AI Lead Scoring Beyond Rules-Based Models

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Most "lead scoring" deployed today is manual weighting dressed up as intelligence.
The logic goes: a form submission is worth 10 points, a VP title adds 20, a company with 200+ employees adds 15, visiting the pricing page adds 25. Add it up and anything above 70 is a "hot lead." Sales team works the hot leads first.
The problem is obvious once you say it out loud: a human decided those weights. They made a judgment call, probably informed by some intuition and a few anecdotes from the sales team, and encoded it as static rules. The weights don't update when the market shifts. They don't recalibrate when your Ideal Customer Profile (ICP) changes after you raise a Series B. And they definitely don't capture the interaction between signals.
A VP title from a 50-person company at 2 AM on a Saturday converts at a completely different rate than the same title from a 300-person company at 10 AM on a Tuesday.
Machine learning (ML) lead scoring lets the data choose the weights instead of the humans. That's the entire conceptual difference. But executing it well requires understanding how the model works, what data it needs, and where deployments fail. This is Pattern 1 in the AI Sales Operator architecture, and the foundation everything else builds on.
What rule-based scoring misses
Rules are categorical. ML models are probabilistic. McKinsey's research on AI in B2B sales identifies lead qualification as one of the highest-impact AI use cases for sales teams, precisely because the improvement compounds: better scoring means reps work better leads, which means more closes, which means better training data for the next model iteration. That distinction produces a set of systematic blind spots in rule-based approaches:
Field sparsity. Most lead forms capture 4-6 fields. Most Customer Relationship Management (CRM) records have dozens of potentially relevant fields, many of them empty. Rules treat empty fields as neutral. ML models can learn that a missing LinkedIn URL in a specific company-size band correlates with lower close rates, because that's what the historical data shows. The absence of information is itself a signal.
Timing and sequence. A lead who visits the pricing page on day one and fills out the demo form the same day converts differently than a lead who visited the pricing page three weeks before submitting the form, then visited again the day before. Rules can detect "pricing page visit = 25 points," but they don't capture recency curves or behavioral sequences. ML models do.
