How AI Patterns Combine Capabilities Into Solutions

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
There's a common mental model of AI that imagines one smart system sitting at the center of a business, accepting any question and returning the right answer. Ask it a sales question, get sales insight. Ask it an HR question, get HR policy. Ask it to send an email, it sends the email.
That model is wrong, and believing it causes expensive mistakes.
A capable AI system is not one model doing everything. It's a sequence of specialized moves. The same way a supply chain has receiving, inspection, routing, and shipping (each stage doing one thing, handing off to the next), an AI workflow has Ingest, Analyze, Predict, Generate, and Execute. Each capability does its specific job. The output of one step becomes the input of the next. And the weakest link in that chain determines the quality of the whole system.
This article shows you exactly how those chains work. Three worked examples. Real failure modes at each handoff. And a way to read any AI vendor pitch with the chain in mind.
The 5 capabilities: one paragraph each
Before looking at chains, get clear on what each capability actually does in isolation.
Ingest is perception. It converts a raw signal (an image, a recording, a PDF, a live data stream) into a format the AI can work with. Ingest doesn't understand the content. It converts it. Speech-to-text is Ingest. OCR on a scanned invoice is Ingest. Pulling CRM records via API is Ingest. The output of Ingest is always something more machine-readable than what went in. Read the full breakdown in Ingest: How AI Takes In Your Business Data.
Analyze is comprehension. It takes the ingested material and makes sense of it. Classification (this email is a complaint), extraction (the vendor name is Acme Corp, the amount is $4,200), summarization (the key points from this 80-page contract), sentiment detection (this customer is frustrated). Analyze answers: what is this, and what's in it?
Predict is foresight. It uses patterns learned from historical data to estimate what comes next. A lead scoring model predicting 82% conversion probability is Predict. A churn model flagging three accounts at elevated risk is Predict. An anomaly detector saying "this transaction is statistically unusual" is Predict. It answers: what's likely?
Generate is creation. It produces a new artifact: a draft email, a summary paragraph, a piece of code, an image, a structured plan. The artifact sits in draft form. It hasn't been sent, committed, or shared. Generate answers: what should we create in response to what we know?
Execute is action. It changes state outside the AI system. Sends the email. Updates the CRM record. Routes the support ticket. Places the order. Flags the transaction. Execute has consequences that are often hard to reverse. It answers: what should change in the world, right now? The full implications are covered in Execute: When AI Changes External State (and Why It's Risky).
These five cover everything any business AI system does. For a deeper look at each one individually, the ACE Framework Foundation covers all five capabilities with their full definitions. Now watch how they chain.
Key Facts: AI Capability Chain Performance
- Fewer than 10% of enterprises that experiment with AI agents successfully scale them to tangible value, primarily due to failed capability handoffs (McKinsey Agentic AI Study, 2025)
- 80% of organizations have encountered risky or unexpected behavior from AI agents, with nearly every incident tracing back to an Execute step that fired without adequate upstream validation (McKinsey, 2025)
- AI systems with structured multi-step capability chains deliver 3.5x more accurate outputs than single-prompt models on complex business tasks (Stanford HAI, 2024)
How capabilities chain into patterns
Capability chains are useful because they expose where a bad input becomes a bad judgment, generated artifact, or action.
