Requisitos de Governança por Padrão de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
"Humanos devem revisar os outputs de AI antes de agir com base neles." Se a política de governança de AI da sua empresa contém essa frase, ela não contém nada. Essa frase descreve tudo e não governa coisa alguma.
Governança vinculada a padrões específicos é algo completamente diferente. "Para implantações de Autonomous Agent em contextos voltados ao cliente, exigir aprovação humana antes de qualquer etapa Execute que altere um registro financeiro ou envie comunicação externa" é acionável. Você pode auditar isso. Pode treinar alguém nisso. Pode mostrar a um regulador e explicar o que significa na prática.
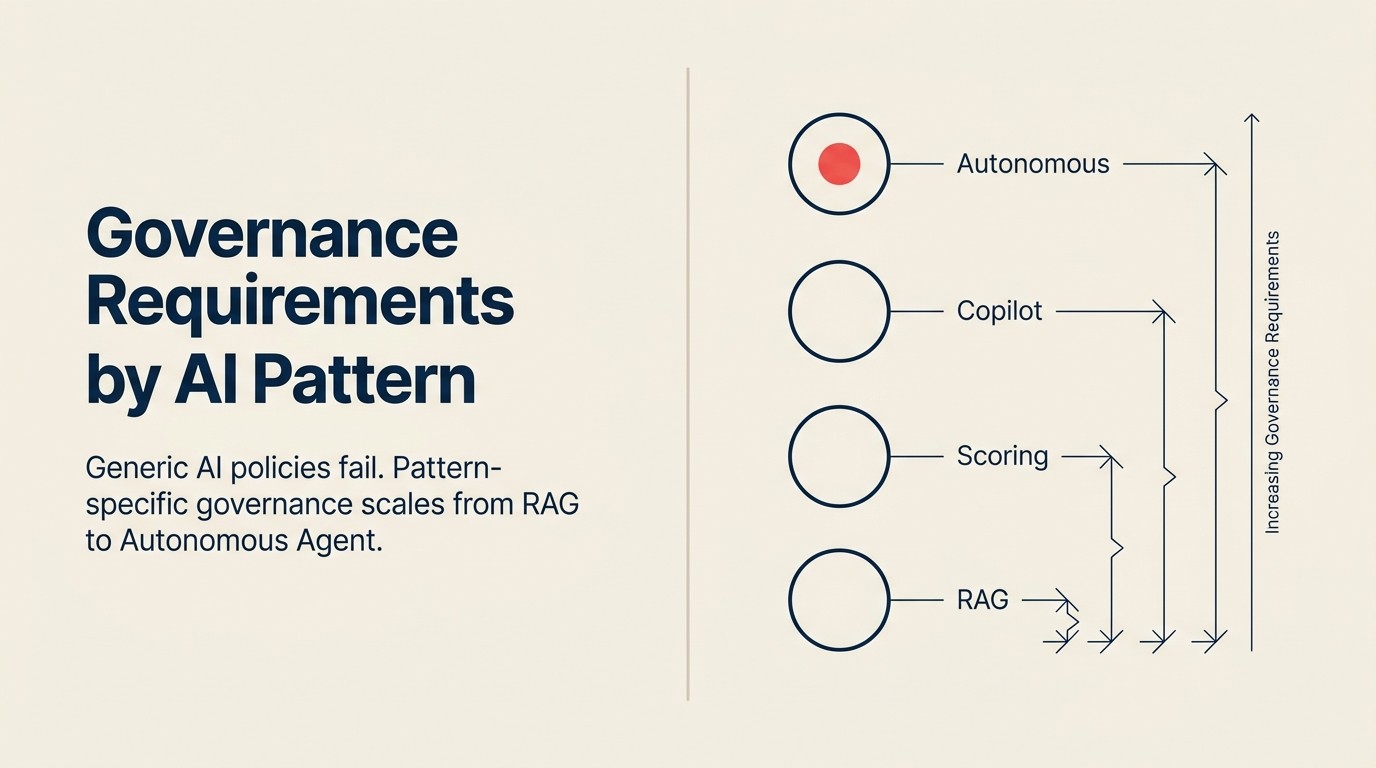
A maioria dos frameworks de governança de AI é escrita no nível errado de abstração, porque foram projetados para abranger toda a superfície de AI de uma organização. Essa amplitude impõe imprecisão. Este artigo vai na direção oposta: requisitos específicos para cada um dos 10 padrões de AI de negócios, baseados em quatro dimensões de governança aplicadas de forma consistente. O limite entre generate e execute é o conceito mais importante a ser internalizado antes de ler esses requisitos.
