Was sind Embeddings? KI die Bedeutung hinter Wörtern beibringen
 Wie weiß KI, dass "Auto" und "Automobil" dasselbe bedeuten? Oder dass "König" zu "Königin" wie "Mann" zu "Frau" verhält? Die Antwort sind Embeddings - die mathematische Magie, die Wörter in Zahlen transformiert, die Bedeutung erfassen und KI ermöglichen, Sprache wie Menschen zu verstehen.
Wie weiß KI, dass "Auto" und "Automobil" dasselbe bedeuten? Oder dass "König" zu "Königin" wie "Mann" zu "Frau" verhält? Die Antwort sind Embeddings - die mathematische Magie, die Wörter in Zahlen transformiert, die Bedeutung erfassen und KI ermöglichen, Sprache wie Menschen zu verstehen.
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Technische Definition
Embeddings sind dichte numerische Repräsentationen diskreter Objekte (wie Wörter, Sätze oder Bilder) in einem kontinuierlichen Vektorraum, wo ähnliche Elemente auf nahe Punkte abgebildet werden. Diese hochdimensionalen Vektoren (typischerweise 256-1536 Zahlen) kodieren semantische Bedeutung und Beziehungen.
Laut Google Research sind "Embeddings eines der wichtigsten Konzepte im modernen Natural Language Processing und ermöglichen es uns, mathematische Werkzeuge auf Wörter anzuwenden und Beziehungen zwischen ihnen zu verstehen." Der Durchbruch kam, als Forscher entdeckten, dass semantische Beziehungen durch Vektorarithmetik erfasst werden können.
Das berühmte Beispiel: Vektor("König") - Vektor("Mann") + Vektor("Frau") ≈ Vektor("Königin") demonstriert, wie Embeddings konzeptuelle Beziehungen mathematisch erfassen.
Geschäftsübersetzung
Für Führungskräfte sind Embeddings wie GPS-Koordinaten für Bedeutung - sie sagen KI, wie nah oder weit Konzepte voneinander entfernt sind und ermöglichen semantische Suche, personalisierte Empfehlungen und intelligente Kategorisierung im großen Maßstab.
Stellen Sie sich vor, Ihren Produktkatalog nicht alphabetisch, sondern nach tatsächlicher Ähnlichkeit zu organisieren. Embeddings tun dies automatisch und verstehen, dass "Laptop" näher an "Notebook-Computer" ist als an "Notizbuch-Papier" ohne explizite Programmierung.
In praktischer Hinsicht treiben Embeddings die KI an, die ähnliche Kundensupport-Tickets findet, verwandte Produkte empfiehlt, doppelte Inhalte erkennt und versteht, dass eine Suche nach "erschwingliche Anwälte" auch "günstige Rechtsanwälte" zeigen sollte.
