Scoring and Routing: AI Triage dalam Skala Besar
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
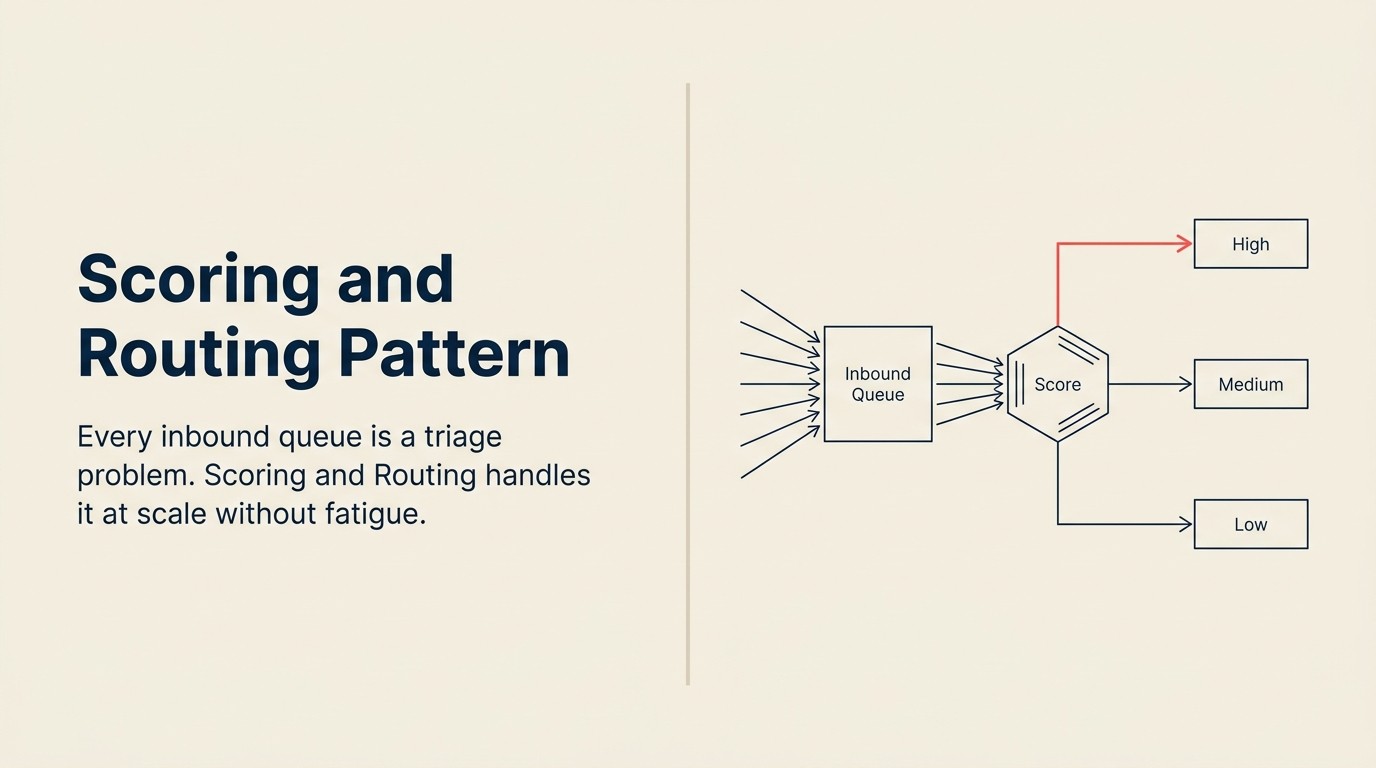
Setiap antrian inbound adalah masalah triage.
Lead tiba dari kampanye webinar: 400 kontak, 40 di antaranya benar-benar berniat membeli dan 360 yang mengklik karena judulnya menarik. Support ticket menumpuk semalam: 300 permintaan baru, 12 di antaranya adalah masalah enterprise mendesak dan 288 yang merupakan pertanyaan L1 yang sudah terjawab di dokumen Anda. Aplikasi pinjaman masuk: 1.200 minggu ini, beberapa layak kredit, beberapa tidak, beberapa yang tampak bersih ternyata penipuan.
