Generative Research: Compressing Hours of Reading

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A good analyst can synthesize 30 sources into a coherent brief. They know which sources to trust, which to weight lightly, how to surface the tension when two credible sources disagree, and how to make the output readable for a VP who has eight minutes before a board meeting.
Most teams can't afford enough analysts to do this well, consistently, across every market, account, and competitor they care about. The account research before a sales call gets skipped. The competitive intelligence report is three weeks stale when it's used. The due diligence on a potential acquisition target is shallow because no one had time to go deeper.
Generative Research is the AI pattern that compresses this synthesis work to minutes. Not by eliminating analysis, but by automating the reading, cross-referencing, and initial structuring that consumes most of an analyst's time. The analyst's judgment still matters at the end. But the analyst starts from a 10-page brief instead of from 30 browser tabs.
The pattern comes with a trust question that its sibling pattern, the RAG Assistant, doesn't have. RAG retrieves from a known, controlled knowledge base. Generative Research sweeps live, external, or cross-domain sources. That difference changes what verification looks like and where the failure modes cluster.
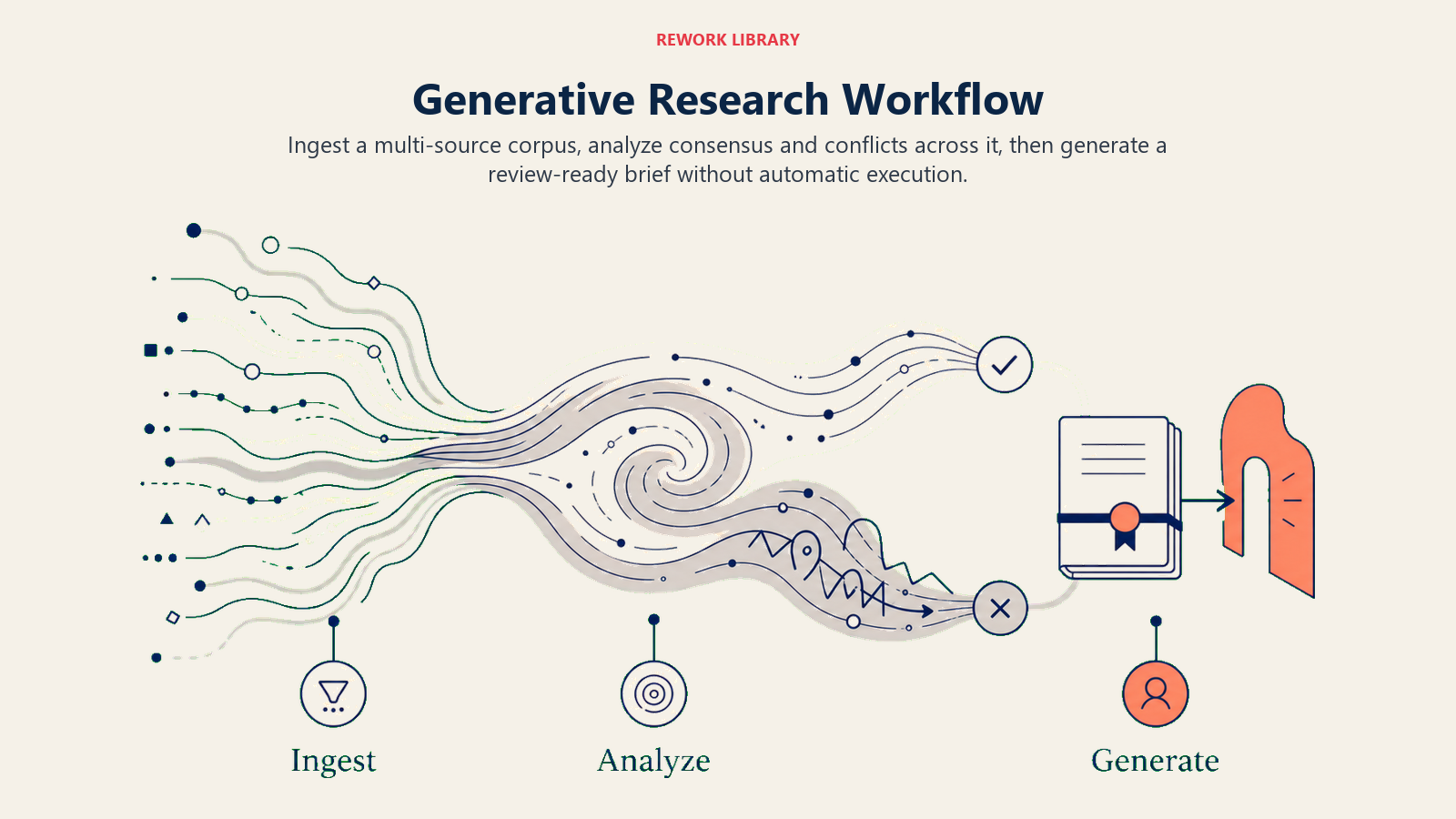
The formula: Ingest, Analyze, Generate
Ingest (multi-source corpus) pulls the raw source material. The sources depend on the use case. For competitive intelligence: press releases, G2 and Capterra reviews, LinkedIn job postings, conference recordings, earnings call transcripts, trade press articles. For account research: the target company's recent news, leadership LinkedIn profiles, industry analyst reports, recent funding announcements, competitor mentions. For executive trend synthesis: earnings call transcripts from 10-20 public companies in the sector, Gartner or Forrester excerpts, board-level news articles. The Ingest layer does the collection and initial normalization: converting PDFs, web pages, transcripts, and structured data into readable text chunks.
Analyze (synthesize) is the most demanding step in this pattern. The model doesn't just summarize each source independently. It reads across all sources simultaneously, identifies what multiple sources agree on (high-confidence signals), surfaces where sources conflict (areas of uncertainty), extracts named entities and key facts, and builds a coherent interpretation of what the evidence collectively says. This cross-source synthesis is where Generative Research differs from simple document summarization. Summarizing each source separately is not the pattern. The value is in the synthesis layer. See Analyze: how AI makes sense of what you've collected for the full capability definition.