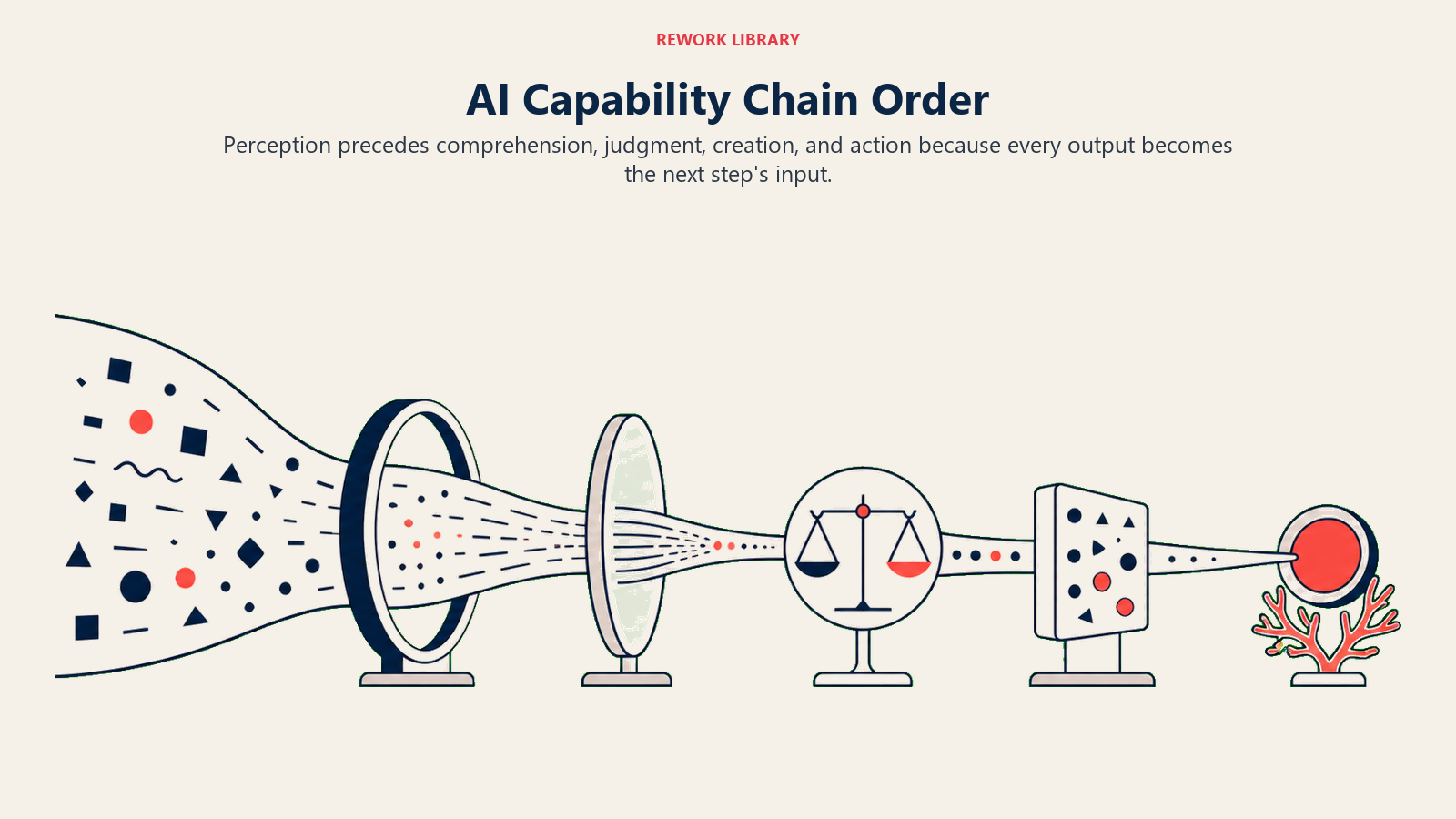
The chain notation is straightforward: Capability A (what it operates on) → Capability B (what it produces) → Capability C (what it decides or creates).
The order matters because each step's output becomes the next step's input. If Ingest produces a poor-quality transcript (background noise, unclear speakers, technical jargon misread), then Analyze is working with bad material. If Analyze misclassifies the intent, Predict has the wrong features. If Predict scores incorrectly, Execute routes the wrong way. Errors compound downstream.
This is the most important thing to understand about AI patterns: the system is only as strong as its weakest handoff.
AI teams that document their capability chains before deployment catch an average of 2.3 integration failure points per system before they reach production, versus 0.6 failure points identified by teams that don't model the chain explicitly (Gartner AI Engineering Report, 2025).
The Capability Stack Order Rule
In any AI pattern, capabilities must execute in the sequence: perception before comprehension, comprehension before judgment, judgment before creation, creation before action. Skipping or reversing a step does not simplify the system. It relocates the problem downstream, where it is harder to detect and costlier to fix. Every reliable AI pattern respects this order, even when vendors obscure it behind a single "smart" interface.
Let's trace three real patterns at increasing levels of complexity.
Worked example 1: RAG Assistant (simple, 3 capabilities)
The RAG example is intentionally simple: a user question flows through retrieval and generation without prediction or execution.