Tugasnya sama dalam setiap kasus. Pisahkan sinyal dari kebisingan. Prioritaskan item yang tepat. Rutekan masing-masing ke orang atau proses yang tepat. Lakukan cukup cepat sehingga hal-hal yang benar-benar mendesak tidak duduk dalam antrian selama tiga jam sementara seorang manusia membaca semuanya secara manual.
Triage manual tidak dapat diskalakan. Aturan berbasis threshold ("rutekan lead dari perusahaan dengan 500+ karyawan ke tim enterprise") melewatkan konteks. Mereka tidak bisa membaca utas email yang datang bersama lead. Mereka tidak bisa melihat bahwa pengunjung menghabiskan 40 menit di halaman penetapan harga Anda. Mereka tidak bisa memperhitungkan bahwa prospek ini sebelumnya pernah churn setelah enam bulan.
Scoring and Routing adalah AI pattern yang menangani ini. Ini adalah salah satu pattern yang paling penting secara ekonomi dalam business AI, dan memahaminya dengan jelas, termasuk di mana ia salah, sepadan dengan investasinya.
Formulanya: Ingest, Analyze, Predict, Execute
Ingest (catatan masuk) menangkap input mentah: catatan lead baru, support ticket yang dikirimkan, lamaran pekerjaan, klaim asuransi yang diajukan. Dalam sebagian besar deployment, langkah Ingest bukan hanya item itu sendiri. Ia menarik konteks terkait: riwayat penelusuran lead, tier dan usia akun pelanggan, resume pelamar yang diunggah bersama deskripsi pekerjaan, sidik jari perangkat transaksi dan riwayat merchant.
Analyze (ekstrak fitur) mengubah input mentah menjadi sinyal yang akan digunakan model. Untuk lead: ukuran perusahaan, senioritas jabatan, halaman situs yang dikunjungi, domain email, industri, dan keterlibatan masa lalu. Untuk support ticket: klasifikasi intent (tagihan? bug? permintaan fitur?), sentimen, tier pelanggan, dan apakah cocok dengan pola insiden yang diketahui. Langkah ini adalah tempat keunggulan AI dimulai. Triage manusia melihat 3-5 sinyal. Model mengevaluasi 20-50 secara bersamaan, termasuk interaksi antara sinyal yang tidak akan diperiksa manusia.
Predict (scoring) adalah model yang menerapkan pola yang dipelajari pada fitur-fitur tersebut. Outputnya adalah skor: probabilitas atau peringkat prioritas. Untuk lead: probabilitas menutup dalam 90 hari. Untuk tiket: probabilitas ini perlu eskalasi atau spesialis. Untuk penipuan: probabilitas transaksi ini tidak sah. Langkah Predict adalah pencocokan pola murni terhadap hasil historis, biasanya diimplementasikan dengan logistic regression, gradient-boosted trees, atau LLM yang di-fine-tune untuk input kaya teks. Ini telah mengamati apa yang terjadi pada catatan masa lalu yang tampak seperti ini.
Execute (rutekan atau tetapkan) mengambil skor dan bertindak atasnya. Tetapkan lead ke tim enterprise. Pindahkan tiket ke antrian keamanan. Tolak transaksi dan picu workflow tinjauan. Buat tugas Salesforce. Kirim peringatan Slack ke rep on-call. Execute adalah tempat skor menjadi keputusan dengan konsekuensi. Di sini juga tata kelola paling penting. Langkah Execute memiliki efek downstream nyata yang tidak selalu mudah dibatalkan.
Key Facts: Dampak Bisnis Scoring and Routing
- McKinsey memperkirakan AI dalam penjualan dan pemasaran dapat membuka $0,8 hingga $1,2 triliun dalam produktivitas inkremental, dengan pemain yang berinvestasi dalam AI melihat peningkatan pendapatan 3-15% dan peningkatan ROI penjualan 10-20% (McKinsey, 2023)
- Perusahaan B2B yang menggunakan lead scoring berbasis AI melihat peningkatan tingkat konversi 2-3x dalam tier lead dengan skor tertinggi dibandingkan antrian yang ditriage secara manual, dalam deployment matang dengan 12+ bulan data hasil (Forrester B2B Sales AI Report, 2025)
- Carrier asuransi yang menggunakan Scoring and Routing pattern melaporkan pengurangan 30-40% dalam biaya pemrosesan klaim pada klaim rutin, dengan mempercepat klaim bersih dan merutekan yang kompleks ke adjuster spesialis (Deloitte Insurance AI Study, 2024)
Lima contoh nyata secara mendalam
1. Lead scoring dan penugasan rep
Kasus penggunaan kanonik. Kampanye pemasaran menghasilkan 300 lead inbound. Model menerima setiap catatan lead ditambah data perilaku dari analitik situs dan platform keterlibatan email Anda. Ia menganalisis fitur seperti jabatan (VP of Sales mendapat skor lebih tinggi dari Sales Intern), ukuran perusahaan, kesesuaian industri, halaman yang dikunjungi (halaman penetapan harga dikunjungi lebih dari dua kali adalah sinyal kuat), email dibuka dalam dua jam, dan riwayat CRM masa lalu jika ini adalah prospek yang kembali.