Firmographic change signals. A company that just hired a VP of Sales is a fundamentally different prospect than the same company six months ago. A recent funding round changes buying capacity. A new product launch creates technology needs. Static rules don't pick up these dynamic signals. ML models fed with recent firmographic data (from sources like LinkedIn, Clearbit, or 6sense) can factor them in.
Multi-touch interactions. The combination of "VP title + pricing page + referral source = partner channel" might convert at 40%. Each element alone might be worth 10%. Rules score them independently; ML captures the interaction effect.
Key Facts: AI Lead Scoring
- McKinsey identifies lead qualification as one of the highest-impact AI use cases for B2B sales teams, because better scoring compounds: better leads close more often, generating better training data for the next model iteration
- A minimum of 200 closed-won deals is required for a reliable ML lead scoring model; below 100, most commercial tools produce output that's statistically indistinguishable from random assignment
- Companies using AI-assisted lead scoring report 10-20% higher lead-to-opportunity conversion rates compared to static rules-based models, according to MadKudu and 6sense customer data (2022-2024)
How ML lead scoring works (without the PhD)
The mechanics are simpler than most vendors make them sound. Here's the operational logic, using ACE Framework vocabulary:
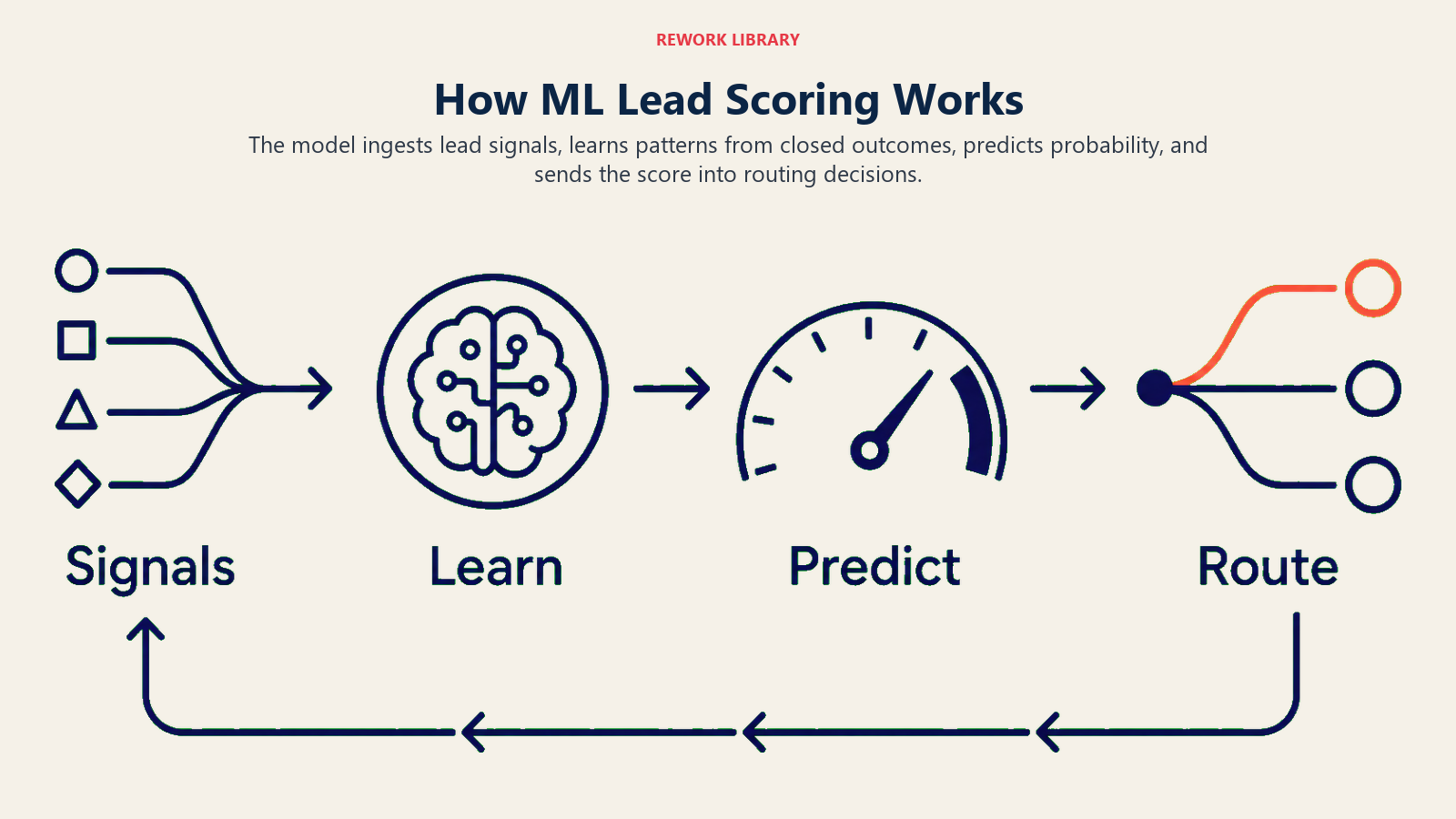
Ingest pulls in all available signals for each lead: CRM fields (title, company size, industry, source), behavioral data (pages visited, emails opened, webinar attended), firmographic enrichment (revenue band, headcount, funding stage, tech stack), and time-based data (when activities happened, gaps between them).
Analyze extracts features from that raw data. Features are the input variables the model actually trains on. Some are direct (title = "VP" → binary feature). Some are engineered (days between first visit and form submission → numeric feature). Some are interaction terms (company size × engagement frequency → composite signal). Feature engineering is where most of the work happens, and where ops teams who understand their own data have an advantage over generic out-of-box models.
Predict trains a model on historical labeled data: deals that closed (won) and deals that didn't (lost), along with all the features above. Under the hood, most commercial lead scoring tools use logistic regression or gradient boosting, both well-understood ML techniques that output a probability between 0 and 1. The model learns which feature combinations correlate with closed-won outcomes in your specific customer base and applies those learned weights to every new lead, producing a probability output: this lead has a 73% chance of converting, given what we know about it.