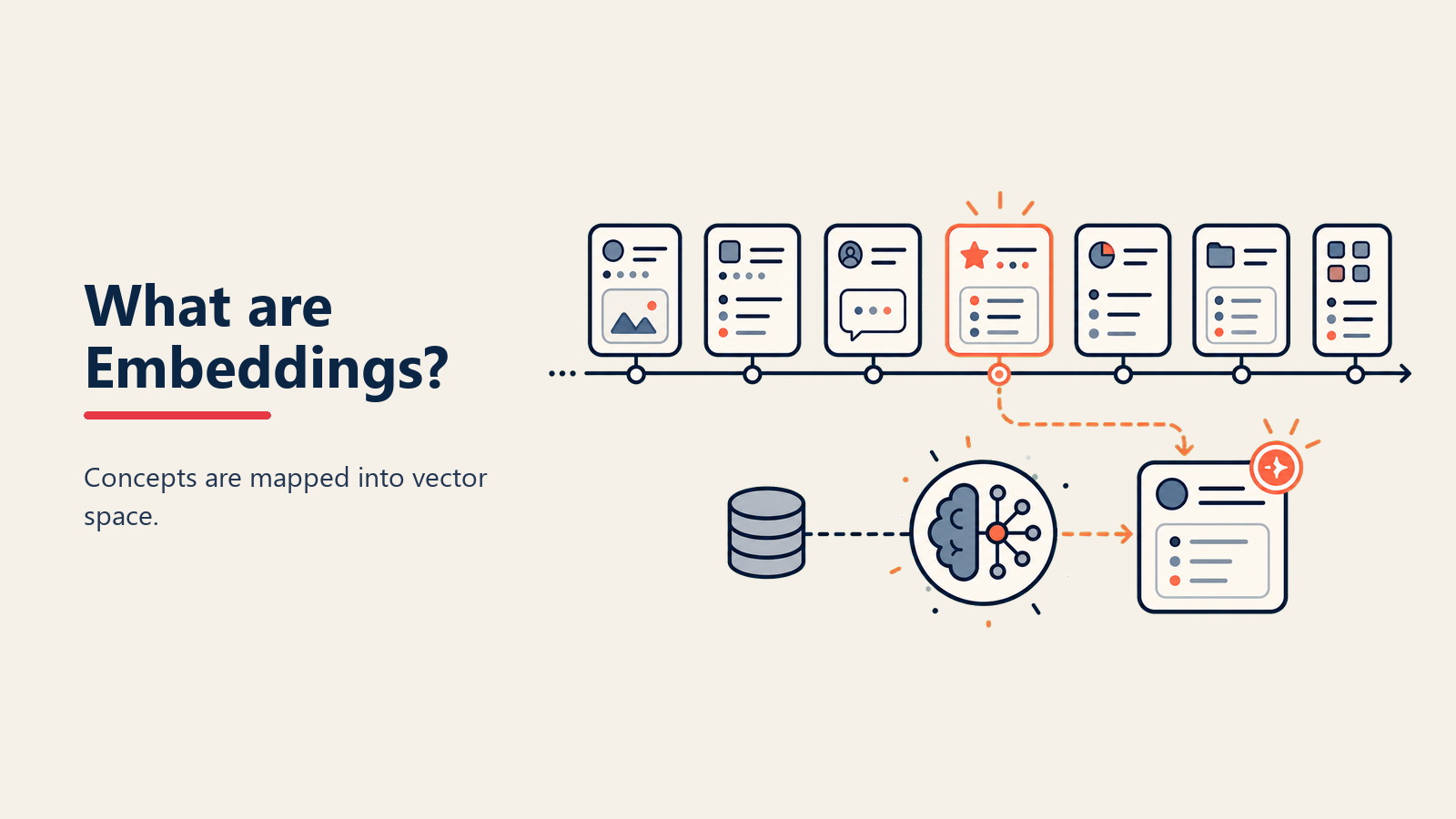
Wie Embeddings funktionieren
Der Embedding-Prozess:
• Input-Verarbeitung: Text, Bilder oder andere Daten in Standardformat konvertiert (wie Tokens für Text)
• Neuronales Netzwerk-Encoding: Deep Learning-Modelle transformieren Inputs in dichte Vektoren und lernen Muster aus massiven Datensätzen
• Vektorrepräsentation: Jeder Input wird zu einer Liste von Zahlen (z.B. [0.2, -0.5, 0.8...]), die seine Position im "Bedeutungsraum" darstellt
• Ähnlichkeitsberechnung: Mathematischer Abstand zwischen Vektoren zeigt semantische Ähnlichkeit an - nähere Vektoren bedeuten ähnlichere Konzepte
• Downstream-Anwendungen: Diese Vektoren fließen in Suche, Klassifikation, Clustering und andere KI-Aufgaben
Typen von Embeddings
Verschiedene Embeddings für verschiedene Daten:
Typ 1: Word Embeddings Beispiele: Word2Vec, GloVe Anwendungsfall: Einzelne Wörter verstehen Anwendung: Rechtschreibprüfung, Autocomplete
Typ 2: Sentence/Document Embeddings Beispiele: BERT, Sentence-BERT Anwendungsfall: Vollständigen Kontext erfassen Anwendung: Dokumentensuche, Zusammenfassung
Typ 3: Image Embeddings Beispiele: ResNet, CLIP Anwendungsfall: Computer Vision-Verständnis Anwendung: Bildsuche, Produktabgleich
Typ 4: Multimodale Embeddings Beispiele: CLIP, ALIGN Anwendungsfall: Medienübergreifendes Verständnis Anwendung: Text-zu-Bild-Suche
Geschäftsanwendungen
Embeddings treiben echte Lösungen an:
E-Commerce-Beispiel: Amazons Produkt-Embeddings verstehen, dass Kunden, die nach "Laufschuhen" suchen, möglicherweise auch "Sportsocken" und "Fitness-Tracker" wollen, und generieren 35% der Käufe durch Embedding-basierte Empfehlungen.
Kundenservice-Beispiel: Zendesk nutzt Embeddings, um Tickets automatisch an die richtige Abteilung weiterzuleiten, versteht, dass "kann mich nicht anmelden" und "Passwort funktioniert nicht" ähnliche Probleme sind, und reduziert die Reaktionszeit um 40%.
Content-Management-Beispiel: Netflix-Embeddings verstehen Sehpräferenzen jenseits von Genres und erkennen, dass Fans von "Stranger Things" möglicherweise "Dark" aufgrund thematischer Ähnlichkeiten genießen, was das Engagement um 25% steigert.