Langkah Predict menetapkan setiap lead skor dari 0-100 yang mewakili perkiraan probabilitas konversi. Langkah Execute merutekan lead di atas 75 ke rep senior Anda dengan SLA hari yang sama, lead antara 40-75 ke SDR untuk kualifikasi, dan lead di bawah 40 ke urutan nurture otomatis.
Tooling di sini meliputi Salesforce Einstein Lead Scoring, HubSpot's Predictive Lead Scoring, dan di Rework, AI-assisted scoring yang terintegrasi ke dalam workflow penjualan. Sistem yang dikalibrasi dengan baik biasanya menggeser 20-30% lebih banyak Pipeline ke lead yang berkonversi tinggi tanpa menambah headcount. Untuk pendalaman implementasi khusus penjualan, lihat lead scoring AI melampaui model berbasis aturan.
2. Prioritisasi support ticket dan routing tim
Perusahaan SaaS B2B menerima 600 support ticket setiap hari. Model menerima teks setiap tiket bersama data akun pelanggan yang mengirimkan: ARR, tier kontrak, pola penggunaan, riwayat tiket sebelumnya, dan hari menuju pembaruan. Analyze mengklasifikasikan intent (masalah tagihan, bug teknis, permintaan fitur, masalah keamanan), mendeteksi sentimen, dan memeriksa indikator risiko eskalasi.
Predict memberi skor urgensi: pelanggan ARR tinggi dengan masalah tagihan tiga minggu sebelum pembaruan mendapat skor teratas. Execute merutekan tiket urgensi tinggi ke account manager yang ditunjuk, masalah teknis ke tier engineering yang tepat, dan permintaan fitur urgensi rendah ke antrian backlog. Hasilnya: masalah enterprise mendapat respons dalam hitungan menit; kebisingan L1 tidak memblokir tim.
Alat dalam ruang ini meliputi Zendesk AI, kecerdasan tiket Intercom, dan Freddy AI dari Freshdesk.
3. Penyaringan resume dan penugasan rekruter
Sebuah perusahaan membuka 12 posisi terbuka dan menerima 1.800 lamaran dalam dua minggu. Model menerima setiap resume dan deskripsi pekerjaan. Analyze mengekstrak sinyal yang relevan: tahun dalam peran yang relevan, keterampilan spesifik yang disebutkan, perusahaan yang pernah bekerja, tingkat pendidikan, struktur dan kelengkapan resume. Ia membandingkan setiap resume dengan profil target untuk peran tersebut.
Predict menghasilkan skor kesesuaian per pelamar per peran. Execute menampilkan kuartil teratas ke rekruter untuk peran tersebut, merutekan kandidat borderline ke langkah penyaringan yang lebih ringan, dan mengirim tier bawah respons otomatis. Catatan: ini juga tempat risiko bias paling tinggi. Dibahas di bawah.
Alat di sini meliputi Eightfold, HireVue, Paradox, dan add-on penyaringan AI Greenhouse.
4. Fast-track klaim asuransi vs. tinjauan manusia
Sebuah perusahaan asuransi memproses 5.000 klaim setiap bulan. Klaim sederhana (tabrakan ringan dengan dokumentasi foto dan tanggung jawab yang jelas) dapat dibayarkan dalam 48 jam jika model memberi mereka skor "fast-track." Klaim kompleks memerlukan adjuster manusia.
