Was ist eine Data Pipeline? Die Informationsautobahn Ihres Unternehmens
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
"Unsere Daten sind überall - CRM, Website, Lagerverwaltung, Social Media. Aber bis wir sie analysieren, sind sie bereits veraltet." Klingt bekannt? Diese Frustration eines CEO ist der Grund, warum Data Pipelines existieren. Sie sind die unsichtbare Infrastruktur, die Chaos in Insights verwandelt - automatisch. Im Kern sind Data Pipelines ein Schlüsselkomponente der AI Automation-Strategie.
Data Pipeline verstehen
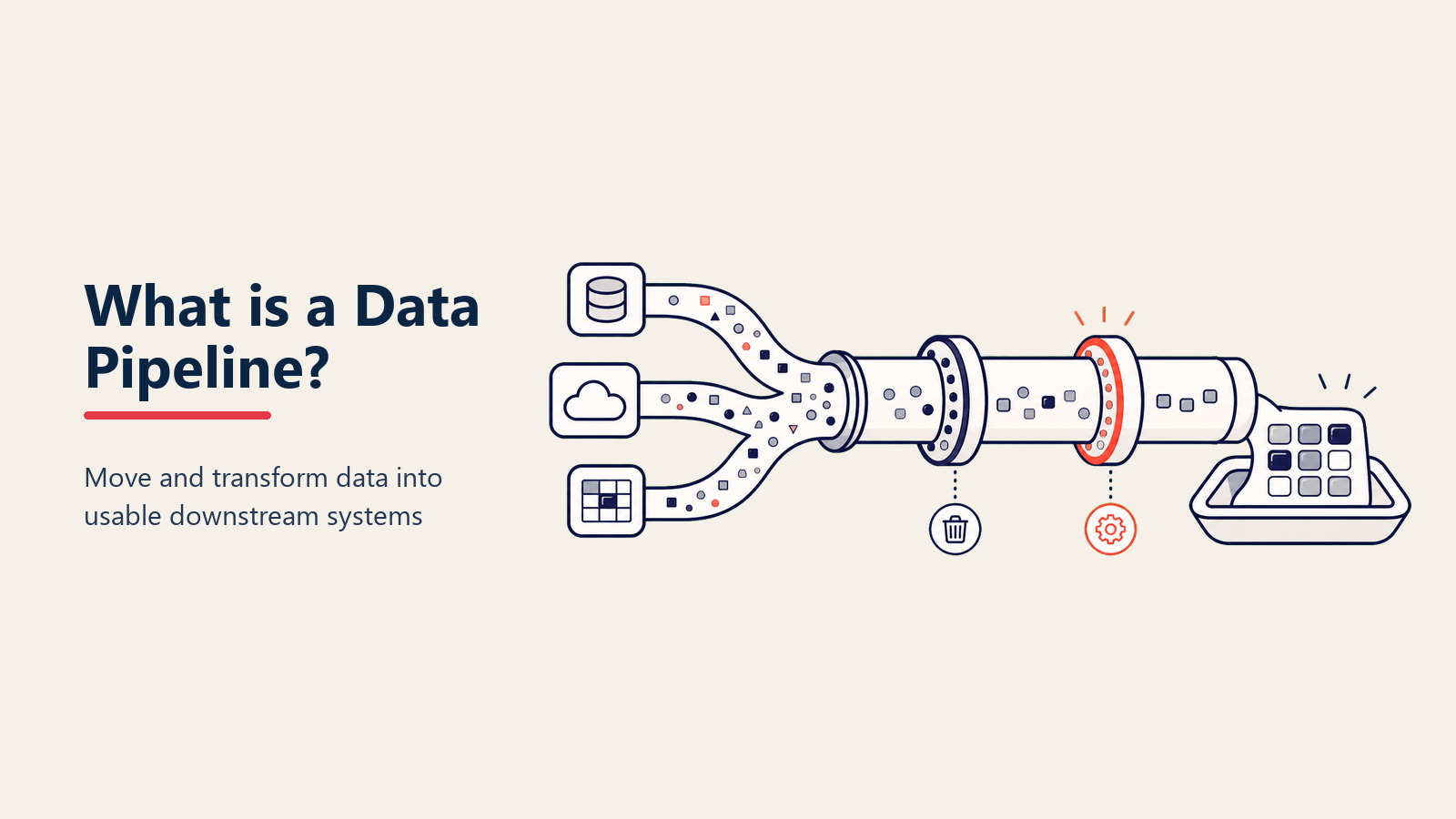
Sie wissen, wie ein Fabrik-Fließband Produkte durch verschiedene Stadien bewegt? Eine Data Pipeline ist ähnlich, aber für Informationen. Sie sammelt automatisch Daten aus verschiedenen Quellen, bereitet sie auf, transformiert sie in nutzbare Formate und liefert sie dorthin, wo sie gebraucht werden.