Por que a governança é específica por padrão
Os requisitos de governança seguem o risco. E o risco em sistemas de AI vem quase inteiramente de duas fontes: o que a capacidade Execute faz e em qual domínio ela opera. O NIST AI Risk Management Framework (AI RMF 1.0) codifica isso com quatro funções: GOVERN, MAP, MEASURE e MANAGE. O que este artigo faz no nível do padrão é uma implementação das funções MAP e MEASURE: tornando a superfície de risco de AI específica, auditável e operacional em vez de teórica.
Um RAG Assistant que lê documentos de políticas e responde perguntas de funcionários tem baixas necessidades de governança. O pior resultado realista é uma resposta incorreta e confiante sobre elegibilidade de benefícios. Incômodo. Corrigível. Não é um evento de responsabilidade.
Um Autonomous Agent que envia e-mails para clientes, atualiza registros financeiros no ERP e agenda reuniões em nome do CEO tem um risco completamente diferente. O pior resultado realista é uma ação irreversível tomada em escala com base em uma premissa alucinada. Isso é um evento de responsabilidade.
O gradiente de risco entre os padrões mapeia quase perfeitamente a intensidade de Execute de cada padrão. Padrões que ficam em Analyze ou Generate carregam uma carga de governança limitada. Padrões que Execute repetidamente, de forma autônoma e em escala, carregam uma carga substancial. Veja o gradiente de risco entre os padrões de AI para o framework completo.
Key Facts: Lacunas de Governança de AI nas Empresas
- 83% das organizações já usam ferramentas de AI, mas apenas 25% implementaram frameworks de governança robustos. (Compliance Week, 2026)
- O EU AI Act entra em vigor completo em 2 de agosto de 2026, com multas de até 35 milhões de euros ou 7% da receita global para violações de práticas de AI proibidas. Violações em sistemas de AI de alto risco acarretam multas de até 15 milhões de euros ou 3% da receita global.
- O mercado de governança de AI crescerá de 309 milhões de dólares em 2025 para 5,88 bilhões de dólares até 2035, um CAGR de 34%, refletindo a rápida institucionalização dos requisitos de governança nas implantações de AI empresarial.
"Até 2026, metade dos governos do mundo espera que as empresas cumpram as leis de AI e requisitos de privacidade de dados. As organizações que construíram infraestrutura de governança em 2024 e 2025 agora têm trilhas de auditoria, checkpoints HITL e mecanismos de override prontos para revisão regulatória. As que não fizeram isso estão fazendo retrofitting sob prazos de conformidade." (Modulos AI Compliance Guide, 2026)
As quatro dimensões de governança
Para cada padrão, a governança se desdobra em quatro dimensões. Elas são consistentes, então você pode construir sua política de governança de AI como uma tabela em vez de um texto narrativo:
Requisitos de trilha de auditoria. Quais registros precisam ser mantidos, em qual formato e por quanto tempo? As trilhas de auditoria servem a dois propósitos: depuração quando algo dá errado e demonstração de conformidade quando alguém pergunta. Ambos os propósitos exigem especificidade sobre quais inputs e outputs foram registrados.
Checkpoints de human-in-the-loop. Em qual ponto do fluxo de trabalho um humano precisa revisar antes que o sistema prossiga? Não "humanos devem revisar outputs." Uma etapa específica, uma condição específica, um ponto de decisão específico.
Mecanismos de override e rollback. Quando um humano discorda de uma ação de AI, ou quando uma etapa Execute se mostra incorreta, o que acontece? Todo padrão que pode Execute precisa de um caminho de rollback definido.
Frequência de revisão e retreinamento. Com que frequência o próprio padrão é revisado quanto à precisão, deriva e relevância contínua? Um modelo Scoring+Routing treinado nos leads do ano passado pode estar ativamente enganando neste ano. Alguém precisa ser responsável por essa revisão com uma agenda definida.
Governança do RAG Assistant
O RAG Assistant é o padrão mais amplamente implantado e carrega o menor risco de Execute de qualquer sistema de AI que responde a usuários. Mas "baixo risco" não significa "sem governança."