Model menerima data formulir klaim, foto terlampir, riwayat kendaraan, riwayat pemegang polis, dan catatan pihak ketiga. Analyze mengekstrak indikator kompleksitas: apakah tanggung jawab jelas? Apakah ada cedera? Apakah jumlah yang diklaim cocok dengan data insiden yang sebanding? Apakah riwayat penggugat menunjukkan pola anomali?
Predict memberi skor setiap klaim dalam dua dimensi: probabilitas fast-track (apakah ini rutin?) dan probabilitas penipuan (apakah ini cocok dengan pola penipuan yang diketahui?). Execute merutekan klaim fast-track dan penipuan rendah ke pembayaran otomatis, klaim kompleksitas menengah ke adjuster, dan klaim probabilitas penipuan tinggi ke unit investigasi khusus.
Ini adalah salah satu kasus penggunaan yang paling terbukti untuk pattern ini, dengan carrier melaporkan pengurangan 30-40% dalam biaya pemrosesan pada mayoritas yang rutin.
5. Deteksi penipuan dalam pembayaran
Stripe Radar adalah salah satu sistem scoring yang paling banyak digunakan di dunia, meskipun sebagian besar operator menganggapnya sebagai "pencegahan penipuan" daripada "AI." Untuk setiap transaksi kartu, model Stripe menerima metadata kartu, sidik jari perangkat, jumlah transaksi, kategori merchant, data geografis, dan sinyal perilaku (seberapa cepat formulir diisi, apakah alamat penagihan dan pengiriman cocok).
Analyze mengekstrak fitur. Predict menetapkan skor probabilitas penipuan: 99,5% (hampir pasti penipuan) atau 0,2% (hampir pasti sah). Execute bertindak berdasarkan skor tersebut: setujui, kirim ke tinjauan 3D Secure, atau blokir sepenuhnya.
Langkah Execute di sini sangat berisiko tinggi dan terjadi dalam milidetik. Itulah mengapa kalibrasi threshold skor sangat penting. Threshold yang ditetapkan terlalu agresif memblokir transaksi sah dan menghasilkan chargeback dari pelanggan yang marah. Terlalu permisif dan kerugian penipuan meningkat. Threshold yang tepat adalah keputusan bisnis, bukan sekadar parameter model.
The Score-Then-Execute Loop
Scoring and Routing bekerja dalam dua fase berbeda yang tidak boleh digabungkan: fase scoring di mana setiap item masuk menerima peringkat prioritas berdasarkan fitur yang diekstrak dan pola hasil historis, dan fase execute di mana peringkat tersebut mendorong keputusan routing. Menggabungkan dua fase, seperti merutekan langsung dari aturan berbasis threshold tanpa scoring model, melewatkan sinyal kontekstual yang membedakan lead enterprise berintent rendah dari lead SMB berintent tinggi. Merutekan langsung dari kepercayaan model mentah tanpa pemetaan score-to-threshold menghasilkan ketidakstabilan routing saat model melakukan kalibrasi. Struktur dua fase -- score dulu lalu execute berdasarkan threshold yang divalidasi -- adalah yang membuat pattern ini andal pada volume besar.
