Kecerunan Risiko Merentasi AI Patterns

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Setiap rangka kerja tadbir urus AI akhirnya melakukan kesilapan yang sama: menganggap semua AI sama berbahaya.
Hasilnya boleh dijangka. Pasukan tadbir urus menulis polisi menyeluruh yang menerapkan proses kelulusan yang sama, kitaran semakan yang sama, dan tahap sekatan yang sama kepada chatbot yang menjawab soalan polisi HR dan kepada agen yang boleh mengeluarkan bayaran balik dalam Stripe. Chatbot HR mati dalam kitaran semakan enam bulan. Agen bayaran balik dihantar dengan kawalan yang lemah kerana tiada yang membezakannya daripada chatbot.
Kedua-dua hasil itu adalah buruk. Mentadbir berlebihan patterns berisiko rendah membunuh penggunaan dan menjadikan pasukan AI bekerja mengelak proses tadbir urus. Mentadbir kurang patterns berisiko tinggi menyebabkan insiden yang menjadi tajuk berita.
Penyelesaiannya adalah tadbir urus berkadar: padankan kawalan Anda kepada tahap risiko sebenar setiap pattern, bukan kepada rasa generik "AI adalah berisiko." Ia bermula dengan memahami di mana setiap pattern berada pada kecerunan risiko. Rangka Kerja Pengurusan Risiko AI NIST mengesyorkan pendekatan ini dengan tepat, mentadbir, memetakan, mengukur, dan menguruskan risiko AI dalam konteks, berskala kepada kes penggunaan yang khusus dan akibat yang berpotensi. Jika Anda masih membiasakan diri dengan 10 patterns teras, mulakan dengan apakah AI pattern terlebih dahulu.
Apa yang mendorong risiko dalam AI patterns
Tiga faktor menentukan tahap risiko asas sesebuah pattern.
Kebolehbalikan tindakan Execute. Patterns yang tidak menyertakan langkah Execute membawa risiko paling rendah: jika AI salah, tiada apa yang berubah di dunia luar. Manusia membaca keluaran dan memutuskan sama ada hendak bertindak. Patterns yang Execute membawa risiko berkadar dengan betapa sukarnya untuk membatalkan tindakan. Mengemas kini medan CRM mudah dibalikkan. Menghantar e-mel kepada pelanggan lebih sukar dibalikkan (Anda boleh menghantar pembetulan, tetapi Anda tidak boleh membatalkan penghantaran). Mengeluarkan bayaran balik, membuat pesanan, atau menyekat transaksi berada pada kos kebolehbalikan tertinggi.
Taksonomi Risiko AI Gartner 2025 menilai ketidakbolehbalikan sebagai pengganda risiko tunggal tertinggi dalam rangka kerja tadbir urus AI, mendahului kepekaan data dan pendedahan kawal selia, kerana ralat tidak boleh balik berskala lebih cepat dan menentang pembetulan setelah gelung Execute berjalan pada volum.
Penentukuran keyakinan keluaran Predict. Patterns yang bergantung pada Predict untuk mendorong penghalaan atau keputusan membawa risiko berkadar dengan seberapa baik keyakinan model ditentukur. Model pemarkahan lead yang berkata "kebarangkalian penukaran 82%" sepatutnya salah kira-kira 18% masa apabila ia memberi skor lead pada 82%. Jika penentukuran model tidak betul (secara konsisten terlalu yakin atau kurang yakin), setiap keputusan penghalaan hiliran berdasarkan skor itu merosot. Keyakinan yang salah penentukuran tidak kelihatan sehingga Anda mengaudit hasil berbanding ramalan.
Penempatan manusia dalam gelung. Risiko adalah lebih rendah apabila pintu semakan manusia berada antara Generate dan Execute. Ia lebih tinggi apabila Execute berlaku secara automatik berdasarkan ambang atau peraturan. Dan ia paling tinggi apabila Execute berada dalam gelung, berjalan beberapa kali per matlamat, di mana kesilapan awal berganda melalui langkah kemudian. Sempadan Generate vs. Execute adalah keputusan reka bentuk kritikal untuk mana-mana pattern yang menyertakan Execute.
