Menggabungkan Pola-Pola untuk Membangun AI Agent
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Satu pola melakukan satu hal dengan baik.
Meeting Intelligence mengubah rekaman panggilan menjadi catatan terstruktur dan daftar tindak lanjut. Scoring and Routing mengklasifikasikan inbound lead dan menugaskannya ke sales rep yang tepat. Workflow Copilot menampilkan next-best action di sidebar CRM. Masing-masing merupakan kemampuan nyata yang dapat diterapkan.
Namun tidak ada satupun yang, sendiri, menjadi AI Sales Operator.
AI Sales Operator menghadiri panggilan. Ia memperbarui CRM, meneliti akun, menyusun tindak lanjut, memantau kesehatan deal, dan menampilkan tindakan berikutnya ketika sales rep membuka data tersebut keesokan paginya. Ia menangani seluruh pekerjaan, bukan satu tugas saja.
Perbedaan antara satu pola dengan agent yang menangani sebuah peran adalah penggabungan (stacking). Artikel ini menjelaskan konsep tersebut, mengerjakan dua contoh lengkap, dan membahas di mana stack bisa gagal serta cara merancangnya agar tidak terjadi.
Konsep penggabungan pola
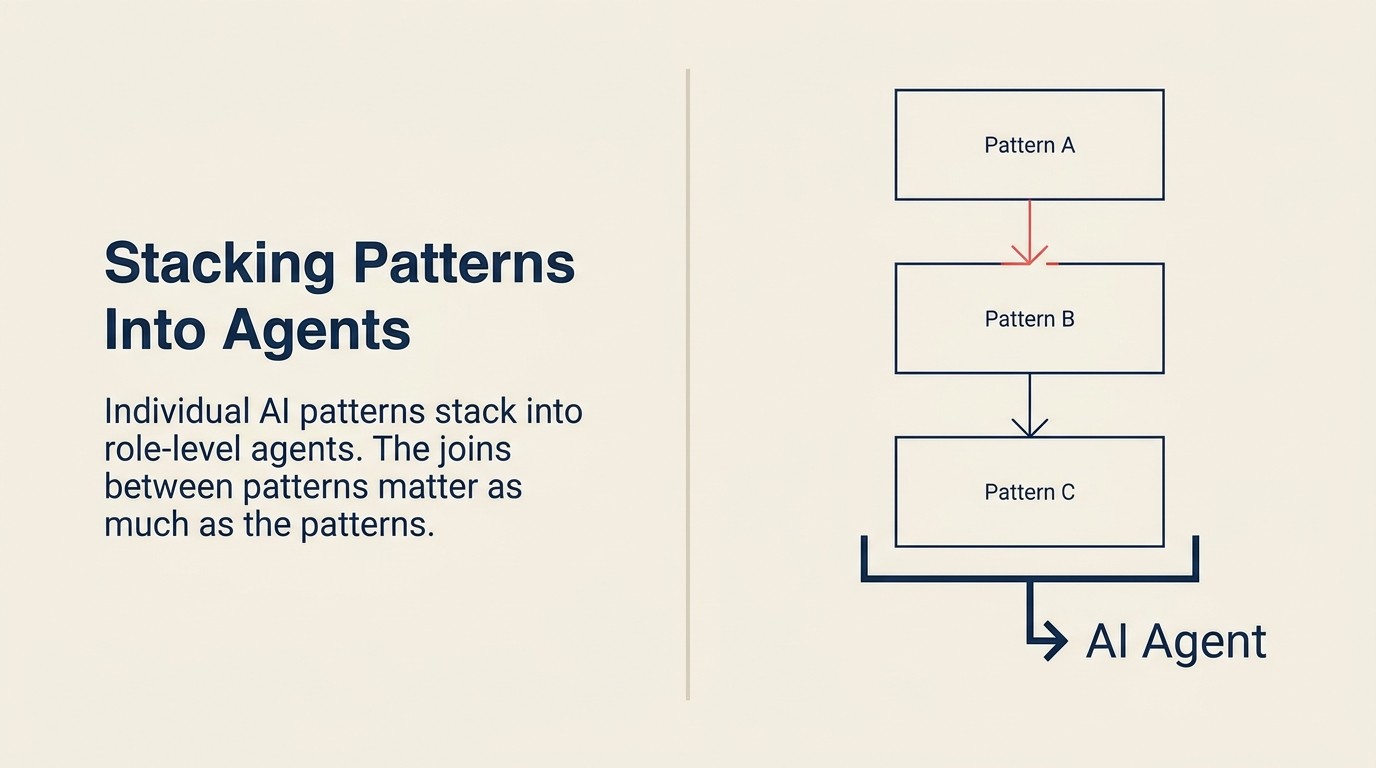
Pola-pola menjadi blok bangunan ketika output dari satu pola menjadi input bagi pola berikutnya.