That's it. A probability number from 0 to 100, grounded in your own win/loss history, updated as new deals close. The recalibration loop is what separates a working model from one that slowly drifts.
The Probabilistic Lead Score Standard
The Probabilistic Lead Score Standard defines what a defensible AI lead score must include: a probability output between 0 and 1 grounded in the company's own win/loss history, trained on at least 200 closed-won outcomes, recalibrated no less than quarterly against new deal outcomes, and exposed to reps with feature attribution (which signals drove this score). Any scoring system that fails one of these four criteria is better classified as enhanced rules-based scoring than true ML scoring, because the output isn't statistically grounded in measured conversion patterns.
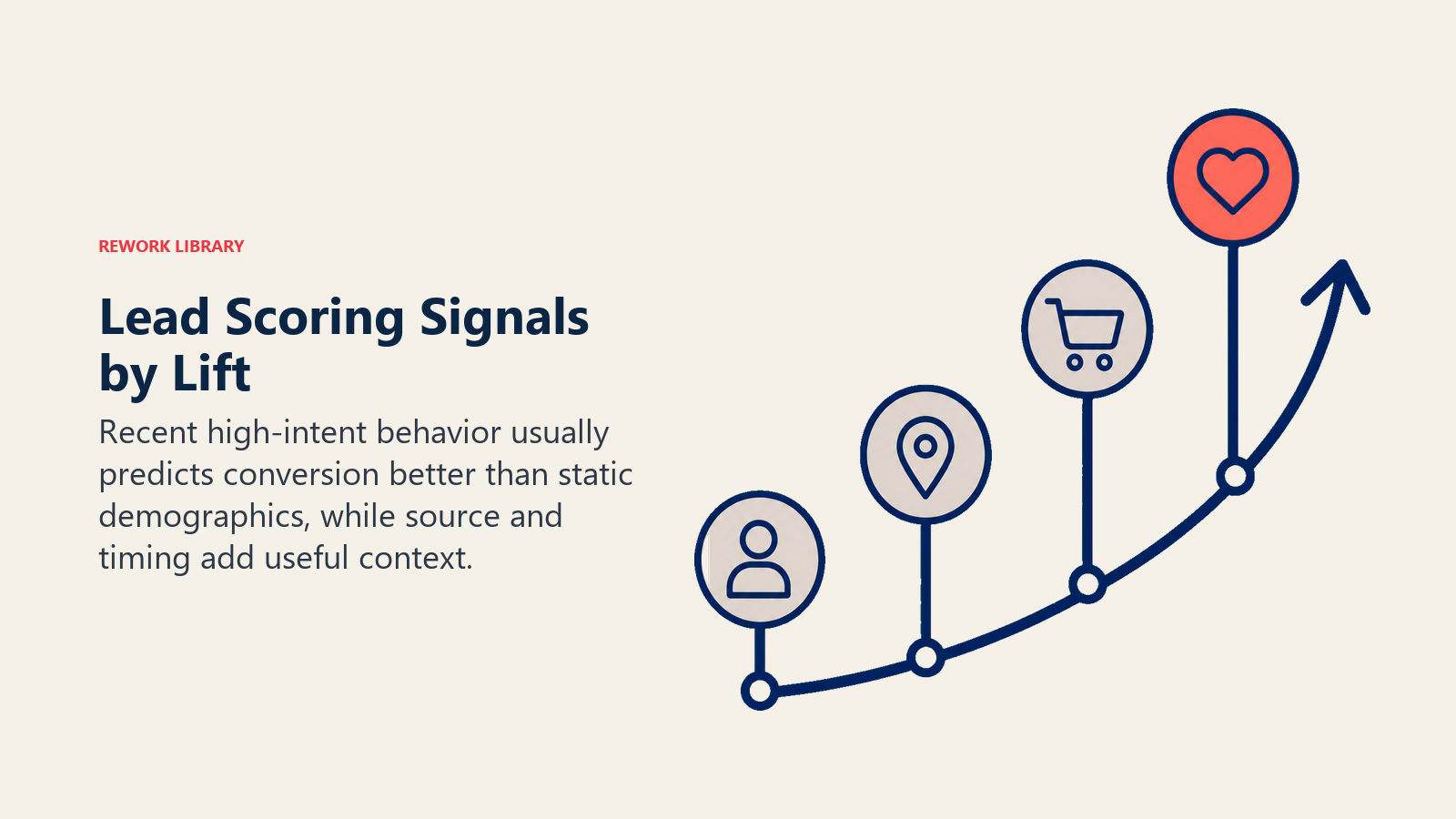
Signal types ranked by conversion lift
Not all signals are equally useful. Based on patterns from MadKudu's research and 6sense's buyer intent data published between 2022 and 2024, here's how signal categories generally rank in lift contribution for B2B SaaS:
| Signal Type | Examples | Lift Contribution | Notes |
|---|---|---|---|
| Intent signals | Pricing page visits, competitor comparison pages, G2 category views | Very High | Late-stage buying signals; recency matters (last 7 days >> last 30 days) |
| Engagement recency | Email opens, website visits in last 14 days, attended webinar | High | Recency curve matters: exponential decay past 30 days |
| Firmographic fit | Company size, industry vertical, funding stage | High | Your ICP definition encoded mathematically |
| Technographic fit | CRM type (Salesforce vs. HubSpot), known integrations, current tech stack | Medium-High | Strongest lift when your product displaces or complements a specific tool |
| News triggers | Recent funding, new hire announcements, product launches | Medium | Strong signal for cold outbound; less predictive for inbound |
| Contact-level fit | Title, seniority, department | Medium | Strongest when combined with company-level fit, weaker in isolation |