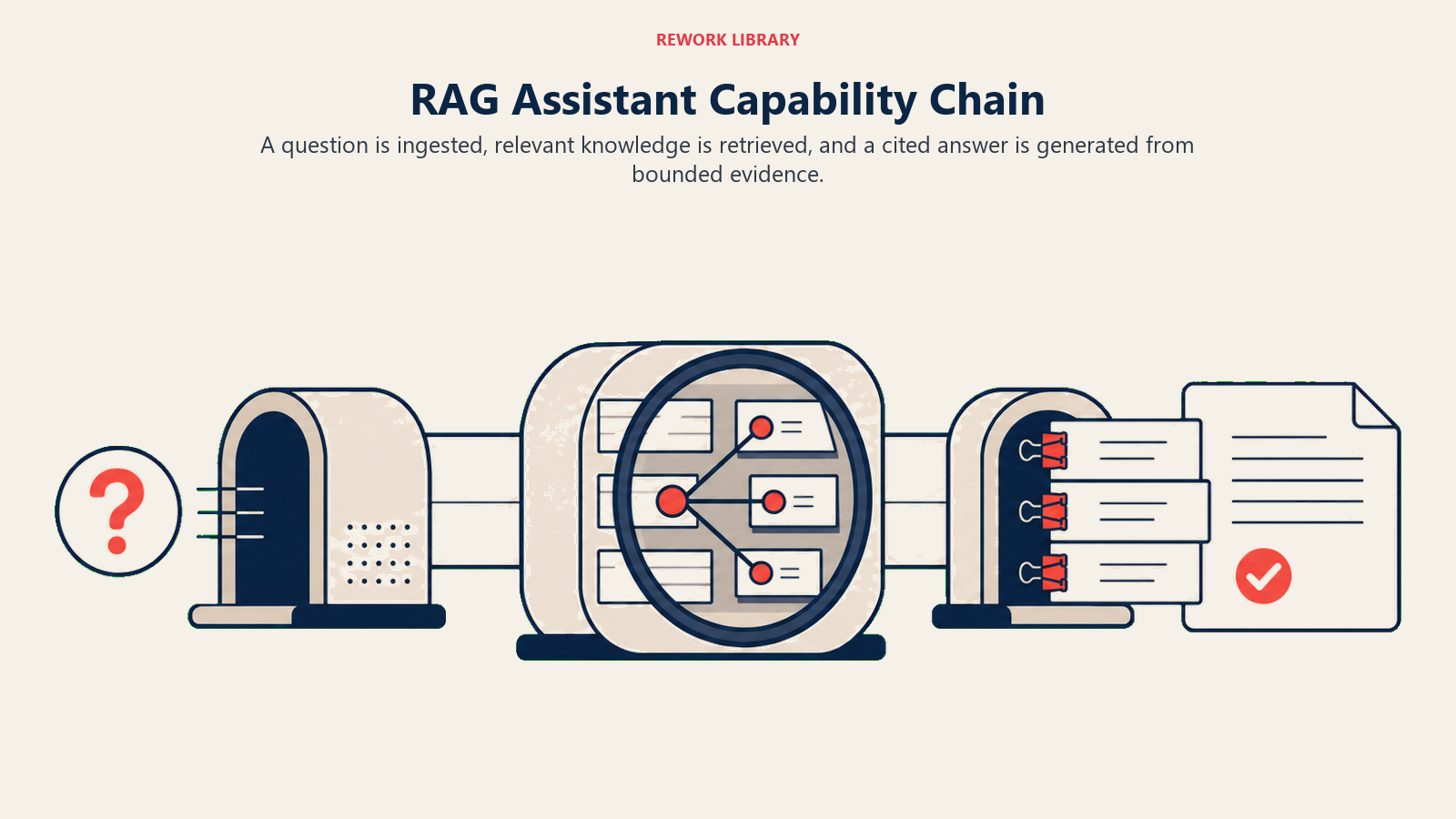
The problem: A 300-person software company has built up a 400-page knowledge base over five years. Policies, product specs, onboarding docs, historical RFP answers, legal FAQs. A new sales rep asks "does our product support SOC 2 Type II?" The knowledge base has the answer, buried in a security addendum from 2023. The rep can't find it in time for the call.
The chain: Ingest (the rep's question) → Analyze (retrieve relevant docs from the knowledge base) → Generate (answer with citations)
Walk through each step concretely.
The rep types their question. Ingest converts it into a query vector, a mathematical representation of the question's meaning. This is the perception step: converting natural language into something the retrieval system understands.
