Dependencias y Prerrequisitos de Patrones de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La razón más común por la que un patrón de AI falla después del despliegue es un prerrequisito que nunca se auditó.
No el modelo equivocado. No el proveedor equivocado. No el patrón equivocado. Una dependencia de datos que nadie verificó. Un acceso a API que se asumió pero nunca se confirmó. Una base de conocimiento que existe como una carpeta de documentos pero no tiene Pipeline de embeddings, ni cadencia de actualización, ni propietario asignado.
El patrón se construye. La integración se completa. Y luego, en la tercera semana de pruebas, alguien pregunta dónde están los datos históricos de resultados para el modelo de Scoring y descubre que nunca se recopilaron en un formato estructurado. O las grabaciones de audio para Meeting Intelligence existen, pero están almacenadas en un sistema de proveedor que no tiene API de exportación. O la base de conocimiento de la que se suponía que el RAG (Retrieval-Augmented Generation) Assistant debía responder tiene 18 meses de antigüedad y es completamente incorrecta sobre dos líneas de producto.
Estos descubrimientos no destruyen los proyectos de AI. Los retrasan entre tres y seis meses y consumen la buena voluntad que el período de prueba debía generar. La investigación de McKinsey sobre escalar AI agéntico con transformaciones de datos encuentra que ocho de cada diez empresas citan las limitaciones de datos como el principal obstáculo para escalar AI, no la calidad del modelo ni la selección del proveedor.
Este artículo mapea las dependencias por patrón, desarrolla una secuencia de despliegue real y le ofrece una lista de verificación de auditoría de prerrequisitos para ejecutar antes de que se apruebe cualquier implementación. Para la visión más amplia de preparación de datos antes de que comience cualquier proyecto de AI, preparación de datos: el prerrequisito que la mayoría de los proyectos de AI omiten es donde empezar.
Tipos de dependencias
Tres categorías cubren el panorama de dependencias:
Dependencias de datos: ¿Qué datos deben existir, estar correctamente estructurados y ser accesibles antes de que el patrón pueda operar? Esta es la categoría que más frecuentemente se pasa por alto. Los equipos asumen que los datos existen porque se han recopilado. Pero existencia no es lo mismo que accesibilidad, estructura o calidad. Los 7 tipos de datos que impulsan el AI empresarial enmarca el panorama completo aquí.
Dependencias de infraestructura: ¿Qué sistemas, Pipelines, APIs y recursos de cómputo deben estar en su lugar para que el patrón ingiera, procese, almacene y entregue resultados? Los equipos de ingeniería suelen tomar en cuenta estos aspectos, pero los propietarios de programas y negocios frecuentemente los subestiman. Un Pipeline de embeddings para RAG, un webhook de CRM para Scoring and Routing y un Pipeline de procesamiento de audio para Meeting Intelligence son cada uno inversiones de ingeniería no triviales.
Dependencias de patrones: Algunos patrones requieren que otro patrón opere primero, porque el patrón posterior consume datos que el patrón anterior produce. Meeting Intelligence produce los datos estructurados de llamadas que Workflow Copilot usa para sugerencias de siguiente acción en el CRM. Si Meeting Intelligence no está funcionando, el Workflow Copilot no tiene nada desde donde sugerir.
Key Facts: Fallos por Prerrequisitos de AI
- El 85% de los proyectos de AI fallidos citan la baja calidad de datos como causa raíz, según el análisis de RAND Corporation de más de 2.400 iniciativas de AI empresarial.
- La investigación de Gartner 2025 predice que el 60% de los proyectos de AI que carecen de datos listos para AI serán abandonados antes de completarse.
