AI Agentを構築するためのパターン・スタッキング
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
単一のパターンは1つのことをうまくこなします。
Meeting Intelligenceは通話録音を構造化されたメモとアクションアイテムに変換します。Scoring and RoutingはインバウンドのLeadを分類し、適切な担当者に割り当てます。Workflow CopilotはCRMのサイドバーに次に取るべきアクションを表示します。これらはいずれも、実際に導入可能な機能です。
しかし、そのどれも単独では、AI Sales Operatorにはなれません。
AI Sales Operatorは商談の電話に同席し、CRMを更新し、アカウントを調査し、フォローアップのメッセージを下書きし、ディールの健全性を監視し、担当者が翌朝レコードを開いたときに次のアクションを表示します。単一のタスクではなく、職務全体を担います。
単一パターンとロール全体を担うAgentの違いはスタッキングにあります。本記事では、この概念を解説し、2つの完全な実例を紹介したうえで、スタックが失敗するポイントとそれを防ぐ設計方法を説明します。
スタッキングの概念
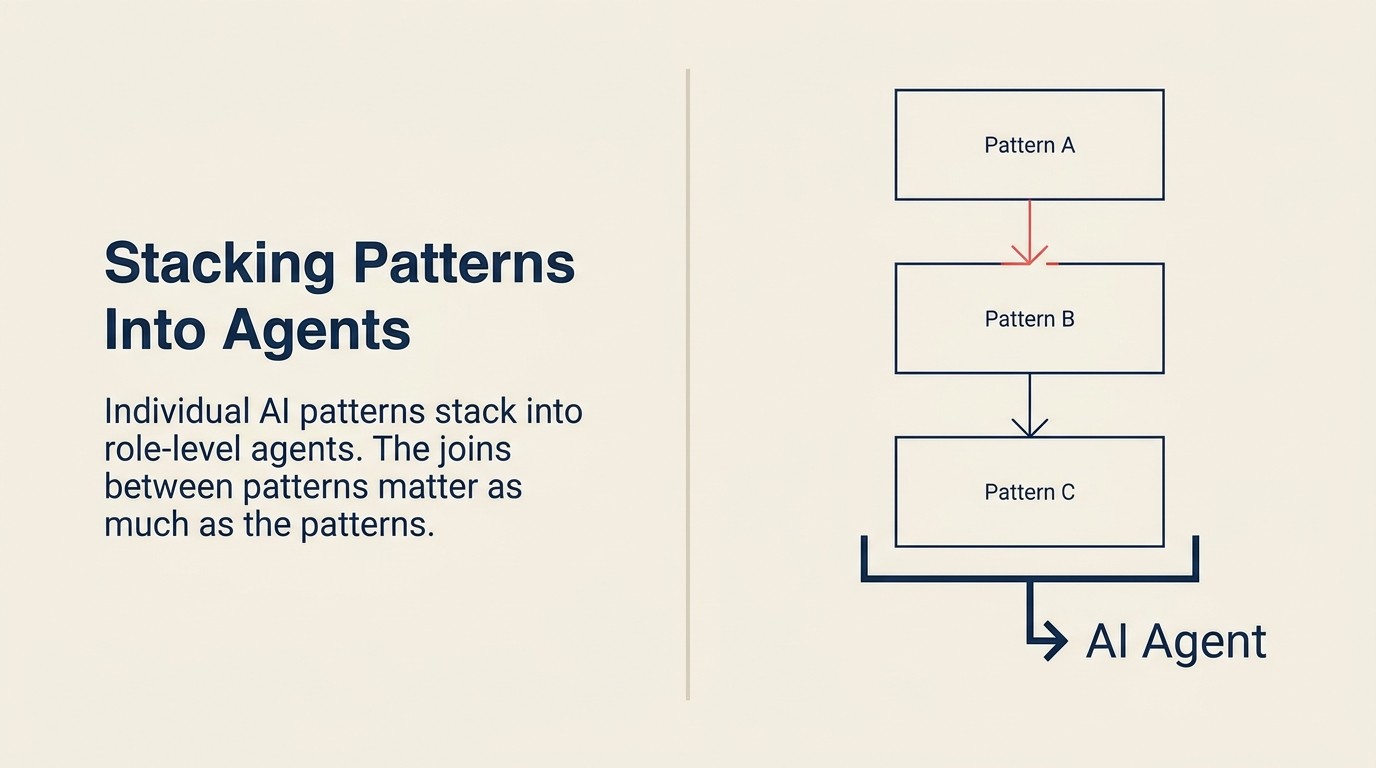
パターンのアウトプットが次のパターンのインプットになるとき、パターンはビルディングブロックへと変わります。
Key Facts: 本番環境でのAI Agentスタッキング
- Deloitteの2025年新興テクノロジートレンド調査によると、AI Agentのパイロットを実施した企業のうち、本番環境で稼働させているのはわずか11%です。ボトルネックはモデルの能力ではなく、ほぼ常に統合とガバナンスにあります。
- Gartnerの予測では、2027年末までにエージェンティックAIプロジェクトの40%以上がコストの増大、ビジネス価値の不明確さ、リスク管理の不備を理由にキャンセルされるとされています。
- 本番稼働中のAgent実装の66%が、単一AgentではなくマルチAgentシステムを採用しています。これは、単一パターンでは職務全体をこなせないという業界全体の認識を反映しています。(Landbase, 2026)
AnthropicのBuilding Effective Agentsガイドは、数十の本番デプロイメントから導き出された知見として、最も高性能なエージェンティックシステムは単一の高度なモデルで構築されるのではなく、明確に定義されたシーケンスで単純なパターンを組み合わせることで構築されると明示しています。各レイヤーは次のレイヤーへ構造化されたアウトプットを渡します。
スタッキングは、単なる機能の組み合わせではなく、アーキテクチャレベルの構成です。Meeting Intelligenceのアウトプット(構造化されたメモ、アクションアイテム、センチメント、主要な反論)は、次のアクション提案のコンテキストとしてWorkflow Copilotに流れます。Workflow CopilotによるCRM更新はディールレコードを変更し、そのレコードをScoring and Routingが使って担当者のPipelineを再優先付けします。各パターンは業務サイクルをさらに前進させます。
設計上の重要な洞察は、スタッキングの失敗はほとんどがパターン自体ではなく、パターン同士のつなぎ目で発生するということです。
Meeting Intelligenceがフリーテキストのサマリーを生成し、Workflow Copilotが特定フィールドを持つ構造化JSONオブジェクトを期待している場合、データは流れません。遅延バジェットが各パターン200ミリ秒の応答を想定しているのに、Autonomous Agentのステップに8秒かかる場合、スタック全体がユーザーエクスペリエンスの要件に違反します。パターン2でエラーが発生してもサイレントにパターン3に渡ると、後続のパターンは破損したインプットから最適化されていることに気づきません。
優れたスタッキング設計とは、パターン自体と同じくらい丁寧につなぎ目を設計することです。
「各レイヤーが処理前にインプットを検証するマルチAgentの実装では、アウトプットをそのまま下流に流すスタックと比べてエラー伝播率が3倍低くなります。つなぎ目こそがアーキテクチャです。」(Shakudo Enterprise AI Production Report, 2026)
