O que é Transformer Architecture? O Projeto Que Mudou a IA para Sempre
 Antes de 2017, a IA lutava com documentos longos e perdia contexto rapidamente. Então vieram os Transformers – a arquitetura por trás do ChatGPT, BERT e virtualmente cada avanço na IA moderna. Entender esta inovação ajuda você a compreender por que a IA generativa de hoje é tão poderosa e o que é possível para seu negócio.
Antes de 2017, a IA lutava com documentos longos e perdia contexto rapidamente. Então vieram os Transformers – a arquitetura por trás do ChatGPT, BERT e virtualmente cada avanço na IA moderna. Entender esta inovação ajuda você a compreender por que a IA generativa de hoje é tão poderosa e o que é possível para seu negócio.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Avanço Técnico
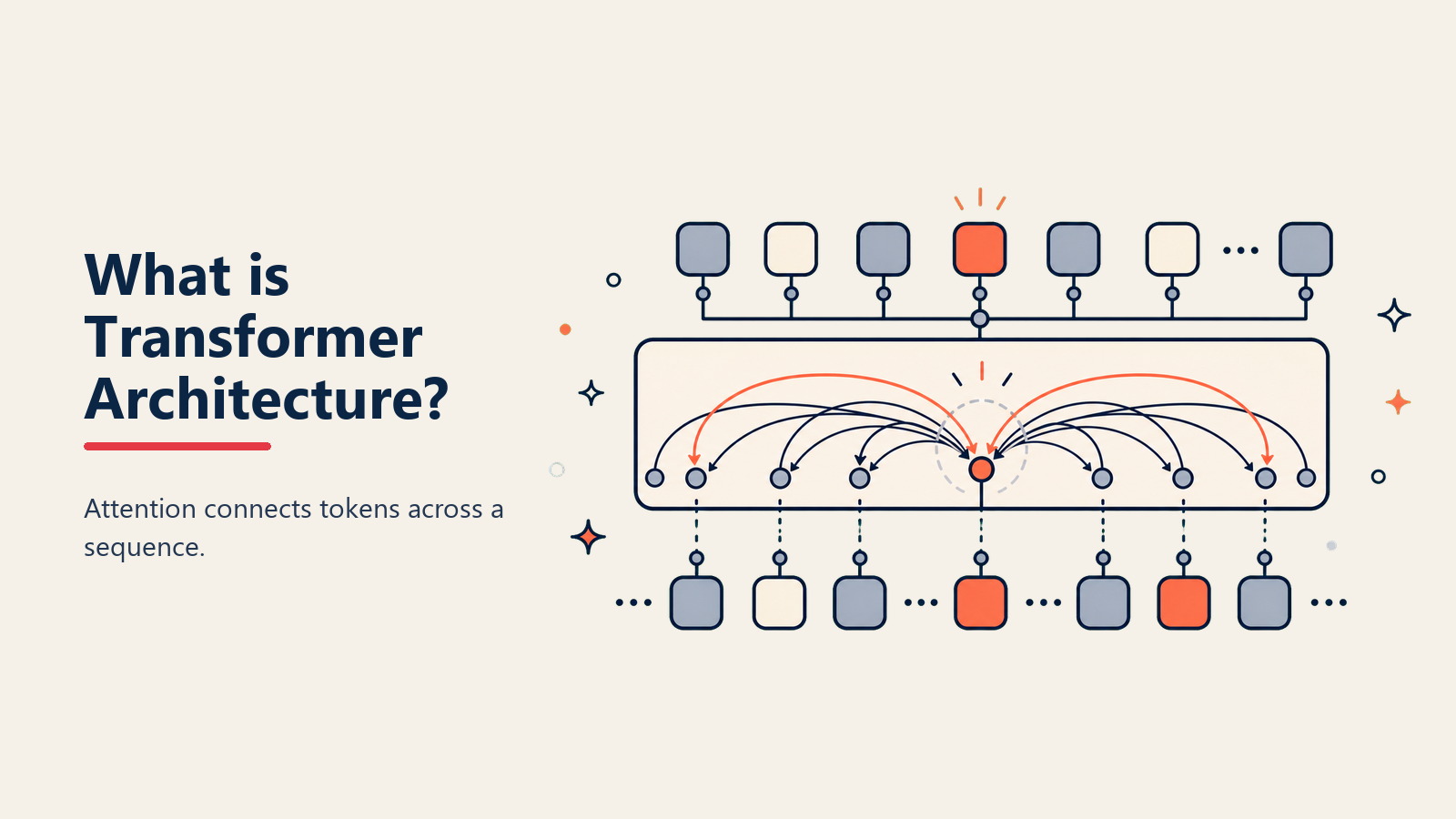
O Transformer é uma arquitetura de rede neural introduzida no artigo histórico "Attention Is All You Need" (2017) por pesquisadores do Google. Ele revolucionou a IA processando sequências inteiras simultaneamente em vez de palavra por palavra, usando um mecanismo chamado self-attention para entender relações entre todas as partes da entrada.