Generate (report, brief, or structured output) produces the deliverable. This might be a competitive analysis formatted as a section-by-section brief with citations, an account research card formatted for a CRM insert, an executive memo with bullet points and a recommended action, or a market sizing table with source footnotes. The Generate step formats the synthesized insight into the output format the requester needs.
Note that this pattern ends at Generate. There is no Execute step in the base formula. The output is a draft for a human to review before it goes anywhere. For most Generative Research use cases, that human review is not optional. It's the governance mechanism that makes the pattern safe to distribute.
Key Facts: Generative Research Impact
- McKinsey estimates generative AI can automate 60-70% of employees' time currently spent on knowledge work activities, with research synthesis cited as one of the highest-value knowledge work activities it can compress (McKinsey, 2023)
- Sales reps complete pre-call research on 40-60% of calls without AI assistance; with AI-generated account briefs, pre-call research completion rates climb to 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- AI-powered competitive intelligence briefs synthesize 20-50 sources in 2-4 hours versus 6-8 hours per analyst per competitor using manual research, a 3-5x source coverage improvement at 85-90% time reduction (Gartner Competitive Intelligence Report, 2025)
The Multi-Source Synthesis Pattern
Generative Research's core value is not summarization of individual sources. It is cross-source synthesis: finding what multiple sources agree on (high-confidence signals), surfacing where sources conflict (areas of uncertainty), and inferring what the combined evidence implies beyond what any single source explicitly states. A Generative Research deployment that summarizes each source independently and presents the summaries side by side is not using this pattern. The pattern requires an Analyze step that reads all sources simultaneously and produces a unified interpretation. That synthesis layer is what compresses 30 sources into a coherent brief, and it's what separates Generative Research from a batch of summarizations stitched together.
Generative Research vs. RAG Assistant: the critical distinction
These two patterns are the most commonly confused in practice.

RAG Assistant retrieves answers from a controlled, known internal knowledge base. You know what's in the knowledge base (your product docs, past support tickets, HR policies). The retrieval is bounded. The answers cite sources that exist in your system. The failure mode is retrieving the wrong document or the knowledge base being stale. Not fabrication from the open web.