Trilha de auditoria: Registre consultas e respostas. Marque cada resposta com o(s) documento(s) fonte utilizados. Inclua uma pontuação de confiança ou contagem de citações quando disponível. Retenção mínima: 90 dias para depuração, mais tempo para setores regulamentados.
Checkpoints HITL: Não são necessários para casos de uso somente leitura onde os usuários entendem que estão interagindo com AI. Obrigatórios quando o output do RAG é usado em comunicação externa: rascunhos de e-mail para clientes, registros regulatórios, propostas para clientes. Se o output sair da empresa, um humano o revisa primeiro.
Mecanismo de override: Defina o processo de correção da base de conhecimento. Quando um usuário identifica uma resposta incorreta, quem pode atualizar o documento fonte? Qual é o SLA de resposta para correções críticas?
Cadência de revisão: Auditoria trimestral da base de conhecimento. Verifique documentos desatualizados, links de fonte quebrados e tópicos onde as perguntas dos usuários ficam sem resposta (sinal de lacunas de conhecimento). Revisão anual da qualidade de recuperação usando um conjunto de consultas de teste.
Governança do Scoring + Routing
Este padrão carrega pouca carga direta de governança, mas exposição significativa de conformidade quando aplicado a pessoas (contratação, empréstimos, seguros, justiça criminal). Quando Scoring+Routing determina qual tratamento humanos recebem, ECOA, GDPR Artigo 22 e Title VII se tornam relevantes.
Trilha de auditoria: Registre cada decisão de pontuação com os features de input utilizados e a pontuação produzida. Isso não é negociável para qualquer caso de uso regulamentado. "Nosso modelo disse 62" não é um registro de governança. "Modelo versão 3.1, features de input: porte da empresa=enterprise, engajamento=alto, demo=concluído, pontuação=62, roteado para: equipe enterprise-west" é.
Checkpoints HITL: Override humano disponível em qualquer decisão de roteamento. Representantes de vendas devem poder reatribuir leads manualmente. Equipes de suporte devem poder escalar tickets manualmente independentemente da pontuação de AI. A rota da AI é um padrão, não um bloqueio.
Mecanismo de override: Bypass manual de roteamento para cada ponto de decisão. Garanta que as ações de bypass também sejam registradas. Padrões de overrides manuais frequentemente sinalizam deriva do modelo ou problemas de qualidade de dados.
Cadência de revisão: Revisão mensal da distribuição de pontuações. Se a pontuação mediana está mudando ou o bucket de pontuações altas está diminuindo, algo mudou nos seus dados ou no seu mercado. Revisão trimestral da precisão do modelo em relação a dados de teste retidos.
Governança do Vision Extract
Este padrão substitui a entrada de dados humana. A questão de governança é: o que acontece quando ele erra e quem detecta o erro?
Trilha de auditoria: Registre todos os registros extraídos com a imagem fonte, a pontuação de confiança de extração e os valores de campo extraídos. Armazene as imagens fonte pelo período de vida do negócio do registro.
Checkpoints HITL: Obrigatório para extrações com baixa confiança. Defina seu limite de confiança (tipicamente, qualquer coisa abaixo de 85% de precisão em campos críticos vai para a fila de revisão humana). Também obrigatório para qualquer extração que será usada em uma transação financeira sem verificação adicional.
Mecanismo de override: Fluxo de trabalho de correção manual de campos com log de auditoria. Cada correção humana deve ser registrada. Esse é o seu sinal de treinamento para melhoria do modelo.
Cadência de revisão: Verificação mensal de precisão em uma amostra de extrações de alta confiança. Você está procurando erros sistemáticos que ficam acima do limite de confiança. Adições de tipos de documentos ou mudanças de formato de fornecedores devem acionar verificação imediata.
Governança do Meeting Intelligence
O padrão Meeting Intelligence tem duas preocupações de governança distintas que a maioria das implantações subestima: consentimento e qualidade dos dados do CRM. Para um exemplo completo de governança em um contexto de sales ops com AI, governança e trilhas de auditoria em AI sales ops cobre o framework completo de auditoria.