Failure modes: apa yang sebenarnya salah
| Failure mode | Akar penyebab | Perbaikan |
|---|---|---|
| Bias data pelatihan | Model dilatih pada hasil yang secara historis miring (rep masa lalu hanya menutup dari mid-market; lead enterprise diprioritaskan secara tidak adil) | Audit distribusi skor di seluruh segmen. Periksa korelasi demografis dalam data kandidat atau pelanggan. |
| Miscalibration threshold | Threshold 70 poin yang mengirim 60% lead berintent tinggi ke rep junior karena cutoff tidak divalidasi terhadap win rate aktual | Validasi threshold terhadap hasil. Perlakukan penetapan threshold sebagai item tinjauan bisnis kuartalan, bukan pengaturan satu kali. |
| Keusangan fitur | Model yang dilatih pada data Q1 melewatkan lini produk baru yang diluncurkan di Q3, sehingga prospek yang mengunjungi halaman produk tersebut tidak mendapat skor baik | Siapkan jadwal retraining otomatis yang terhubung dengan perubahan produk/segmen. Lacak pergeseran distribusi skor dari waktu ke waktu. |
| Kegagalan feedback loop | Tidak ada yang memantau apakah lead yang dirutekan benar-benar menutup, tiket benar-benar diselesaikan, atau klaim yang dirutekan benar-benar dibayarkan dengan bersih | Bangun pelacakan hasil ke dalam workflow dari hari pertama. Model membutuhkan data historis berlabel untuk tetap terkalibrasi. |
| Inflasi skor tanpa tindakan | Scoring berjalan, tetapi rep mengabaikan urutan antrian; semua orang mengerjakan Pipeline mereka sendiri | Buat skor terlihat di antarmuka workflow (CRM, alat support). Kaitkan metrik kinerja tim dengan kepatuhan scoring, bukan hanya output. |
| Kesalahan routing senyap | Execute mengirim item ke antrian yang salah secara senyap (tidak ada yang menyadari selama berminggu-minggu) | Catat setiap keputusan routing. Buat laporan pengecualian yang menampilkan ketidaksesuaian antara tier yang diberi skor dan tier hasil. |
Dua failure mode dengan leverage tertinggi (miscalibration threshold dan kegagalan feedback loop) juga yang paling tidak menarik untuk diperbaiki. Mereka tidak memerlukan model baru. Mereka memerlukan disiplin operasional: tinjauan berkala tentang siapa yang dirutekan ke mana, dan apakah keputusan routing tersebut membuahkan hasil.
Laporan Operasi AI Gartner 2025 menemukan bahwa 68% sistem scoring AI yang berkinerja di bawah benchmark awal mereka melacak degradasi ke kegagalan feedback loop. Model tidak pernah dilatih ulang pada hasil baru, sehingga terus memberi skor pada catatan saat ini terhadap pola yang dipelajari dari data closed-won 2022.
Kalibrasi threshold: pengungkit yang paling diabaikan
Sebagian besar operator yang menerapkan sistem scoring menghabiskan 90% perhatian mereka pada pemilihan model dan 10% pada penetapan threshold. Return atas investasi tersebut terbalik.
Tugas model adalah meranking item. Tugas threshold adalah memutuskan apa arti peringkat tersebut secara operasional. Model lead scoring mungkin secara akurat meranking 300 lead dari 1 hingga 300. Tetapi jika Anda menetapkan threshold "prioritas tinggi" pada 60 dari 100 dan 200 dari 300 lead Anda mendapat skor di atas 60, rep senior Anda kewalahan dan segmentasi menjadi tidak berarti.
Kalibrasi threshold memerlukan tiga input: distribusi skor data historis, kapasitas operasional Anda di setiap tier routing (berapa banyak item yang dapat ditangani tim enterprise Anda per hari?), dan data hasil (rentang skor apa yang sebenarnya berkorelasi dengan kemenangan?). Ketika Anda memiliki ketiga hal ini, Anda dapat menetapkan threshold yang sesuai dengan realitas operasional, bukan hanya cutoff statistik.
Tinjau threshold setidaknya setiap kuartal. Perubahan pasar, perubahan campuran kampanye, dan ekspansi produk semuanya menggeser distribusi skor di bawah Anda.
Kapan Scoring and Routing bekerja, dan kapan tidak
Bekerja dengan baik ketika:
- Anda memiliki hasil historis berlabel. Model belajar dari data masa lalu: lead mana yang menutup, klaim mana yang curang, pelamar mana yang dipekerjakan dan bertahan. Tidak ada riwayat berlabel berarti tidak ada prediksi yang bermakna.
- Anda memiliki volume. Scoring and Routing terbayar ketika masalah triage nyata. Jika Anda menerima 15 lead per minggu, rep penjualan dapat men-triage-nya secara manual dalam 10 menit. Jika Anda menerima 500, Anda membutuhkan pattern ini.
- Keputusan routing memetakan ke tindakan yang jelas dan dapat dieksekusi. "Rutekan ke tim enterprise" dapat dieksekusi. "Perlakukan lead ini dengan lebih hati-hati" tidak.
- Data Anda cukup lengkap dan konsisten. Bidang yang hilang (lead tanpa jabatan, tiket tanpa tautan akun) menurunkan kualitas prediksi.
