Competitor Battlecards Generated With AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Most battlecards are outdated within 60 days of being written.
The competitor ships a new integration in March. Their pricing page changes in April. They win a marquee customer in your top vertical in May. They hire a new VP of Product who comes from a company your buyers respect. None of that shows up in the battlecard your product marketing team wrote in January.
And the account executive (AE) on a competitive deal in June goes in with stale intel. Against a buyer who did their own research last week.
This isn't a failure of the product marketing team. It's a failure of the update model. Quarterly manual competitive intelligence reviews can't keep pace with the rate at which markets change. AI-generated battlecards can, if you build them with the right architecture.
The key capability is not initial generation. It's change detection and continuous refresh. Any competent analyst can write a battlecard once. AI earns its place in the competitive intelligence workflow by keeping it current. This is the Generative Research pattern applied to competitive intelligence: Ingest live signals, Analyze for meaningful changes, Generate updated sections automatically. Harvard Business Review's research on win/loss analysis confirms that competitive deal outcomes depend far more on execution quality and current positioning than on static product comparisons.
What a good battlecard actually contains
Key Facts: Competitive Intelligence and Sales Win Rates
- Sales reps using regularly updated battlecards win 23% more competitive deals than those without current competitive materials, according to Gartner's 2025 Sales Enablement Benchmark.
- 68% of B2B deals now involve at least one direct competitor, making competitive readiness a standard requirement, not an edge case. (Crayon, 2025)
- 65% of mid-market SaaS sales reps report that their battlecards are outdated or irrelevant when they need them in a deal. (Seismic, 2025)
Before discussing how AI generates and updates battlecards, it's worth being precise about what a useful battlecard covers. Bad battlecards are either too promotional (we're better in every way) or too general (they're a leading vendor in this space). Neither helps a rep in a deal.

Feature comparison. An honest, specific table of where your product is stronger, where they're stronger, and where capabilities are comparable. Not a marketing-favorable version. Reps see through that, buyers definitely see through that, and it destroys trust in the whole document if one section is clearly spin.
Messaging counter-plays. When the buyer says "the other vendor told us they handle X with their Y feature," here is the accurate response. Specific language the rep can use, not a generic "our approach is different."
Pricing comparison. What they charge, at what tier, for what seat count, with what add-ons. This is the most volatile section, which is why AI refresh matters most here. Pricing changes happen without announcements.
Recent wins and losses by segment. Where are they winning? What company types, sizes, use cases? Where are you winning against them? Pattern recognition across deal outcomes is more useful than theoretical positioning. This feeds directly from your win/loss analysis data, which meeting intelligence tools can systematically surface.
Key objections and proven responses. The specific objections that come up in competitive deals, mapped to responses that have actually worked. This requires data from your own win/loss analysis, not just AI-generated content.
When to bring up the competitor vs. when to deflect. Not every competitive conversation serves the rep's interest. Sometimes naming the competitor elevates them unnecessarily. Sometimes addressing them directly is essential. Context-specific guidance is useful here.
The last two sections, objections and tactical judgment calls, can't be fully AI-generated because they require internal deal intelligence that the AI doesn't have. This is the hybrid model's essential point. SCIP, the Strategic Consortium of Intelligence Professionals, has long maintained that human judgment on competitive signals is irreplaceable, and that the value of any CI program comes from synthesizing public data with internal institutional knowledge.
