Was ist Self-Attention? Die geheime Zutat hinter AIs Sprachverständnis
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Stellen Sie sich vor, Sie lesen "The bank was steep" versus "The bank was closed." Wie wissen Sie sofort, dass das eine Flussufer bedeutet und das andere eine Finanzinstitution? Ihr Gehirn nutzt Kontext - betrachtet alle Wörter zusammen, nicht nur in Reihenfolge. Genau das macht Self-Attention für AI, und deshalb kann ChatGPT tatsächlich verstehen, was Sie meinen.
Die Self-Attention-Story
Vor 2017 lasen AI-Modelle Text wie ein Schnellleser mit Tunnelblick - ein Wort nach dem anderen, wobei früherer Kontext vergessen wurde. Übersetzung war holprig. Verständnis war oberflächlich. Dann führten Google-Forscher Self-Attention in ihrem Paper "Attention Is All You Need" ein.
Spulen wir vor in die Gegenwart: Self-Attention hat revolutioniert, wie AI Sprache, Bilder und sogar DNA-Sequenzen versteht. Es ist die Grundlage von GPT, BERT und praktisch jedem Durchbruchsmodell im Natural Language Processing.
Für moderne Unternehmen bedeutet dies AI, die tatsächlich Kontext erfasst, Nuancen versteht und menschenähnliche Antworten liefert. Deshalb wurden Kundenservice-Bots plötzlich intelligent und warum AI nun kohärente Marketing-Texte schreiben kann.
Wie Self-Attention tatsächlich funktioniert
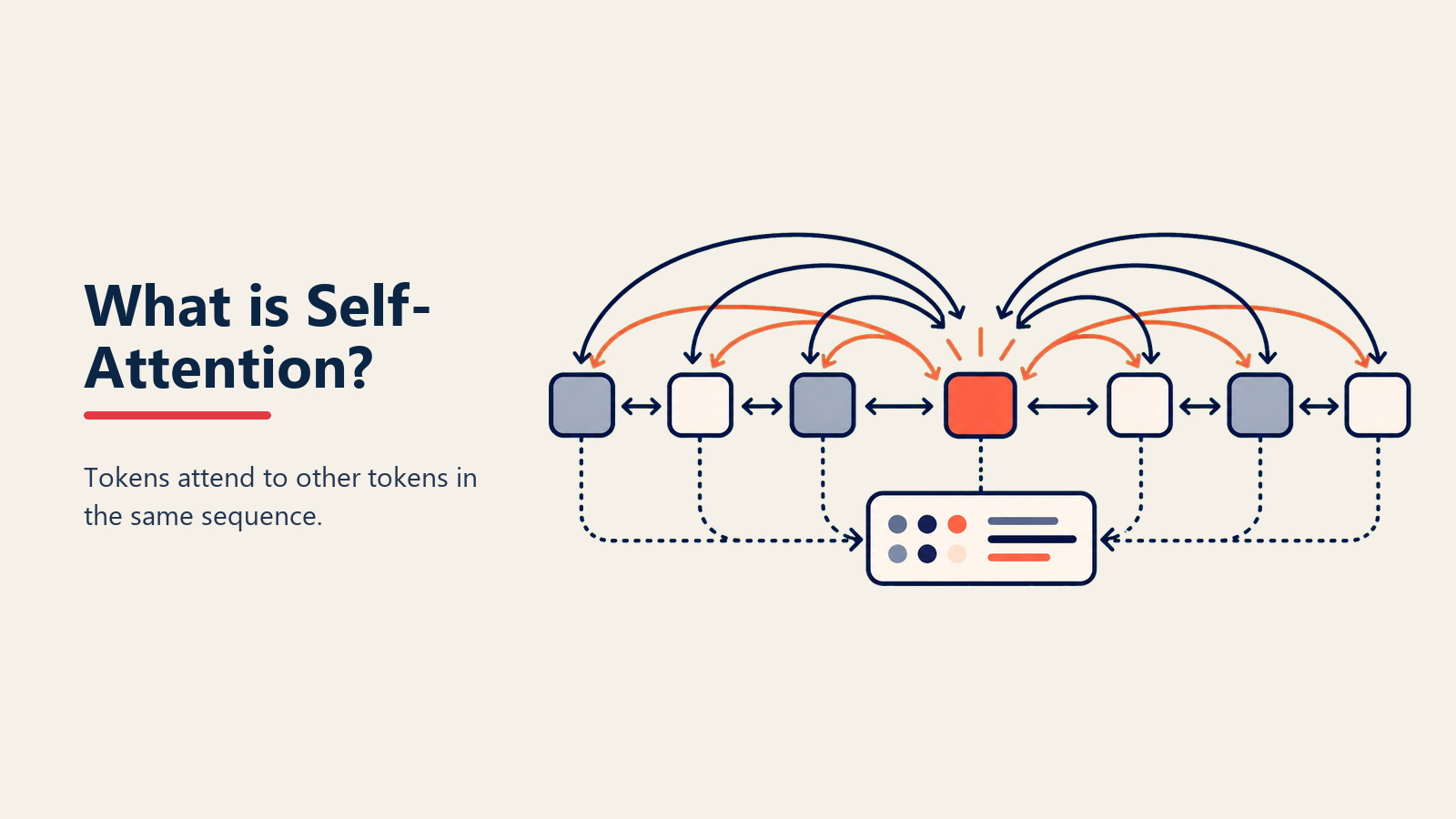
Self-Attention arbeitet durch einen elegant einfachen Prozess. Zunächst betrachtet es jedes Wort (oder Token) in Ihrer Eingabe gleichzeitig - nicht sequenziell. Wie Augen, die sich auf mehrere Dinge gleichzeitig fokussieren können.
Dann berechnet es für jedes Wort, wie viel Aufmerksamkeit jedem anderen Wort geschenkt werden soll. Bei der Verarbeitung von "The cat sat on the mat" weiß es, dass "cat" viel Aufmerksamkeit auf "sat" (was hat die Katze getan?) und "mat" (wo saß sie?) richten sollte.
Schließlich erstellt es angereicherte Repräsentationen, bei denen jedes Wort Informationen über seine Beziehungen zu allen anderen Wörtern enthält. "Bank" weiß nun, ob es in der Nähe von "river" oder "money" steht.