- Solo el 12% de las organizaciones tienen datos de calidad suficiente para soportar aplicaciones de AI sin una fase significativa de trabajo previo. (MIT Project NANDA, 2025)
Mapa de dependencias por patrón
| Patrón | Dependencias de datos | Dependencias de infraestructura | Dependencias de patrones comunes |
|---|---|---|---|
| RAG Assistant | Base de conocimiento mantenida (políticas, SOPs, documentación de producto, tickets resueltos); fragmentada e incrustada en una base de datos vectorial | Base de datos vectorial; Pipeline de embeddings; Pipeline de ingesta y actualización de documentos | Ninguna (suele ejecutarse primero) |
| Scoring + Routing | Registros históricos con resultados etiquetados (cierre ganado/perdido, resuelto/escalado, contratado/rechazado); campos de características estructuradas por registro | CRM o sistema de tickets con soporte de webhooks; infraestructura de entrenamiento y reentrenamiento de modelos; motor de reglas de enrutamiento | Ninguna (puede ser el primer patrón desplegado) |
| Vision Extract | Imágenes de entrenamiento o ejemplos de escaneos anotados para el tipo de documento objetivo; acceso a los documentos fuente en forma digital o física | Pipeline de ingesta de imágenes; API de OCR o modelo de visión; sistema de registro objetivo con acceso de escritura | Ninguna (suele ejecutarse de forma independiente) |
| Meeting Intelligence | Grabaciones de audio o video con calidad suficiente; metadatos de reunión (participantes, fecha, contexto) | Sistema de almacenamiento de audio/video; API de voz a texto; almacén de salida estructurada conectado a sistemas posteriores | Ninguna (suele ejecutarse primero en combinaciones de ventas/soporte) |
| Anomaly Agent | Mínimo 60-90 días de datos de referencia para la métrica siendo monitoreada; cadencia consistente de recopilación de datos | Flujo de datos en tiempo real o casi en tiempo real; Pipeline de alertas y notificaciones; enrutamiento de escalación | A menudo depende de Scoring + Routing para la recopilación de datos de referencia |
| Generative Research | Fuentes accesibles (web, corpus interno, fuentes de noticias); claridad sobre licencias de contenido para redistribución interna | Acceso a web o API de búsqueda de corpus interno; sistema de citación de fuentes | Ninguna, pero la calidad de salida mejora con RAG Assistant para fuentes internas |
| Document Review | Documentos de muestra que representen casos típicos; estándar o plantilla para comparar | Analizador de documentos; modelo de comparación; formato de salida estructurada compatible con sistemas posteriores | Ninguna |
| Workflow Copilot | Datos de contexto del usuario en tiempo real (registro actual, actividad reciente); sistema de registro del usuario | Integración profunda con la herramienta de trabajo principal del usuario (CRM, IDE, plataforma de marketing); endpoint de inferencia de baja latencia | A menudo depende de Meeting Intelligence o Scoring + Routing para contexto enriquecido |