Key Facts: Penggabungan AI Agent dalam Produksi
- Hanya 11% perusahaan besar yang melakukan pilot AI agent yang berhasil menjalankannya dalam produksi, menurut studi Emerging Technology Trends 2025 dari Deloitte. Hambatannya hampir selalu pada integrasi dan governance, bukan pada kemampuan model.
- Gartner memprediksi lebih dari 40% proyek agentic AI akan dibatalkan pada akhir 2027, dengan alasan biaya yang terus meningkat, nilai bisnis yang tidak jelas, dan kontrol risiko yang tidak memadai.
- 66% implementasi AI agent dalam produksi kini menggunakan desain sistem multi-agent, bukan pendekatan single-agent, mencerminkan pengakuan industri bahwa tidak ada satu pola pun yang menangani peran penuh. (Landbase, 2026)
Panduan Anthropic Building Effective Agents, yang diambil dari lusinan deployment produksi, menyatakan hal ini secara eksplisit: sistem agentic paling powerful tidak dibangun dengan satu model yang canggih, melainkan dengan menggabungkan pola-pola yang lebih sederhana dalam urutan yang terdefinisi, di mana setiap lapisan meneruskan output terstruktur ke lapisan berikutnya.
Penggabungan pola adalah komposisi arsitektur, bukan sekadar kombinasi fitur. Output dari Meeting Intelligence (catatan terstruktur, tindak lanjut, sentimen, keberatan utama) mengalir ke Workflow Copilot sebagai konteks untuk saran next action. Pembaruan CRM dari Workflow Copilot mengubah deal record yang digunakan Scoring and Routing untuk memprioritaskan ulang pipeline sales rep. Setiap pola memajukan pekerjaan lebih jauh dalam siklus kerja.
Insight desain utama: titik sambungan antar pola adalah tempat di mana sebagian besar kegagalan penggabungan terjadi. Bukan pola-polanya sendiri. Melainkan handoff di antara mereka.
Jika Meeting Intelligence menghasilkan ringkasan teks bebas sementara Workflow Copilot mengharapkan objek JSON terstruktur dengan field tertentu, tidak ada yang mengalir. Jika anggaran latensi mengasumsikan setiap pola merespons dalam 200 milidetik tetapi langkah Autonomous Agent membutuhkan 8 detik, seluruh stack melanggar persyaratan pengalaman pengguna. Jika kesalahan pada pola ke-2 diteruskan diam-diam ke pola ke-3, pola-pola berikutnya mengoptimalkan dari input yang salah tanpa mengetahuinya.
Desain penggabungan yang baik berarti merancang titik sambungan dengan cermat seperti merancang pola-polanya sendiri.
"Implementasi multi-agent di mana setiap lapisan memvalidasi inputnya sebelum diproses mencapai tingkat propagasi error 3x lebih rendah dibandingkan stack yang meneruskan output ke bawah tanpa validasi. Titik sambunganlah yang menjadi arsitekturnya." (Shakudo Enterprise AI Production Report, 2026)
Lantas apa yang berubah ketika pola-pola bergabung menjadi agent penuh? Bagian berikutnya menjelaskan perbedaannya.
Level 2 vs Level 3
ACE Framework membedakan antara pola di Level 2 dan AI Agent di Level 3 berdasarkan tiga dimensi:
Cakupan: Pola Level 2 menyelesaikan tugas spesifik yang terbatas. Agent Level 3 memiliki sebuah peran. AI Sales Operator memiliki workflow sales rep. AI Support Agent memiliki antrian support. Cakupan Agent mencakup seluruh fungsi pekerjaan, bukan tugas-tugas individual di dalamnya.