Pertimbangkan alternatif ketika:
vs. Anomaly Agent: Scoring and Routing menetapkan prioritas dalam kategori yang diketahui. Anomaly Agent menandai item yang tidak termasuk dalam kategori yang diharapkan (unknown unknown). Jika Anda perlu menangkap pola penipuan baru yang tidak terlihat seperti penipuan masa lalu, Anomaly Agent adalah alat yang tepat. Scoring and Routing akan memberi skor kasus baru tersebut sebagai risiko menengah karena menyerupai catatan normal, bukan karena mereka adalah pola penipuan yang familiar.
vs. Workflow Copilot: Scoring bertindak tanpa pengguna. Copilot membantu pengguna selama pekerjaan mereka. Jika proses Anda memerlukan penilaian yang tidak dapat didelegasikan secara algoritmis (panggilan penjualan enterprise yang kompleks, negosiasi yang nuansif, situasi pelanggan yang sensitif), Copilot membantu manusia daripada menggantikan keputusan triage mereka.
vs. Autonomous Agent: Scoring and Routing membuat satu keputusan pada satu titik dalam workflow. Autonomous Agent menjalankan loop multi-langkah, membuat beberapa keputusan untuk menyelesaikan tujuan. Scoring and Routing adalah modul dalam workflow yang lebih besar; Autonomous Agents adalah workflow penuh.
ROI signals: cara mengukur apakah berhasil
| Metrik | Apa yang diukur | Benchmark yang masuk akal |
|---|---|---|
| Speed-to-first-contact | Waktu dari pengiriman lead hingga outreach rep pertama | Pengurangan 50-70% vs. antrian manual |
| Utilisasi rep berdasarkan tier | Porsi waktu rep enterprise pada lead dengan skor enterprise | Baseline: ~40%. Dengan scoring: 65-80% |
| Win rate: scored vs. unscored | Perbandingan tingkat konversi di seluruh band skor tinggi/menengah/rendah | Band tinggi harus 2-3x win rate band rendah dalam deployment matang |
| Waktu resolusi tiket berdasarkan jalur routing | Tiket yang dirutekan AI vs. tiket yang disortir manual | Pengurangan 20-35% dalam time-to-resolution untuk yang dirutekan AI |
| Tingkat false positive | Item yang dirutekan ke antrian prioritas yang tidak memerlukan prioritas | Lacak setiap kuartal; target <15% false positive dalam tier enterprise |
| Pergeseran distribusi skor | Apakah distribusi skor model bergeser dari waktu ke waktu | Tandai jika skor rata-rata berubah lebih dari 10 poin dari kuartal ke kuartal |
Perbandingan win rate antara lead yang di-score dan yang tidak di-score adalah bukti terkuat Anda. Jika lead dalam band skor teratas menutup pada 28% dan lead dalam band skor terbawah menutup pada 7%, model menghasilkan nilainya. Jika angka-angka tersebut serupa, model tidak membedakan dengan berguna, dan Anda memiliki masalah data pelatihan atau fitur.
Persyaratan tata kelola
Scoring and Routing menyentuh hasil ekonomi orang: komisi rep penjualan, tawaran pekerjaan kandidat, persetujuan atau penolakan pelanggan. Itu bukan alasan untuk menghindarinya. Itu adalah alasan untuk mengaturnya dengan baik.
Audit model setiap kuartal. Periksa distribusi skor di seluruh segmen demografis, geografis, dan firmografis. Jika model lead scoring Anda secara sistematis memberi skor lebih rendah pada lead dari wilayah atau industri tertentu tanpa alasan bisnis, Anda memiliki masalah bias meskipun model secara teknis "akurat."
Definisikan override manusia dengan jelas. Rep mana pun harus dapat menandai lead dengan skor rendah yang mereka yakini berintent tinggi. Rekruter mana pun harus dapat memindahkan resume ke putaran berikutnya secara manual. Proses override harus dicatat sehingga Anda dapat memeriksa apakah override secara sistematis berbeda dari prediksi model, dan apakah override tersebut benar.
Jadwal retraining. Untuk sebagian besar aplikasi bisnis, retraining kuartalan adalah default yang masuk akal. Bulanan jika pasar Anda berubah cepat. Tahunan hampir selalu terlalu lambat. Anda memberi skor prospek 2025 terhadap model 2023.