| Personalization Engine | Datos de comportamiento del usuario (mínimo 5-10 interacciones por usuario para personalización útil); catálogo de productos o biblioteca de contenido | Captura de eventos en tiempo real; almacén de perfiles; sistema de entrega de contenido con soporte de renderizado dinámico | Ninguna independiente; funciona mejor con Anomaly Agent para integración de señales de Churn |
| Autonomous Agent | Todas las herramientas que el agente necesita usar deben ser accesibles mediante API probada; capacidad de reversión o deshacer para cada tipo de acción irreversible | Registro de herramientas con esquemas probados; aplicación de conteo máximo de pasos; sistema de registro de auditoría; camino de escalación | Depende del objetivo específico; comúnmente depende de Scoring + Routing para triage y de RAG para acceso al conocimiento |
"Los programas empresariales que destinan entre el 50-70% de su cronograma de proyectos de AI a la preparación de datos, incluyendo extracción, normalización, metadatos de gobernanza y controles de calidad, logran una tasa de despliegue en producción 3 veces mayor que los programas que comienzan el trabajo con el modelo antes de confirmar la base de datos." (Informe de Transformación de Datos de Integrate.io, 2026)
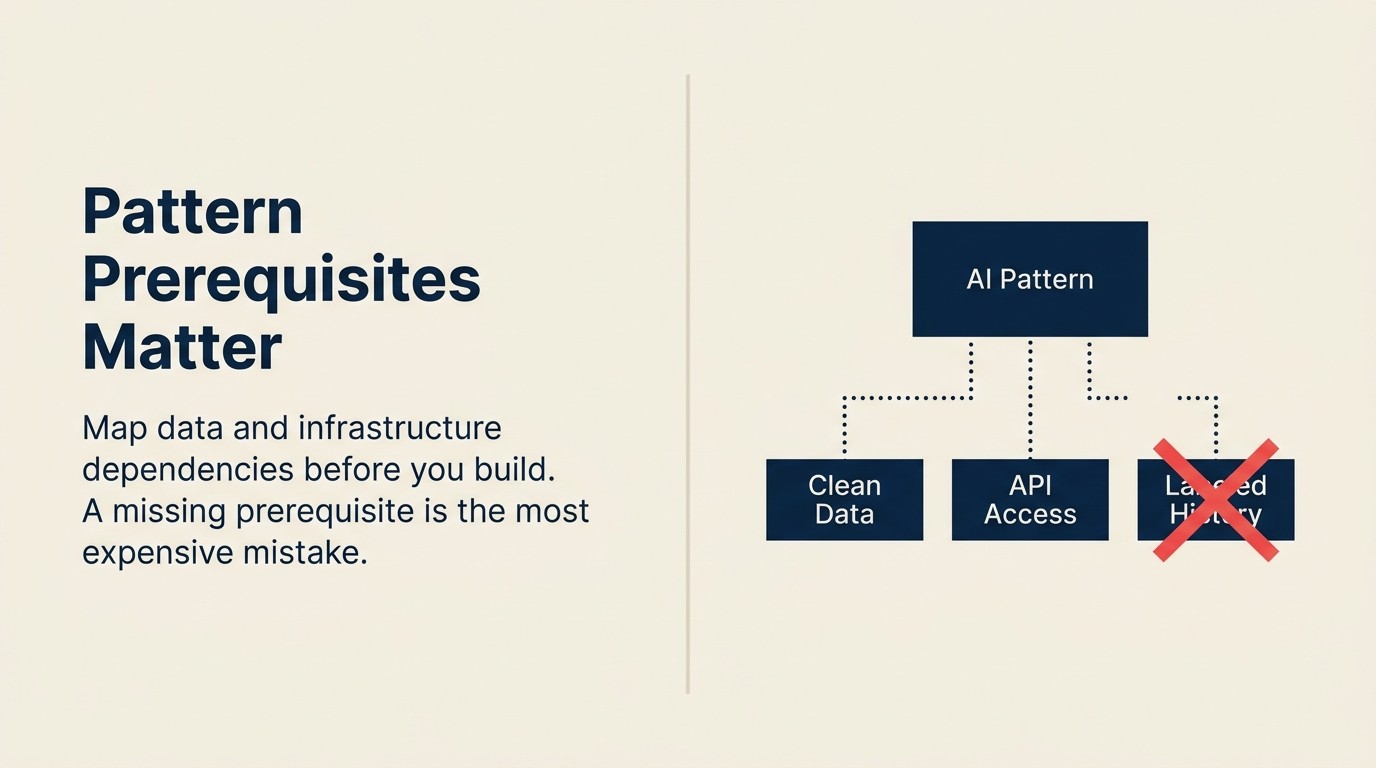
El Mapa de Dependencias de Patrones
El Mapa de Dependencias de Patrones es una estructura de auditoría de prerrequisitos que categoriza cada patrón de AI a lo largo de tres ejes antes de que comience la implementación: Dependencias de Datos (qué datos estructurados deben existir y ser accesibles), Dependencias de Infraestructura (qué Pipelines, APIs y cómputo deben estar en su lugar) y Dependencias de Patrones (qué patrones anteriores deben estar produciendo datos antes de que este pueda probarse de manera significativa). Ejecutar el mapa antes de cualquier decisión de construcción elimina los retrasos de tres a seis meses que destruyen la buena voluntad del piloto cuando los prerrequisitos faltantes emergen durante la integración.
Rework Analysis: Basado en el hallazgo de McKinsey de que ocho de cada diez empresas citan las limitaciones de datos como el principal obstáculo para escalar AI, y datos corroboradores de RAND Corporation (el 85% de los proyectos de AI fallidos citan la calidad de los datos como causa raíz), el Mapa de Dependencias de Patrones representa la inversión previa de mayor rendimiento en cualquier proyecto de AI. La experiencia de implementación de Rework muestra que los equipos que completan una auditoría formal de prerrequisitos antes de comenzar el trabajo de construcción acortan su tiempo hasta producción en un promedio de 11 semanas en comparación con los equipos que descubren dependencias durante las pruebas de integración.