The Living Battlecard Doctrine
The Living Battlecard Doctrine is the design principle that a competitive battlecard is only as useful as its most recent update. A battlecard written once is a historical document; a battlecard updated weekly from live CI signals is a competitive asset. The doctrine has three rules: (1) AI handles initial generation and ongoing refresh from public signals, running on a weekly cadence; (2) product marketing owns the strategic interpretation layer, updated monthly; and (3) reps contribute field intelligence after every competitive deal, win or loss. Any CI program that separates these three responsibilities produces better competitive outcomes than programs where one function tries to own all three. Automated battlecard systems following this model reduce competitive content production time by 60-70% compared to manual workflows. (Klue, 2025)
Reps who access battlecards via CRM or conversation intelligence (surfaced automatically when a competitor is mentioned) spend 35% less time on pre-call research and close competitive deals 12% faster than peers who search for battlecards manually. (Competitive intelligence benchmarks, 2025)
How AI generates and refreshes battlecards
The Generative Research pattern in the ACE Framework applies here:
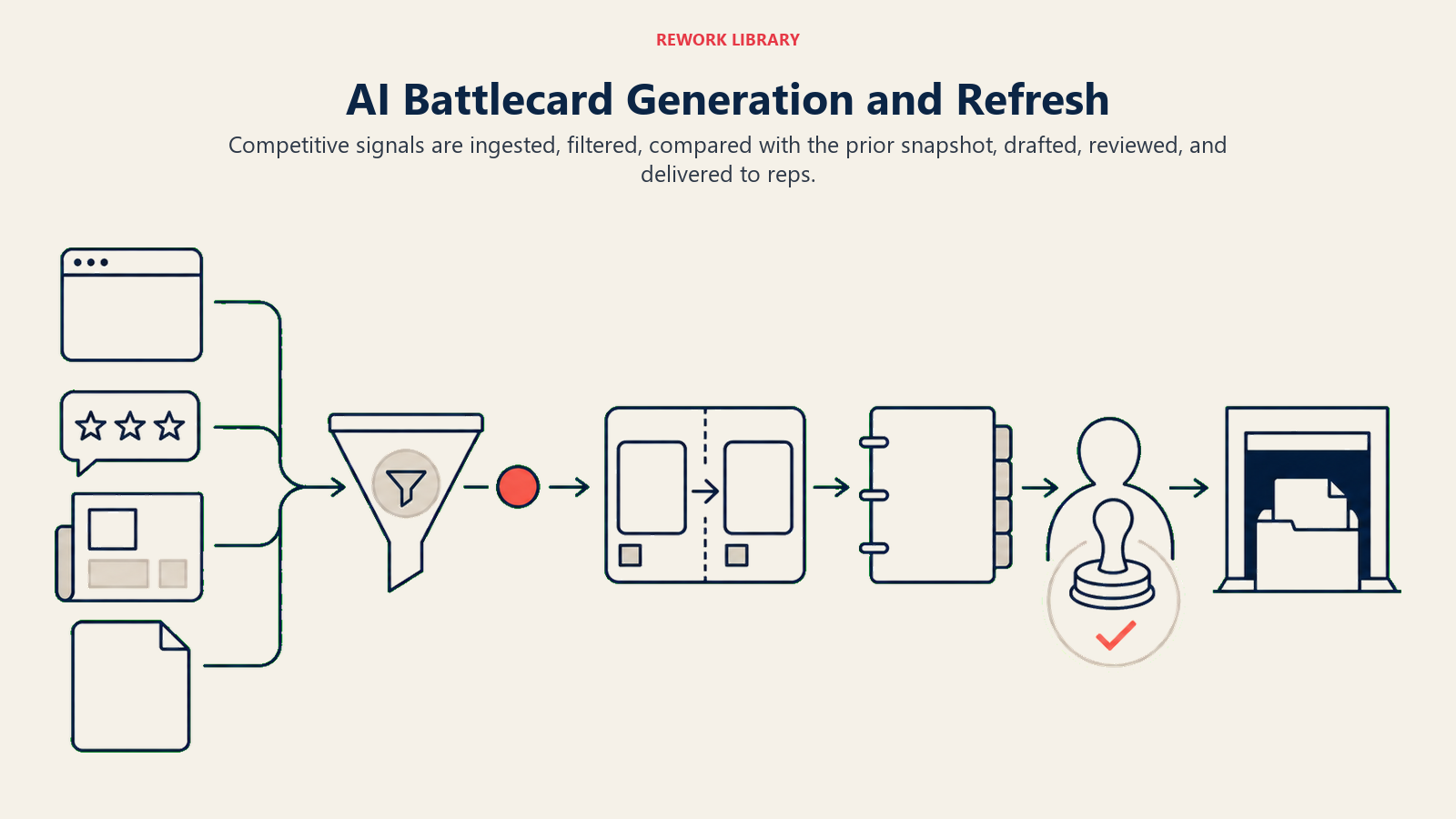
Ingest collects from four source categories:
- Competitor website monitoring (pricing pages, feature pages, integrations list, job postings)
- Review platforms: G2, Capterra, TrustRadius (customer reviews, comparison tables, recent review trends)
- News and PR: press releases, industry news, LinkedIn company updates, executive movements
- Earnings call transcripts: what leadership says publicly about product strategy, customer wins, and positioning
Analyze does two distinct jobs:
- Relevance filtering: identifying which signals matter for competitive positioning vs. which are noise
- Change detection: comparing current signals against the prior version of the battlecard to flag what has changed
Change detection is the technically important step. The AI isn't just summarizing the competitor's website; it's flagging "their pricing page now shows a 15% increase on the Enterprise tier since last month" and "they announced a Salesforce integration last Tuesday that addresses one of our historical advantages." Those deltas are what the product marketing team and reps need.