Otoritas data: Agent Level 3 menyimpan state persisten tentang domain mereka. AI Sales Operator mengetahui riwayat deal secara lengkap, pola kinerja sales rep, template outreach mana yang berhasil di segmen industri mana. Pengetahuan institusional tersebut terakumulasi antar sesi dan menginformasikan sesi berikutnya. Pola Level 2 individual bersifat stateless: mereka menerima input dan menghasilkan output tanpa mengakumulasi konteks.
Permukaan governance: Pola Level 2 memiliki otoritas yang terbatas. Mereka hanya bisa melakukan apa yang menjadi kemampuan spesifik mereka. Agent Level 3 memiliki otoritas gabungan di berbagai kemampuan dan berbagai sistem. Persyaratan governance mereka jauh lebih kompleks. Gerbang persetujuan, jejak audit, dan batasan cakupan yang berlaku untuk setiap pola berlipat ganda di lapisan Level 3.
Berpindah dari Level 2 ke Level 3 bukan sekadar menambahkan lebih banyak pola.
Ini adalah keputusan desain untuk memberikan kepemilikan peran kepada sistem, dengan infrastruktur data dan arsitektur governance yang kepemilikan tersebut butuhkan. Riset McKinsey tentang seizing the agentic AI advantage mengkonfirmasi framing ini: kurang dari 10% perusahaan yang bereksperimen dengan agent berhasil menskalakan mereka, dan kesenjangan tersebut hampir selalu pada infrastruktur dan governance, bukan kemampuan model.
"Perusahaan yang memperlakukan deployment agent Level 3 sebagai penambahan fitur, bukan keputusan kepemilikan peran, mengalami tingkat pembatalan proyek 4x lebih tinggi di tahun kedua dibandingkan mereka yang menetapkan governance dan infrastruktur data terlebih dahulu." (McKinsey QuantumBlack, 2025)
Dua contoh berikut menunjukkan seperti apa infrastruktur tersebut dalam praktik nyata.
Contoh 1: AI Sales Operator
AI Sales Operator menggabungkan lima pola: Meeting Intelligence, RAG Assistant (Retrieval-Augmented Generation), Scoring and Routing, Workflow Copilot, dan Anomaly Agent. Berikut kontribusi setiap lapisan dan cara mereka melakukan handoff.
Lapisan 1: Meeting Intelligence
- Yang dilakukan: Menyerap rekaman panggilan, melakukan transkripsi, mengekstrak tindak lanjut, keberatan utama, dan sinyal deal.
- Dalam konteks ini: Setiap panggilan sales mengalir melalui Meeting Intelligence secara otomatis. Output berupa data terstruktur dengan transkrip, tindak lanjut, analisis sentimen, dan keberatan yang ditandai berdasarkan kategori ACE.
- Output ke lapisan berikutnya: Ringkasan panggilan terstruktur dengan field utama: tahap deal, keberatan yang muncul, langkah selanjutnya yang disepakati, timeline yang dinyatakan prospek, nama sales rep.
Lapisan 2: Workflow Copilot
- Yang dilakukan: Mengambil ringkasan panggilan ditambah konteks CRM yang ada dan menghasilkan next-best action untuk sales rep.
- Dalam konteks ini: Segera setelah panggilan berakhir, sales rep membuka record CRM dan melihat draft email tindak lanjut, rekomendasi pembaruan tahap, dan daftar tindakan dari panggilan.
- Input dari lapisan 1: Ringkasan panggilan terstruktur. Workflow Copilot tidak dapat memproses audio mentah atau transkrip mentah. Output Meeting Intelligence harus terstruktur dengan benar agar bisa digunakan Copilot.
- Output ke lapisan berikutnya: Sales rep meninjau dan menyetujui tindakan. Record CRM diperbarui dengan tahap baru, catatan, dan tugas berikutnya.
Lapisan 3: Scoring and Routing
- Yang dilakukan: Memberi skor ulang pada deal berdasarkan sinyal yang diperbarui dan memprioritaskan ulang pipeline sales rep.