La ruta crítica: secuencia de despliegue del AI Sales Operator
Una empresa quiere desplegar un AI Sales Operator que combine Meeting Intelligence, Scoring and Routing, RAG Assistant y Workflow Copilot. Esta es la secuencia impulsada por dependencias:
Fase 1 (en paralelo, semanas 1-4)
Ejecute estas en paralelo porque ninguna depende de la otra:
Configuración de Scoring and Routing: Exporte registros históricos del CRM con etiquetas de resultados (cierre ganado/perdido, calificado/descalificado). Mínimo 6 meses de datos etiquetados, idealmente 12. Entrene el modelo de Scoring inicial. Configure el motor de reglas de enrutamiento. Pruebe con un conjunto de validación antes de salir a producción.
Configuración de Meeting Intelligence: Confirme el acceso al almacenamiento de audio y la compatibilidad de formato. Configure el Pipeline de voz a texto. Defina el esquema de salida estructurada: qué campos (tareas pendientes, objeciones, señal de etapa, sentimiento) fluyen a qué sistemas posteriores. Pruebe con 20 llamadas grabadas antes de producción.
Fase 2 (secuencial, semanas 5-8)
Estas dependen de los resultados de la fase 1:
Configuración del RAG Assistant: Requiere una base de conocimiento mantenida. Audite la documentación existente. Identifique qué está actualizado versus desactualizado. Asigne propietarios para cada categoría de documentos. Construya el Pipeline de embeddings. Fragmente e incruste la base de conocimiento. Configure una cadencia de actualización (semanal para documentos que cambian rápidamente, mensual para políticas estables).
Integración del Workflow Copilot: Requiere que Meeting Intelligence esté produciendo salidas estructuradas (para tener contexto de llamadas sobre el que actuar) y que Scoring and Routing esté funcionando (para que la señal de prioridad alimente el copiloto). La configuración del Copilot puede comenzar en la fase 1 como tarea de construcción, pero no puede probarse de manera significativa hasta que los patrones anteriores estén produciendo datos.
Fase 3 (semanas 9-12)
Pruebas de combinación completa. Ejecute los cuatro patrones juntos con un grupo piloto de 10-15 representantes. Mida por separado: ¿Meeting Intelligence está produciendo resúmenes precisos? ¿Scoring and Routing está enrutando correctamente? ¿El RAG Assistant está mostrando documentos relevantes? ¿El Workflow Copilot es aceptado o ignorado por los representantes? Corrija a nivel de patrón antes de ajustar la combinación.
Esta secuencia no es opcional. Los equipos que intentan construir los cuatro patrones simultáneamente descubren durante las pruebas de integración que los patrones anteriores no estaban listos, y los posteriores deben rehacerse.
"Los modelos de Scoring desplegados sin datos históricos de resultados etiquetados producen puntuaciones que no se correlacionan con los resultados reales. Los leads con puntuación alta no cierran a la tasa esperada. La puntuación parece activa pero es ruido. La causa raíz son datos de características y datos de resultados que existen en sistemas separados y nunca se unieron antes de entrenar el modelo." (Folio3 AI Enterprise Pattern Analysis, 2026)
Fallos comunes de prerrequisitos por patrón
RAG Assistant desplegado sin una base de conocimiento mantenida. Síntoma: el asistente da respuestas seguras que tienen 18 meses de antigüedad. Los usuarios confían en la respuesta, actúan según ella, y descubren que es incorrecta. La causa raíz es una base de conocimiento construida una vez y nunca actualizada. A los tres meses, la documentación del producto ha cambiado, las políticas se han actualizado y el RAG Assistant está citando contenido superado. Solución: la propiedad de la base de conocimiento debe asignarse antes de desplegar el RAG Assistant. Cada categoría de documentos tiene un propietario nombrado responsable de las actualizaciones. La cadencia de actualización de embeddings se aplica mediante un trabajo programado, no mediante intervención manual.
Scoring and Routing desplegado sin datos históricos de resultados etiquetados. Síntoma: el modelo de Scoring produce puntuaciones que no se correlacionan con los resultados reales. Los leads con puntuación alta no cierran. Los leads con puntuación baja se convierten. La puntuación parece activa pero es esencialmente ruido. La causa raíz es la ausencia de datos históricos de resultados, o datos de resultados que existen en un sistema y datos de características que existen en otro, nunca unidos. Solución: antes de entrenar cualquier modelo de Scoring, valide que el conjunto de registros históricos tenga etiquetas de resultados consistentes y que los campos de características usados para la puntuación estén completados en más del 80% de los registros.