Generative Research synthesizes from a corpus that is often external, live, or cross-domain. The sources aren't pre-indexed in your system. They're pulled at query time from web searches, API feeds, uploaded documents, or third-party databases. The synthesis can surface information that no single source explicitly states: the model infers from the combination. That inference capability is both the value and the risk.
The practical implication: RAG outputs can be verified by checking the cited source. Generative Research outputs require spot-checking both the cited source (does the source actually say what's attributed?) and the synthesis logic (does the inference hold up?). Different verification process, different governance requirement.
Five real examples in depth
The examples below all depend on cross-source synthesis: the AI has to reconcile evidence, not simply summarize one document.

1. Competitive intelligence reporting
A VP of Product needs a quarterly competitive update on three direct competitors. Each competitor has a website, a G2 profile, an active LinkedIn, recent press releases, and a handful of review mentions on Reddit and Capterra. Manually reading and synthesizing all of that takes a product analyst 6-8 hours per competitor.
Ingest pulls from all these sources: web pages scraped at pull time, G2 reviews filtered by date, LinkedIn posts and job listings, press releases, and news mentions. Analyze cross-references the sources: what features are reviewers consistently mentioning in G2 reviews that aren't on the company's own website? What does the job posting for "Head of Enterprise Sales" signal about their strategic direction? Where do two sources disagree (one review calls the UX excellent; another flags it as a weakness)?
Generate produces a structured brief: product updates in the quarter, positioning shifts, pricing signals from reviews, talent signals from job listings, and key quotes from third-party sources. The output is formatted as a one-page summary with expandable sections for each source category.
Human review checks: do the cited quotes actually come from the cited sources? Do the inferred strategic conclusions hold up under scrutiny?
Tools that support this: Perplexity API, Tavily for web search grounding, Claude and GPT-4 with search tools, and purpose-built competitive intelligence platforms like Crayon, Klue, and Battlecards.
2. Account research briefing before a sales call
A sales director has a call in 90 minutes with a VP of Operations at a manufacturing company she hasn't spoken with before. She needs to know: what's happening at this company, what their recent challenges are, who the stakeholders are, and what the industry context is.
Ingest pulls: the company's recent press releases and news coverage (last 90 days), the prospect's LinkedIn profile and recent activity, the CEO and CFO's recent public comments, industry news from manufacturing trade outlets, and any existing CRM data and past email threads.
Analyze surfaces: a recent acquisition that changed their supply chain priorities, a LinkedIn post from the prospect mentioning operational complexity as a challenge, an earnings call quote from the CEO about "operational efficiency" as a 2026 priority, and a pattern in recent hires suggesting they're building out a data team.
Generate produces a two-page pre-call brief: key company context (2 bullets), recent developments (3 bullets), contact background (2 bullets), likely priorities based on evidence (3 bullets with sources), and suggested opening questions tied to the intelligence. The rep reviews in 8 minutes, adjusts the opening question based on her own knowledge, and uses the brief as context rather than as a script.
This pattern is built into Salesforce Einstein's "account summaries," HubSpot's AI research features, and is the core of purpose-built tools like Apollo.io's AI research and Warmly. For the full sales-specific version of this use case, see AI account research before first touch.
3. Executive industry-trend synthesis
A CFO at a healthcare technology company wants a 20-minute brief before a board meeting on "where AI is affecting healthcare revenue cycles." That synthesis normally requires reading 6-8 analyst reports, 3 earnings call transcripts from relevant public companies, and a dozen trade press articles.
Ingest pulls from Gartner excerpts (if available), HIMSS conference coverage, earnings call transcripts from health IT companies (Veeva, Epic partners, Waystar), trade press from Healthcare IT News and Health Data Management, and VC investment announcements in the space.
Analyze identifies the consensus themes (automation of claims adjudication is consistently flagged across 7 of 10 sources), the emerging debates (which AI vendors are actually delivering vs. promising), and the key companies being cited. It also checks for conflicting signals (one source projects 30% admin cost reduction; another analyst report calls that "optimistic").