- Dalam konteks ini: Setelah setiap pembaruan CRM, model Scoring menghitung ulang skor deal (menggabungkan kebaruan, sinyal keterlibatan, tahap, dan data firmografi). Tampilan pipeline sales rep diurutkan ulang secara otomatis.
- Input dari lapisan 2: Field record CRM yang diperbarui. Secara khusus, pembaruan tahap dan sinyal penyelesaian tindakan.
- Output ke lapisan berikutnya: Peringkat prioritas yang diperbarui dalam tampilan pipeline sales rep. Deal berprioritas tinggi muncul di bagian atas.
Lapisan 4: RAG Assistant
- Yang dilakukan: Menampilkan dokumentasi produk, studi kasus, dan playbook penanganan keberatan yang relevan berdasarkan konteks aktif sales rep.
- Dalam konteks ini: Ketika sales rep memiliki tanda "compliance objections raised" pada sebuah deal, RAG Assistant menampilkan tiga studi kasus paling relevan dari industri teregulasi dan playbook keberatan compliance standar.
- Input: Konteks deal record, khususnya tag keberatan dari Meeting Intelligence dan segmen industri dari data firmografi CRM.
- Output: Potongan dokumen dengan tautan, terlihat di sidebar CRM saat sales rep mengerjakan deal tersebut.
Lapisan 5: Anomaly Agent
- Yang dilakukan: Memantau kesehatan deal dari waktu ke waktu dan menandai pola yang tidak normal.
- Dalam konteks ini: Jika deal yang sebelumnya memiliki confidence 85% sepuluh hari lalu tidak memiliki keterlibatan dalam 12 hari, Anomaly Agent menandainya sebagai "deal at risk" dan memicu saran re-engagement dari Workflow Copilot.
- Input: Sinyal keterlibatan historis, tingkat perkembangan tahap deal di seluruh pipeline.
- Output: Alert yang muncul kepada sales rep dan manajer beserta saran tindakan pemulihan.
Stack lima lapisan inilah yang membuat AI Sales Operator terasa seperti sebuah peran, bukan sebuah fitur. Tidak ada pola individual yang, bila diterapkan sendiri, menghasilkan pengalaman ini. Integrasi adalah produknya. Untuk kasus ROI yang membuat stack ini layak dibangun, why sales ops is the highest-ROI AI use case merinci angka-angkanya.
Untuk penjelasan lebih mendalam tentang apa yang dilakukan AI Sales Operator sepanjang hari kerja sales rep, lihat What Is an AI Sales Operator.
Contoh 2: AI Support Agent
AI Support Agent menggabungkan lima pola secara berbeda: Scoring and Routing, RAG Assistant, Document Review, Workflow Copilot, dan Autonomous Agent. Handoff-nya bekerja secara berbeda karena use case support memiliki bentuk yang berbeda.
Lapisan 1: Scoring and Routing
- Yang dilakukan: Menerima setiap tiket yang masuk, mengklasifikasikannya berdasarkan jenis (sengketa tagihan, masalah teknis, permintaan fitur, eskalasi), memberi skor urgensi, dan merutekan ke antrian yang tepat.
- Dalam konteks ini: Sengketa tagihan berurgensi tinggi menuju jalur Autonomous Agent. Masalah teknis di atas ambang kompleksitas tertentu diteruskan ke agen senior. Permintaan standar berurgensi rendah menuju jalur self-service berbantuan RAG.
- Output ke lapisan berikutnya: Tiket dengan tag klasifikasi, skor urgensi, dan keputusan perutean.
Lapisan 2: RAG Assistant (untuk tiket Tier 2+ yang diteruskan ke manusia)
- Yang dilakukan: Untuk tiket yang ditangani agen manusia, RAG Assistant menampilkan 3 resolusi paling relevan dari basis pengetahuan.
- Dalam konteks ini: Agen manusia melihat tiket dan, dalam antarmuka yang sama, 3 saran resolusi teratas dengan skor kemiripan dan langkah resolusi spesifik yang digunakan.
- Input: Teks tiket dan tag klasifikasi dari Scoring and Routing.