Analyze runs a similarity search across all 400 pages of indexed knowledge base content. It finds the three most relevant passages: the security addendum, a compliance FAQ, and a customer-facing product page. It doesn't understand the content yet. It retrieves based on relevance to the query vector.
Generate takes the rep's original question and the three retrieved passages as context. It composes an answer: "Yes, the product is SOC 2 Type II certified. The latest certificate was issued in March 2024 and covers the following control categories... [source: Security Addendum v4, page 3]."
What makes this a pattern and not just "using ChatGPT": the Analyze step (retrieval from a bounded, trusted knowledge base) is what gives the Generated answer its accuracy. Without the retrieval step, you'd be asking a general-purpose language model to answer a question about your specific product. It would Generate an answer, but it might be wrong, outdated, or hallucinated. Hallucination risk by AI pattern explains why RAG specifically exists to solve this problem.
The critical handoff: Ingest to Analyze. If the knowledge base isn't indexed properly, or if the rep's question is phrased in a way that doesn't match the terminology in the docs, the retrieval returns irrelevant passages. Generate then writes a confident-sounding but wrong answer. The failure doesn't look like an error. It looks like an authoritative response.
Worked example 2: Meeting Intelligence (complex, 4 capabilities)
The problem: A sales team runs 200 discovery calls per month. After each call, reps are supposed to log notes in the CRM, send a follow-up email summarizing next steps, and update the deal stage. Most reps do the bare minimum. Notes are thin. Follow-ups are templated. Deal data is stale. The Sales Director can't coach based on call patterns she can't see.
The chain: Ingest (audio/video recording) → Analyze (transcribe + extract topics, action items, sentiment) → Generate (call summary, follow-up email, CRM notes) → Execute (push to CRM, send email to prospect)
Walk through each step.
Ingest receives the recorded call. It runs speech-to-text transcription, handling multiple speakers (rep and prospect), producing a time-stamped text transcript with speaker labels. If there's a video, it also captures facial expression and engagement signals. Output: a clean, labeled transcript.
Analyze runs several sub-processes in parallel on that transcript. Topic classification: what themes came up? (pricing, integration, timeline, competitors). Action item extraction: what did each party commit to? Sentiment analysis: was the prospect engaged or resistant? Question analysis: how many discovery questions did the rep ask? Filler-word flagging: did the rep talk 80% of the time? Each of these is a separate Analyze sub-task, but they're all Analyze: making sense of ingested material.
Generate takes the Analyze outputs and produces three artifacts: a structured call summary (topics discussed, objections raised, next steps), a draft follow-up email to the prospect (personalized to the specific conversation), and a set of CRM field updates (deal stage, sentiment score, key contacts mentioned). These are drafts. Nothing has been sent or committed.
Execute (and this is where governance matters) sends the follow-up email to the prospect, pushes the CRM updates to Salesforce, and notifies the Sales Director's coaching dashboard. In most implementations, the rep reviews the draft first. In more automated setups, Execute happens without review. The difference in those two designs has significant implications for mistakes (email going to wrong person, wrong deal stage committed, coaching data distorted by a bad Analyze run).
The critical handoffs: Ingest quality determines everything. A noisy recording produces a bad transcript. A bad transcript means Analyze can't accurately extract topics or sentiment. An inaccurate Analyze means Generate produces incorrect summaries and wrong CRM entries. By the time Execute fires, the damage is already done. But nobody sees it until a rep gets coached on a call that the AI misread.
This is also where the four-capability chain becomes genuinely complex: each of the four sub-systems (transcription, analysis, generation, CRM integration) is a separate engineering challenge. They can fail independently. The chain is only as reliable as its least-reliable link. Pattern dependencies and prerequisites maps out exactly what each pattern needs to succeed.
Worked example 3: Autonomous Agent (looping, all 5 capabilities)
The problem: A head of partnerships needs to qualify 50 inbound partnership inquiries per month. Each qualification requires researching the company, checking fit against a criteria rubric, drafting a prioritized response or a polite decline, and updating the partnership CRM. It currently takes 3-4 hours per week of her time just for the initial triage pass.