| Lead source | Organic search, partner referral, content download | Low-Medium | Varies dramatically by company; always test rather than assume |
| Form behavior | Time on form, fields filled in, device type | Low | Useful as a tiebreaker; not a primary signal |
The ordering shifts based on your product and market. For a developer tool, technographic fit might be the strongest signal. For a financial services product, firmographic band and regulatory context might dominate. The model learns your specific ranking from your data; the table above is a starting hypothesis.
Data readiness checklist before deploying
This is the step most companies skip. AI lead scoring does not produce good results on bad data. Before purchasing or configuring any ML scoring tool, run through this checklist:

Minimum requirements:
- At least 6 months of closed deals with consistent won/lost labeling (12 months preferred)
- At least 200 closed-won deals total (more is better; below 100 produces unreliable models)
- CRM deal stages are consistent across the team (no "Closed Won" vs. "Won" vs. "Closed" variations)
- First-touch source is captured on at least 70% of records
- Company name and domain are filled in on 80%+ of records
Strong-to-have (improves model quality significantly):
- Contact title and seniority captured on at least 60% of leads
- Company size (employee count) captured or enrichable for 70%+ of records
- Website behavioral data (HubSpot tracking, Segment, or equivalent) sending events to CRM
- At least one firmographic enrichment source (Clearbit, Apollo, ZoomInfo) feeding the CRM
Warning signs that suggest data work before scoring:
- More than 20% of deals closed without an outcome label
- Three or more different stage names for the same lifecycle position
- Less than 6 months of deal history since a CRM migration (pre-migration data is often unreliable)
- Zero behavioral tracking data (no page visit history, no email open tracking)
If you're missing multiple items on the minimum list, spend four to six weeks cleaning data before deploying scoring. The model will be built on whatever you feed it.
From model output to routing threshold
A model gives you a probability. You still need to decide what to do with it.