Generate produces a two-page brief: three consensus trends with evidence, two areas of active disagreement flagged explicitly, five companies worth watching, and a "questions you'll likely face" section with suggested responses. The CFO can present this as informed commentary, not as AI-generated text.
4. Market sizing with cited sources
A startup's Head of Business Development needs a rough market sizing for a new segment before a fundraise meeting. The TAM/SAM/SOM analysis needs to be defensible: not a magic number, but a traceable estimate with sources a VC can check.
Ingest pulls: industry analyst reports, government statistical databases (BLS, Census), public company earnings calls mentioning the segment, and recent startup funding rounds in the space with their implied market assumptions.
Analyze cross-references the sizing estimates from multiple sources: one analyst says $12B TAM, a competitor's S-1 implies $9B, a Gartner report from 2024 said $8B growing at 14%. It identifies the methodological differences (one counts software only; another includes services). It surfaces the range of defensible estimates and the assumptions that drive each.
Generate produces a market sizing memo: methodology section, three scenarios (conservative/base/optimistic), source citations per number, and a one-paragraph "how to defend this" note for the fundraise meeting.
5. M&A due diligence desk research
An acquirer's strategy team needs a preliminary view on a target company before formal engagement. They want public-source intelligence only, before they've signed an NDA. This is desk research, not full diligence, but it needs to be thorough.
Ingest pulls: the target's website and product documentation, all public press coverage, LinkedIn data on employee count and growth trajectory (a proxy for financial performance), Glassdoor reviews for culture signals, Crunchbase for funding history and investor names, G2 for customer sentiment, and patent filings if relevant.
Analyze synthesizes: revenue range estimate from funding + growth signals, team quality and churn signals from LinkedIn and Glassdoor, product differentiation assessment from public materials and reviews, competitive positioning in the context of other acquisitions in the space.
Generate produces a due diligence memo in the format the strategy team uses: business overview, financial estimates with confidence levels, team assessment, product assessment, risk flags, and open questions for the formal diligence process.
Failure modes: what breaks Generative Research
| Failure mode | Root cause | Mitigation |
|---|---|---|
| Confabulation | Model fills gaps between real sources with plausible-sounding claims that no source actually supports | Require citations per claim. Spot-check 3-5 citations per brief before distributing. Never circulate without a named human reviewer who has checked the sources. |
| Source currency lag | Web search index is 2-3 days behind; internal doc synthesis is only as fresh as the last index run | Include crawl or index timestamps in the output. Flag time-sensitive claims with their source date. For live competitive or market intelligence, verify key claims directly. |
| Conflicting sources presented as unified | Model selects one interpretation when sources disagree, without flagging the disagreement | Prompt for explicit conflict surfacing: "If sources disagree on this topic, flag the disagreement and cite both sides." Treat any brief that presents everything as consensus with suspicion. |
| Citation laundering | Model cites a real, credible source for a claim that source doesn't actually make | Spot-check citations: not just that the source exists, but that the cited passage supports the attributed claim. This is the most insidious failure mode because it looks authoritative. |
| Scope drift | Open-ended prompts produce 40-page outputs that are comprehensive but unusable | Define the scope precisely: time range, source types, output format, and word limit. Narrower prompts produce more useful outputs than broad ones. |
| Single-source bias | One dominant, high-quality source overwhelms the synthesis; the output reflects one perspective, not a multi-source view | Check source distribution in the output. If 80% of citations point to one source, the synthesis is not doing its job. |
Citation laundering is the most insidious failure mode because it produces outputs that look authoritative. A brief that cites a real Gartner report for a claim that report doesn't actually make will pass a casual review and fail under scrutiny. Stanford HAI's 2024 evaluation of leading LLMs on citation accuracy found that 23% of automatically-generated citations in long-form synthesis tasks either cited a source that didn't contain the attributed claim or slightly misrepresented the source's position. This doesn't make Generative Research unusable. It makes the 15-minute human review non-negotiable.