Doktrin Kecerunan Risiko
Tadbir urus AI harus berkadar dengan kebolehbalikan dan autonomi langkah Execute setiap pattern, bukan seragam merentasi semua sistem AI. Pattern yang membaca dan menjana (Peringkat 1) memerlukan log audit dan latihan pengguna, bukan pintu kelulusan. Pattern yang melaksanakan secara autonomi dalam gelung (Peringkat 4) memerlukan sempadan skop, had kadar, keupayaan rollback, dan penyeliaan manusia pada pelancaraan. Menggunakan tadbir urus Peringkat 4 kepada patterns Peringkat 1 membunuh penggunaan tanpa mengurangkan risiko. Menggunakan tadbir urus Peringkat 1 kepada patterns Peringkat 4 adalah punca langsung insiden AI yang menjadi tajuk berita.
Key Facts: Risiko AI dan Tadbir Urus
- 80% organisasi telah menghadapi tingkah laku berisiko atau tidak dijangka daripada AI agents, dengan hampir setiap insiden dapat dikesan kepada langkah Execute yang berlaku tanpa pengesahan hulu yang mencukupi (McKinsey, 2025)
- Organisasi yang menggunakan tadbir urus seragam merentasi semua AI patterns menghabiskan 3x lebih banyak untuk overhead pematuhan berbanding mereka yang menggunakan kawalan berkadar risiko bertingkat, sambil mencapai hasil keselamatan yang lebih rendah (Deloitte AI Governance Report, 2025)
- Insiden AI yang mengakibatkan kerugian perniagaan yang boleh diukur adalah 4.7x lebih berkemungkinan melibatkan patterns Execute autonomi atau automatik berbanding patterns Generate baca sahaja (Forrester AI Incident Analysis, 2025)
Spektrum risiko: empat peringkat

Peringkat 1: Baca sahaja, tiada Execute
Patterns: RAG Assistant, Generative Research, Document Review
Patterns ini Ingest, Analyze, Generate, dan berhenti. Tiada apa yang berubah di dunia luar. Keluaran adalah artifak teks (jawapan, laporan, set bendera) yang manusia baca, nilai, dan bertindak atasnya. Jika AI salah, manusia menangkapnya sebelum apa-apa dilakukan.
RAG Assistant menghasilkan jawapan daripada pangkalan pengetahuan. Jika ia mengambil semula petikan yang salah dan menghasilkan jawapan yang tidak betul, manusia yang bertanya soalan membaca jawapan yang salah. Itu adalah masalah. Tetapi ia adalah masalah yang terkandung: satu orang mendapat maklumat yang buruk. Mereka mungkin bertindak atasnya, atau mereka mungkin menyedari ia salah dan mengesahkan.
Generative Research mensintesis laporan daripada pelbagai sumber. Jika ia tersalah atribut petikan atau membuat kesimpulan yang tidak betul, pembaca mendapat laporan yang cacat. Risiko berskala dengan seberapa banyak pembaca mempercayai dan bertindak atas keluaran tanpa pengesahan.
Document Review menandakan risiko dalam kontrak atau polisi. Jika ia terlepas klausa yang tidak standard, pasukan undang-undang mungkin tidak menangkapnya. Risiko itu adalah nyata, tetapi ia adalah risiko ketinggalan (bendera yang terlepas), bukan tindakan yang salah (tindakan salah yang diambil oleh AI).
Risiko asas: Rendah. Kawalan utama adalah jaminan kualiti, bukan pintu tadbir urus. Latih pengguna untuk mengesahkan keluaran penting, terutamanya untuk dokumen berisiko tinggi dalam Document Review. Kekalkan log audit pertanyaan dan keluaran.
Peringkat 2: Execute dengan kelulusan manusia
Patterns: Workflow Copilot, Meeting Intelligence, Vision Extract
Patterns ini menyertakan Execute, tetapi dengan pintu kelulusan manusia yang berada antara Generate dan Execute dalam pelaksanaan standard.