Requisitos de consentimento: O consentimento para gravação não é uniforme. Estados com consentimento de uma parte (incluindo a maior parte dos EUA) permitem gravação se uma das partes consentir. Estados com consentimento de duas partes (Califórnia, Flórida e outros) exigem que todas as partes consintam. O GDPR estende os requisitos de consentimento a cidadãos da UE, independentemente de onde estejam ligando. Se seus representantes usam Meeting Intelligence em qualquer chamada com qualquer participante europeu, você precisa de consentimento documentado. Armazenar gravações sem consentimento é uma responsabilidade, não apenas uma caixa de conformidade.
Trilha de auditoria: Armazenamento de gravações com agenda de retenção adequada ao seu setor (tipicamente 1 a 3 anos para chamadas de vendas, potencialmente mais longo para serviços financeiros ou saúde). Logs de push para o CRM: quando a AI escreveu o quê em qual registro?
Checkpoints HITL: Revisão humana dos pushes para o CRM antes que se tornem dados de sistema de registro. O output do Meeting Intelligence deve entrar em uma área de staging primeiro, não escrever diretamente nos campos ativos do CRM. Uma revisão de cinco minutos por um representante antes de aprovar o push detecta a maioria dos erros sem destruir o ganho de tempo.
Mecanismo de override: Fluxo de trabalho de correção para entradas do CRM. Notas escritas por AI que estejam erradas devem ser corrigíveis com um timestamp mostrando que a correção foi iniciada por humano.
Cadência de revisão: Verificação mensal da qualidade dos dados do CRM para registros escritos por AI. Os itens de ação estão precisos? As atribuições de speakers estão corretas? Os resumos estão capturando os compromissos certos?
Governança do Anomaly Agent
A principal preocupação de governança aqui é o custo do falso positivo: agir sobre uma anomalia que acabou sendo uma variação normal dos negócios.
Trilha de auditoria: Todos os alertas registrados com os dados de sinal que desencadearam o alerta, o nível de confiança do modelo e a disposição (revisado, dispensado, escalado). Esta trilha de auditoria é essencial tanto para depuração quanto para análise de falsos positivos.
Checkpoints HITL: Revisão humana obrigatória antes de qualquer ação Execute em uma anomalia sinalizada. O Anomaly Agent deve alertar e enfileirar, não alertar e agir. Se o seu padrão tem um bloqueio automático (prevenção de fraude), o limite para ação automática deve ser extremamente alto, e todas as ações automáticas devem ser revisadas após o fato.
Mecanismo de override: Supressão de sinalizações para padrões de falsos positivos conhecidos. Se os pagamentos de um fornecedor sempre parecem anômalos por causa do ciclo de faturamento, esse padrão deve ser suprimido na fonte em vez de revisado manualmente todo mês.
Cadência de revisão: Taxa de falsos positivos revisada mensalmente. Se sua taxa de falsos positivos está acima de 15%, a sobrecarga de governança está consumindo o valor. Se está abaixo de 1%, você pode estar deixando passar anomalias reais. O ponto operacional ideal depende do domínio e do custo da ação.
Generative Research, Document Review e Workflow Copilot
Esses três padrões compartilham um perfil de governança comum: o risco principal é distribuir texto gerado por AI como autoritativo sem revisão adequada.
Generative Research: Todo output distribuído fora da equipe imediata requer verificação de fatos por humanos em relação a fontes primárias. A trilha de auditoria registra a consulta, as fontes acessadas e quem aprovou o output para distribuição. Cadência de revisão: verificação mensal da precisão dos outputs, especialmente para casos de uso de alto risco (briefings para investidores, submissões regulatórias, entregas para clientes).
Document Review: O output de AI é um sistema de sinalização, não uma opinião legal. Advogados revisam antes de agir sobre qualquer sinalização. A trilha de auditoria registra qual documento, quais cláusulas foram sinalizadas e qual foi a disposição do advogado humano. Nenhuma ação automatizada em contratos sem aprovação humana.
Workflow Copilot: A governança se concentra no vazamento de dados. Quais dados o copilot está vendo? Se ele está puxando do CRM, ele pode acessar registros fora do território normal de um representante? Os limites de acesso a dados para o copilot precisam ser definidos e auditados, não assumidos.
Governança do Autonomous Agent
Esta é a seção de governança mais crítica do framework e a que a maioria das implementações subestima até que algo dê errado.
Autonomous Agents percorrem todas as cinco capacidades em um loop: Ingest, Analyze, Predict, Generate, Execute e depois repetem. Cada etapa Execute tem consequências. Os erros se acumulam ao longo das iterações. Uma etapa intermediária alucinada na iteração 3 do loop pode gerar uma sequência de ações erradas nas iterações 4 a 8 antes que qualquer humano veja os resultados.