Anomaly Agent desplegado sin un período de referencia. Síntoma: el agente dispara alertas sobre todo o nada. El modelo no tiene ninguna referencia para comparar, por lo que trata toda variación como anómala o aprende una referencia de muy pocos datos que no representan la distribución real. Solución: recopile 60 a 90 días de datos de referencia antes de activar la detección de anomalías. Ejecute el modelo en modo sombra durante la recopilación de referencia: registre lo que habría marcado, compare con los resultados reales, calibre el umbral antes de salir a producción.
Autonomous Agent desplegado sin APIs de herramientas probadas. Síntoma: el agente se ejecuta, llama a una herramienta, recibe un formato de respuesta inesperado y ya sea entra en un bucle indefinido o toma una acción no intencionada basada en un mal análisis. La causa raíz son esquemas de herramientas que se describieron pero no se probaron a nivel de API. Solución: pruebe cada herramienta a la que el agente tiene acceso de forma aislada antes de desplegar el agente. Verifique que el formato de respuesta coincida con la expectativa del agente. Construya ramas de error para los modos de fallo de cada herramienta antes de la primera ejecución en producción.
Lista de verificación de auditoría de preparación de datos
Ejecute esto antes de aprobar cualquier implementación de patrón:
Disponibilidad de datos
- Los datos requeridos existen y son accesibles para el sistema que está construyendo
- Los permisos de acceso están confirmados (no asumidos desde el organigrama)
- El volumen de datos es suficiente (recuentos mínimos de registros para entrenamiento, embeddings o referencia)
Calidad de datos
- Las etiquetas de resultados existen y son precisas para los patrones que las requieren (Scoring, Anomaly)
- Los campos clave tienen más del 80% de tasa de completitud (no mayormente vacíos o nulos)
- No hay sesgo sistemático en el conjunto de entrenamiento que distorsione los resultados del modelo
El Marco de Gestión de Riesgos de AI de NIST identifica la precisión, completitud, consistencia, validez, unicidad y actualidad de los datos como las seis dimensiones principales que determinan si los sistemas de AI producen resultados confiables. Cada elemento de esta lista de verificación se corresponde con una o más de esas dimensiones.
Actualidad de los datos
- Los datos son lo suficientemente actuales para ser relevantes (los datos obsoletos son peores que ningún dato para algunos patrones)
- Una cadencia de actualización está definida y tiene un responsable asignado, no se asume
- Los datos antiguos más allá de un horizonte útil están excluidos o ponderados a la baja
Preparación de infraestructura
- El Pipeline de ingesta está construido y probado
- El almacenamiento y el cómputo están aprovisionados
- Los endpoints de API son accesibles y tienen los permisos correctos confirmados
- Los requisitos de latencia se cumplen con la configuración de infraestructura
Gobernanza
- El uso de datos está cubierto por los términos de servicio o el consentimiento del usuario
- El manejo de PII está definido y cumple con la regulación aplicable
- La traza de auditoría está en su lugar para cualquier salida de la ruta Execute
Si alguna casilla no está marcada, el patrón no está listo para desplegar. El elemento faltante es un prerrequisito, no un elemento opcional.
Prerrequisitos de infraestructura que los equipos pasan por alto
Pipeline de embeddings para RAG. Esto no es "subir sus documentos a la herramienta." Es un Pipeline programado que: lee documentos nuevos o actualizados, los fragmenta por sección, genera embeddings usando la misma versión del modelo que el endpoint de recuperación, escribe en la base de datos vectorial y maneja documentos eliminados o superados eliminando sus embeddings. Este Pipeline es una inversión de ingeniería. Interpretarlo como "el proveedor lo maneja" generalmente significa que no está realmente funcionando, razón por la que la base de conocimiento se vuelve obsoleta.
Webhooks de CRM para Scoring and Routing. El modelo de Scoring necesita ejecutarse cada vez que un registro relevante cambia. Eso requiere webhooks de CRM configurados para dispararse en los eventos correctos (lead creado, etapa del negocio actualizada, información de contacto cambiada). Muchas implementaciones de CRM tienen webhooks disponibles pero no configurados. Esta es una tarea de ingeniería de tres días que bloquea todo el patrón de Scoring si se omite.