De acordo com o artigo original, "Transformers dispensam recorrência e convoluções inteiramente, dependendo apenas de mecanismos de atenção para extrair dependências globais entre entrada e saída." Este processamento paralelo tornou o treinamento 100x mais rápido enquanto melhorava a qualidade.
A eficiência e eficácia da arquitetura levaram ao renascimento da IA que estamos vivenciando, possibilitando modelos com bilhões de parâmetros que entendem contexto como nunca antes.
Impacto nos Negócios
Para líderes empresariais, Transformer architecture é por que a IA moderna pode ler contratos inteiros, manter contexto em conversas longas e gerar relatórios coerentes – é o avanço de engenharia que tornou a IA verdadeiramente útil para tarefas empresariais complexas.
Pense na IA anterior como alguém lendo um livro através de um buraco de fechadura, vendo uma palavra de cada vez e esquecendo partes anteriores. Transformers são como ler a página inteira de uma vez, entendendo como cada palavra se relaciona com todas as outras palavras instantaneamente.
Em termos práticos, Transformers possibilitam bots de atendimento ao cliente que lembram toda a conversa, análise de documentos que entende relações complexas e geração de conteúdo que mantém consistência em páginas.
Componentes Principais
Transformers consistem em inovações-chave:
• Mecanismo de Self-Attention: Permite que cada palavra "atenda" a todas as outras palavras, entendendo relações como pronomes referindo-se a substantivos anteriores
• Codificação Posicional: Adiciona informação sobre ordem de palavras já que Transformers processam todas as palavras simultaneamente, não sequencialmente
• Multi-Head Attention: Múltiplos mecanismos de atenção funcionando em paralelo, cada um aprendendo diferentes tipos de relações
• Redes Feed-Forward: Processam a informação atendida para extrair significado e gerar saídas
• Empilhamento de Camadas: Múltiplos blocos transformer empilhados profundamente, cada um refinando compreensão progressivamente
Como Transformers Funcionam
O processo Transformer simplificado:
Codificação de Entrada: Texto convertido para embeddings com informação de posição adicionada para preservar ordem de sequência
Cálculo de Self-Attention: Cada token calcula sua relação com todos os outros tokens, criando pesos de atenção
Integração de Contexto: Pesos de atenção combinam informação de partes relevantes da entrada para cada posição
Processamento de Camadas: Múltiplas camadas refinam compreensão, com cada camada construindo sobre insights anteriores
Geração de Saída: Representações finais usadas para tarefas como classificação, tradução ou geração de texto
Este processamento paralelo é por que Transformers treinam mais rápido e escalam melhor que arquiteturas anteriores.
Variantes de Transformer
Designs diferentes para necessidades diferentes:
BERT (Bidirecional) Foco: Entender contexto de ambas as direções Melhor para: Busca, classificação, resposta a perguntas Exemplo: Compreensão de busca do Google
GPT (Autorregressivo) Foco: Gerar texto da esquerda para direita Melhor para: Criação de conteúdo, conversa Exemplo: ChatGPT, assistentes de escrita
T5 (Texto-para-Texto) Foco: Enquadrar todas as tarefas como geração de texto Melhor para: Aplicações versáteis Exemplo: Tradução, sumarização
Vision Transformer (ViT) Foco: Aplicar transformers a imagens Melhor para: Tarefas de visão computacional Exemplo: Classificação de imagens, imagem médica
Aplicações Empresariais
Transformers alimentando soluções:
Exemplo de Tech Jurídica: Escritórios de advocacia usam sistemas baseados em BERT para analisar contratos, encontrando cláusulas relevantes em documentos de 100 páginas em segundos, entendendo contexto que busca por palavra-chave perderia, reduzindo tempo de revisão em 90%.