Die Magie geschieht durch mathematische Operationen, die diese Beziehungen bewerten und eine Attention-Map erstellen, die Bedeutung jenseits einzelner Wörter erfasst.
Der geschäftliche Einfluss von Self-Attention
Kundenservice-Revolution Vor Self-Attention: "I can't log in to my account" → Generische Passwort-Zurücksetz-Anweisungen. Nach Self-Attention: AI versteht den vollen Kontext, stellt relevante Rückfragen, bietet spezifische Lösungen. Lösungsraten verbesserten sich um 45%.
Content-Generierung Marketing-Teams nutzen nun Self-Attention-basierte Tools, um kontextuell relevante Inhalte zu erstellen. Eine Agentur produziert 10x mehr personalisierte E-Mail-Kampagnen mit besserem Engagement als manuelles Schreiben.
Dokumentenanalyse Anwaltskanzleien nutzen Self-Attention-Modelle zur Vertragsüberprüfung. Die AI versteht Beziehungen zwischen Klauseln und erkennt Probleme, die menschliche Prüfer übersehen. Prüfungszeit um 70% reduziert, Genauigkeit um 25% gestiegen.
Code-Verständnis Entwicklungsplattformen nutzen Self-Attention, um Programmierabsichten zu verstehen. Autocomplete-Vorschläge sind nun kontextbewusst und steigern die Entwicklerproduktivität um 40%.
Typen von Attention-Mechanismen
Single-Head Attention Wie ein Spotlight auf einen Aspekt von Beziehungen zu fokussieren. Gut für einfache Aufgaben, aber begrenzte Perspektive.
Multi-Head Attention Mehrere Spotlights untersuchen gleichzeitig verschiedene Beziehungstypen. Ein Head könnte sich auf Grammatik konzentrieren, ein anderer auf Bedeutung, ein weiterer auf Stil. Dies wird von den meisten modernen Neural Networks verwendet.
Cross-Attention Verbindet zwei verschiedene Sequenzen - wie die Verbindung von Fragen zu Antworten oder Bildern zu Beschriftungen. Wesentlich für multimodale AI.
Causal (Masked) Attention Schaut nur rückwärts, nicht vorwärts. Wird bei Textgenerierung verwendet, um "Schummeln" durch Sehen zukünftiger Wörter zu verhindern.