- Output: Saran resolusi yang ditampilkan kepada agen manusia sebagai konteks.
Lapisan 3: Workflow Copilot (untuk agen manusia pada tiket kompleks)
- Yang dilakukan: Selama agen manusia aktif mengerjakan tiket, Copilot menyarankan draft respons berikutnya, makro yang tepat untuk diterapkan, dan field yang belum terisi sebelum penutupan.
- Dalam konteks ini: Saat agen manusia mengetik respons, Copilot menampilkan versi yang sudah disusun berdasarkan konteks tiket dan pola resolusi yang diambil RAG.
- Input: Konteks tiket aktif, posisi kursor agen manusia saat ini, dan output RAG dari lapisan 2.
- Output: Draft respons dan daftar periksa untuk agen manusia.
Lapisan 4: Document Review (untuk industri teregulasi)
- Yang dilakukan: Meninjau draft respons sebelum dikirim, memeriksa persyaratan kepatuhan (bahasa FINRA, pengungkapan HIPAA, disclaimer yang diperlukan).
- Dalam konteks ini: Untuk pelanggan layanan keuangan dan kesehatan, setiap draft respons melalui Document Review sebelum dapat dikirimkan.
- Input: Draft respons dari Workflow Copilot.
- Output: Status disetujui/ditandai, dengan item yang ditandai disorot dan bahasa koreksi yang disarankan.
Lapisan 5: Autonomous Agent (untuk resolusi terstruktur Tier 1)
- Yang dilakukan: Menangani tiket Tier 1 yang diidentifikasi Scoring and Routing sebagai tiket yang dapat diselesaikan tanpa keterlibatan manusia (sengketa tagihan di bawah ambang batas, permintaan pengembalian dana standar, alur reset kata sandi).
- Dalam konteks ini: Autonomous Agent memiliki akses ke API payment processor, sistem tiket, dan pengirim email. Ia membaca tiket, memverifikasi klaim, mengeluarkan resolusi, menutup tiket, dan mengirim konfirmasi.
- Input: Tiket terstruktur dengan tag klasifikasi dan cakupan resolusi yang diotorisasi.
- Output: Tiket tertutup dengan log resolusi dan konfirmasi pelanggan yang terkirim.
Stack ini menggambarkan pola desain utama: tidak semua tiket melewati semua lapisan. Keputusan Scoring and Routing di lapisan 1 menentukan lapisan mana yang akan dilalui tiket tertentu. Autonomous Agent menangani subset yang spesifik dan terbatas. Lapisan berbantuan manusia menangani sisanya.
4-Pattern Assembly Framework
4-Pattern Assembly adalah arsitektur bernama untuk membangun AI Agent tingkat peran dari tepat empat lapisan pola: (1) lapisan Ingest/Classify yang menstrukturkan input mentah, (2) lapisan Retrieve/Score yang memperkaya dengan konteks, (3) lapisan Generate/Recommend yang menghasilkan output yang menghadap pengguna, dan (4) lapisan Execute/Monitor yang bertindak atas persetujuan dan menandai penyimpangan. Setiap agent yang menangani peran penuh dapat dipetakan ke empat posisi ini. Pola di bawah empat lapisan menangani tugas. Pola pada empat lapisan atau lebih menangani peran.
Rework Analysis: Berdasarkan dua contoh dalam artikel ini dan pola produksi yang didokumentasikan oleh McKinsey, Gartner, dan Anthropic, agent yang mencapai ambang 4-Pattern Assembly (Ingest, Retrieve, Generate, Execute) menunjukkan tingkat retensi adopsi yang secara konsisten lebih tinggi dibandingkan stack dengan kurang dari empat lapisan. Data implementasi Rework menunjukkan bahwa tim sales yang menggunakan AI Sales Operator penuh dengan 4 lapisan mengurangi rata-rata waktu administrasi siklus deal sebesar 60-70 menit per sales rep per hari, dibandingkan dengan 15-20 menit untuk tim yang hanya menggunakan copilot satu pola.