では、パターンが組み合わさってフルAgentになると何が変わるのでしょうか。次のセクションで違いを説明します。
レベル2とレベル3の違い
ACE Frameworkは、3つの次元でレベル2のパターンとレベル3のAI Agentを区別しています。
スコープ: レベル2のパターンは特定の限定されたタスクを解決します。レベル3のAgentは1つのロールを担います。AI Sales Operatorは担当者のWorkflowを担当します。AI Support Agentはサポートキューを担当します。Agentのスコープは、その職務内の個別タスクではなく、職務機能全体に及びます。
データ権限: レベル3のAgentはドメインに関する永続的な状態を保持します。AI Sales Operatorはディールの全履歴、担当者のパフォーマンスパターン、どのアウトリーチテンプレートがどの業界セグメントで効果的だったかを把握しています。この知識は実行を重ねるごとに蓄積され、後続の実行に反映されます。レベル2の個別パターンはステートレスです。インプットを受け取り、アウトプットを生成しますが、コンテキストを蓄積しません。
ガバナンスの対象範囲: レベル2のパターンは権限が限定されています。その特定の能力の範囲内でのみ動作します。レベル3のAgentは複数の能力と複数のシステムにまたがる統合された権限を持ちます。そのため、ガバナンス要件は比例して複雑になります。各パターンに適用される承認ゲート、監査証跡、スコープ制約がレベル3のレイヤーで乗算されます。
レベル2からレベル3への移行は、単にパターンを追加するだけではありません。
システムにロールの所有権を与え、その所有権に必要なデータインフラとガバナンスアーキテクチャを構築するという設計上の意思決定です。McKinseyのエージェンティックAI活用に関する調査でも同じ見解が示されています。Agentを試験導入した企業のうちスケールに成功するのは10%未満であり、そのギャップはほぼ常にインフラとガバナンスにあり、モデルの能力ではありません。
「レベル3のAgent導入をロールの所有権の決定としてではなく、単なる機能追加として扱う企業は、ガバナンスとデータインフラを先にスコープする企業と比べて、2年目のプロジェクトキャンセル率が4倍高くなります。」(McKinsey QuantumBlack, 2025)
以下の2つの実例では、そのインフラが実際にどのようなものかを具体的に示します。
実例1: AI Sales Operator
AI Sales Operatorは5つのパターンを積み重ねています。Meeting Intelligence、RAG Assistant(Retrieval-Augmented Generation)、Scoring and Routing、Workflow Copilot、そしてAnomaly Agentです。各レイヤーの役割とデータの受け渡し方法を説明します。
レイヤー1: Meeting Intelligence
- 役割: 通話録音を受け取り、文字起こし、アクションアイテム、主要な反論、ディールシグナルを抽出します。
- このコンテキストでの機能: すべての商談電話が自動的にMeeting Intelligenceを経由します。アウトプットは、文字起こし、アクションアイテム、センチメント分析、ACEカテゴリでタグ付けされた反論を含む構造化レコードです。
- 次のレイヤーへのアウトプット: ディールステージ、提起された反論、コミットされた次のステップ、見込み客の希望タイムライン、担当者名などの主要フィールドを含む構造化された通話サマリー。
レイヤー2: Workflow Copilot
- 役割: 通話サマリーと既存のCRMコンテキストを受け取り、担当者に最適な次のアクションを生成します。
- このコンテキストでの機能: 通話終了直後、担当者がCRMレコードを開くと、フォローアップメールの下書き、更新されたステージの推奨、通話からのアクションチェックリストが表示されます。
- レイヤー1からのインプット: 構造化された通話サマリー。Workflow CopilotはRAW音声やRAWトランスクリプトを処理できません。Meeting Intelligenceのアウトプットは、Copilotが使用できるよう正しく構造化されている必要があります。