Die Macht der semantischen Suche
Embeddings revolutionieren die Suche:
Traditionelle Suche:
- Gleicht exakte Schlüsselwörter ab
- Verpasst Synonyme und Kontext
- Gibt irrelevante Ergebnisse mit übereinstimmenden Wörtern zurück
Embedding-basierte Suche:
- Versteht Bedeutung und Absicht
- Findet konzeptionell ähnlichen Inhalt
- Funktioniert natürlich über Sprachen hinweg
Beispiel: Die Suche nach "Budget-Hotel Paris" findet auch "erschwingliche Unterkunft in der französischen Hauptstadt" ohne Schlüsselwortabgleich.
Embedding-Datenbanken
Embeddings im großen Maßstab speichern und durchsuchen:
• Vector Databases: Spezialisierte Systeme (Pinecone, Weaviate, Qdrant) optimiert für Ähnlichkeitssuche über Millionen von Embeddings
• Indexierungsmethoden: Techniken wie HNSW und IVF ermöglichen nahezu sofortige Suche durch Milliarden von Vektoren
• Hybrid-Suche: Kombination von Embeddings mit traditioneller Suche für das Beste aus beiden Welten
• Echtzeit-Updates: Moderne Systeme aktualisieren Embeddings, wenn neue Inhalte ankommen
Implementierungsüberlegungen
Schlüsselfaktoren für Erfolg:
Qualitätsfaktoren:
- Wahl des Embedding-Modells
- Domänenspezifisches Fine-Tuning
- Embedding-Dimensions-Abwägungen
- Update-Frequenzbedarf
Technische Anforderungen:
- Speicher für hochdimensionale Vektoren
- Rechenressourcen für Encoding
- Schnelle Ähnlichkeitssuch-Infrastruktur
- Integration mit bestehenden Systemen
Geschäftskennzahlen:
- Verbesserung der Suchrelevanz
- Empfehlungs-Klickraten
- Genauigkeit der Support-Ticket-Weiterleitung
- Kundenzufriedenheits-Scores
Häufige Embedding-Herausforderungen
Fallstricke und Lösungen:
• Domänen-Mismatch: Generische Embeddings scheitern an spezialisiertem Inhalt → Lösung: Fine-Tune auf Ihre Branchendaten
• Sprachbarrieren: Auf Englisch trainierte Embeddings haben Schwierigkeiten mit anderen Sprachen → Lösung: Multilinguale Modelle
• Concept Drift: Bedeutungen ändern sich im Laufe der Zeit → Lösung: Regelmäßiges Retraining und Monitoring
• Skalierungsprobleme: Milliarden von Embeddings verlangsamen die Suche → Lösung: Approximate-Nearest-Neighbor-Algorithmen
Embeddings nutzen
Ihr Weg zur semantischen KI:
- Beginnen Sie mit Tokenization, um Inputs zu verstehen
- Erkunden Sie Vector Databases für Speicherung
- Lernen Sie über Semantic Search-Anwendungen
- Verstehen Sie, wie Retrieval-Augmented Generation (RAG) Embeddings nutzt
- Sehen Sie, wie Large Language Models Embeddings nutzen
Externe Ressourcen
- OpenAI Embeddings Guide - Text-Embeddings erstellen und nutzen
- Hugging Face Sentence Transformers - Vortrainierte Embedding-Modelle
- Pinecone Vector Database - Produktions-Embedding-Such-Infrastruktur
FAQ
Häufig gestellte Fragen zu Embeddings
Was sind Embeddings?
Embeddings sind numerische Repräsentationen (Vektoren) von Daten wie Wörtern oder Bildern, die semantische Bedeutung erfassen, wobei ähnliche Elemente ähnliche Vektoren im mathematischen Raum haben.
Was ist der Unterschied zwischen Embeddings und traditioneller Kodierung?
Traditionelle Kodierung verwendet willkürliche Zahlen ohne Bedeutungsbeziehungen. Embeddings positionieren ähnliche Konzepte nahe beieinander im Vektorraum und ermöglichen semantische Operationen wie Ähnlichkeitssuche.
Was sind die Haupttypen von Embeddings?
Word Embeddings (einzelne Wörter), Sentence/Document Embeddings (vollständiger Kontext), Image Embeddings (visuelles Verständnis) und Multimodale Embeddings (medienübergreifend wie Text-Bild).
Was ist eine Vector Database?
Eine Vector Database ist ein spezialisiertes System, das für das Speichern und Durchsuchen von Embeddings optimiert ist und schnelle Ähnlichkeitssuchen über Millionen oder Milliarden hochdimensionaler Vektoren ermöglicht.
Teil der AI Terms Collection. Zuletzt aktualisiert: 2026-01-11

Co-Founder, Rework.com