Trilha de auditoria: Cada chamada de ferramenta registrada com parâmetros de input, output e raciocínio de decisão (a etapa Generate que conduziu a decisão Execute). Não apenas "o agente enviou e-mail" mas "o agente recebeu uma solicitação de confirmação de reunião, determinou a janela de agendamento via consulta ao calendário, gerou rascunho de e-mail, enviou para contato externo." Proveniência completa da intenção à ação.
Checkpoints HITL (obrigatórios):
- Antes de qualquer etapa Execute que envie comunicação externa
- Antes de qualquer etapa Execute que altere um registro financeiro
- Antes de qualquer etapa Execute que modifique um registro pertencente a alguém fora da equipe do originador da tarefa
- Antes de qualquer sequência de 3 ou mais etapas Execute em uma única tarefa
Esses não são sugestões. São o requisito mínimo para uma implantação de Autonomous Agent voltada ao cliente. Qualquer implantação sem esses checkpoints está apostando que o agente não vai alucinar em direção a uma ação irreversível. Essa aposta eventualmente vai perder. O EU AI Act, Artigo 14 exige que sistemas de AI de alto risco sejam projetados para que pessoas naturais possam "detectar e corrigir anomalias, permanecer cientes do viés de automação, interpretar corretamente o output do sistema e decidir não usá-lo." Esses requisitos mapeiam diretamente esses checkpoints para qualquer agente operando em contextos de emprego, serviços financeiros ou voltados ao cliente.
Limites de escopo: Defina uma lista de permissões explícita das ferramentas que o agente pode acessar. Um agente que precisa agendar reuniões não precisa de acesso ao seu sistema de faturamento. Um agente que faz pesquisa de conta não precisa de acesso de envio ao seu cliente de e-mail. Os limites de escopo são sua principal defesa contra comportamento Execute inesperado.
Mecanismo de override: Capacidade de parar a tarefa e fazer rollback. O operador precisa da capacidade de interromper uma tarefa do agente em andamento e reverter quaisquer etapas Execute já realizadas. Se sua plataforma não suporta parada de tarefa e rollback, sua postura de governança é fraca independentemente das políticas que você escreveu.
Cadência de revisão: Semanal durante a implantação inicial (primeiros 60 dias). Mensal após a linha de base estabelecida. Auditoria completa de todas as ações Execute trimestralmente, revisando especificamente os casos em que o agente concluiu tarefas de maneiras inesperadas.
| Padrão | Intensidade de Execute | Principal preocupação de conformidade | Requisito mínimo de HITL | Retenção de trilha de auditoria |
|---|---|---|---|---|
| RAG Assistant | Nenhuma (somente leitura) | Respostas incorretas e confiantes | Obrigatório somente para distribuição externa | 90 dias |
| Scoring + Routing | Leve (decisões de roteamento) | Viés algorítmico em RH/crédito | Override humano disponível em cada decisão de roteamento | 12 meses (regulamentado) |
| Vision Extract | Médio (substituição de entrada de dados) | Precisão de registros financeiros | Extrações de baixa confiança vão para fila de revisão humana | Duração da vida útil do negócio do registro |
| Meeting Intelligence | Leve (push para CRM) | Consentimento de gravação por jurisdição | Revisão humana antes que o staging do CRM entre em vigor | 1 a 3 anos (dependendo do setor) |
| Anomaly Agent | Médio (alerta + bloqueio) | Custos de ação por falsos positivos | Revisão humana antes de qualquer ação Execute em item sinalizado | 12 meses |
| Generative Research | Nenhuma (gera texto) | Citações alucinadas distribuídas externamente | Verificação de fatos por humano antes da distribuição externa | 90 dias |
| Document Review | Nenhuma (sinaliza, não altera) | Responsabilidade de opinião legal se tratado como tal | Revisão de advogado antes de agir sobre qualquer sinalização | Ciclo de vida do contrato |
| Workflow Copilot | Leve (sugere, humano aprova) | Vazamento de limite de acesso a dados | Aprovação humana antes de enviar | 90 dias |
| Autonomous Agent | Alto (loop de Execute em múltiplas etapas) | Ações irreversíveis em escala com base em premissas alucinadas | Antes de comunicações externas, alterações financeiras, 3 ou mais etapas Execute | Proveniência completa, 2 ou mais anos |
O Per-Pattern Governance Footprint
O Per-Pattern Governance Footprint é um formato de política estruturado que especifica, para cada implantação ativa de padrão de AI, exatamente quatro coisas: a especificação da trilha de auditoria (formato, campos registrados e período de retenção), os checkpoints de human-in-the-loop (etapa específica, condição de gatilho, quem aprova), o mecanismo de override e rollback (quem pode fazer override, como, com qual registro mantido) e a frequência de revisão e retreinamento (quem revisa, o que procuram, em qual agenda). O framework é baseado no princípio de que os requisitos de governança seguem a intensidade de Execute: padrões nas etapas Analyze e Generate carregam carga de governança limitada, enquanto padrões que Execute repetidamente, de forma autônoma ou em escala, carregam carga substancial proporcional à sua superfície de consequências.