Technischer ausgedrückt ist eine Data Pipeline eine Reihe automatisierter Prozesse, die Daten von Quellsystemen zu Zielsystemen bewegen und sie unterwegs transformieren. Denken Sie daran wie an Sanitärinstallation für Ihre digitalen Operationen.
Der Hauptunterschied ist die Automatisierung. Ohne Pipelines exportiert jemand manuell CSVs, bereinigt Daten in Excel und lädt sie in verschiedene Systeme hoch. Mit Pipelines? Es passiert automatisch, kontinuierlich, präzise.
Die Bausteine von Data Pipelines
Im Kern hat eine Data Pipeline drei Hauptteile:
Die Source Connectors - Diese holen Daten aus Ihren Systemen Denken Sie an diese wie Einlassventile. Sie verbinden sich mit Ihrem CRM, Datenbanken, APIs, Dateien, IoT-Sensoren - überall wo Daten leben. Moderne Connectors können Hunderte von Quellen verarbeiten.
Die Processing Engine - Diese bereinigt und transformiert Daten Es ist im Wesentlichen die Fabrikhalle, wo Rohmaterialien zu Produkten werden. Diese Schicht entfernt Duplikate, korrigiert Formate, berechnet neue Felder und reichert Daten mit zusätzlichem Kontext an.
Die Destination Handlers - Diese liefern verarbeitete Daten Hier landen transformierte Daten - könnte ein Data Warehouse, ein Business Intelligence-Tool, eine andere Anwendung oder ein KI-Modell sein. Der Schlüssel ist, dass Daten nutzungsbereit ankommen, ohne weitere Bereinigung zu benötigen.
Wie verschiedene Branchen Data Pipelines nutzen
E-Commerce Ein Online-Händler baute Pipelines, die ihren Shopify-Shop, Google Analytics, Facebook Ads und das Lagerverwaltungssystem verbinden. Jetzt sehen sie Echtzeit-Profitabilität pro Produkt, einschließlich Werbekosten und Versandkosten. Umsatz pro Besucher stieg um 23%.
Gesundheitswesen Ein Kliniknetzwerk nutzt Pipelines, um Patientenakten, Terminsysteme und Abrechnungsdaten zu kombinieren. Sie verwenden Predictive Analytics, um Nichterscheinen mit 85% Genauigkeit vorherzusagen und automatisch gezielte Erinnerungen zu senden. Patientenpräsenz verbesserte sich um 30%.
Finanzdienstleistungen Ein Fintech-Startup leitet Transaktionsdaten durch Anomaly Detection-Modelle zur Betrugsprävention in Echtzeit. Verdächtige Aktivitäten lösen sofortige Warnungen aus. Sie haben 2,4 Millionen Dollar an betrügerischen Transaktionen verhindert bei gleichzeitiger Verarbeitung unter einer Sekunde.
Fertigung Eine Fabrik streamt Sensordaten von Geräten durch Pipelines zu Predictive-Maintenance-Modellen und nutzt häufig IoT AI für Echtzeit-Überwachung. Sie erkennen potenzielle Ausfälle Tage im Voraus. Ungeplante Ausfallzeiten sanken um 45%.