Workflow Copilot mengarang draf e-mel atau kemas kini CRM. Manusia menyemak draf dan klik hantar. Execute berlaku hanya selepas kelulusan manusia. Risiko ada pada apa yang berlaku apabila Anda membuang pintu kelulusan itu (yang merupakan perkara pertama yang dilakukan pasukan apabila mereka memutuskan AI sudah "cukup baik untuk dipercayai"). Membuang pintu mengubah pattern Peringkat 2 kepada sesuatu yang lebih hampir kepada Peringkat 3.
Meeting Intelligence menghasilkan ringkasan panggilan dan nota CRM, sering dengan langkah semakan wakil sebelum ditolak. Dalam sesetengah pelaksanaan, penolakan ke CRM adalah automatik. Apabila automatik, ringkasan yang buruk menjadi rekod CRM yang buruk, yang mempengaruhi pelaporan pipeline, ketepatan ramalan, dan kualiti bimbingan. Itu adalah hasil risiko sederhana.
Vision Extract menolak rekod berstruktur ke sistem rekod. Dalam kebanyakan pelaksanaan, manusia menyemak sampel rekod sebelum dilakukan. Apabila pemeriksaan sampel dibuang (sering atas sebab kos), ralat pengekstrakan menjadi ralat pangkalan data.
Risiko asas: Sederhana-rendah. Kawalan tadbir urus teras adalah mengekalkan pintu semakan manusia dan mengaudit apa yang berlaku apabila Anda membuangnya. Takrifkan pengendalian pengecualian: apa yang dilakukan sistem dengan rekod yang tidak dapat diekstrak dengan yakin? Halakan ke semakan manual, bukan auto-commit dengan keyakinan rendah.
Peringkat 3: Execute dengan peraturan (tiada kelulusan manusia per tindakan)
Patterns: Scoring plus Routing, Anomaly Agent, Personalization Engine
Patterns ini Execute secara automatik berdasarkan ambang, peraturan, atau keluaran model. Tiada manusia yang meluluskan setiap tindakan individu. Lead yang mendapat skor melebihi 80 secara automatik dihalakan ke pasukan enterprise. Transaksi yang diberi skor sebagai anomali secara automatik ditandakan atau disekat. Sejarah tingkah laku pengguna mencetuskan cadangan produk yang diperibadikan. Tindakan berlaku pada volum, secara berterusan, tanpa manusia dalam gelung pada setiap satu.
Cabaran tadbir urus: kawalan adalah di hulu (penentukuran model, tetapan ambang, baris gilir pengecualian) bukan pada titik tindakan. Jika model pemarkahan lead salah penentukuran, 20% pipeline hasil Anda dihalakan ke pasukan yang salah, dan Anda tidak akan melihatnya sehingga Anda mengaudit hasil. Jika garis asas anomaly agent adalah salah, Anda sama ada menyekat pelanggan yang sah atau terlepas penipuan sebenar. Tiada satu pun kesilapan kelihatan dalam masa nyata tanpa pemantauan.
Risiko asas: Sederhana-tinggi. Keperluan tadbir urus: ambang keyakinan yang ditakrifkan dengan baris gilir semakan manusia untuk kes tepi, audit model tetap yang membandingkan ramalan dengan hasil, prosedur rollback untuk perubahan peraturan, dan pengendalian pengecualian yang didokumentasikan untuk item yang jatuh di bawah ambang keyakinan. Jangan tetapkan ambang dan lupakannya. Semak semula ambang setiap suku tahun berdasarkan data hasil.
Peringkat 4: Execute dalam gelung, autonomi tinggi
Pattern: Autonomous Agent
Autonomous Agent menggunakan semua lima keupayaan dalam gelung, mengejar matlamat merentasi pelbagai langkah dan pelbagai sistem. Setiap iterasi gelung boleh menyertakan tindakan Execute. Kesilapan dalam langkah awal (Analyze yang salah, Predict yang salah penentukuran) merebak melalui setiap tindakan Execute seterusnya dalam gelung. Dan gelung berjalan lagi, dan lagi, sehingga matlamat dipenuhi atau agen memutuskan ia tidak dapat meneruskan.
