Was ist Context Window? KIs Speicherlimit verstehen
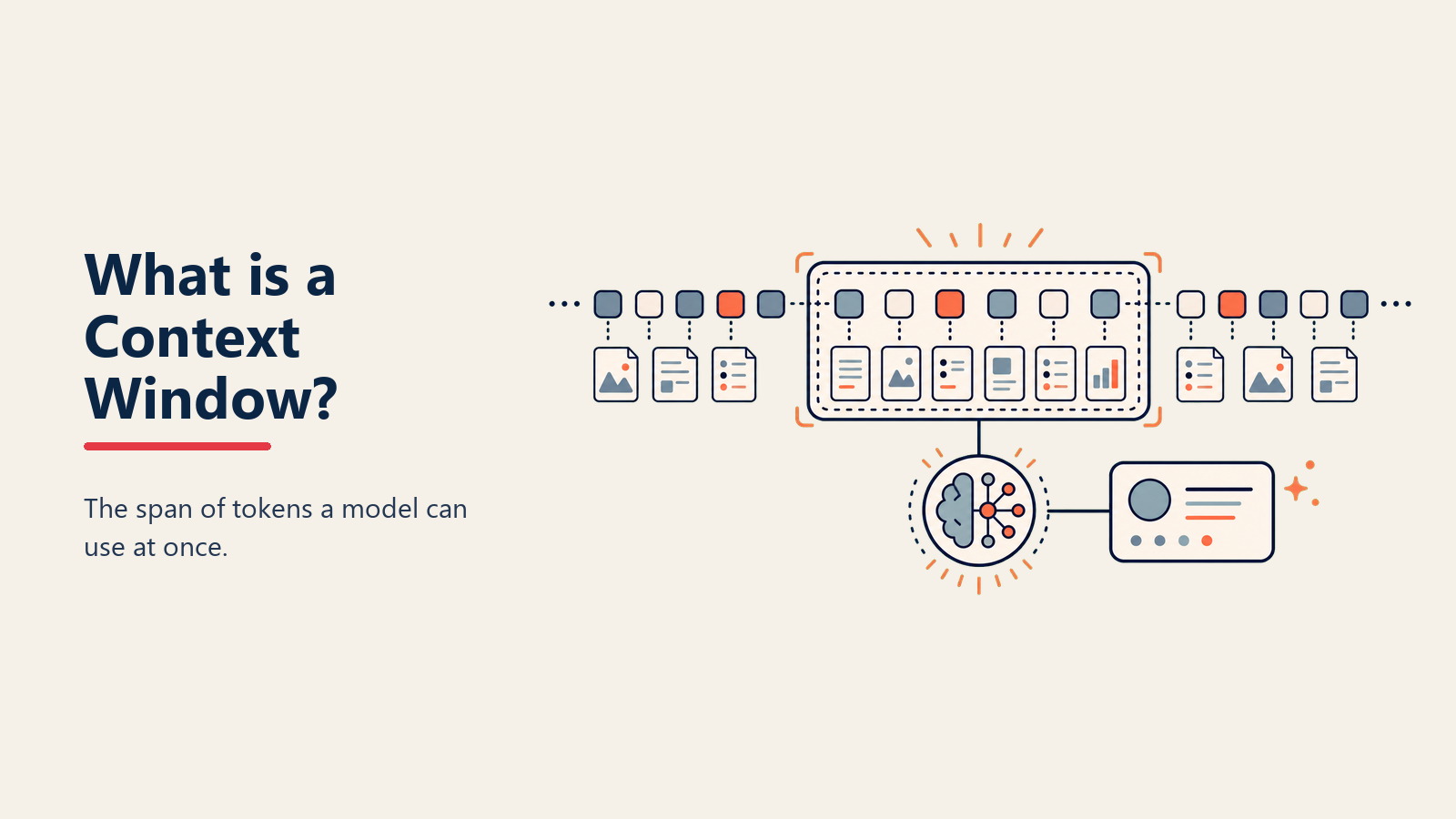 Ihr KI-Assistent vergisst plötzlich, was Sie vor fünf Minuten besprochen haben. Er kann Ihren 200-seitigen Vertrag nicht in einem Durchgang verarbeiten. Er verliert den Anfang aus den Augen, wenn Sie das Ende einer langen Konversation erreichen. Das sind keine Bugs – das sind Context Window-Limitierungen. Diese Grenze zu verstehen ist der Schlüssel zur effektiven KI-Nutzung.