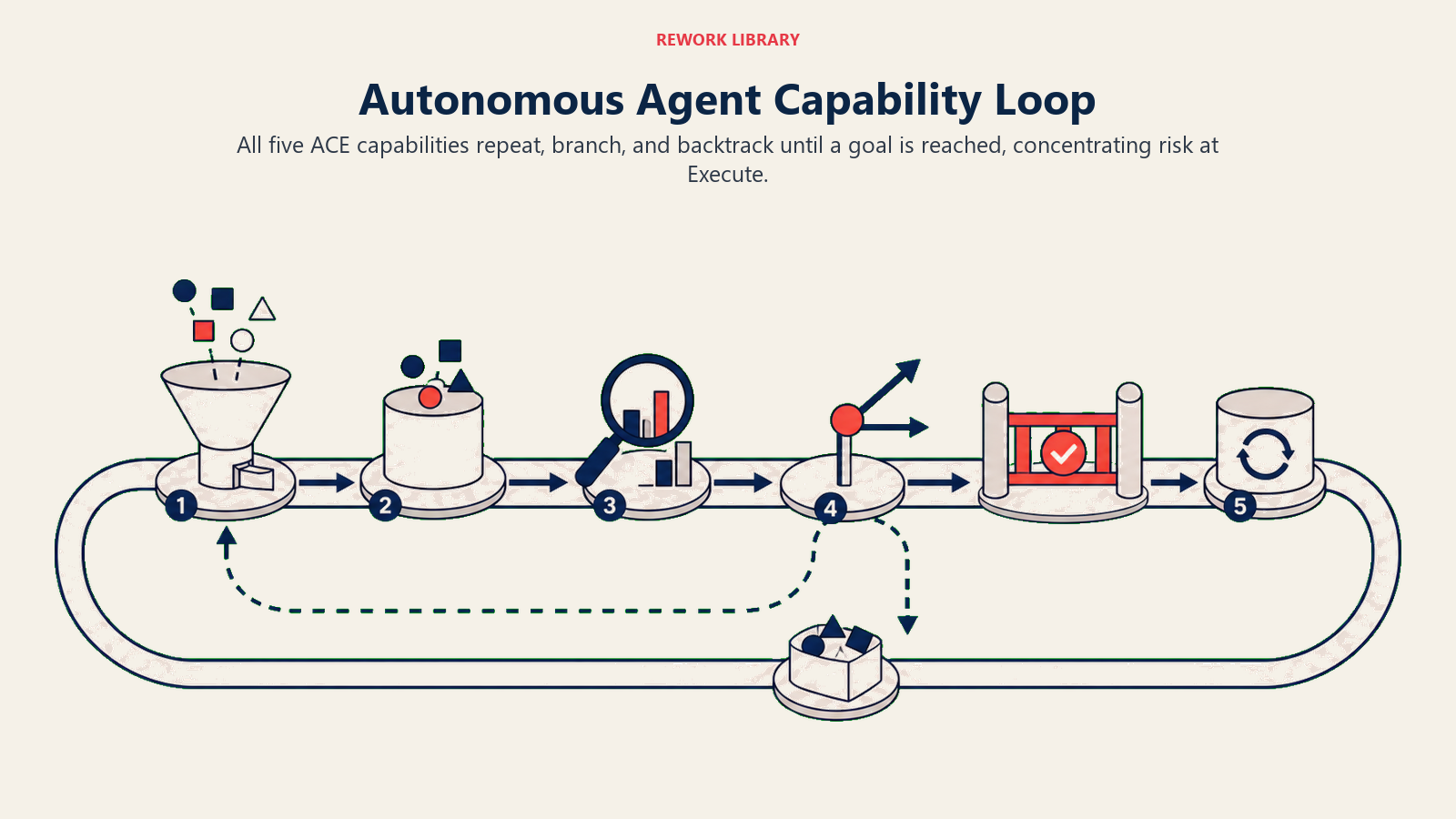
The chain (looping): Ingest (partnership inquiry email + company URL) → Analyze (extract company info, check against criteria) → Predict (fit score) → Generate (acceptance draft or decline draft) → Execute (send response + update CRM) → repeat for next inquiry
What makes this an Autonomous Agent and not just a simple chain: the loop. The agent doesn't just run through the chain once. It runs it for each item in the queue. And it can backtrack: if the initial company research (first Analyze pass) comes back incomplete, the agent issues a follow-up Ingest (fetches more data from another source) before running Predict.
Walk through a single iteration.