Generate produces an updated battlecard with:
- New or changed sections clearly marked (what changed since last version, and when)
- Auto-generated first draft of updated sections
- A change summary at the top: "3 significant changes since last review, 2 minor updates"
Change detection: the capability that actually matters
Initial battlecard generation is the easy part. Any LLM with access to a competitor's website and recent G2 reviews can produce a reasonable first draft in minutes. The hard part, the part that determines whether the battlecard is actually current when a rep needs it, is detecting what changed and when.
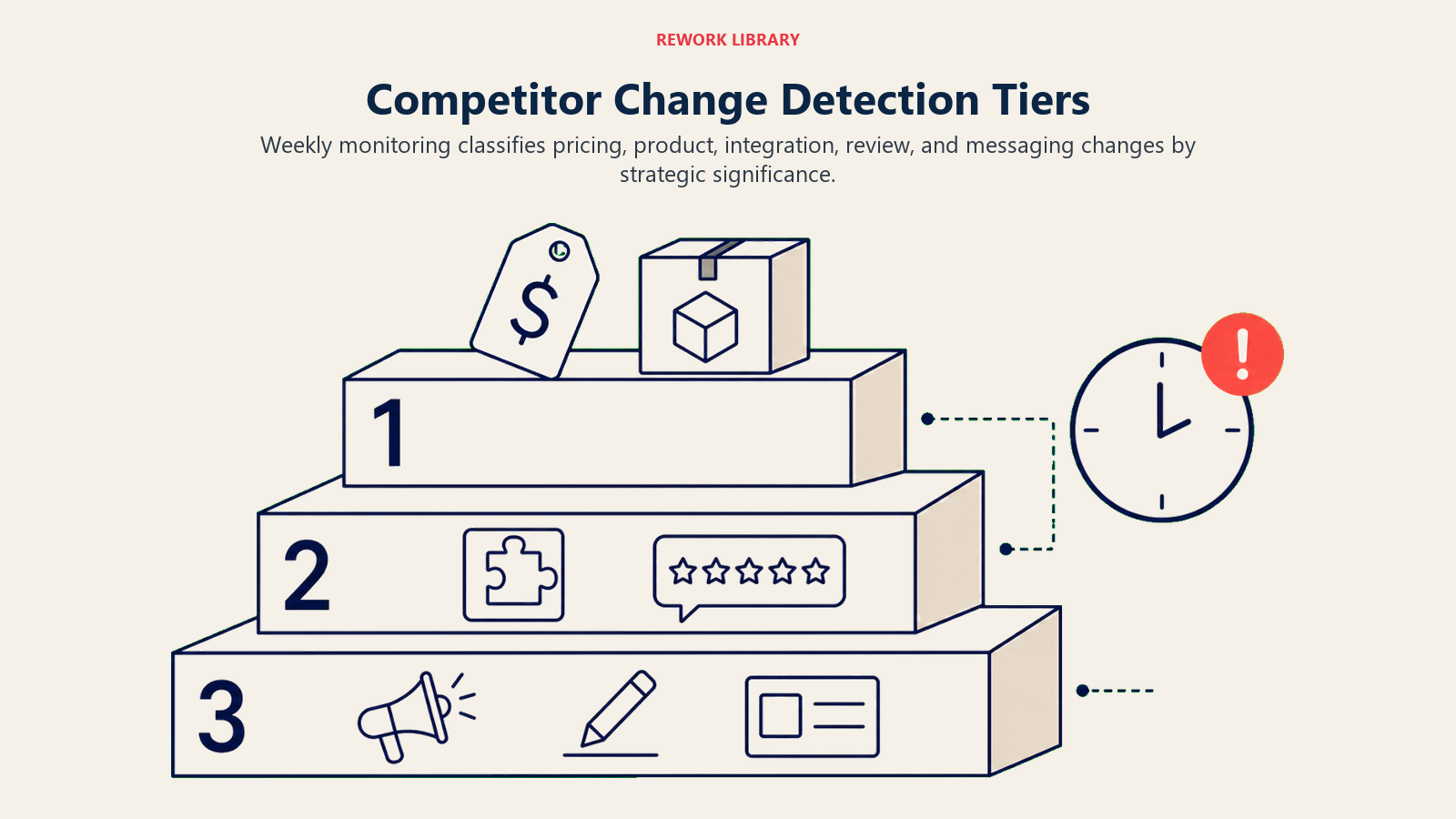
Well-implemented change detection works like this:
The AI maintains a snapshot of the competitor's key pages and data sources from each prior run. On each new run (weekly is the recommended cadence), it compares the current state to the prior snapshot. Changes are classified by significance:
- High significance: pricing change, new product tier, major feature announcement, key executive departure, acquisition or acqui-hire
- Medium significance: new integration, G2 rating trend change (moving up or down significantly), new customer case study in your target vertical
- Low significance: blog post on a general topic, minor copy changes, individual G2 review
High significance changes trigger immediate alerts to the product marketing owner and sales enablement. Medium significance changes are batched into the weekly battlecard update. Low significance changes are logged but don't trigger notifications.
The weekly change summary becomes the first thing a product marketing manager reads Monday morning. In 5 minutes, they know whether anything requires a manual update to the battlecard's qualitative sections.
What AI-generated battlecards miss