Rework Analysis: Com base na descoberta da Compliance Week de que 83% das empresas usam AI, mas apenas 25% têm frameworks de governança robustos, e com a vigência completa do EU AI Act para sistemas de AI de alto risco em agosto de 2026, o Per-Pattern Governance Footprint representa a estrutura de governança mínima viável para qualquer organização que opera AI em contextos de emprego, financeiro, saúde ou voltados ao cliente. Os dados de implementação de governança da Rework mostram que as equipes que definem o Per-Pattern Governance Footprint antes de implantar cada padrão reduzem o tempo de preparação de auditoria de conformidade em uma média de 8 semanas em comparação com as equipes que documentam a governança retroativamente após reguladores ou incidentes exigirem isso.
Construindo a política de governança a partir deste framework
Uma política de governança específica por padrão tem esta estrutura:
Inventário de padrões. Liste todas as implantações ativas de padrões de AI na organização, a equipe responsável e as ações Execute que ela pode realizar.
Classificação de risco. Usando as quatro dimensões acima, classifique cada implantação em uma escala de 1 a 5. Implantações de Autonomous Agent voltadas ao cliente pontuam 5. RAG Assistants somente leitura pontuam 1.
Tabela de requisitos. Para cada implantação: especificação da trilha de auditoria (formato, campos, retenção), checkpoints HITL (etapa específica, condição de gatilho específica), mecanismo de override (quem pode fazer override, como, com qual registro) e cadência de revisão (quem revisa, o que procuram, quando).
Atribuição de responsabilidade. Cada implantação de padrão tem um responsável operacional nomeado que é accountable pela cadência de revisão e pela resposta a incidentes.
Procedimento de resposta a incidentes. Quando um padrão produz um output que causa dano (ação errada tomada, dados vazados, alucinação distribuída externamente), quem é notificado, quem investiga e quais são os pontos de decisão para suspensão versus operação continuada com controles adicionais?
Isso não é um exercício de conformidade. É o procedimento operacional que permite executar padrões de alta autonomia com segurança. Sem ele, cada implantação de Autonomous Agent está a um incidente de ser desligada permanentemente.
O objetivo da governança não é desacelerar a adoção de AI. É tornar a adoção durável. Os Princípios de AI da OCDE, adotados por 42 países e referência fundamental tanto para o EU AI Act quanto para o framework NIST, descrevem accountability como um princípio central: os atores de AI são responsáveis pelo funcionamento adequado dos sistemas de AI e pelo respeito às normas aplicáveis. A governança específica por padrão é como essa accountability se torna operacional em vez de aspiracional. As equipes que implantam sem estruturas de governança têm seus padrões desligados por jurídico ou conformidade após o primeiro incidente e passam meses reconstruindo confiança. As equipes que implantam com governança específica por padrão podem avançar mais rapidamente na próxima implantação porque demonstraram disciplina operacional na primeira.
Os padrões são poderosos. A governança é o que os mantém em execução. Comece com risco de alucinação por padrão para os modos de falha específicos que a governança foi projetada para detectar, e medindo ROI por padrão para os dados de trilha de auditoria que alimentam sua análise de ROI.
Perguntas Frequentes
Por que os padrões de AI precisam de governança específica por padrão em vez de uma única política?