- 次のレイヤーへのアウトプット: 担当者がアクションを確認・承認します。CRMレコードが新しいステージ、メモ、次のタスクで更新されます。
レイヤー3: Scoring and Routing
- 役割: 更新されたシグナルに基づいてディールを再スコアリングし、担当者のPipelineを再優先付けします。
- このコンテキストでの機能: CRM更新のたびに、スコアリングモデルがディールスコアを再計算します(直近の状況、エンゲージメントシグナル、ステージ、企業データを組み合わせます)。担当者のPipelineビューが自動的に並び替えられます。
- レイヤー2からのインプット: 更新されたCRMレコードフィールド。具体的にはステージ更新とアクション完了シグナルです。
- 次のレイヤーへのアウトプット: 担当者のPipelineビューの更新された優先順位ランキング。優先度の高いディールが上部に表示されます。
レイヤー4: RAG Assistant
- 役割: 担当者のアクティブなコンテキストに基づいて、関連する製品ドキュメント、事例、反論対応Playbookを提示します。
- このコンテキストでの機能: 担当者がディールに「コンプライアンス上の反論あり」フラグがある場合、RAG Assistantは規制業界から最も関連性の高い3つの事例と標準的なコンプライアンス反論Playbookを表示します。
- インプット: ディールレコードのコンテキスト。具体的にはMeeting Intelligenceからの反論タグとCRM企業データの業界セグメントです。
- アウトプット: 担当者がディールに取り組んでいるときにCRMサイドバーに表示されるリンク付きドキュメントのスニペット。
レイヤー5: Anomaly Agent
- 役割: 時間の経過とともにディールの健全性を監視し、異常なパターンをフラグします。
- このコンテキストでの機能: 10日前に85%の確度だったディールが12日間エンゲージメントなしの場合、Anomaly Agentはそれを「リスクのあるディール」としてフラグし、Workflow Copilotの再エンゲージメント提案をトリガーします。
- インプット: 過去のエンゲージメントシグナル、Pipeline全体のディールステージ進行率。
- アウトプット: 担当者とマネージャーに表示されるアラートと推奨される回復アクション。
この5レイヤーのスタックが、AI Sales Operatorを単なる機能ではなくロールのように感じさせる理由です。個別のパターンを単独でデプロイしても、このエクスペリエンスは生まれません。統合こそが製品です。このスタックを構築する価値を示すROIのケースについては、なぜSales OpsがAIのROIで最も高いユースケースなのかで数字を詳しく解説しています。
AI Sales Operatorが担当者の1日全体を通じて何を行うかについての詳細は、AI Sales Operatorとはをご覧ください。
実例2: AI Support Agent
AI Support Agentは5つのパターンを異なる方法で積み重ねています。Scoring and Routing、RAG Assistant、Document Review、Workflow Copilot、そしてAutonomous Agentです。サポートのユースケースは構造が異なるため、データの受け渡し方法も異なります。
レイヤー1: Scoring and Routing
- 役割: 受信するすべてのチケットを受け取り、タイプ(請求の紛争、技術的な問題、機能リクエスト、エスカレーション)で分類し、緊急度をスコアリングし、適切なキューにルーティングします。
- このコンテキストでの機能: 緊急度の高い請求の紛争はAutonomous Agentのパスに流れます。複雑さのしきい値を超える技術的な問題はシニアAgentにルーティングされます。緊急度の低い標準的なリクエストはRAGが支援するセルフサービスのパスに流れます。
- 次のレイヤーへのアウトプット: 分類タグ、緊急度スコア、ルーティング判定が付いたチケット。
レイヤー2: RAG Assistant (Tier 2以上で人間が担当するチケット)