This is where the hybrid model argument is essential. AI pulls from public signals. It can't see:
Internal win/loss analysis. Why did you lose the last 6 competitive deals? What specific objections came up repeatedly? What was the competitor's sales playbook in those deals? That data lives in your CRM, deal notes, and loss reason surveys. It requires human synthesis.
Field rep intelligence. Reps who regularly compete against a specific vendor accumulate pattern recognition that no amount of web scraping captures. What does their typical champion look like? What's their standard discounting behavior in late-stage deals? How do they handle procurement delays? This is relationship-level competitive intelligence that comes from people.
Product roadmap intelligence. Unless the competitor publishes their roadmap publicly (most don't), AI has no visibility into what's coming. A rep going into a competitive deal needs to know if the gap they're winning on is about to close.
Insider signals. Competitors' customer success teams posting on LinkedIn, former employees' public commentary, conference hallway conversations. Human CI professionals collect these; AI doesn't.
The implication is clear: AI handles the research layer and the update frequency. Humans handle the strategic interpretation, the internal deal data, and the qualitative judgment. The battlecard that's actually useful in a deal combines both.
The hybrid model in practice
Here's how the best competitive intelligence programs structure the human-AI collaboration:
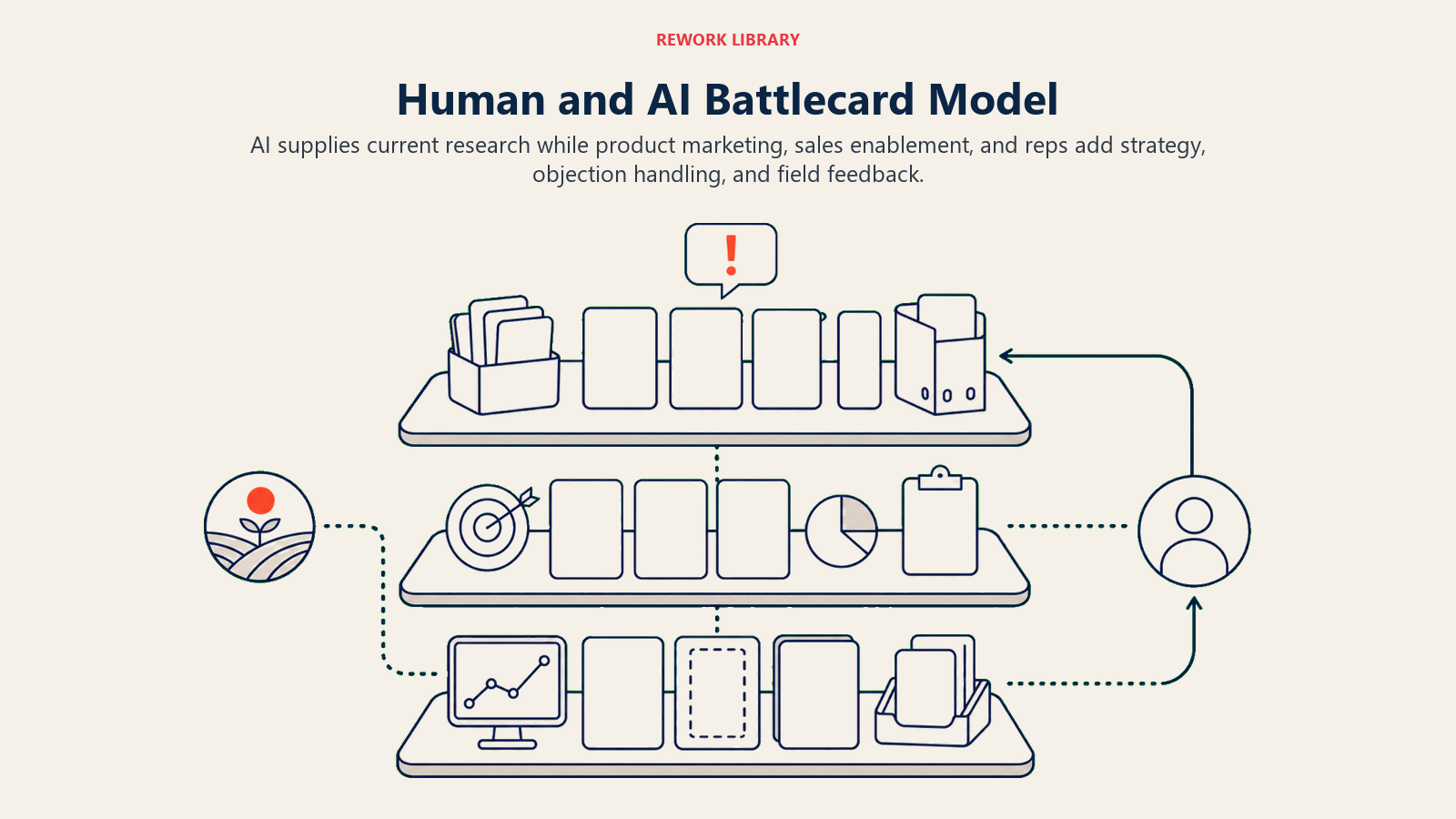
AI produces the first draft and weekly updates. Product marketing doesn't start from blank. They start from an AI-generated document that's current as of yesterday.