Confabulation deserves direct attention because it's the failure mode that creates the most trust damage. A Generative Research brief that contains one confidently-cited claim that the cited source doesn't actually make will, when discovered, destroy trust in the entire brief and in the pattern more broadly. OpenAI's research on GPT-4 acknowledges this directly: even high-capability models can produce plausible-sounding but inaccurate content, which is why citation verification remains a human responsibility regardless of model quality. The mitigation is not to avoid the pattern. It's to build verification into the workflow before distribution. See hallucination risk by AI pattern for how this compares to failure modes in other Generate-heavy patterns.
The trust model: verification is not optional
The RAG Assistant pattern benefits from a relatively contained trust model. The knowledge base is yours. The sources are known. If an answer is wrong, the source is wrong, and you can fix the source.
Generative Research draws from external, live, and cross-domain sources. The synthesis can produce inferences no individual source explicitly supports. That's the value. But it's also why the trust model must be explicit.
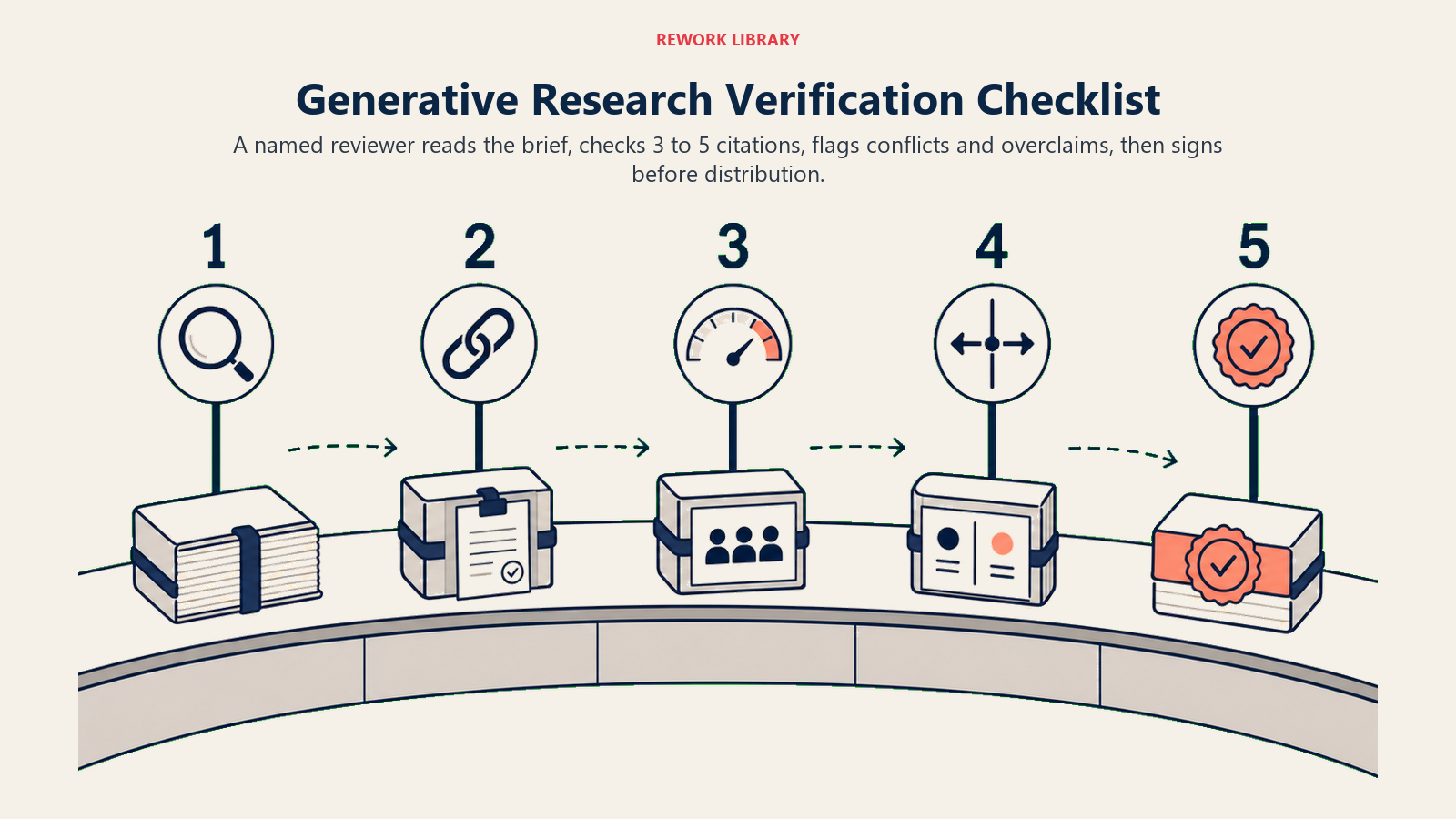
Before any Generative Research output is distributed, a named human reviewer should:
- Read the output as a full document, not just the summary
- Spot-check 3-5 citations, verifying that the source exists and that the attributed claim is actually in the source
- Flag any consensus claims that feel overstated given their evidence base
- Mark any section where sources were conflicted (if not already flagged by the AI)
- Add their name to the document as the reviewing analyst
This review takes 15-30 minutes for a well-formatted brief. It is not the same as the original 6-8 hour research job. That's the productivity gain. But the 15-minute review is not optional.