- 役割: 人間のAgentが処理するチケットについて、RAG Assistantがナレッジベースから最も関連性の高い過去の解決策を3件表示します。
- このコンテキストでの機能: 人間のAgentはチケットを見ると同時に、同じ画面で類似スコアと具体的な解決手順が付いた上位3件の解決策の提案を確認できます。
- インプット: Scoring and Routingからのチケットテキストと分類タグ。
- アウトプット: 人間のAgentにコンテキストとして表示される解決策の候補。
レイヤー3: Workflow Copilot (複雑なチケットを担当する人間のAgent向け)
- 役割: 人間のAgentがチケットに取り組んでいる間、Copilotは次の応答の下書き、適用すべき正しいマクロ、クローズ前に入力すべき不足フィールドを提案します。
- このコンテキストでの機能: 人間のAgentが応答を入力すると、Copilotはチケットのコンテキストとレイヤー2から取得したRAGの解決パターンに基づいて事前に下書きされたバージョンを表示します。
- インプット: アクティブなチケットのコンテキスト、人間のAgentの現在のカーソル位置、レイヤー2のRAGアウトプット。
- アウトプット: 人間のAgentへの応答の下書きとチェックリスト。
レイヤー4: Document Review (規制産業向け)
- 役割: 送信前に下書きの応答をレビューし、コンプライアンス要件(FINRAの言語、HIPAAの開示事項、必須の免責事項)を確認します。
- このコンテキストでの機能: 金融サービスおよびヘルスケアの顧客については、すべての応答の下書きが提出前にDocument Reviewを通過する必要があります。
- インプット: Workflow Copilotからの応答の下書き。
- アウトプット: 承認/フラグのステータス。フラグが立てられた項目はハイライトされ、修正された言語が提案されます。
レイヤー5: Autonomous Agent (Tier 1の定型的な解決向け)
- 役割: Scoring and RoutingがTier 1と判定した、人間の関与なしに解決可能なチケット(しきい値以下の請求の紛争、標準的な返金リクエスト、パスワードリセットの手続き)を処理します。
- このコンテキストでの機能: Autonomous Agentは決済API、チケットシステム、メール送信機能にアクセスできます。チケットを読み取り、請求を確認し、解決策を実行し、チケットをクローズして確認メールを送信します。
- インプット: 分類タグと承認された解決スコープを持つ構造化チケット。
- アウトプット: 解決ログと顧客への確認メールを含むクローズされたチケット。
このスタックは重要な設計パターンを示しています。すべてのチケットがすべてのレイヤーを通過するわけではありません。レイヤー1のScoring and Routingの判定が、特定のチケットがどの後続レイヤーを通過するかを決定します。Autonomous Agentは特定の限定されたサブセットを処理し、残りは人間が支援するレイヤーが処理します。
4パターンアセンブリフレームワーク
4パターンアセンブリは、正確に4つのパターンレイヤーからロールレベルのAI Agentを構築するための名前付きアーキテクチャです。(1) RAWインプットを構造化するIngest/Classifyレイヤー、(2) コンテキストで情報を補完するRetrieve/Scoreレイヤー、(3) 人間向けのアウトプットを生成するGenerate/Recommendレイヤー、(4) 承認に基づいてアクションを実行し変化を監視するExecute/Monitorレイヤーです。職務全体を担うAgentはすべて、これら4つのポジションにマッピングできます。4レイヤー未満のパターンはタスクを処理し、4レイヤー以上のパターンはロールを処理します。
Rework分析: 本記事の2つの実例とMcKinsey、Gartner、Anthropicが記録した本番パターンに基づくと、4パターンアセンブリの閾値(Ingest、Retrieve、Generate、Execute)に達したAgentは、4レイヤー未満のスタックと比較して一貫して高い採用継続率を示しています。Reworkの実装データによると、フル4レイヤーのAI Sales Operatorを使用している営業チームは、単一パターンのCopilotのみを使用するチームの1日15〜20分と比較して、1日あたり担当者1人あたり平均60〜70分のディールサイクルの事務作業時間を削減しています。