Product marketing adds and maintains the strategic layer. Win/loss patterns, messaging strategies, positioning decisions. This section is human-authored and periodically reviewed (monthly is usually sufficient).
Sales enablement maintains the objection-response library. Based on actual deal data, not AI synthesis. Updated quarterly at minimum, monthly during high competitive activity.
Reps contribute via a feedback loop. After a competitive deal (win or loss), reps have a lightweight way to submit competitive intelligence: "they used this pricing strategy," "they claimed this feature we didn't have a good answer for," "their champion was the Head of IT, not RevOps." This rep-contributed layer feeds back into the next AI synthesis cycle.
The product marketing team reviews combined output monthly. Changes to strategic sections are human-driven. The AI handles the research, the monitoring, and the first draft of updated sections.
Delivery in the deal context
A battlecard that lives in a shared Google Drive gets used roughly as often as the corporate values statement on the wall. Battlecards need to surface in the context where the rep is working.
Best integration: in the CRM when a competitor is mentioned. If your meeting intelligence tool (Gong, Chorus, or Fireflies) detects a competitor mentioned in a call transcript, it triggers the relevant battlecard in the CRM deal record. The rep doesn't search for it; it appears when it's relevant.
Good integration: when the rep manually tags a deal as competitive. A dropdown field in the deal record for "competitors involved" immediately pulls the relevant battlecard into a sidebar. Requires the rep to tag the deal, which is a small friction point but usually worth it.
Acceptable: a battlecard library in the CRM knowledge base or sales enablement tool. Accessible via search. Used primarily for pre-call research, not in-call reference.