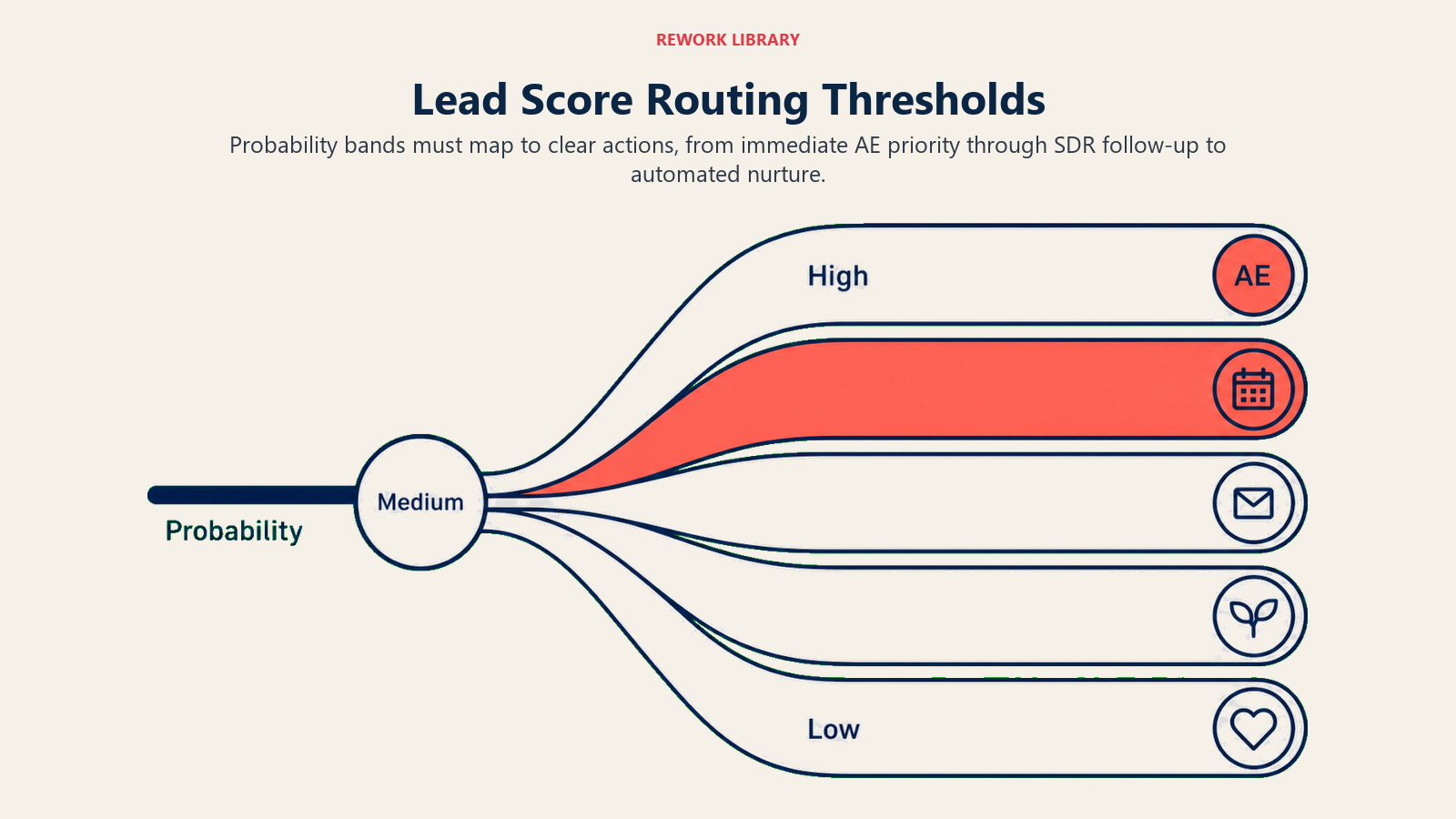
Most deployments define three to five buckets with routing logic attached:
| Score Range | Label | Routing Action |
|---|---|---|
| 85-100% | Very High | Route to senior AE, immediate Slack notification, no SDR filter |
| 65-84% | High | Route to AE queue, SLA: contact within 2 hours |
| 40-64% | Medium | Route to Sales Development Representative (SDR) for qualification, enroll in mid-touch sequence |
| 20-39% | Low | Auto-enroll in nurture sequence, no rep assignment |
| 0-19% | Very Low | No action; add to newsletter list only |
The threshold numbers are yours to set, not the vendor's. They should reflect: how much rep capacity you have (more reps = lower threshold for direct assignment), how often you can tolerate a false positive (a high-scored lead who turns out to be wrong = wasted rep time), and what your current contact SLA commitments are.