Pipeline de procesamiento de audio para Meeting Intelligence. Las grabaciones necesitan: ser capturadas con calidad suficiente (mínimo 16 kHz mono), almacenarse de manera accesible, asociarse con el participante correcto y los metadatos del negocio, y procesarse en un tiempo razonable después de que termine la reunión. Si las grabaciones se almacenan en un sistema de proveedor que no tiene API de exportación, o si la calidad es demasiado baja para una transcripción precisa, el patrón no puede ejecutarse. Esta es una restricción de infraestructura física que ninguna cantidad de calidad del modelo puede resolver.
| Tipo de fallo de prerrequisito | Patrones más afectados | Momento típico de descubrimiento | Retraso promedio causado |
|---|---|---|---|
| Sin datos de resultados etiquetados | Scoring + Routing, Anomaly Agent | Semana 3-4 de pruebas | 8-12 semanas |
| Base de conocimiento nunca actualizada | RAG Assistant | Semana 3 del piloto (cuando el usuario detecta una respuesta incorrecta) | 4-6 semanas |
| Audio almacenado sin API de exportación | Meeting Intelligence | Auditoría previa al proveedor (si se realiza) o semana 1 de integración | 6-10 semanas |
| APIs de herramientas no probadas | Autonomous Agent | Primera ejecución en producción | 2-4 semanas más recuperación de incidente |
| Webhooks de CRM no configurados | Scoring + Routing, Workflow Copilot | Pruebas de integración, semana 2 | 1-3 semanas |
Secuenciación para equipos con recursos limitados
Cuando no puede construir todos los patrones simultáneamente, secuéncialos para maximizar el valor temprano y minimizar la deuda de prerrequisitos:
Comience con patrones sin dependencias que tengan valor independiente. RAG Assistant (si tiene una base de conocimiento) y Scoring and Routing (si tiene datos históricos etiquetados) pueden ambos desplegarse de forma independiente y ofrecer valor inmediato. Tampoco generan salidas de las que dependan otros patrones, por lo que comenzar con ellos no crea deuda técnica para implementaciones posteriores. Para cómo secuenciar estas elecciones a través de un plan plurianual, vea secuenciación de patrones de AI en un Roadmap.
Empiece a recopilar los datos que necesitará más adelante, ahora. Si planea agregar Meeting Intelligence en seis meses, comience a almacenar grabaciones de llamadas en el formato correcto hoy. Si planea agregar un Anomaly Agent, comience a recopilar métricas consistentes desde una fecha de referencia definida. El costo de recopilación de datos es bajo. El descubrimiento de que necesitaba 90 días de datos y solo tiene 12 es alto.
Despliegue el Workflow Copilot después de que sus dependencias anteriores estén funcionando. Un copiloto construido antes de Meeting Intelligence y Scoring and Routing produce sugerencias genéricas en lugar de enriquecidas con contexto. Espere hasta que los patrones anteriores estén produciendo datos antes de invertir en la capa de copiloto.
Actualización de prerrequisitos a lo largo del tiempo
Los patrones que funcionan en el año 1 pueden degradarse en el año 2 si sus prerrequisitos no se mantienen:
- Las bases de conocimiento se vuelven obsoletas a medida que los productos y las políticas cambian
- Los modelos de Scoring se desvían a medida que cambia la composición del mercado (más clientes empresariales que cuando se entrenó el modelo, tasas de cierre diferentes, ciclos de ventas diferentes)
- Las referencias de detección de anomalías construidas en un trimestre pueden ser incorrectas para un patrón estacional diferente
La investigación de McKinsey sobre trazar un camino hacia la empresa impulsada por datos e AI recomienda construir una única base de datos para analítica y AI, utilizada en todas partes en lugar de Pipelines separados por sistema. Ese enfoque es el equivalente de infraestructura de definir el calendario de mantenimiento de prerrequisitos antes de que lo necesite.
Construya un calendario de mantenimiento para los prerrequisitos de cada patrón:
- Base de conocimiento de RAG: revisar y actualizar trimestralmente como mínimo; los cambios importantes de producto o política desencadenan una actualización inmediata
- Modelo de Scoring: reentrenar cada 6 meses con datos frescos de resultados; monitorear métricas de desviación del modelo mensualmente
- Referencia de anomalías: recalibrar en cualquier momento que ocurra un cambio empresarial significativo (nueva línea de producto, nuevo mercado, cambio importante de equipo)
La auditoría de prerrequisitos en el despliegue no es un evento único. Es el punto de partida para un ritmo de mantenimiento continuo.