Self-Attention in Aktion
Sprachübersetzung Alter Weg: "The spirit is willing but the flesh is weak" → "The vodka is good but the meat is rotten" (tatsächlicher früher Übersetzungsfehler). Mit Self-Attention: Perfektes Kontextverständnis. Professionelle Übersetzungsqualität. Nuancen bleiben erhalten.
Suchverständnis Anfrage: "Apple stock performance not the fruit" Self-Attention versteht, dass "not the fruit" "Apple" modifiziert, und liefert nur Finanzergebnisse. Such-Relevanz verbesserte sich um 60%.
Sentiment Analysis "I don't think this product is not worth avoiding." Self-Attention entwirrt die doppelten Verneinungen und versteht, dass dies tatsächlich eine Empfehlung ist. Sentiment-Genauigkeit: 94%.
Warum Self-Attention traditionelle Methoden schlägt
Parallele Verarbeitung Traditionelle Modelle verarbeiten sequenziell (Wort für Wort). Self-Attention verarbeitet alle Wörter gleichzeitig. Ergebnis: 100x schnelleres Training.
Langstrecken-Abhängigkeiten Kann verwandte Konzepte verbinden, die durch Hunderte von Wörtern getrennt sind. Traditionelle Modelle vergessen. Self-Attention erinnert sich an alles.
Recheneffizienz Trotz Verarbeitung von mehr Beziehungen sind moderne Implementierungen hochoptimiert. Bessere Ergebnisse bei angemessenen Rechenkosten.
Transfer Learning Mit Self-Attention trainierte Modelle übertragen Wissen besser auf neue Aufgaben. Einmal trainieren, überall anwenden.
Self-Attention in Ihrem Unternehmen implementieren
Option 1: Vortrainierte Modelle verwenden Nutzen Sie Modelle wie GPT oder BERT, die bereits Self-Attention integriert haben. Schnellster Weg zum Wert.
- OpenAI API: 0,002-0,03 € pro 1.000 Tokens
- Hugging Face-Modelle: Kostenlos bis 20 €/Stunde
- Google Cloud AI: Nutzungsbasierte Bezahlung
Option 2: Bestehende Modelle Fine-tunen Nehmen Sie vortrainierte Modelle und passen Sie sie an Ihre spezifischen Bedürfnisse an. Beste Balance aus Anpassung und Effizienz.
- Erforderlich: 1.000-10.000 Beispiele
- Zeit: 1-2 Wochen
- Kosten: 500-5.000 € für Rechenleistung
Option 3: Eigene Modelle bauen Nur für spezifische Bedürfnisse, die nicht von bestehenden Modellen bedient werden. Erfordert erhebliche Expertise und Ressourcen.
- Team: ML-Engineers benötigt
- Zeit: 3-6 Monate
- Kosten: 50.000-500.000+ €
Häufige Missverständnisse
"Es ist zu komplex für geschäftliche Nutzung" Realität: Sie müssen die Mathematik nicht verstehen. Vorgefertigte Modelle und APIs machen Self-Attention für jeden Entwickler zugänglich.
"Es erfordert massive Rechenleistung" Realität: Inferenz (Nutzung von Modellen) ist leichtgewichtig. Training ist teuer, aber Sie müssen selten von Grund auf trainieren.
"Es ist nur für Sprache" Realität: Self-Attention funktioniert für beliebige sequenzielle oder relationale Daten. Bilder via Computer Vision, Zeitreihen, Graphen - alle profitieren.
Der technische Vorteil (vereinfacht)
Hier ist, was Self-Attention besonders macht, ohne dass ein PhD erforderlich ist:
Query-Key-Value-System
- Query: "Wonach suche ich?"
- Key: "Welche Informationen habe ich?"
- Value: "Woran soll ich mich erinnern?"
Wie ein intelligentes Ablagesystem, das genau weiß, was basierend auf Kontext abzurufen ist.
Attention-Scores Mathematische Ähnlichkeit zwischen Wörtern. Hoher Score = aufpassen. Niedriger Score = ignorieren. Berechnet für jedes Wortpaar.
Positional Encoding Fügt Wortreihenfolgeinformationen hinzu. Weiß, dass "dog bites man" sich von "man bites dog" unterscheidet, selbst während alle Wörter gleichzeitig verarbeitet werden.
Echte Implementierungsbeispiele
E-Commerce-Suche Vorher: Keyword-Matching. "Blue running shoes" verpasste "azure athletic footwear." Nachher: Self-Attention ermöglicht Semantic Search, die Bedeutung versteht. 35% mehr relevante Ergebnisse.