Di mana stack mengalami kegagalan
Ketidakcocokan format data antar pola. Pola A menghasilkan ringkasan teks bebas. Pola B mengharapkan objek JSON terstruktur. Tidak ada yang mengalir. Solusinya bukan menyalahkan salah satu pola. Melainkan merancang skema handoff sebelum membangun salah satu lapisan. Kontrak handoff adalah bagian terpenting dari arsitektur.
Latensi yang terakumulasi. Stack dengan 5 pola di mana setiap pola membutuhkan 2 detik untuk merespons memerlukan total 10 detik sebelum pengguna melihat hasilnya. Analisis McKinsey tentang reimagining tech infrastructure for agentic AI menyoroti akumulasi latensi sebagai salah satu tantangan yang paling diremehkan saat beralih dari model tunggal ke deployment multi-agent. Dalam konteks copilot di mana pengguna aktif menunggu, 10 detik terlalu lama. Dalam proses background asinkron (pembaruan CRM setelah panggilan), 10 detik tidak masalah. Petakan anggaran latensi terhadap persyaratan pengalaman pengguna sebelum memutuskan kedalaman stack.
Propagasi error. Output yang salah dari pola ke-2 adalah input untuk pola ke-3. Jika pola ke-3 tidak memvalidasi inputnya, ia akan mengoptimalkan dari data yang salah dan menghasilkan output yang salah yang mengalir ke pola ke-4. Saat error terdeteksi, kesalahan tersebut sudah berlipat ganda. Solusinya adalah validasi input di setiap lapisan, bukan hanya di titik masuk awal. Setiap pola harus menolak input yang salah bentuk atau berkepercayaan rendah, bukan mencoba meneruskannya.
Celah governance di titik sambungan. Kebijakan governance mungkin mencakup tindakan Execute dari setiap pola individual. Namun siapa yang menyetujui data yang mengalir dari Meeting Intelligence ke Workflow Copilot? Siapa yang mengotorisasi reprioritisasi Scoring and Routing terjadi secara otomatis berdasarkan item tindakan yang dihasilkan AI dari sebuah panggilan? Titik sambungan antar pola menciptakan permukaan governance yang tidak tercakup oleh kebijakan individual masing-masing pola. Rancang governance di titik sambungan, bukan hanya di level pola. Batas generate vs. execute adalah titik awal yang paling jelas untuk memulai diskusi ini.
| Mode kegagalan | Di mana biasanya muncul | Mitigasi |
|---|---|---|
| Ketidakcocokan format data | Pada handoff pertama antar pola | Definisikan skema handoff sebelum membangun; validasi di setiap lapisan |
| Anggaran latensi terlampaui | Setelah seluruh stack selesai dibuat | Uji setiap pola secara independen; modelkan total latensi sebelum deployment |
| Propagasi error | Di hilir dari output pertama yang salah | Validasi input di setiap lapisan; input berkepercayaan rendah harus dieskalasi, bukan diteruskan diam-diam |
| Celah governance di titik sambungan | Pada fase desain persetujuan dan audit | Petakan persyaratan governance untuk setiap aliran data, bukan hanya setiap output pola |
| Penyimpangan model entitas bersama | Ketika pola mereferensikan "contact" atau "deal" yang sama secara berbeda | Model entitas tunggal yang dibagikan ke semua pola; tegakkan di lapisan data |
Prinsip desain untuk stack pola
Modular. Setiap pola harus dapat diganti tanpa membangun ulang seluruh stack. Lapisan Meeting Intelligence dapat ditingkatkan ke model yang lebih baik tanpa mengubah Workflow Copilot atau Scoring and Routing, selama skema output tetap konsisten. Perlakukan setiap lapisan sebagai kontrak dengan input dan output yang terdefinisi, bukan sebagai komponen yang terikat erat.
Dapat diobservasi. Setiap handoff antar pola harus dicatat. Bukan hanya output akhir. Aliran data lengkap: apa yang diterima pola sebagai input, apa yang dihasilkan, apa yang dikirim ke lapisan berikutnya, dan kapan. Observabilitas di titik sambungan adalah satu-satunya cara untuk men-debug stack ketika ada yang salah. Logging hanya pada output akhir hanya memberi tahu apa hasil akhirnya, bukan di mana kesalahan berasal.