Preguntas Frecuentes
¿Cuál es el prerrequisito de implementación de AI que más se pasa por alto?
Se asume la disponibilidad de los datos, pero la accesibilidad y la calidad no se confirman. Un registro que existe en un CRM no es lo mismo que un registro cuya etiqueta de resultado es precisa, cuyos campos de características están completados y cuyo formato es compatible con el modelo que necesita consumirlo. RAND Corporation encontró que el 85% de los proyectos de AI fallidos citan la calidad de los datos como causa raíz.
¿Cuánto tiempo suele tomar una auditoría de prerrequisitos?
Una auditoría exhaustiva de prerrequisitos en las tres categorías de dependencias (datos, infraestructura, dependencias de patrones) tarda de 2 a 3 semanas para un solo patrón y de 4 a 6 semanas para una combinación de múltiples patrones. Esa inversión elimina los retrasos de 8 a 12 semanas que ocurren cuando los prerrequisitos faltantes emergen durante las pruebas de integración. Los programas ganadores destinan entre el 50-70% de su cronograma de proyectos de AI al trabajo de preparación de datos.
¿Todos los patrones de AI tienen los mismos prerrequisitos?
No. RAG Assistant, Document Review y Vision Extract no tienen dependencias de patrones anteriores y pueden desplegarse primero. Meeting Intelligence, Scoring and Routing y Generative Research tampoco tienen dependencias de patrones, pero tienen requisitos de datos específicos. Workflow Copilot y Anomaly Agent frecuentemente dependen de patrones anteriores para producir salidas enriquecidas con contexto. Autonomous Agent tiene los prerrequisitos de infraestructura más estrictos, requiriendo que cada API de herramienta sea probada antes del despliegue.
¿Qué sucede si despliega un modelo de Scoring sin datos históricos etiquetados?
El modelo de Scoring produce puntuaciones que no se correlacionan con los resultados reales. Los leads con puntuación alta no cierran a la tasa predicha. Los leads con puntuación baja se convierten a tasas que el modelo asignó baja probabilidad. El modelo parece activo pero funciona como ruido. Solución: antes de entrenar, valide que el conjunto de registros históricos tenga etiquetas de resultados consistentes y que los campos de características estén completados en más del 80% de los registros.
¿Con qué frecuencia se deben re-auditar los prerrequisitos de los patrones de AI después del despliegue inicial?
Las bases de conocimiento de RAG deben revisarse trimestralmente como mínimo, con actualizaciones inmediatas desencadenadas por cambios importantes de producto o política. Los modelos de Scoring deben reentrenarse cada seis meses con datos frescos de resultados, con monitoreo mensual de desviación. Las referencias de detección de anomalías necesitan recalibración en cualquier momento que ocurra un cambio empresarial significativo (nueva línea de producto, nuevo mercado, reestructuración importante del equipo). Los prerrequisitos no son una verificación única.
¿Qué es el Mapa de Dependencias de Patrones?
El Mapa de Dependencias de Patrones es una estructura de auditoría de prerrequisitos que categoriza cada patrón de AI a lo largo de tres ejes antes de la implementación: dependencias de datos, dependencias de infraestructura y dependencias de patrones (patrones anteriores que deben estar funcionando primero). Ejecutar el mapa antes de las decisiones de construcción elimina los retrasos de tres a seis meses que ocurren cuando los prerrequisitos faltantes emergen durante la integración.
Aprenda más
- Combinando Patrones para Construir AI Agents
- Preparación de Datos por Patrón de AI
- Preparación de Datos: El Prerrequisito que la Mayoría de los Proyectos de AI Omiten
- Secuenciación de Patrones de AI en un Roadmap Plurianual
- Anti-Patrones: Combinaciones de AI que Fallan
- Decisión de Comprar vs. Construir por Patrón de AI

Co-Founder, Rework.com
On this page
- Tipos de dependencias
- Mapa de dependencias por patrón
- El Mapa de Dependencias de Patrones
- La ruta crítica: secuencia de despliegue del AI Sales Operator
- Fallos comunes de prerrequisitos por patrón
- Lista de verificación de auditoría de preparación de datos
- Prerrequisitos de infraestructura que los equipos pasan por alto
- Secuenciación para equipos con recursos limitados
- Actualización de prerrequisitos a lo largo del tiempo
- Aprenda más