Getting thresholds right is a calibration exercise, not a one-time configuration. Run with the initial thresholds for 60 days, then compare: for each bucket, what was the actual conversion rate? If your "High" bucket is converting at 8% and your "Medium" bucket is converting at 12%, your thresholds are miscalibrated. Adjust and observe again. And always keep an eye on queue volume: a threshold drift that suddenly sends 40% of leads to the "High" bucket will destroy rep trust within weeks.
Common failure modes
Model trained on biased historical data. If your historical wins skew toward a specific channel (e.g., 70% of your closed deals came from partner referrals), the model will learn to score partner-sourced leads high. When you expand into a new channel, the model will score those leads poorly. Not because they're bad leads, but because it has no training data for that pattern. Fix: retrain with broader data, or segment models by source.
Scores that aren't surfaced to reps. The model produces good output, but it lives in a CRM field nobody looks at. Reps continue working leads in arrival order. This is an adoption failure, not a model failure. Fix: surface scores in the rep's daily workflow (Slack notification, CRM queue sorted by score) and train reps on what the score means before go-live.
No feedback loop to retrain. The model is configured in January and never touched again. Twelve months later, the market has shifted, the ICP has evolved, and the model is still optimizing for patterns from 18 months ago. Fix: build a quarterly recalibration process. Revenue Operations (RevOps) lead reviews model performance metrics (accuracy, precision, recall by bucket) and triggers a retrain when accuracy drops more than 5 percentage points.
Threshold set-and-forget. Initial thresholds are set at go-live and never reviewed. 90 days later, 40% of all leads are scoring "High" because the model learned too broadly. The "High" queue is overwhelming reps and trust collapses. Fix: review threshold distribution monthly and adjust to maintain the right queue volume for rep capacity.
Full treatment of common AI lead scoring pitfalls.
Vendor snapshot
Salesforce Einstein Lead Scoring is included with Sales Cloud Enterprise and above. It trains on your Salesforce data directly, without needing to export or connect to a third-party tool. The model recalibrates automatically on a periodic schedule. Quality is strong for companies with clean Salesforce data and 12+ months of history. Limited configuration for advanced feature engineering or custom data sources.
HubSpot Predictive Lead Scoring is available on Marketing Hub Professional/Enterprise and Sales Hub Enterprise. Similar architecture to Einstein: trains on HubSpot data, produces scores visible in the HubSpot pipeline. Weaker for companies with significant behavioral data outside HubSpot or complex firmographic segmentation needs.
MadKudu is a purpose-built B2B scoring platform that connects to Salesforce, HubSpot, and multiple data enrichment sources. It surfaces feature importance (which signals drove a specific score), making it easier for RevOps to audit and calibrate. Best for companies that want transparency into model logic and are willing to do the data integration work.
6sense focuses on intent signals (buying committee identification, anonymous visitor tracking) more than conversion probability. Its strength is mid-funnel account prioritization, especially for account-based selling. Often layered on top of a CRM-native scoring model rather than replacing it.
Rework Sales AI includes Scoring+Routing built into the CRM as part of the full AI Sales Operator architecture. Scores recalibrate from deal outcomes, route to rep queues automatically, and feed directly into the Workflow Copilot for draft follow-ups. Best fit for teams that want integrated scoring without managing a separate vendor relationship.
Rework Analysis: The most common ML lead scoring failure we see isn't a bad model. It's a good model that nobody recalibrates. Teams deploy in Q1, see strong results in Q2, and by Q4 they're wondering why the "hot" leads aren't closing anymore. The model was trained on a market that existed 9 months ago. Their ICP shifted after a pricing change, a new competitor entered, or a new use case emerged. Quarterly recalibration isn't optional maintenance; it's the mechanism that keeps the probability output connected to current reality. Teams that build the recalibration review into their ops calendar from day one sustain 12-18 month ROI. Those that treat the model as a one-time install typically see performance plateau within 6 months.