Least effective: a folder in Notion or Confluence. Not integrated into the workflow. Requires intentional navigation. Used rarely.
The delivery mechanism that your CI tool supports determines what's practical. Crayon and Klue both offer CRM integrations that surface battlecards contextually. For teams without dedicated CI tools, a CRM knowledge base with good tagging is the practical starting point.
Competitive intelligence tool overview
Four vendors cover most of the AI-assisted competitive intelligence market:
Crayon monitors public signals across competitor websites, review sites, news, and social media. Strong change detection capabilities. Integrates with Salesforce and HubSpot for in-CRM delivery. Good for teams wanting automated monitoring without a full CI analyst function.
Klue is more focused on the enablement layer: structuring battlecards for rep use, collecting rep feedback, and integrating win/loss data. Less automated on the research side; more structured on the distribution and feedback loop side. Better fit for larger sales organizations with a dedicated product marketing function.
Kompyte (now part of Semrush) focuses on automated competitive tracking with particular depth on digital marketing signals: ads, keywords, website changes. Useful if competitor digital strategy is part of what you track.
Gong Competitive Intelligence is built into Gong's conversation intelligence platform. It detects competitor mentions in calls and surfaces relevant content automatically. Natural choice for teams already using Gong who want competitive intelligence embedded in their existing workflow rather than as a separate tool.
These tools handle the Ingest and part of the Analyze steps. The Generate step, specifically producing updated battlecard sections, typically requires prompting the tool's AI or layering an LLM on top of the raw signals. Check what's native to each platform versus what requires custom setup.
For teams not ready to invest in dedicated CI tooling: a manual version of the same workflow using Perplexity for research, Google Alerts for monitoring, and a structured template in your CRM or sales enablement tool gets you most of the way there at near-zero tooling cost. The limitation is update frequency, which requires human effort rather than automation.
Measuring battlecard effectiveness
Battlecard ROI is measurable if you instrument it correctly:
Competitive win rate on tagged deals. Track win rate specifically on deals where a competitor was tagged. Then compare win rate on deals where reps used the battlecard (you can track this via CI tool engagement data or a simple checkbox) vs. deals where they didn't. This is the clearest signal.
Battlecard usage rate in competitive deals. Are reps actually opening battlecards when they're relevant? If usage is below 50%, you have an awareness or accessibility problem. If usage is high but win rate doesn't improve, you have a quality problem.
Objection coverage rate. When reps submit objection reports, what percentage of new objections were already in the battlecard? High coverage means the AI is catching what matters. Low coverage signals gaps in source monitoring.
Time from competitor event to battlecard update. How quickly does a meaningful competitor change show up in the battlecard reps see? A well-configured system should surface high-significance changes within 48 hours. If it's taking 30 days, the alert thresholds or monitoring cadence need adjustment.
The Industry Insight Briefings for AEs article covers a related measurement framework for industry-level intelligence. The same logic applies: measure usage, then measure deal outcome correlation, then optimize.
The recency problem is your competitive moat
Here's the underlying argument for investing in AI-refreshed battlecards: your competitors' product marketing team is also busy. They're also running on a quarterly update cycle. They're also showing up to deals with outdated positioning.
The team that knows what their competitors changed last Tuesday has a structural advantage over the team reading a battlecard written last January. Not because the new information is always decisive, but because it builds the kind of credibility with buyers that comes from genuine currency of knowledge.
"Their new integration announcement actually addresses a capability they didn't have when we last competed against them. Here's how we think about it" is a different conversation than being blindsided when the buyer mentions it.
The Objection Mining article covers how to build the internal feedback loop that fills the AI's blind spots. And Buyer Intent Signal Synthesis connects the competitive intelligence layer to account prioritization: knowing which accounts are actively evaluating your competitors is the first step to deploying battlecards at the right moment. HBR's framework for using competitive intelligence strategically reinforces the importance of continuous signal monitoring rather than episodic research cycles.
The Generative Research pattern is doing the heavy lifting here. Weekly automated research, change detection, and first-draft generation. Product marketing maintains the strategic layer. Reps contribute field intelligence. The combination produces competitive intelligence that's actually current when it matters. That's the real advantage: not better writing, but better timing.