Ini secara kategori berbeza daripada peringkat lain. Workflow Copilot melaksanakan sekali, dengan manusia menyemak draf. Autonomous Agent mungkin melaksanakan 15 kali semasa menyelesaikan tugasan penyelidikan-dan-jangkauan, tanpa manusia menyemak langkah 2 hingga 14.
Senario yang menyebabkan kerosakan sebenar: agen yang menyelidik prospek dan menghantar e-mel jangkauan pada skala, mendapat pemetaan akaun yang salah dan menghantar mesej yang tidak sesuai kepada syarikat yang salah. Agen yang menguruskan permintaan bayaran balik dan mengeluarkan bayaran balik berdasarkan peraturan padanan yang cacat. Agen yang memperhitungkan masa kalendar dan mencipta tugasan CRM, berjalan melalui senarai 300 kenalan, mendapat integrasi kalendar yang salah, dan mencipta bunyi bising merentasi jadual seluruh pasukan. McKinsey melaporkan bahawa 80% organisasi telah menghadapi tingkah laku berisiko daripada AI agents, dan patterns di atas mewakili dengan tepat mod kegagalan yang muncul dalam insiden tersebut.
Risiko asas: Tinggi. Tadbir urus yang diperlukan: sempadan skop yang eksplisit (sistem apa yang boleh disentuh agen, tindakan apa yang boleh diambilnya), had kadar pada tindakan Execute (tidak lebih daripada X e-mel per jam, tidak lebih daripada $Y dalam bayaran balik sehari tanpa semakan manusia), keupayaan rollback untuk tindakan yang telah dilaksanakan, dan manusia dalam gelung semasa perlancaran pengeluaran pertama sebelum diskala. Had kadar adalah kawalan yang paling diabaikan: ia mengubah kemungkinan kesilapan massa menjadi kesilapan yang terkandung dan boleh diperbetulkan.
Semua 10 patterns pada kecerunan
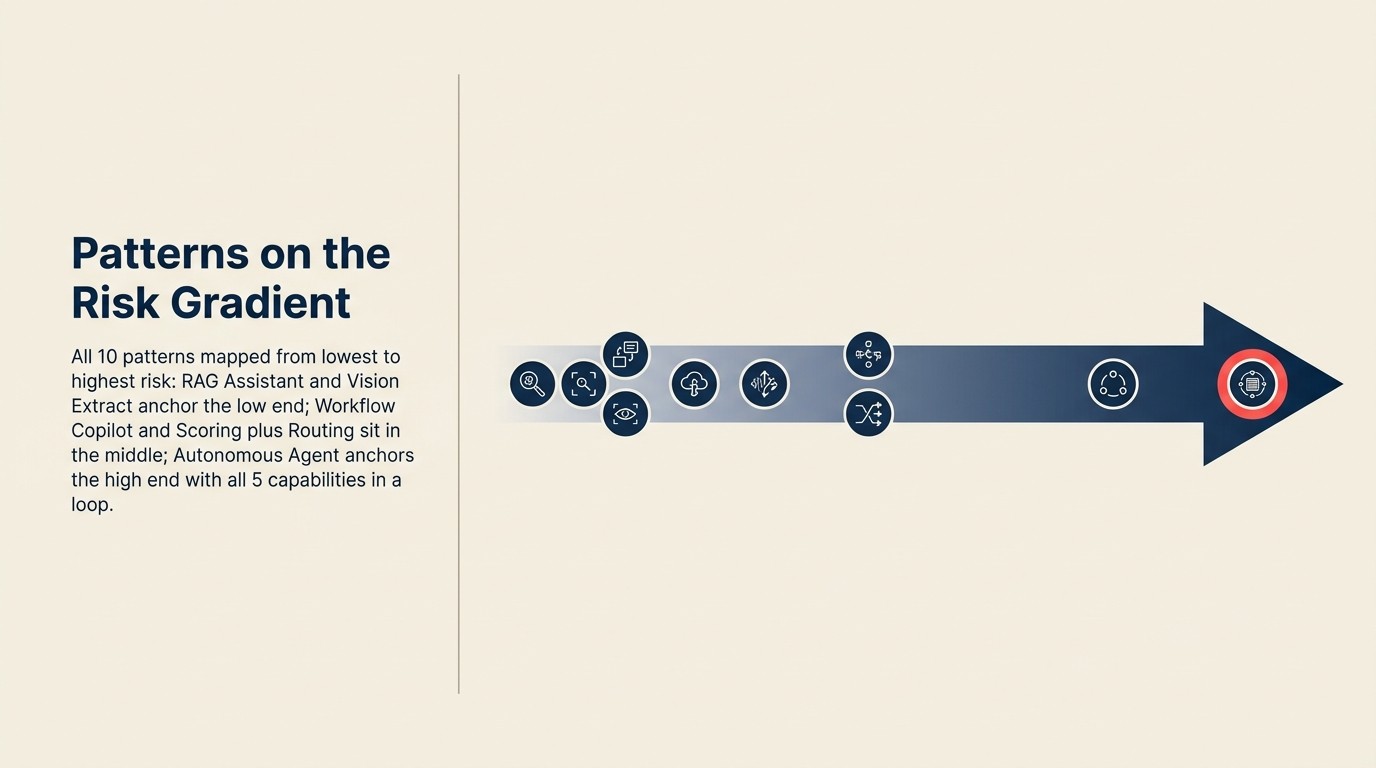
| Pattern | Peringkat Risiko | Execute? | Pintu manusia? | Risiko utama |
|---|---|---|---|---|
| RAG Assistant | Peringkat 1 (Rendah) | Tidak | T/B | Jawapan yang salah atau lapuk |
| Generative Research | Peringkat 1 (Rendah) | Tidak | T/B | Sintesis yang tidak betul, sumber yang tersalah atribut |