Kunden-E-Mail-Klassifizierung Vorher: Regelbasiertes Routing. 65% Genauigkeit. Nachher: Self-Attention-Modell versteht Kontext und Absicht. 92% genaues Routing.
Finanzberichtsanalyse Vorher: Manuelles Lesen von Earnings Calls. Tagelange Arbeit. Nachher: Self-Attention extrahiert wichtige Erkenntnisse, Sentiment und Forward Guidance. Minuten, nicht Tage.
Ihre Self-Attention-Strategie
So funktioniert Self-Attention in Kürze. Ergibt jetzt mehr Sinn, oder?
Als Nächstes sollten Sie Transformer Architecture verstehen - das vollständige Framework, das auf Self-Attention aufbaut. Außerdem zeigt unser Leitfaden zu Large Language Models, wie Self-Attention skaliert, um ChatGPT und ähnliche Systeme anzutreiben.
Häufig gestellte Fragen zu Self-Attention
Was ist Self-Attention?
Self-Attention ist ein AI-Mechanismus, der Modellen ermöglicht, Kontext und Beziehungen zu verstehen, indem untersucht wird, wie jedes Wort zu jedem anderen Wort in einer Sequenz in Beziehung steht - gleichzeitig, anstatt sie nacheinander zu verarbeiten.
Was ist der Unterschied zwischen Self-Attention und traditioneller AI-Textverarbeitung?
Traditionelle Modelle lesen Text sequenziell (Wort für Wort) und vergessen oft früheren Kontext. Self-Attention verarbeitet alle Wörter gleichzeitig und behält Beziehungen zwischen allen Textteilen bei, was besseres Verständnis ermöglicht.
Was sind die Haupttypen von Attention-Mechanismen?
Single-Head Attention (fokussiert auf einen Aspekt), Multi-Head Attention (untersucht gleichzeitig mehrere Beziehungstypen), Cross-Attention (verbindet zwei verschiedene Sequenzen) und Causal Attention (schaut nur rückwärts für Textgenerierung).
Wie funktioniert Self-Attention in der Praxis?
Es verwendet ein Query-Key-Value-System, bei dem jedes Wort fragt "Wonach suche ich?" (Query), "Welche Informationen habe ich?" (Key) und "Woran soll ich mich erinnern?" (Value), wobei Attention-Scores zwischen allen Wortpaaren berechnet werden.
Warum ist Self-Attention wichtig für moderne AI?
Es ermöglicht parallele Verarbeitung (100x schnelleres Training), behandelt Langstrecken-Abhängigkeiten, ermöglicht besseres Transfer Learning und ist die Grundlage von Durchbruchsmodellen wie GPT, BERT und ChatGPT, die tatsächlich Kontext und Nuancen verstehen.
External Resources
Erkunden Sie maßgebliche Forschung und Dokumentation zu Self-Attention:
- Google's "Attention Is All You Need" Paper - Das wegweisende Paper von 2017, das die Transformer-Architektur einführte
- The Illustrated Transformer - Visueller Leitfaden zum Verständnis von Self-Attention und Transformers
- Stanford CS224N: NLP with Deep Learning - Umfassende Kursmaterialien zu Attention-Mechanismen
Learn More
Erkunden Sie verwandte AI-Konzepte, um Ihr Verständnis zu vertiefen:
- Attention Mechanism - Die breitere Familie von Techniken, die Self-Attention umfasst
- Deep Learning - Die Grundlage, die Self-Attention ermöglicht
- Embeddings - Wie Wörter repräsentiert werden, bevor Self-Attention sie verarbeitet
- Generative AI - Anwendungen, die von Self-Attention-Mechanismen angetrieben werden
Teil der AI Terms Collection. Zuletzt aktualisiert: 2026-07-21

Co-Founder, Rework.com
On this page
- Die Self-Attention-Story
- Wie Self-Attention tatsächlich funktioniert
- Der geschäftliche Einfluss von Self-Attention
- Typen von Attention-Mechanismen
- Self-Attention in Aktion
- Warum Self-Attention traditionelle Methoden schlägt
- Self-Attention in Ihrem Unternehmen implementieren
- Häufige Missverständnisse
- Der technische Vorteil (vereinfacht)
- Echte Implementierungsbeispiele
- Ihre Self-Attention-Strategie
- External Resources
- Learn More