A new partnership inquiry arrives. Ingest pulls the email text, the sender's company name, and the URL they included. It also fetches the company's LinkedIn page and Crunchbase profile. Output: a structured data package about the inquiry.
Analyze reads the structured data and checks it against the partnership criteria: company size, industry vertical, existing integrations, geographic focus. It extracts the key signals: 45-person company, B2B SaaS, operates in North America, no existing integrations. Output: a set of tagged attributes.
Predict scores the inquiry against the fit model: 73% fit, above the 65% threshold for a full exploration. (Below threshold inquiries get the polite decline path.)
Generate drafts a response email acknowledging the inquiry, proposing a 30-minute discovery call, and noting two specific reasons the fit looks promising. It also generates a CRM entry with the fit score and key attributes.
Execute sends the email, creates the CRM record, and moves the inquiry to the "Active Qualification" stage. Then the loop moves to the next inquiry.
Why this is different from the linear examples: The loop means the agent is making decisions about what to do next, not just running a fixed sequence. If the Predict score is low, the path diverges. If Analyze comes back with incomplete data, the path revisits Ingest. This is what "agentic" means in the technical sense: the system has a goal, and it's choosing its path to reach it. See stacking patterns to build AI agents for how this composability plays out in real deployments.
The critical concern: Execute in a loop. Every time the agent sends an email or updates a CRM record, it's taking an action with consequences. McKinsey reports that 80% of organizations have encountered risky behavior from AI agents, and almost every case traces back to an Execute step that fired without adequate upstream validation. If the Analyze step misclassified a high-value prospect as a low-fit inquiry, Execute sent them a decline. You can't unsend that email. Autonomous Agents are the highest-risk pattern in the ACE Framework, and that risk is almost entirely concentrated at the Execute step inside a loop. The Generate-vs-Execute boundary is the exact line where this risk lives.
Common mistakes when combining capabilities
Skipping Analyze before Generate. The most common shortcut is to connect Ingest directly to Generate: feed the raw input to the model and ask it to produce a response. This skips the retrieval, extraction, and comprehension step. The result is AI hallucination: the model generates something coherent-sounding that isn't grounded in the actual content. Adding the Analyze step (retrieval, classification, extraction) is what grounds the output. Enterprise AI systems that include an Analyze step between Ingest and Generate reduce hallucination rates by up to 60% versus direct Ingest-to-Generate pipelines, according to Google DeepMind's RAG evaluation benchmarks (2024).
Skipping Ingest quality checks. Garbage in, garbage out isn't a new idea, but it applies with unusual force to AI chains. A bad transcript means bad analysis means bad generation. Unlike traditional software where bad input produces an obvious error, AI chains often produce plausible-looking bad output. You don't see the failure until someone acts on it.
Executing without a human-in-the-loop checkpoint. The most common source of AI incidents is removing the human review step between Generate and Execute. Generate + Execute without human review means the AI is taking actions in the world based on its own outputs. For low-stakes workflows (formatting a calendar invite, updating a non-critical field), that's fine. For anything customer-facing or financially consequential, removing the human checkpoint is the decision most often regretted.
Mismatching capability to output type. Asking Predict to do what Analyze should do (trying to "predict" the meaning of a document, when what you need is to extract information from it). Or asking Generate to do what Predict should do (asking a language model to "predict" conversion probability, when what you actually need is a scoring model trained on historical outcomes). These mismatches produce systems that feel like they're working but are poorly suited to the job.
Handoff risk by capability transition
The most important risks sit at the handoffs, where one capability's output becomes another capability's assumption.

Not every step in the chain carries equal failure risk. Here's where errors tend to concentrate, based on production AI deployment postmortems.
| Handoff | Failure mode | Impact | Source |
|---|---|---|---|
| Ingest to Analyze | Poor transcription, missing fields, garbled OCR | All downstream steps work on wrong data | Google AI Engineering, 2024 |
| Analyze to Predict | Misclassification passes wrong features to scoring model | Scoring model produces plausible but incorrect scores | Gartner AI Ops, 2025 |
| Predict to Generate | Borderline predictions produce overconfident generated text | Confident-sounding wrong answers | Stanford HAI, 2024 |
| Generate to Execute | AI-approved draft fired without human review | Irreversible customer-facing or data errors | McKinsey, 2025 |
| Execute back to Ingest (loop) | Agent loops without exit condition | Runaway automation, duplicate records | Forrester AI Risk, 2025 |
How to read a vendor pitch using capability chaining
When a vendor says "AI that handles your support tickets," don't nod along. Ask which capabilities they cover.