| Document Review | Peringkat 1 (Rendah) | Tidak | T/B | Bendera yang terlepas (risiko ketinggalan) |
| Workflow Copilot | Peringkat 2 (Sederhana-rendah) | Ya, berpintu manusia | Semak sebelum Execute | Pembuangan pintu; draf buruk yang dilakukan |
| Meeting Intelligence | Peringkat 2 (Sederhana-rendah) | Ya, sering berpintu manusia | Semak sebelum tolak | Nota tidak tepat dalam sistem rekod |
| Vision Extract | Peringkat 2 (Sederhana-rendah) | Ya, berpintu manusia | Pemeriksaan sampel sebelum commit | Ralat pengekstrakan dalam pangkalan data |
| Scoring plus Routing | Peringkat 3 (Sederhana-tinggi) | Ya, automatik | Ambang + baris gilir pengecualian | Model salah penentukuran yang menghalakan pada skala |
| Anomaly Agent | Peringkat 3 (Sederhana-tinggi) | Ya, automatik | Ambang + baris gilir pengecualian | Garis asas yang salah; positif palsu atau makluman yang terlepas |
| Personalization Engine | Peringkat 3 (Sederhana-tinggi) | Ya, automatik | Ambang + pemantauan | Personalisasi diskriminasi; pendedahan harga |
| Autonomous Agent | Peringkat 4 (Tinggi) | Ya, bergelung | Had kadar + penyeliaan awal | Ralat yang berganda merentasi langkah Execute |
Cara konteks domain menggandakan risiko
Peringkat di atas mewakili risiko asas. Konteks domain adalah pengganda.
Pattern Vision Extract yang memproses kad perniagaan ke dalam CRM adalah risiko asas Peringkat 2. Medan yang salah (nombor telefon tersilap satu digit, nama syarikat tersalah eja) adalah isu kualiti data yang menjengkelkan. Boleh dibaiki.
Pattern Vision Extract yang sama membaca borang pengambilan pesakit dan mengemas kini sistem rekod perubatan adalah masalah tadbir urus Peringkat 3. Nilai medan yang salah (ubatan yang salah, alergi yang salah, dos yang salah) dalam rekod pesakit boleh mempengaruhi keputusan klinikal. Formula keupayaan yang sama, domain yang berbeza, peringkat risiko yang berbeza.