スタックが失敗するポイント
パターン間のデータ形式の不一致。 パターンAがフリーテキストのサマリーを生成し、パターンBが構造化JSONオブジェクトを期待している場合、データは流れません。原因はどちらのパターンにもありません。どちらのレイヤーを構築する前に、ハンドオフのスキーマを設計することが解決策です。ハンドオフコントラクトはアーキテクチャで最も重要な要素です。
遅延の累積。 各パターンが2秒かかる5パターンのスタックは、ユーザーに何かが表示されるまでに10秒かかります。McKinseyの分析では、単一モデルからマルチAgentデプロイメントに移行する際に、遅延の累積が最も過小評価されている課題の一つとして挙げられています。ユーザーがアクティブに待機しているCopilotのコンテキストでは、10秒は長すぎます。バックグラウンドの非同期プロセス(通話後のCRM更新)では10秒は許容範囲内です。スタックの深さを決定する前に、遅延バジェットをユーザーエクスペリエンスの要件と照らし合わせてください。
エラーの伝播。 パターン2の誤ったアウトプットがパターン3のインプットになります。パターン3がインプットを検証しない場合、破損したデータから最適化され、パターン4に流れる誤ったアウトプットを生成します。エラーが表面化するころには、それは増幅されています。解決策は最初のエントリポイントだけでなく、各レイヤーでのインプット検証です。各パターンは処理を進めようとするのではなく、不正形式または低信頼度のインプットを拒否する必要があります。
つなぎ目のガバナンスギャップ。 ガバナンスポリシーは各パターンの個別のExecuteアクションをカバーするかもしれません。しかし、Meeting IntelligenceからWorkflow Copilotへのデータフローは誰が承認したのでしょうか。Scoring and Routingの再優先付けが、通話からのAI生成のアクションアイテムに基づいて自動的に行われることを誰が承認したのでしょうか。パターン間のつなぎ目は、個々のパターンのポリシーがカバーしないガバナンスの対象範囲を生み出します。パターンレベルだけでなく、つなぎ目のガバナンスを設計してください。ACE Frameworkのgenerate vs. executeの境界がこの議論を始める最も明確な出発点です。
| 失敗のパターン | 一般的に表面化する場所 | 対策 |
|---|---|---|
| データ形式の不一致 | パターン間の最初のハンドオフ | 構築前にハンドオフスキーマを定義し、各レイヤーで検証する |
| 遅延バジェットの超過 | フルスタックの組み立て後 | 各パターンを独立してベンチマーク測定し、デプロイ前に合計遅延をモデル化する |
| エラーの伝播 | 最初の誤ったアウトプットの下流 | 各レイヤーでのインプット検証。低信頼度のインプットはサイレントに渡すのではなくエスカレートする |
| つなぎ目のガバナンスギャップ | 承認と監査の設計フェーズ | 各パターンのアウトプットだけでなく、各データフローのガバナンス要件をマッピングする |
| 共有エンティティモデルのずれ | パターンが同じ「コンタクト」や「ディール」を異なる方法で参照する場合 | すべてのパターンで共有される単一エンティティモデル。データレイヤーで強制する |
パターンスタックの設計原則
モジュール性。 各パターンはスタック全体を再構築することなく交換可能であるべきです。アウトプットスキーマが一貫している限り、Meeting IntelligenceレイヤーをWorkflow CopilotやScoring and Routingのレイヤーを変更することなく、より優れたモデルにアップグレードできます。各レイヤーは、密結合したコンポーネントとしてではなく、定義されたインプットとアウトプットを持つコントラクトとして扱ってください。
可観測性。 パターン間のすべてのハンドオフはログに記録されるべきです。最終的なアウトプットだけでなく、フルデータフロー全体を記録します。パターンがインプットとして受け取ったもの、生成したもの、次のレイヤーに送ったもの、そしてその時刻です。つなぎ目での可観測性は、何かがうまくいかない場合にスタックをデバッグする唯一の方法です。最終的なアウトプットのみをログに記録しても、最終結果は分かりますが、エラーがどこで発生したかは分かりません。