Typen von Data Pipelines
Batch Processing Pipelines Diese laufen nach Zeitplan - stündlich, täglich, wöchentlich. Perfekt für Berichte, Data Warehousing und Szenarien, wo Echtzeit nicht kritisch ist. Wie ein Zug, der Passagiere zu festgelegten Zeiten abholt.
Streaming Pipelines Diese verarbeiten Daten sofort bei Ankunft. Unverzichtbar für Betrugserkennung, Echtzeit-Personalisierung und Betriebsüberwachung. Wie ein Förderband, das nie anhält.
Hybrid Pipelines Kombinieren Batch und Streaming für Flexibilität. Streamen kritischer Daten während historische Analysen gebündelt werden. Die meisten Unternehmen landen hier irgendwann.
Die ETL vs. ELT-Debatte
ETL (Extract, Transform, Load) Traditioneller Ansatz: Daten vor dem Speichern transformieren. Wie Zutaten kochen, bevor man sie in den Kühlschrank legt. Funktioniert gut für strukturierte Daten und wenn Speicher teuer ist.
ELT (Extract, Load, Transform) Moderner Ansatz: Rohdaten speichern, später transformieren. Wie Zutaten kaufen und später entscheiden, was man kocht. Besser für Big Data und wenn Speicher günstig ist.
Die meisten Cloud-nativen Unternehmen bevorzugen ELT für Flexibilität, aber ETL dominiert noch in regulierten Branchen, die Data Governance benötigen.
Implementierungs-Roadmap
Woche 1-2: Datenprüfung
- Alle Datenquellen kartieren
- Aktuelle manuelle Prozesse dokumentieren
- Höchste-Impact-Pipeline-Möglichkeiten identifizieren
- Zeit für manuelle Datenaufgaben berechnen
Woche 3-4: Pilot-Pipeline
- Mit einem einfachen Flow starten (z.B. Verkaufsdaten zum Dashboard)
- No-Code-Tools für schnelle Erfolge nutzen
- Eingesparte Zeit und verbesserte Genauigkeit messen
- Lessons Learned dokumentieren
Monat 2: Abdeckung erweitern
- Mehr Datenquellen hinzufügen
- Grundlegende Transformationen einführen
- Monitoring und Alerts einrichten
- Team für Wartung schulen
Monat 3+: Erweiterte Features
- Echtzeit-Streaming wo nötig implementieren
- Datenqualitätsprüfungen hinzufügen
- Komplexe Transformationen aufbauen
- Mit AI/ML-Modellen integrieren
Tools und Plattformen
No-Code-Lösungen:
- Zapier - Verbindet 5.000+ Apps ($19,99/Monat)
- Make.com (ehemals Integromat) - Visuelle Automatisierung ($9/Monat)
- Fivetran - Automatisierte Daten-Connectors ($120/Monat)
Entwicklerfreundlich:
- Apache Airflow - Open-Source-Orchestrierung (Kostenlos)
- Prefect - Moderne Workflow-Automatisierung (Free Tier verfügbar)
- Dagster - Datenorchestrierungsplattform (Free Open-Source)
Enterprise-Plattformen:
- Informatica - Vollständiges Datenmanagement (Individuelle Preise)
- Talend - Umfassende Datenplattform ($1.170/Benutzer/Jahr)
- Azure Data Factory - Microsoft-Lösung ($0,001 pro Aktivität)
Häufige Fallstricke
Fallstrick 1: Zu komplex starten Eine Einzelhandelskette versuchte, eine Master-Pipeline zu bauen, die 50 Systeme auf einmal verbindet. Es scheiterte spektakulär. Lösung: Mit 2-3 Systemen starten. Wert beweisen. Dann expandieren.
Fallstrick 2: Datenqualität ignorieren Garbage in, garbage out - aber schneller! Schlechte Daten, die sich schnell bewegen, sind schlimmer als langsame manuelle Prozesse. Lösung: Qualitätsprüfungen in jede Pipeline-Phase einbauen.
Fallstrick 3: Keine Fehlerbehandlung Ein fehlerhafter Datensatz brachte eine gesamte Pipeline zum Absturz und verlor einen Tag Daten. Lösung: Pipelines so gestalten, dass sie Fehler elegant behandeln. Fehler protokollieren, fehlerhafte Datensätze überspringen, Menschen alarmieren.