Pattern Scoring plus Routing yang menghalakan lead jualan masuk adalah risiko asas Peringkat 3. Model yang salah penentukuran menghalakan beberapa lead ke pasukan yang salah. Impak hasil, menjengkelkan, boleh diaudit.
Pattern Scoring plus Routing yang sama yang diterapkan kepada permohonan kredit adalah masalah tadbir urus Peringkat 4 dalam pasaran yang dikawal selia. ECOA, Akta Perumahan Adil, dan GDPR Artikel 22 memerlukan kejelasan dan hak semakan manusia untuk keputusan yang didorong AI yang mempengaruhi akses kepada kredit. Pendedahan kawal selia menukar masalah teknikal Peringkat 3 kepada masalah undang-undang Peringkat 4.
Laraskan setiap peringkat pattern ke atas apabila: keluaran mempengaruhi keputusan yang dikawal selia (kredit, pekerjaan, perumahan, penjagaan kesihatan), data melibatkan maklumat peribadi yang sensitif, tindakan Execute adalah kewangan atau mempunyai akibat undang-undang, atau skala tindakan automatik menjadikan kesilapan sukar untuk dikesan sebelum berganda.
Anggaran risiko yang biasa rendah mengikut pattern
Scoring plus Routing terasa selamat kerana ia "hanya menghalakan perkara." Keputusan penghalaan pada skala adalah keputusan hasil. Jika model pemarkahan lead Anda salah tentang lead mana yang merupakan keutamaan tinggi, wakil terbaik Anda bekerja pada akaun yang salah. Jika penghalaan tiket sokongan Anda tersalah klasifikasikan kemendesakan, pelanggan enterprise menunggu dalam baris gilir standard. Ini bukan risiko abstrak. Mereka boleh diukur: semak pengagihan aktiviti wakil Anda, kadar pelanggaran SLA Anda, dan ketepatan penghalaan Anda setiap bulan.
Personalization Engine terasa tidak berbahaya kerana ia hanya "menunjukkan kandungan yang relevan." Penentuan harga yang diperibadikan (menunjukkan harga yang berbeza kepada pengguna yang berbeza) boleh mencipta pendedahan undang-undang di bawah undang-undang perlindungan pengguna di beberapa bidang kuasa, terutamanya apabila personalisasi berkorelasi dengan ciri-ciri yang dilindungi. Iklan kerja yang diperibadikan yang mengecualikan kumpulan demografik tertentu berdasarkan sasaran tingkah laku telah menjadi subjek siasatan EEOC dan EU. "Kami hanya mempersonalisasikan kandungan" bukan jawapan tadbir urus.
Workflow Copilot kelihatan berisiko rendah kerana manusia menyemak segalanya. Sehingga manusia berhenti menyemak. Pintu semakan adalah keseluruhan struktur tadbir urus untuk pattern ini. Apabila pasukan memutuskan AI sudah "cukup baik" dan membuang langkah semakan, mereka baru sahaja menggunakan Execute automatik tanpa kawalan tadbir urus Peringkat 3. Peralihan harus disengajakan dan didokumentasikan, bukan perubahan proses yang senyap.
Keperluan tadbir urus mengikut peringkat

Peringkat 1: Log audit pertanyaan dan keluaran. Proses semakan kualiti (pensampelan berkala keluaran oleh penyemak manusia). Latihan pengguna tentang jangkaan pengesahan (kes penggunaan berisiko tinggi memerlukan pengesahan bebas). Tiada pintu kelulusan diperlukan untuk penggunaan standard.
Peringkat 2: Kekalkan pintu semakan manusia sebagai polisi eksplisit. Dokumentasikan aliran kerja mana yang mempunyai auto-commit diaktifkan berbanding semakan-diperlukan. Kadar pemeriksaan sampel untuk rekod auto-committed. Penghalaan pengecualian untuk keluaran berkeyakinan rendah.
Peringkat 3: Pemantauan ketepatan model dengan audit hasil berkala (bandingkan ramalan dengan hasil sebenar). Ambang keyakinan dengan baris gilir pengecualian untuk item di bawah ambang. Semakan ambang suku tahunan berdasarkan data hasil. Dokumentasi peraturan penghalaan dan laluan eskalasi. Makluman penyimpangan model.