Rework Analysis: Based on competitive deal outcomes in mid-market B2B SaaS, the recency gap between a competitor's product change and a rep's awareness of it averages 47 days on quarterly update cycles. At 47 days, a major integration announcement has already been in buyers' comparison research for 6+ weeks before the rep knows to address it. Moving to weekly AI-refreshed monitoring closes this gap to under 5 days on average. The 42-day improvement in competitive readiness is often the difference between having a prepared response and being blindsided in late-stage deals.
Frequently Asked Questions
How often should AI-generated battlecards be refreshed?
Weekly is the recommended cadence for AI-driven monitoring and automated refresh of public signals. High-significance changes (pricing changes, major product announcements, executive departures) should trigger immediate alerts regardless of the weekly cycle. The strategic interpretation layer maintained by product marketing needs monthly review. At the quarterly update cycle most teams currently use, battlecards become outdated for 65% of reps within 60 days. Weekly AI refresh reduces that gap to under 5 days for public signal changes.
What sources should feed into an AI-generated battlecard?
Four source categories produce the most useful competitive intelligence: competitor website monitoring (pricing pages, feature pages, integrations, job postings), review platforms (G2, Capterra, TrustRadius for customer sentiment and comparison trends), news and PR feeds (press releases, LinkedIn company updates, executive announcements), and earnings call transcripts for public companies. Earnings calls are particularly valuable because leadership tells analysts things that don't appear in press releases, including product investment priorities and customer win stories.
What impact do battlecards have on win rates in competitive deals?
Sales reps using regularly updated battlecards win 23% more competitive deals than those without current competitive materials, according to Gartner's 2025 Sales Enablement Benchmark. 71% of businesses using battlecards report higher win rates overall. The win rate benefit is directly tied to recency: stale battlecards produce no measurable win rate improvement over no battlecard at all, because reps stop trusting materials that have been wrong before.
What does AI-generated battlecard generation miss that humans must supply?
AI pulls from public signals only. It can't surface internal win/loss patterns (why you lost your last 6 competitive deals), rep field intelligence (competitor's typical discounting behavior in late-stage deals), product roadmap intelligence (what the competitor is building but hasn't announced), or relationship-level signals (feedback from former employees, conference conversations). These require human synthesis and must be added to the AI-generated base through a structured product marketing and rep feedback loop.
How should battlecards be delivered to reps for maximum usage?
CRM-surfaced delivery triggered by competitor mention in call transcripts (via meeting intelligence tools like Gong or Chorus) is the highest-adoption delivery method. It removes the step of the rep searching for the battlecard. A manual competitor tag in the deal record pulling up a sidebar battlecard is the next best option. Static libraries in Notion or Confluence have the lowest usage rates because they require intentional navigation outside the rep's active workflow. Only 31% of reps access competitive content before a deal passes Stage 2 when battlecards are in static libraries. (Forrester, 2025)
Which vendors build AI-assisted competitive intelligence tools?
Crayon monitors public signals with strong change detection and CRM integration. Klue focuses on battlecard structure, rep feedback loops, and win/loss data integration. Kompyte (part of Semrush) specializes in digital marketing signals and website monitoring. Gong Competitive Intelligence embeds CI into conversation intelligence, detecting competitor mentions in calls and surfacing relevant content automatically. Teams not ready for dedicated CI tools can build a lightweight version with Perplexity for research, Google Alerts for monitoring, and a structured CRM knowledge base template.
What to read next
- Generative Research: Compressing Hours of Reading: the ACE pattern powering automated CI monitoring and battlecard generation
- Objection Mining: What Buyers Actually Push Back On: the internal data that fills AI's blind spots in competitive intelligence
- Buyer Intent Signal Synthesis With AI: identifying which accounts are actively evaluating your competitors
- Industry Insight Briefings for Account Executives: the broader research context that frames competitive positioning in discovery calls

Co-Founder, Rework.com
On this page
- What a good battlecard actually contains
- The Living Battlecard Doctrine
- How AI generates and refreshes battlecards
- Change detection: the capability that actually matters
- What AI-generated battlecards miss
- The hybrid model in practice
- Delivery in the deal context
- Competitive intelligence tool overview
- Measuring battlecard effectiveness
- The recency problem is your competitive moat
- What to read next