Dokumentasi untuk industri yang diregulasi. Dalam layanan keuangan, pinjaman, asuransi, dan perekrutan, keputusan scoring otomatis mungkin memerlukan explainability di bawah ECOA, GDPR Article 22, atau undang-undang AI tingkat negara bagian. Ketahui yurisdiksi Anda. "Model yang mengatakan begitu" bukan penjelasan yang dapat dipertahankan untuk keputusan kredit yang merugikan.
Lanskap vendor dan tooling
| Kasus penggunaan | Alat utama |
|---|---|
| Lead scoring | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Routing support ticket | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Penyaringan kandidat | Eightfold, HireVue, Paradox, Greenhouse AI |
| Deteksi penipuan | Stripe Radar, Kount, Featurespace, Sardine |
| Klaim asuransi | Shift Technology, Tractable, Cape Analytics |
| Infrastruktur scoring kustom | Pinecone (vector embeddings untuk kesamaan fitur), Tecton (feature stores), AWS SageMaker, Azure ML |
Untuk tim yang membangun scoring kustom: Pinecone dan Weaviate sering digunakan untuk retrieval fitur berbasis kesamaan, tetapi model scoring inti biasanya adalah gradient-boosted tree (LightGBM, XGBoost) atau LLM yang di-fine-tune untuk input kaya teks. Infrastruktur lebih tidak penting daripada kualitas data historis berlabel dan ketelitian kalibrasi threshold.
Koneksi ke AI Sales Operator
Scoring and Routing adalah salah satu dari empat pattern di inti AI Sales Operator (Level 3 dalam ACE Framework). Dalam konteks itu, lead scoring bukan hanya fitur otomasi pemasaran. Ini adalah lapisan keputusan front-of-funnel yang menentukan bagaimana hari setiap rep diorganisir. Konsep AI Sales Operator menjelaskan bagaimana empat pattern ini bekerja bersama dalam praktik.
Organisasi penjualan dengan kinerja tertinggi menggunakan scoring bukan hanya untuk memprioritaskan lead inbound tetapi untuk memprioritaskan waktu rep di seluruh Pipeline penuh: deal mana yang harus dimajukan, akun mana yang harus diterlibatkan untuk ekspansi, pembaruan mana yang berisiko churn. Ketika Scoring and Routing terhubung ke Meeting Intelligence (analisis panggilan) dan Workflow Copilot (saran tertanam CRM), ketiga pattern bersama-sama membentuk loop tertutup: AI memberi skor peluang, AI menganalisis panggilan, AI menyarankan tindakan berikutnya.
Arsitektur itulah yang membedakan tim penjualan yang ditingkatkan AI dari tim yang hanya memiliki alat AI untuk penugasan lead.
Rework Analysis: Sebagian besar tim yang menerapkan lead scoring mendapatkan model yang benar dan operasi yang salah. Model memberi skor lead secara akurat. Tetapi threshold ditetapkan sekali saat peluncuran, data hasil tidak pernah diumpankan kembali, dan tim tidak pernah mengaudit apakah lead dengan skor tinggi benar-benar menutup pada tingkat yang lebih tinggi daripada lead dengan skor rendah. Enam bulan kemudian, rep telah berhenti mempercayai urutan antrian dan mengerjakan Pipeline mereka sendiri. ROI model menguap bukan karena AI gagal tetapi karena feedback loop tidak pernah dibangun. Scoring and Routing memerlukan dua komitmen organisasi, bukan satu: sistem scoring dan tinjauan hasil kuartalan yang menjaganya tetap terkalibrasi. Tim yang membuat kedua komitmen melihat peningkatan konversi 2-3x. Tim yang hanya membuat komitmen pertama melihat pergeseran lambat kembali ke triage manual.
Pertanyaan yang Sering Diajukan
Apa itu Scoring and Routing AI pattern?
Scoring and Routing adalah AI pattern yang secara otomatis memprioritaskan dan menetapkan item masuk (lead, tiket, lamaran, klaim) menggunakan formula empat langkah: Ingest catatan masuk dan konteks, Analyze fitur yang diekstrak, Predict skor prioritas, dan Execute keputusan routing. Pattern ini menangani triage pada volume yang tidak dapat dipertahankan oleh tinjauan manual, dan ia mengevaluasi 20-50 sinyal secara bersamaan versus 3-5 yang dibaca manusia selama triage manual.
Bagaimana cara kerja AI lead scoring?