グレースフルデグレード。 Anomaly Agentが利用できない場合(モデルタイムアウト、APIの障害)、スタックの残りの部分は引き続き動作するべきです。担当者のWorkflow Copilotは次のアクションを引き続き表示するべきです。Meeting IntelligenceはCRMを引き続き更新するべきです。アラートが一時的に停止していることを示す表示とともに、異常監視の画面のみが非表示になるべきです。各レイヤーの失敗モードを明示的に設計してください。利用できないレイヤーはスタックをクラッシュさせるエラーではなく、失敗フラグを持つnullアウトプットを生成するべきです。
| スタックの深さ | 典型的なユースケース | 平均遅延(同期) | エラー伝播リスク | ガバナンスの複雑さ |
|---|---|---|---|---|
| 1パターン | 単一タスク(文字起こし、ルーティング、下書き) | 2秒未満 | 低 | シンプル |
| 2〜3パターン | タスククラスター(通話+CRM更新) | 3〜6秒 | 中 | 中程度 |
| 4〜5パターン(ロールレベル) | 職務機能の完全な所有(AI Sales Operator) | 6〜15秒(非同期OK) | 検証なしでは高 | 複雑 |
| 6パターン以上 | クロスファンクションのオーケストレーション | 非同期のみ | 非常に高 | 専用ガバナンスレイヤーが必要 |
「エンタープライズAI Agentデプロイメントの平均Time-to-Valueは5.1ヶ月で、営業開発Agentは3.4ヶ月で元が取れます。財務・運用Agentの平均は8.9ヶ月です。主な変数はモデルの選択ではなく、スタックの深さとデータの準備状況です。」(Landbase Agentic AI Report, 2026)
スタッキング前の前提条件
マルチパターンスタックを構築する前に、3つのインフラ条件を整える必要があります。
共有データパイプライン。 スタック内のすべてのパターンは、一貫したスキーマを持つ同じデータストアにアクセスする必要があります。Meeting Intelligenceがあるデータベースに書き込み、Scoring and Routingが別のデータベースから読み取る場合、スタックはサイロ化します。データパイプラインが結合組織の役割を果たします。
共有エンティティモデル。 すべてのパターンが同じ「コンタクト」「ディール」「チケット」、またはその他の中心的なエンティティの定義を参照する必要があります。Meeting Intelligenceがコンタクトをメールアドレスで識別し、Scoring and RoutingがCRMレコードIDで識別する場合、コンタクトが一方のシステムに存在して他方に存在しない瞬間にその結合は壊れます。
定義された遅延バジェット。 スタックを組み立てる前に、構築しているユーザーエクスペリエンスに対して許容できる応答時間を把握してください。Copilotのインタラクションは同期的であり、厳しい遅延要件があります(2秒未満)。バックグラウンド処理(通話後のCRM更新)は30〜60秒を許容できます。スタックの深さはバジェットに収まる必要があります。
レベル3への道
本記事の実例は、ACE Frameworkがレベル3と呼ぶもの、つまりロールレベルのAI Agentの出発点です。AI Sales OperatorとAI Support Agentはどちらもレベル3の構成体であり、適切なデータインフラとガバナンスアーキテクチャを持つレベル2のパターンをスタッキングすることで構築されています。
レベル2からレベル3への移行は、「タスクを行うAI」から「職務機能を担うAI」への移行です。この移行には、上述したインフラと設計上の規律が必要です。スタックにパターンをもう1つ追加するだけで越えられる閾値ではありません。
スタックに参加する前に慎重な前提条件が必要なパターンについては、パターンの依存関係と前提条件をご覧ください。部門別のスタックの機能については、部門別パターンの組み合わせをご覧ください。
よくある質問
AIパターンを「スタックする」とはどういう意味ですか?