The feedback loop is the whole game
Rule-based scoring is a hypothesis: these attributes should predict conversion. You set it once and hope it ages well.
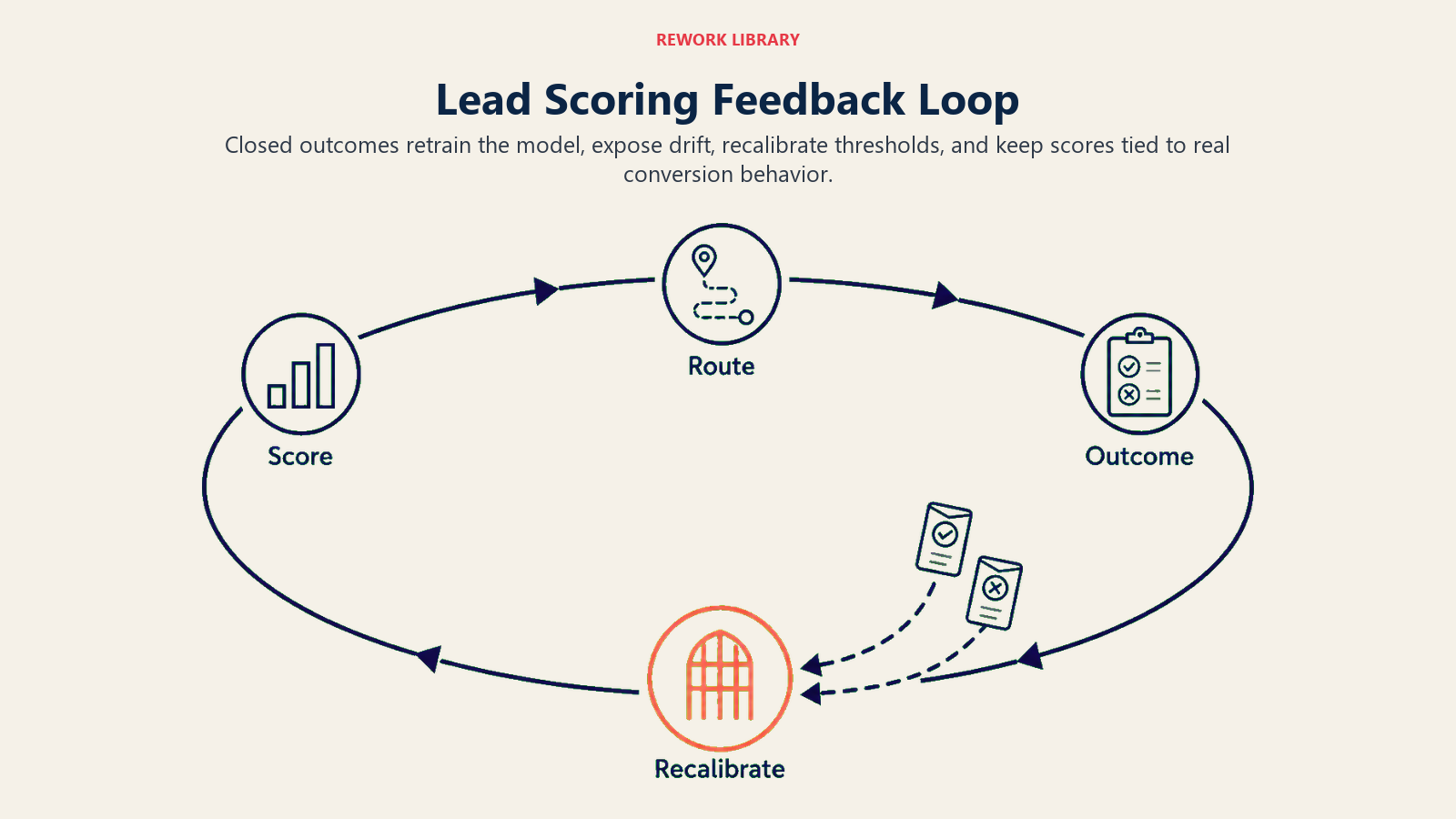
ML scoring is a measurement: these attributes did predict conversion, based on actual outcomes, updated as new outcomes arrive.