AI lead scoring menerima setiap catatan lead ditambah data perilaku (halaman yang dikunjungi, keterlibatan email, waktu penelusuran di penetapan harga), mengekstrak fitur (ukuran perusahaan, senioritas jabatan, industri, riwayat CRM masa lalu), dan menerapkan model yang dilatih untuk menetapkan skor probabilitas. Model belajar dari hasil historis: lead masa lalu dengan profil serupa mana yang benar-benar menutup. Skor mendorong routing: skor tinggi pergi ke rep senior dengan SLA hari yang sama, skor menengah pergi ke SDR untuk kualifikasi, skor rendah pergi ke urutan nurture otomatis.
Apa failure mode paling umum dalam Scoring and Routing?
Dua kegagalan dengan dampak tertinggi adalah miscalibration threshold dan kegagalan feedback loop. Miscalibration threshold mengirim proporsi lead yang salah ke setiap tier routing, baik membebani rep senior dengan lead berkualitas menengah atau under-routing prospek berintent tinggi yang genuine. Kegagalan feedback loop terjadi ketika data hasil (siapa yang menutup, siapa yang churn, klaim mana yang curang) tidak diumpankan kembali untuk melatih ulang model, menyebabkannya memberi skor catatan saat ini terhadap pola historis yang kedaluwarsa. Gartner menemukan 68% sistem scoring yang berkinerja buruk melacak degradasi ke kegagalan feedback loop.
Apa itu The Score-Then-Execute Loop?
The Score-Then-Execute Loop adalah struktur dua fase dari Scoring and Routing pattern: pertama fase scoring di mana setiap item menerima peringkat prioritas dari fitur yang diekstrak dan pola hasil historis, kemudian fase execute di mana threshold yang divalidasi menerjemahkan peringkat tersebut menjadi keputusan routing. Menggabungkan dua fase, seperti merutekan langsung dari threshold berbasis aturan tanpa scoring model, melewatkan sinyal kontekstual yang membedakan lead enterprise berintent tinggi dari lead SMB berintent rendah. Merutekan langsung dari kepercayaan model mentah tanpa validasi threshold menghasilkan ketidakstabilan routing.
Kapan Anda harus menggunakan Scoring and Routing versus Anomaly Agent?
Gunakan Scoring and Routing ketika Anda perlu men-triage item dalam kategori yang diketahui: menetapkan prioritas di seluruh lead, tiket, atau lamaran yang semuanya mengikuti pola familiar. Gunakan Anomaly Agent ketika Anda perlu menangkap item yang tidak termasuk dalam kategori yang diharapkan, seperti pola penipuan baru yang tidak menyerupai penipuan masa lalu. Scoring and Routing akan memberi skor penipuan baru sebagai risiko menengah karena terlihat seperti transaksi normal. Anomaly Agent menandainya secara khusus karena menyimpang dari baseline statistik.
ROI apa yang harus Anda harapkan dari Scoring and Routing?
Deployment matang dengan 12+ bulan data hasil melihat peningkatan tingkat konversi 2-3x dalam tier lead dengan skor tertinggi. Tim penjualan melihat pengurangan 50-70% dalam speed-to-first-contact. Routing support ticket biasanya mengurangi time-to-resolution sebesar 20-35%. Carrier asuransi melaporkan pengurangan 30-40% dalam biaya pemrosesan klaim. Mencapai benchmark ini memerlukan sistem scoring yang terkalibrasi dan tinjauan hasil kuartalan yang melatih ulang model pada data yang ditutup baru.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Formulanya: Ingest, Analyze, Predict, Execute
- Lima contoh nyata secara mendalam
- 1. Lead scoring dan penugasan rep
- 2. Prioritisasi support ticket dan routing tim
- 3. Penyaringan resume dan penugasan rekruter
- 4. Fast-track klaim asuransi vs. tinjauan manusia
- 5. Deteksi penipuan dalam pembayaran
- The Score-Then-Execute Loop
- Failure modes: apa yang sebenarnya salah
- Kalibrasi threshold: pengungkit yang paling diabaikan
- Kapan Scoring and Routing bekerja, dan kapan tidak
- ROI signals: cara mengukur apakah berhasil
- Persyaratan tata kelola
- Lanskap vendor dan tooling
- Koneksi ke AI Sales Operator
- Pelajari lebih lanjut