Mengalami degradasi secara graceful. Jika Anomaly Agent tidak tersedia (timeout model, gangguan API), sisa stack harus terus bekerja. Workflow Copilot sales rep harus tetap menampilkan tindakan berikutnya. Meeting Intelligence harus tetap memperbarui CRM. Hanya permukaan pemantauan anomali yang akan padam, dengan indikator terlihat bahwa alert sementara dijeda. Rancang mode kegagalan setiap lapisan secara eksplisit. Lapisan yang tidak tersedia harus menghasilkan output null dengan tanda kegagalan, bukan error yang menghentikan seluruh stack.
| Kedalaman stack | Use case tipikal | Rata-rata latensi (sinkron) | Risiko propagasi error | Kompleksitas governance |
|---|---|---|---|---|
| 1 pola | Tugas tunggal (transkripsi, perutean, penyusunan) | Di bawah 2 detik | Rendah | Sederhana |
| 2-3 pola | Kelompok tugas (panggilan + pembaruan CRM) | 3-6 detik | Sedang | Moderat |
| 4-5 pola (tingkat peran) | Kepemilikan fungsi penuh (AI Sales Operator) | 6-15 detik async OK | Tinggi tanpa validasi | Kompleks |
| 6+ pola | Orkestrasi lintas fungsi | Async saja | Sangat tinggi | Memerlukan lapisan governance khusus |
"Median waktu-ke-nilai untuk deployment AI agent enterprise adalah 5,1 bulan, dengan sales development agent mencapai balik modal dalam 3,4 bulan. Agent keuangan dan operasional rata-rata membutuhkan 8,9 bulan. Kedalaman stack dan kesiapan data adalah variabel utama, bukan pemilihan model." (Landbase Agentic AI Report, 2026)
Prasyarat sebelum menggabungkan pola
Sebelum membangun stack multi-pola, tiga kondisi infrastruktur perlu tersedia:
Pipeline data bersama. Semua pola dalam stack membutuhkan akses ke penyimpanan data yang sama dengan skema yang konsisten. Jika Meeting Intelligence menulis ke satu database dan Scoring and Routing membaca dari database lain, stack tersebut terisolasi. Pipeline data adalah jaringan penghubungnya.
Model entitas bersama. Setiap pola harus merujuk pada definisi yang sama tentang "contact," "deal," "ticket," atau entitas sentral apa pun. Jika Meeting Intelligence mengenal contact melalui alamat email mereka dan Scoring and Routing mengidentifikasinya melalui ID record CRM, titik sambungan akan putus begitu contact ada di satu sistem tetapi tidak di sistem lainnya.
Anggaran latensi yang terdefinisi. Ketahui waktu respons yang dapat diterima untuk pengalaman pengguna yang sedang Anda bangun sebelum merakit stack. Interaksi copilot bersifat sinkron dan memiliki persyaratan latensi yang ketat (di bawah 2 detik). Pemrosesan background (pembaruan CRM pasca-panggilan) dapat mentoleransi 30-60 detik. Kedalaman stack harus sesuai dengan anggaran tersebut.
Jalan menuju Level 3
Contoh-contoh dalam artikel ini merupakan awal dari apa yang disebut ACE Framework sebagai Level 3: AI Agent di tingkat peran. AI Sales Operator dan AI Support Agent keduanya merupakan konstruksi Level 3, masing-masing dibangun dengan menggabungkan pola Level 2 dengan infrastruktur data dan arsitektur governance yang tepat.
Perkembangan dari Level 2 ke Level 3 adalah perkembangan dari "AI yang melakukan tugas" menjadi "AI yang memiliki fungsi." Perkembangan tersebut memerlukan infrastruktur dan disiplin desain yang dijelaskan di atas. Ini bukan ambang yang dapat Anda capai hanya dengan menambahkan satu pola lagi ke stack.
Untuk pola-pola yang memerlukan prasyarat tertentu sebelum dapat berpartisipasi dalam stack, lihat Pattern Dependencies and Prerequisites. Untuk melihat di mana stack bekerja berdasarkan departemen, lihat Pattern Combinations by Department.
Pelajari lebih lanjut

Co-Founder, Rework.com