Porque os requisitos de governança seguem a intensidade de Execute, e a intensidade de Execute varia dramaticamente entre os padrões. Um RAG Assistant que responde perguntas de funcionários carrega quase nenhum risco de Execute. Um Autonomous Agent que envia e-mails, atualiza registros financeiros e agenda reuniões carrega risco substancial de irreversibilidade. Uma única política que abrange ambos ou governa o RAG Assistant com excessiva rigidez (desacelerando a adoção) ou governa o Autonomous Agent com excessiva leveza (criando risco de incidente).
O que é o Per-Pattern Governance Footprint?
O Per-Pattern Governance Footprint especifica quatro coisas para cada padrão de AI ativo: a especificação da trilha de auditoria (formato, campos, retenção), checkpoints de human-in-the-loop (etapa e condição de gatilho específicas), mecanismo de override e rollback (quem pode fazer override, como, com qual registro) e frequência de revisão e retreinamento. Ele transforma declarações genéricas de governança em procedimentos operacionais que podem ser auditados, ensinados e mostrados a reguladores.
Quais requisitos do EU AI Act se aplicam a implantações de Autonomous Agent?
O Artigo 14 exige que sistemas de AI de alto risco permitam que humanos detectem e corrijam anomalias, permaneçam cientes do viés de automação, interpretem corretamente os outputs do sistema e decidam não usá-lo. Isso mapeia diretamente para quatro requisitos de governança do Autonomous Agent: capacidade de parada de tarefa e rollback, registro e cadência de revisão de falsos positivos, trilhas de auditoria de proveniência completa da intenção à ação e aprovação humana antes de etapas Execute irreversíveis. Multas por não conformidade com o EU AI Act chegam a 35 milhões de euros ou 7% da receita global por práticas proibidas.
Com que frequência os padrões de AI devem ser revisados para deriva do modelo?
Modelos de Scoring e Routing devem ser revisados mensalmente para mudanças na distribuição de pontuações e trimestralmente para precisão em relação a dados de teste retidos. Anomaly Agents devem ter sua taxa de falsos positivos revisada mensalmente. RAG Assistants requerem auditorias trimestrais da base de conhecimento. Autonomous Agents devem ser revisados semanalmente nos primeiros 60 dias, depois mensalmente, com uma auditoria trimestral completa de todas as ações Execute. A deriva do modelo é a lacuna de governança mais comum em implantações do segundo ano porque as equipes constroem cadências de revisão nos planos de lançamento e depois as deprioritizam conforme outros trabalhos se acumulam.
Qual é o modo de falha de governança mais crítico para Autonomous Agents?
Implantar sem capacidade de parada de tarefa e rollback. Autonomous Agents percorrem todas as cinco capacidades ACE em um loop, o que significa que cada etapa Execute se baseia na anterior. Uma etapa intermediária alucinada na iteração 3 do loop pode gerar uma sequência de ações erradas nas iterações 4 a 8 antes que qualquer humano veja os resultados. Sem a capacidade de interromper o agente no meio da execução e reverter etapas Execute já realizadas, a postura de governança é teórica em vez de operacional. Se sua plataforma de agente não suporta parada de tarefa e rollback, isso é um requisito bloqueante antes da implantação.
Como os padrões de Scoring e Routing criam risco de conformidade em contextos de RH?
Quando Scoring e Routing determina quais candidatos avançam em um processo de contratação, EEOC Title VII, GDPR Artigo 22 e leis estaduais emergentes de viés de AI se tornam aplicáveis. O modelo não deve usar características protegidas como features (ou features que servem como proxies para características protegidas). As trilhas de auditoria devem registrar cada decisão de pontuação com os features de input utilizados. O override humano deve estar disponível em cada decisão de roteamento. Nos EUA, mais de 40 estados agora têm legislação ativa de AI, com Texas TRAIGA e California SB 53 ambas em vigor a partir de 1 de janeiro de 2026, criando obrigações concretas de conformidade para decisões de emprego algorítmicas.
Saiba mais

Co-Founder, Rework.com
On this page
- Por que a governança é específica por padrão
- As quatro dimensões de governança
- Governança do RAG Assistant
- Governança do Scoring + Routing
- Governança do Vision Extract
- Governança do Meeting Intelligence
- Governança do Anomaly Agent
- Generative Research, Document Review e Workflow Copilot
- Governança do Autonomous Agent
- O Per-Pattern Governance Footprint
- Construindo a política de governança a partir deste framework
- Saiba mais