Exemplo de Saúde: O Med-PaLM 2 do Google (baseado em Transformer) alcançou desempenho de nível especialista em exames médicos entendendo contextos médicos complexos, possibilitando assistência de IA para diagnóstico e planejamento de tratamento.
Exemplo de Finanças: O DocAI do JPMorgan usa Transformers para processar milhões de documentos financeiros, entendendo contexto entre páginas para extrair insights que impulsionam decisões de negociação e avaliação de risco.
Por Que Transformers Dominam
Vantagens-chave impulsionando adoção:
Paralelização:
- Processar sequências inteiras simultaneamente
- 100x mais rápido treinamento que RNNs
- Escala eficientemente com hardware
Dependências de Longo Alcance:
- Mantém contexto ao longo de milhares de tokens
- Entende relações em nível de documento
- Lida com tarefas de raciocínio complexo
- Pré-treinar uma vez, fazer fine-tune para muitas tarefas
- Reduz requisitos de dados drasticamente
- Possibilita implantação rápida
Versatilidade:
- Funciona para texto, imagens, áudio, código
- Mesma arquitetura, diferentes aplicações
- Abordagem unificada para IA
Limitações de Transformer
Entendendo restrições:
• Custo Computacional: Atenção escala quadraticamente com comprimento de sequência → Solução: Variantes eficientes de atenção
• Janelas de Contexto: Ainda limitado a milhares de tokens → Solução: Processamento hierárquico, aumento de recuperação
• Fome de Dados: Requer conjuntos de dados massivos de pré-treinamento → Solução: Few-shot learning, fine-tuning eficiente
• Interpretabilidade: Padrões de atenção complexos difíceis de explicar → Solução: Ferramentas de visualização de atenção
Direções Futuras
Para onde Transformers estão indo:
- Janelas de contexto mais longas (1M+ tokens)
- Mecanismos de atenção mais eficientes
- Compreensão multimodal
- Implantação em dispositivos de borda
- Modelagem de sequências biológicas
Saiba Mais
Explore conceitos relacionados para aprofundar sua compreensão:
- Mecanismo de Atenção - A inovação principal alimentando Transformers
- Modelos de Linguagem Grandes - Como Transformers escalam para bilhões de parâmetros
- Fine-tuning - Personalizando modelos Transformer para seus casos de uso
- Deep Learning - O campo mais amplo que Transformers revolucionaram
Recursos Externos
- Jay Alammar's Blog - As melhores explicações visuais de arquitetura transformer e mecanismos de atenção
- Hugging Face Blog - Guias práticos para implementar e fazer fine-tune de modelos transformer
- Google AI Research - Pesquisa original de transformer e últimas inovações arquiteturais
Seção de FAQ
Perguntas Frequentes sobre Transformer Architecture
O que é Transformer Architecture?
Transformer é uma arquitetura de rede neural que processa sequências inteiras simultaneamente usando mecanismos de atenção, possibilitando processamento paralelo e melhor compreensão de contexto do que modelos sequenciais anteriores.
Qual é a diferença entre Transformers e arquiteturas de IA anteriores?
Arquiteturas anteriores (RNNs, LSTMs) processavam sequências palavra por palavra sequencialmente. Transformers processam todas as palavras simultaneamente usando self-attention, tornando-os 100x mais rápidos para treinar e melhores em dependências de longo alcance.
Quais são os principais tipos de modelos Transformer?
BERT (compreensão bidirecional), GPT (geração de texto), T5 (texto-para-texto) e Vision Transformer/ViT (processamento de imagem). Cada um otimizado para diferentes tarefas.
O que é self-attention em Transformers?
Self-attention é um mecanismo onde cada token (palavra) pode atender diretamente a todos os outros tokens na sequência, entendendo relações independentemente da distância entre palavras.
Parte da [Coleção de Termos de AI]. Última atualização: 2026-01-11