Ihr KI-Assistent vergisst plötzlich, was Sie vor fünf Minuten besprochen haben. Er kann Ihren 200-seitigen Vertrag nicht in einem Durchgang verarbeiten. Er verliert den Anfang aus den Augen, wenn Sie das Ende einer langen Konversation erreichen. Das sind keine Bugs – das sind Context Window-Limitierungen. Diese Grenze zu verstehen ist der Schlüssel zur effektiven KI-Nutzung.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die Speicher-Revolution
Context Windows entstanden als definierende Eigenschaft von Large Language Models, als GPT-2 2019 mit 1.024 Tokens startete. Jede Generation erweiterte die Kapazität: GPT-3 (4K), GPT-3.5 (16K), GPT-4 (128K), und jetzt Modelle wie Claude mit 1M+ Token-Windows.
Google DeepMind definiert Context Window als „die maximale Textmenge, gemessen in Tokens, die ein Sprachmodell gleichzeitig verarbeiten kann, umfassend sowohl Input-Prompt als auch generierte Antwort innerhalb seines Arbeitsspeichers."
Die Erweiterung von 4K auf 1M+ Tokens stellt eine 250-fache Steigerung in nur fünf Jahren dar und verwandelt KI von der Handhabung kurzer Konversationen zur Verarbeitung ganzer Codebasen, juristischer Dokumente und buchlanger Materialien.
Context Windows in Geschäftsbegriffen
Für Führungskräfte bedeutet Context Window die Menge an Informationen, die KI im aktiven Speicher gleichzeitig halten kann – bestimmend, ob sie Ihren vollständigen Quartalsbericht analysieren, Kontext während einer langen Support-Konversation beibehalten oder komplexe Multi-Dokument-Analysen durchführen kann.
Stellen Sie sich Context Window als Kurzzeitgedächtniskapazität vor. Eine Person mit exzellentem Gedächtnis könnte sich an eine 30-minütige Konversation im Detail erinnern, während jemand anderes sich nur an die letzten paar Austausche erinnert. Ähnlich verliert KI mit einem 4K Context Window nach ein paar Seiten den Überblick, während 1M Token-Modelle Hunderte von Seiten gleichzeitig im Blick behalten.
Praktisch bedeuten größere Context Windows die Analyse längerer Dokumente, Aufrechterhaltung kohärenter mehrstündiger Konversationen und Arbeit mit komplexen Informationen, ohne frühere Details aus den Augen zu verlieren.
Context Window-Komponenten
Context Windows bestehen aus diesen wesentlichen Elementen:
• Token Count: Die Maßeinheit für Text (ungefähr 4 Zeichen pro Token in Englisch), Definition der Kapazität in Zahlen wie 4K, 32K oder 1M Tokens
• Input Space: Der Anteil, der Ihren Prompts, Dokumenten und Konversationshistorie zugeordnet ist und Tokens vom Gesamtfenster verbraucht
• Output Space: Reservierte Tokens für die KI-Antwort, typischerweise begrenzt, um zu verhindern, dass Output die verfügbare Kapazität überwältigt
• Sliding Window: Einige Modelle behalten feste Fenstergröße bei, „gleiten" aber entlang längerer Texte und verarbeiten in sequenziellen Chunks mit Überlappung
• Cache Memory: Fortgeschrittene Systeme cachen häufig referenzierte Inhalte außerhalb des Hauptfensters und erweitern die effektive Kapazität
Wie Context Windows funktionieren
Context Window-Management folgt diesen Schritten:
Token-Berechnung: Jeder Input (Ihre Nachrichten, Dokumente, System-Prompts) wird in Tokens umgewandelt und zählt gegen die Gesamtfensterkapazität
Fensterzuweisung: Das Modell weist verfügbaren Raum zwischen Input-Kontext und erwarteter Ausgabe zu und balanciert Verständnis mit Antwortgenerierung
Attention-Mechanismus: Die KI verarbeitet alle Tokens innerhalb des Fensters gleichzeitig unter Verwendung von Transformer Architecture und versteht Beziehungen zwischen entfernten Textteilen
Dies geschieht sofort, aber wenn Inputs die Fenstergröße überschreiten, muss das Modell entweder frühe Inhalte abschneiden, Informationen komprimieren oder die Verarbeitung verweigern.