Peringkat 4: Sempadan skop eksplisit yang didokumentasikan dan dikuatkuasakan pada peringkat sistem (bukan hanya polisi). Had kadar pada tindakan Execute. Keupayaan rollback untuk membalikkan tindakan yang telah dilaksanakan. Penyeliaan manusia diperlukan untuk perlancaran pengeluaran pertama. Pelancaran berperingkat (mulakan dengan akaun atau kes penggunaan berisiko rendah sebelum diskala). Pelan tindak balas insiden untuk apabila agen mengambil tindakan yang salah pada skala.
Membina daftar risiko Anda
Daftar risiko untuk AI patterns yang aktif tidak perlu kompleks. Untuk setiap pattern yang sedang dalam pengeluaran, dokumentasikan:
- Nama pattern dan kes penggunaan khusus (contohnya, "Scoring plus Routing untuk tugasan lead masuk")
- Peringkat risiko (1-4)
- Pengganda domain (data yang dikawal selia? akibat kewangan? data peribadi yang sensitif?)
- Pemilik (siapa yang bertanggungjawab memantau ketepatan dan tadbir urus pattern ini)
- Kekerapan semakan (Peringkat 1: tahunan; Peringkat 2: suku tahunan; Peringkat 3: bulanan; Peringkat 4: mingguan sehingga stabil)
- Kawalan semasa (apa yang sebenarnya ada)
- Jurang yang diketahui (apa yang sepatutnya ada tetapi tiada)
Daftar itu adalah dokumen yang hidup. Semasa Anda menambah patterns, melaraskan domain, atau mengubah konfigurasi, kemas kininya. Tujuannya bukan kesempurnaan: ia adalah bahawa seseorang memiliki postur risiko setiap pattern dan menyemaknya mengikut jadual.
Rework Analysis: Kesilapan tadbir urus yang paling kerap kami lihat adalah organisasi yang menulis satu polisi AI yang terpakai secara seragam kepada semua sistem AI. Polisi itu akhirnya ditentukur kepada pattern paling berbahaya dalam pengeluaran (sering kali agen autonomi atau sistem penghalaan automatik) dan diterapkan kepada segalanya. Hasilnya: RAG Assistants berisiko rendah tersekat dalam semakan keselamatan enam bulan sementara Autonomous Agents berisiko tinggi sebenar yang dihantar hanya mempunyai semakan kotak semak. Tadbir urus bertingkat, disesuaikan dengan profil Execute sebenar setiap pattern, menghabiskan lebih sedikit dan mengawal lebih banyak berbanding polisi AI menyeluruh. Model empat peringkat di atas memberi pasukan risiko dan pematuhan perbendaharaan kata untuk menulis peraturan berkadar berbanding peraturan menyeluruh.
Soalan Lazim
Apakah kecerunan risiko merentasi AI patterns?
Kecerunan risiko menempatkan AI patterns dari Peringkat 1 (baca sahaja, tiada Execute) hingga Peringkat 4 (gelung autonomi dengan langkah Execute berulang). Patterns Peringkat 1 seperti RAG Assistant dan Generative Research membawa risiko rendah kerana AI menghasilkan keluaran teks yang manusia bertindak atasnya. Patterns Peringkat 4 seperti Autonomous Agent membawa risiko tinggi kerana Execute berlaku beberapa kali per matlamat tanpa semakan manusia, dan ralat berganda merentasi langkah.
Apa yang menjadikan AI pattern berisiko tinggi?
Tiga faktor mendorong risiko AI pattern: ketidakbolehbalikan tindakan Execute (betapa sukarnya untuk membatalkan apa yang AI lakukan), penentukuran keyakinan keluaran Predict (sama ada skor mencerminkan kebarangkalian sebenar dengan tepat), dan penempatan manusia dalam gelung (sama ada manusia menyemak keluaran sebelum Execute berlaku). Analisis Insiden AI Forrester 2025 mendapati insiden AI yang melibatkan patterns Execute adalah 4.7x lebih berkemungkinan menyebabkan kerugian perniagaan yang boleh diukur berbanding insiden yang melibatkan patterns Generate baca sahaja.