Der Business Case für Data Pipelines
Zeitersparnis:
- Manuelle Datenverarbeitung: 20 Stunden/Woche
- Mit Pipelines: 2 Stunden/Woche
- ROI: 18 Stunden frei für Analysen
Genauigkeitsgewinne:
- Manuelle Fehlerrate: 5-10%
- Pipeline-Fehlerrate: <0,1%
- Auswirkung: Bessere Entscheidungen, weniger Korrekturen
Geschwindigkeit zu Insights:
- Manuell: 2-3 Tage Verzögerung
- Pipeline: Echtzeit bis stündlich
- Ergebnis: Schnellere Reaktion auf Chancen
Jetzt sind Sie Pipeline-bereit
Also, das sind Data Pipelines in Kürze. Macht jetzt mehr Sinn, oder?
Als Nächstes sollten Sie Data Curation verstehen - denn saubere Daten machen bessere Pipelines. Außerdem zeigt unser Leitfaden zu MLOps, wie Pipelines Machine Learning in der Produktion antreiben.
Verwandte Ressourcen
Erkunden Sie diese verwandten Konzepte, um Ihr Verständnis von Data Pipelines und ihrer Rolle in KI-Systemen zu vertiefen:
- Machine Learning - Die Grundlage für viele Pipeline-gestützte Vorhersagen
- AI Integration - Wie Sie Pipelines mit Ihren bestehenden Systemen verbinden
- Model Monitoring - Pipeline-Performance und Modellgenauigkeit im Zeitverlauf verfolgen
Externe Ressourcen
- Apache Airflow Documentation - Open-Source-Workflow-Orchestrierungsplattform
- AWS Data Pipeline Guide - Cloud-basierte ETL-Service-Tutorials
- Databricks: Data Engineering - Moderne Data-Pipeline-Architekturmuster
FAQ
Häufig gestellte Fragen zu Data Pipeline
Was ist eine Data Pipeline?
Eine Data Pipeline ist eine Reihe automatisierter Prozesse, die Daten von Quellsystemen zu Zielsystemen bewegen, sie dabei transformieren und bereinigen - wie ein Fließband für Geschäftsinformationen.
Was ist der Unterschied zwischen ETL und ELT?
ETL (Extract, Transform, Load) transformiert Daten vor dem Speichern. ELT (Extract, Load, Transform) speichert Rohdaten zuerst und transformiert sie dann später. ELT bietet mehr Flexibilität, benötigt aber mehr Speicher.
Was sind die drei Hauptkomponenten von Data Pipelines?
Source Connectors (holen Daten aus Systemen), Processing Engine (bereinigt und transformiert Daten) und Destination Handlers (liefern Daten an Analytics-Tools, Datenbanken oder Anwendungen).
Was sind die drei Typen von Data Pipelines?
Batch Processing Pipelines (laufen nach Zeitplan), Streaming Pipelines (verarbeiten Daten sofort) und Hybrid Pipelines (kombinieren Batch und Streaming für Flexibilität).
Was sind häufige Fallstricke bei der Data-Pipeline-Implementierung?
Zu komplex starten (zu viele Systeme auf einmal verbinden), Datenqualität ignorieren (Garbage in, Garbage out) und keine Fehlerbehandlung (ein fehlerhafter Datensatz bringt alles zum Absturz).
Teil der [AI Terms Collection]. Zuletzt aktualisiert: 2026-07-21

Co-Founder, Rework.com
On this page
- Data Pipeline verstehen
- Die Bausteine von Data Pipelines
- Wie verschiedene Branchen Data Pipelines nutzen
- Typen von Data Pipelines
- Die ETL vs. ELT-Debatte
- Implementierungs-Roadmap
- Tools und Plattformen
- Häufige Fallstricke
- Der Business Case für Data Pipelines
- Jetzt sind Sie Pipeline-bereit
- Verwandte Ressourcen
- Externe Ressourcen
- FAQ