- "How do you handle ticket ingestion? Do you support email, chat, and phone?"
- "What does your Analyze step do: classification, extraction, both? What accuracy on classification?"
- "Do you Predict anything, like escalation risk or routing priority, or is it rule-based routing?"
- "What does your Generate step produce: a draft response for the agent, or a complete response sent to the customer?"
- "Who controls Execute: does the AI send autonomously, or does a human approve each response?"
Each question exposes a different capability. The answers tell you: what does this product actually do, where does the human stay in the loop, and what happens when a step fails?
A vendor that can't map their product to these capability questions isn't hiding something sinister. They just haven't thought about it at this level. But you should, because you'll operate the system, not them.
Rework Analysis: Most AI implementation failures are chain failures, not model failures. When we review post-mortems from enterprise AI rollouts, the underlying model is rarely the problem. The problem is that one handoff in the capability chain was either skipped, poorly scoped, or not monitored. Teams that map their full Ingest-to-Execute chain before deployment, and specify what "good output" looks like at each step, catch the majority of failure points before they reach users. Treating each handoff as an explicit engineering checkpoint, rather than an implicit feature of the vendor's black box, is the single highest-leverage reliability investment an AI team can make.
Frequently Asked Questions
What is a capability chain in AI?
A capability chain is the sequence of ACE steps (Ingest, Analyze, Predict, Generate, Execute) that an AI pattern executes to solve a business problem. Each step's output becomes the next step's input. The chain's overall quality is limited by its weakest handoff, which is why understanding each transition is more valuable than knowing what model the vendor uses.
Why do most enterprise AI agents fail to scale?
McKinsey research finds that fewer than 10% of enterprises that experiment with AI agents scale them to tangible value, primarily because teams underestimate capability handoff complexity. The most common failure is assuming each capability step works correctly in isolation without testing how errors propagate downstream from one step to the next.
What is the most dangerous step in an AI capability chain?
Execute is the highest-risk step because it changes external state in ways that are often hard to reverse. McKinsey found that 80% of AI agent incidents trace back to Execute steps that fired without adequate upstream validation. Removing the human review step between Generate and Execute is the design decision most frequently identified in AI incident postmortems.
How does skipping Analyze affect AI output quality?
Skipping Analyze by connecting Ingest directly to Generate is the most common AI chain shortcut, and it produces hallucination: the model generates coherent-sounding responses not grounded in actual data. Enterprise AI systems that include an Analyze step reduce hallucination rates by up to 60% versus direct Ingest-to-Generate pipelines (Google DeepMind RAG benchmarks, 2024).
What is the Capability Stack Order Rule?
The Capability Stack Order Rule states that AI capabilities must execute in sequence: perception (Ingest) before comprehension (Analyze), comprehension before judgment (Predict), judgment before creation (Generate), creation before action (Execute). Skipping or reversing a step relocates the problem downstream where it is harder to detect, not simpler to handle.
How should I evaluate AI vendor claims using capability chains?
Ask each vendor to map their product to specific capability steps: What does your Ingest handle? What does your Analyze classify or extract? Do you use Predict or rule-based logic for routing? Does Generate produce drafts or send autonomously? Who controls Execute? Vendors that cannot answer these questions have not thought about their system at the level you will need to operate it.
Learn more
- What Is an AI Pattern? The Building Block of Business AI
- Why 10 Patterns Cover 90 Percent of Business AI Use Cases
- The Risk Gradient Across AI Patterns
- Hallucination Risk by AI Pattern
- The Generate vs. Execute Boundary: Why Guardrails Matter
- Stacking Patterns to Build AI Agents
- Pattern Dependencies and Prerequisites

Co-Founder, Rework.com
On this page
- The 5 capabilities: one paragraph each
- How capabilities chain into patterns
- The Capability Stack Order Rule
- Worked example 1: RAG Assistant (simple, 3 capabilities)
- Worked example 2: Meeting Intelligence (complex, 4 capabilities)
- Worked example 3: Autonomous Agent (looping, all 5 capabilities)
- Common mistakes when combining capabilities
- Handoff risk by capability transition
- How to read a vendor pitch using capability chaining
- Learn more