Bagaimana tadbir urus harus berskala merentasi peringkat risiko AI pattern?
Patterns Peringkat 1 memerlukan log audit dan latihan pengguna tentang jangkaan pengesahan. Patterns Peringkat 2 memerlukan pintu semakan manusia yang dikekalkan dan penghalaan pengecualian untuk keluaran berkeyakinan rendah. Patterns Peringkat 3 memerlukan pemantauan ketepatan model, ambang keyakinan dengan baris gilir pengecualian, dan audit hasil suku tahunan. Patterns Peringkat 4 memerlukan sempadan skop, had kadar pada tindakan Execute, keupayaan rollback, dan penyeliaan manusia semasa perlancaran pengeluaran awal.
Mengapa pattern Workflow Copilot berisiko lebih rendah berbanding Scoring plus Routing?
Workflow Copilot menyertakan pintu kelulusan manusia yang eksplisit antara Generate dan Execute: AI mengarang draf, manusia meluluskan sebelum apa-apa dihantar atau dilakukan. Scoring plus Routing Execute secara automatik pada skala berdasarkan skor model, tanpa semakan manusia per tindakan. Risiko dalam Workflow Copilot berskala dengan pembuangan pintu. Risiko dalam Scoring plus Routing berskala dengan salah penentukuran model, yang tidak kelihatan sehingga Anda mengaudit hasil.
Apakah Doktrin Kecerunan Risiko?
Doktrin Kecerunan Risiko menyatakan bahawa tadbir urus AI mesti berkadar dengan kebolehbalikan dan autonomi langkah Execute setiap pattern, bukan seragam merentasi semua sistem AI. Menggunakan kawalan yang sama kepada RAG Assistant baca sahaja dan Autonomous Agent secara serentak mentadbir berlebihan sistem berisiko rendah dan mentadbir kurang yang berisiko tinggi. Tadbir urus bertingkat yang disesuaikan dengan profil Execute sebenar setiap pattern menghabiskan lebih sedikit dan mengawal lebih banyak berbanding polisi AI menyeluruh.
Adakah konteks domain mempengaruhi peringkat risiko sesebuah pattern?
Ya. Konteks domain adalah pengganda ke atas risiko asas. Vision Extract yang memproses kad perniagaan adalah risiko asas Peringkat 2. Pattern yang sama mengemas kini rekod perubatan yang mengandungi data alergi atau ubatan adalah masalah tadbir urus Peringkat 4 kerana ralat secara langsung mempengaruhi keputusan klinikal. Begitu juga, Scoring plus Routing untuk tugasan lead adalah Peringkat 3, tetapi pattern yang sama yang diterapkan kepada keputusan kredit mencetuskan kewajipan kawal selia di bawah ECOA dan GDPR Artikel 22 yang menolaknya ke Peringkat 4.
Ketahui lebih lanjut
- Keperluan Tadbir Urus mengikut AI Pattern
- Risiko Halusinasi mengikut AI Pattern
- Autonomous Agent: Matlamat Berbilang Langkah Dengan Penggunaan Alat
- Memilih AI Pattern yang Betul untuk Masalah Anda
- Sempadan Generate vs. Execute: Mengapa Pagar Penting
- Pattern Meeting Intelligence
- Mengukur ROI AI Pattern

Co-Founder, Rework.com
On this page
- Apa yang mendorong risiko dalam AI patterns
- Doktrin Kecerunan Risiko
- Spektrum risiko: empat peringkat
- Peringkat 1: Baca sahaja, tiada Execute
- Peringkat 2: Execute dengan kelulusan manusia
- Peringkat 3: Execute dengan peraturan (tiada kelulusan manusia per tindakan)
- Peringkat 4: Execute dalam gelung, autonomi tinggi
- Semua 10 patterns pada kecerunan
- Cara konteks domain menggandakan risiko
- Anggaran risiko yang biasa rendah mengikut pattern
- Keperluan tadbir urus mengikut peringkat
- Membina daftar risiko Anda
- Ketahui lebih lanjut