Context Window-Größen
Verschiedene Modelle bieten unterschiedliche Kapazitäten:
Typ 1: Kleiner Kontext (4K-8K Tokens) Am besten für: Schnelle Abfragen, einfache Aufgaben Hauptmerkmal: Schnelle Verarbeitung, niedrigere Kosten Beispiel: Basis-Kundensupport, einfache Q&A
Typ 2: Mittlerer Kontext (32K-64K Tokens) Am besten für: Dokumentenanalyse, erweiterte Konversationen Hauptmerkmal: Ausgewogene Performance und Kapazität Beispiel: Analyse von Berichten, Multi-Turn-Dialoge
Typ 3: Großer Kontext (128K-200K Tokens) Am besten für: Komplexe Dokumente, Code-Analyse Hauptmerkmal: Handhabt substanzielle Materialien Beispiel: Juristische Verträge, technische Dokumentation
Typ 4: Erweiterter Kontext (1M+ Tokens) Am besten für: Gesamte Codebasen, buchlange Analyse Hauptmerkmal: Verarbeitet massive Mengen gleichzeitig Beispiel: Vollständige Codebase-Review, umfassende Forschung
Context Window-Erfolgsgeschichten
So nutzen Unternehmen größere Context Windows:
Juristisches Beispiel: Anthropics Claude mit 200K Kontext analysiert gesamte juristische Verträge in einem Durchgang, reduziert Überprüfungszeit von 8 Stunden auf 45 Minuten und identifiziert Inkonsistenzen über Hunderte von Seiten.
Software-Beispiel: GitHub Copilot Workspace nutzt erweiterten Kontext, um gesamte Codebasen zu verstehen, und bietet Vorschläge, die Dateien im gesamten Projekt berücksichtigen, anstatt nur die aktuelle Datei, was Code-Konsistenz um 60% verbessert.
Forschungsbeispiel: Semantic Scholar verarbeitet vollständige Forschungspapiere in einzelnen Context Windows und generiert umfassende Zusammenfassungen, die nuancierte Argumente von Einleitung bis Schlussfolgerung erfassen.
Ihr Context Window maximieren
Bereit, KIs Speicher effektiv zu nutzen?
- Verstehen Sie Tokenization, um Nutzung zu schätzen
- Lernen Sie Prompt Engineering für Effizienz
- Erkunden Sie Retrieval-Augmented Generation, wenn Dokumente Windows überschreiten
- Erwägen Sie AI Agents für mehrstufige Aufgaben
Mehr erfahren
Erweitern Sie Ihr Verständnis verwandter KI-Konzepte:
- Large Language Models - Die KI-Systeme mit Context Windows
- Transformer Architecture - Wie Kontextverarbeitung intern funktioniert
- Attention Mechanism - Die Technologie, die langen Kontext ermöglicht
- Model Parameters - Bezogen auf Modellkapazität
Externe Ressourcen
- OpenAI Context Window Research - Entwicklungen bei der Erweiterung der Kontextkapazität
- Anthropic's Long Context Guide - Technische Details zu 200K+ Token-Windows
- Hugging Face: Context Length - Praktische Leitfäden zur Context Window-Nutzung
FAQ-Bereich
Häufig gestellte Fragen zu Context Window
Was ist ein Context Window?
Ein Context Window ist die maximale Textmenge (gemessen in Tokens), die ein KI-Sprachmodell gleichzeitig verarbeiten kann, umfassend sowohl Ihren Input als auch die KI-Antwort innerhalb seines Arbeitsspeichers.
Was ist der Unterschied zwischen 4K und 1M Token Context Windows?
4K Tokens (~3.000 Wörter) handhabt kurze Konversationen. 1M Tokens (~750.000 Wörter) kann ganze Bücher, Codebasen oder Hunderte von Dokumenten gleichzeitig verarbeiten – ein 250-facher Unterschied in der Kapazität.
Was sind die Haupt-Context Window-Größen?
Klein (4K-8K Tokens für schnelle Aufgaben), Mittel (32K-64K für Dokumente), Groß (128K-200K für komplexe Materialien) und Erweitert (1M+ für umfassende Analyse).
Woher weiß ich, ob ich das Context Window überschritten habe?
Die KI wird entweder frühe Inhalte abschneiden, eine Fehlermeldung zurückgeben, dass das Token-Limit überschritten wurde, oder die Verarbeitung des Inputs verweigern. Einige Systeme zeigen Token-Zählungen proaktiv an.
Teil der AI Terms Collection. Zuletzt aktualisiert: 2026-02-09