But "ML scoring is a measurement" only holds if the measurement system has a feedback loop. Without recalibration, the model is also a hypothesis, just one trained on data instead of intuition. A hypothesis that drifts as market conditions change.
The deployments that deliver sustained ROI are the ones where RevOps owns the feedback loop. They track model accuracy quarterly. They retrain when accuracy drops. They audit threshold performance monthly. They treat the scoring model as infrastructure, not a one-time project.
That operational ownership is what separates an AI lead scoring deployment that keeps improving from one that produces good results for three months and then becomes background noise. Once the scoring model is calibrated and feeding the right leads to the right reps, the next question is what happens to those leads when they arrive.
Frequently Asked Questions
What is AI lead scoring?
AI lead scoring uses machine learning models trained on historical CRM data to assign each inbound lead a probability score between 0 and 100. Instead of human-assigned point weights (rule-based scoring), the model learns which signal combinations actually correlate with closed-won outcomes in your specific customer base and applies those learned weights to every new lead. The score updates as new deals close, making it self-calibrating rather than static.
How is AI lead scoring different from rules-based lead scoring?
Rules-based scoring encodes a human hypothesis: "VP title adds 20 points, pricing page visit adds 25." AI scoring measures what actually converted: the model finds the signal combinations that correlate with won deals in your historical data and weights them accordingly. The practical difference is that rules don't adapt when your ICP changes, don't capture interaction effects between signals, and don't improve over time. AI models do all three when properly recalibrated.
What data does an AI lead scoring model need to work?
The minimum requirements are at least 6 months of closed deals with consistent won/lost labeling (12 months preferred), at least 200 closed-won deals total, consistent CRM stage definitions, first-touch source captured on 70%+ of records, and company name/domain filled in on 80%+ of records. Models trained on fewer than 100 won deals produce output statistically indistinguishable from random assignment.
Which signals matter most for B2B lead scoring?
Intent signals (pricing page visits, competitor comparison pages, G2 category views) carry the highest conversion lift because they indicate late-stage buying behavior. Engagement recency follows, with exponential decay past 30 days. Firmographic fit (company size, industry, funding stage) is the third most predictive category for most B2B SaaS products. The specific ranking varies by product; the model learns your company's actual ordering from your data.
How often should an AI lead scoring model be recalibrated?
Quarterly recalibration is the minimum standard. The RevOps owner should review model accuracy (precision and recall by score bucket) each quarter and trigger a retrain when accuracy drops more than 5 percentage points from the baseline. ICPs shift, new channels emerge, and pricing changes alter which leads convert. A model trained 9-12 months ago without recalibration may be optimizing for patterns that no longer reflect current buyers.
What are the most common AI lead scoring failure modes?
The four most common failures are: (1) model trained on biased historical data (e.g., 70% of wins from one channel, making the model poor at scoring other channels); (2) scores not surfaced in the rep's daily workflow, so reps ignore them; (3) no recalibration process, causing accuracy to drift as the market changes; and (4) threshold miscalibration, where too many leads score "High" and overwhelm rep capacity until trust in the system collapses.
What routing actions should different score ranges trigger?
A standard five-bucket routing model maps to: 85-100% (direct to senior AE, immediate Slack notification), 65-84% (AE queue, 2-hour contact SLA), 40-64% (SDR qualification, enroll in mid-touch sequence), 20-39% (automated nurture, no rep assignment), and 0-19% (newsletter only). The specific thresholds should be calibrated to your team's rep capacity and reviewed monthly to maintain the right queue volume for your current headcount.
Learn More

Co-Founder, Rework.com
On this page
- What rule-based scoring misses
- How ML lead scoring works (without the PhD)
- The Probabilistic Lead Score Standard
- Signal types ranked by conversion lift
- Data readiness checklist before deploying
- From model output to routing threshold
- Common failure modes
- Vendor snapshot
- The feedback loop is the whole game
- Learn More