The common failure: teams deploy Generative Research and stop doing spot-checks after the first six months because outputs "seem fine." Then a brief with a fabricated statistic reaches a board presentation. The fix is making the spot-check a documented workflow step, not an optional review.
When Generative Research works (and when it doesn't)
Works well when:
- The question has a defined scope. "What did Competitor X announce in Q1 2026?" is scoped. "Tell me everything about Competitor X" is not.
- Sources are available and accessible. For public companies, market research, and competitive intelligence, public sources are usually rich. For private companies or emerging markets, source quality drops.
- The output will be reviewed before distribution. This isn't a trust issue about the technology. It's a workflow requirement for any research output that informs decisions.
- The need is for synthesis, not for a specific factual lookup. If you need "what is Acme Corp's ARR?", that's a factual lookup where a single authoritative source is better than synthesis. If you need "what can we infer about Acme Corp's growth trajectory from public signals?", that's synthesis.
vs. RAG Assistant: RAG is your internal knowledge base answering known questions. Generative Research is synthesis from external or cross-domain sources producing new insight. They're often used together: Generative Research to build intelligence briefs from external sources, RAG Assistant to answer "what have we learned about this account?" from past briefs and call notes.
vs. Document Review: Document Review takes a specific document and checks it against a known standard or template. Generative Research takes many documents and synthesizes a new output from them. The distinction: one document vs. many sources; compliance check vs. insight synthesis.
vs. Meeting Intelligence: Meeting Intelligence processes your own conversation recordings. Generative Research draws from external material. They can be paired: Meeting Intelligence captures your own customer conversations, Generative Research synthesizes external market context, and a strategist combines both for a full account view.
ROI signals: measuring the impact
| Metric | Manual baseline | With Generative Research | Typical improvement |
|---|---|---|---|
| Analyst hours per brief | 4-8 hours for a full competitive brief | 30-60 minutes (AI + review) | 85-90% time reduction |
| Time from request to deliverable | 1-3 days (backlog + writing time) | 2-4 hours (same-day turnaround) | 80-90% cycle time reduction |
| Source coverage per brief | 5-10 sources (practical limit for one analyst) | 20-50 sources (AI synthesis limit is broader) | 3-5x coverage improvement |
| Brief frequency | 1 comprehensive brief per month per topic | Weekly briefs become feasible | 4-6x cadence improvement |
| Pre-call research completion rate | 40-60% of sales calls have any pre-call research | 85-95% with automated account brief generation | 40-50% improvement |
The pre-call research completion rate is often the most tractable metric to track, and it connects directly to pipeline outcomes. When reps walk into calls with a brief, the call quality improves. McKinsey's research on AI in B2B sales finds that account research and pre-call preparation are among the highest-excitement AI use cases for sales leaders, precisely because the productivity gain is measurable and immediate. Not because the brief is perfect, but because having context shifts the opening from "tell me about your company" to "I saw you just opened a new office in Austin. Is that tied to the expansion push you mentioned on your earnings call?"
