
That is the real test.
Recovery plan
If RevOps is already failing, do not start with a new dashboard or tool.
Start here:
| Step | Action |
|---|---|
| 1 | Rewrite the RevOps charter |
| 2 | Define decision rights with a RACI |
| 3 | Audit lifecycle stages and required fields |
| 4 | Pick the three highest-leakage handoffs |
| 5 | Build one trusted executive dashboard |
| 6 | Create a monthly governance cadence |
| 7 | Protect proactive RevOps roadmap capacity |
This sequence gives RevOps the authority and focus it needs before adding more work.
Recovery plan takeaway
RevOps usually fails for operating reasons, not because the idea is weak. The function needs a mandate, decision rights, clean prioritization, and a clear way to connect data, process, systems, and leadership cadence.
Without those pieces, RevOps becomes a helpful team with no authority over the system it is expected to improve. A failing RevOps function should be repaired by clarifying ownership first, then by fixing the highest-leakage handoffs and source-of-truth problems.
That repair work has to be visible.
Leaders need to see which ownership decisions changed, which handoffs improved, and which reports became trustworthy again.
Monday recovery actions
If RevOps is already struggling, start with a small set of visible actions.
| Day-one action | Why it helps |
|---|---|
| Freeze non-urgent field and dashboard changes for two weeks | Stops new system drift while the team diagnoses |
| List the top ten recurring requests | Reveals whether RevOps is trapped in ticket work |
| Audit one lifecycle path from lead to renewal | Shows where definitions and handoffs break |
| Pick one executive source of truth | Reduces reporting debates immediately |
| Create an exception log | Turns process breaks into data instead of anecdotes |
| Review RevOps decision rights with the sponsor | Tests whether the function can govern or only advise |
These actions are not a full transformation. They create enough control to see the real problem.
Recovery sequencing
Do not recover by rebuilding every tool and dashboard at once.
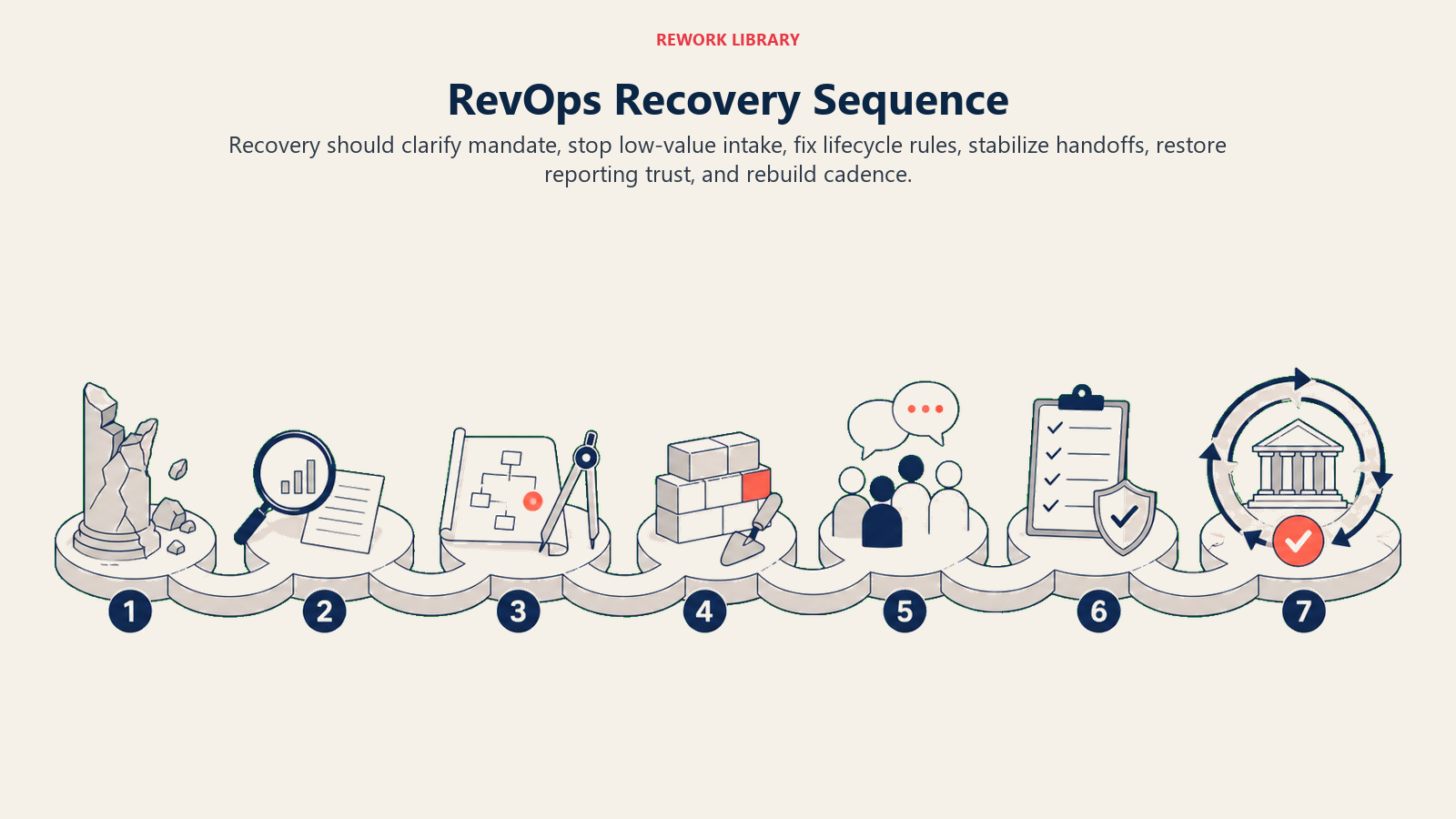
Use this sequence:
- Clarify mandate and sponsor.
- Stop low-value intake.
- Fix lifecycle definitions.
- Stabilize the highest-risk handoff.
- Pick one trusted executive dashboard.
- Add systems change control.
- Rebuild cadence around decisions.
- Expand roadmap only after trust improves.
This sequence works because RevOps failure is usually cumulative. Weak authority creates poor intake. Poor intake prevents process work. Weak process makes dashboards untrusted. Untrusted dashboards create more manual requests. Recovery has to break that loop.
Frequently Asked Questions about Why RevOps Fails
Why do RevOps teams fail?
Most fail because the mandate is unclear. They are asked to improve cross-functional revenue performance without the authority to govern definitions, data, systems, or handoffs.
What is the first sign RevOps is failing?
The first sign is usually trust decay. Leaders stop trusting dashboards, teams use shadow spreadsheets, and meetings become arguments about data instead of decisions.
How do you fix a failing RevOps function?
Rewrite the charter, clarify decision rights, simplify lifecycle definitions, clean the core data model, and protect RevOps capacity for proactive system work.
Is RevOps failure usually a people problem?
Not usually. It is more often an operating model problem: unclear ownership, weak governance, poor data, or a reporting line that gives RevOps accountability without authority.
Learn more

Senior Operations & Growth Strategist
On this page
- 1. RevOps has responsibility without authority
- Failure diagnosis table
- 2. The company starts with dashboards
- 3. Sales Ops gets renamed RevOps
- 4. Every team keeps its own source of truth
- 5. Automation scales broken process
- 6. RevOps becomes a ticket queue
- 7. Cadence is confused with meetings
- 8. Data quality is treated as cleanup
- 9. RevOps is measured only by output
- The failure pattern
- How to detect failure early
- What leaders should do differently
- Recovery example
- Failure mode by company stage
- What healthy RevOps looks like instead
- What to measure during recovery
- Recovery plan
- Recovery plan takeaway
- Monday recovery actions
- Recovery sequencing
- Learn more