スタッキングとは、一方のアウトプットが次のインプットになるよう個別のAIパターンを連鎖させることです。単一のパターンは1つの限定されたタスクを処理します。スタックは、通話に同席すること、CRMを更新すること、翌朝までに担当者の次のアクションを表示することなど、組み合わさって完全なロールを構成する一連のタスクを処理します。
ロールレベルのAI Agentを構築するには何個のパターンが必要ですか?
4パターンアセンブリフレームワークでは、最小限のロールレベルAgentを4つのレイヤーと定義しています。Ingest/Classify、Retrieve/Score、Generate/Recommend、Execute/Monitorです。4レイヤー未満のスタックはタスクのクラスターを処理しますが、完全なロールは処理しません。本記事のAI Sales OperatorとAI Support Agentの両方の例は、4〜5レイヤーの閾値で動作しています。
パターンスタックで最もよくある失敗ポイントは何ですか?
パターン間のハンドオフでのデータ形式の不一致が、初期段階の失敗の大部分の原因です。パターンAはフリーテキストを生成し、パターンBは構造化JSONを期待します。データは流れません。解決策は、どちらのレイヤーを構築する前にハンドオフスキーマを定義し、そのつなぎ目のコントラクトを第一級のアーキテクチャ上の成果物として扱うことです。
なぜエンタープライズのAI Agentを本番環境にスケールすることに成功する企業が少ないのですか?
Deloitteの2025年データによると、AI Agentをパイロット導入した企業のうち、本番環境で稼働させているのはわずか11%です。ボトルネックはモデルの能力ではありません。統合の複雑さ(各パターンが読み書きするすべてのシステムへのコネクタが必要)、パターン間のつなぎ目のガバナンスギャップ、スタック全体で共有エンティティモデルが存在しないことが原因です。
ACE FrameworkにおけるレベルのパターンとレベルのAI Agentの違いは何ですか?
レベル2のパターンはステートレスで範囲が限定されています。インプットを受け取り、アウトプットを生成しますが、永続的なコンテキストを持ちません。レベル3のAI Agentはロールを担います。ドメインに関する永続的な状態を保持し、実行を重ねるごとに制度的知識を蓄積し、複数のシステムにまたがる統合された権限を持ちます。レベル2からレベル3への移行には、追加のパターンだけでなく、データインフラとガバナンス設計が必要です。
マルチパターンスタックでの遅延はどのように対処しますか?
構築前に遅延バジェットをマッピングしてください。同期Copilotのインタラクションには合計2秒未満が必要です。各ステップに2秒かかる5パターンのスタックはそのバジェットを8秒超えます。解決策は、パターンの深さを減らすか、独立したレイヤーを並列化するか、または遅延の許容範囲が30〜60秒の非同期バックグラウンド処理にインタラクションモデルをシフトすることです。
パターンをスタックすると、ガバナンス要件はどのように変わりますか?
個々のパターンには限定されたガバナンスがあります。それぞれの特定の能力の範囲内でアクションを取ることができます。スタックはすべてのつなぎ目でガバナンスの対象範囲を生み出します。データはパターン間を流れ、権限は累積し、監査要件は倍増します。ACE Frameworkのgenerate vs. executeの境界は実践的な出発点です。システムが外部システムでアクションを取るスタック内のすべてのポイントを特定し、それらのポイントに明示的な承認ゲートを設計してください。
関連記事

Co-Founder, Rework.com