Rework Analysis: The Generative Research deployments that succeed have one thing in common: a named reviewer who owns the 15-minute spot-check before every brief is distributed. It's not the AI that makes a research brief trustworthy. It's the reviewer's name on the document. Teams that skip this step in favor of speed eventually circulate a brief with a fabricated statistic to a board, a client, or an investor. Once that happens, trust in the entire program collapses, not just in the specific brief. The reviewer's job is not to repeat the research. It's to verify 3-5 citations and flag any claim that feels overconfident given its evidence base. That takes 15-30 minutes for a 10-page brief. It converts a potentially dangerous output into a trustworthy deliverable. No other governance control delivers more ROI at lower cost.
Frequently Asked Questions
What is the Generative Research AI pattern?
Generative Research is an AI pattern that synthesizes multiple sources into a coherent research output. The formula is: Ingest (multi-source corpus), Analyze (cross-source synthesis identifying consensus signals, conflicts, and inferences), Generate (structured report, brief, or analysis). It differs from RAG Assistant in that it draws from external, live, or cross-domain sources rather than a controlled internal knowledge base, and it produces new inferences from the combination of sources.
What is the Multi-Source Synthesis Pattern?
The Multi-Source Synthesis Pattern is the defining capability of Generative Research: reading multiple sources simultaneously to find what they collectively agree on, surface where they conflict, and infer what the combined evidence implies beyond what any single source states. A deployment that summarizes each source independently is not using this pattern. The synthesis layer is what compresses 30 sources into a coherent brief and distinguishes Generative Research from a batch of document summaries stitched together.
How is Generative Research different from a RAG Assistant?
RAG Assistant retrieves answers from a controlled internal knowledge base you own. Generative Research synthesizes from external, live, or cross-domain sources at query time. The trust models are different: RAG outputs can be verified by checking the cited internal source. Generative Research outputs require verifying that the cited external source actually supports the attributed claim and that the synthesized inference holds up under scrutiny. The 15-minute human review before distribution is a governance requirement for Generative Research that is less critical for RAG.
What is citation laundering in AI research?
Citation laundering occurs when an AI model cites a real, credible source for a claim that source doesn't actually make. Stanford HAI's 2024 evaluation found 23% of AI-generated citations in long-form synthesis tasks either cited a source that didn't contain the attributed claim or misrepresented the source's position. This produces outputs that look authoritative and pass casual review but fail under scrutiny. The mitigation is spot-checking 3-5 citations per brief before distribution.
What ROI should you expect from Generative Research?
Analyst hours per competitive brief drop from 4-8 hours to 30-60 minutes (85-90% time reduction). Source coverage per brief improves from 5-10 sources to 20-50 sources (3-5x improvement). Pre-call research completion rates for sales reps climb from 40-60% to 85-95%. Briefing cadence improves 4-6x (weekly briefs become feasible where monthly was the previous limit). The pre-call research completion rate is the most trackable metric and connects directly to pipeline outcomes.
What are the most common Generative Research failure modes?
The six main failure modes are confabulation (plausible-sounding claims not supported by any source), citation laundering (real source cited for a claim the source doesn't make), source currency lag (index is days behind), conflicting sources presented as unified consensus, scope drift (too broad a prompt producing an unusable output), and single-source bias (one dominant source overwhelming the synthesis). Citation laundering is the most insidious because it looks authoritative. Confabulation is the most damaging to trust when discovered.
Learn more

Co-Founder, Rework.com
On this page
- The formula: Ingest, Analyze, Generate
- The Multi-Source Synthesis Pattern
- Generative Research vs. RAG Assistant: the critical distinction
- Five real examples in depth
- 1. Competitive intelligence reporting
- 2. Account research briefing before a sales call
- 3. Executive industry-trend synthesis
- 4. Market sizing with cited sources
- 5. M&A due diligence desk research
- Failure modes: what breaks Generative Research
- The trust model: verification is not optional
- When Generative Research works (and when it doesn't)
- ROI signals: measuring the impact
- Learn more