Common AI Lead Scoring Pitfalls (And How to Fix Them)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Most AI lead scoring deployments fail quietly. There's no system crash, no error message, and no moment where anyone declares it broken. The model runs, scores appear in the Customer Relationship Management (CRM), reps glance at them for a few weeks, and then stop using them. The tool stays on the contract. The scores keep updating. Six months later, when someone asks whether lead scoring is working, nobody really knows.
The quiet failure is the worst kind: it's expensive, it's invisible, and it's attributed to the wrong cause. "Our leads are just lower quality this quarter." "Reps need better training on qualification." "Maybe the model needs more data." All of those might be true. But often the deeper problem is structural, not a data volume problem or a rep performance problem.
This article is a diagnostic for ops leaders who've deployed AI lead scoring and aren't seeing the behavior change they expected. The failures below are the most common patterns, and most of them are fixable with operational changes rather than vendor swaps.
Pitfall 1: Training on biased historical data
The problem: Your model trained on past closed-won deals, and your past closed-won deals over-represent one segment. The model learned to score that segment high. But that segment may not represent your actual best-fit accounts today.

What this looks like in practice: A SaaS company trained their lead scoring model on three years of closed deals. Most of those deals were SMB, because that was their primary market three years ago. They've since shifted upmarket. The model keeps scoring SMB leads high and enterprise leads low, even though the sales team's mandate is enterprise. Sales leadership thinks the scoring is "backwards." It's not backwards; it learned the past accurately. The past is just wrong for today's strategy.
The fix: Before retraining, do a closed-won audit. Group your historical closed-won deals by deal size, industry, and Ideal Customer Profile (ICP) segment. If your current target market isn't proportionally represented in the training set, your model needs either retraining on a filtered, representative subset, or an ICP-weighted scoring layer on top. This is why AI lead scoring emphasizes that model architecture is only as good as the training labels. The labels come first.
Key Facts: AI Lead Scoring Failure Rates
- The NIST AI Risk Management Framework identifies ongoing monitoring and measurement as a core trustworthiness requirement for deployed AI systems; a scoring model with no retraining cadence violates this requirement by design
- Models trained on fewer than 100 closed-won outcomes produce output statistically indistinguishable from random assignment; below 200, model reliability is marginal
- Score-to-conversion correlation studies consistently show that 25-30% of all inbound leads scoring as "hot" is the threshold where threshold miscalibration begins degrading rep trust; above 30%, adoption typically collapses within 60 days
The 5 Lead Scoring Failure Modes
The 5 Lead Scoring Failure Modes is a diagnostic framework for AI scoring deployments that appear to be running but aren't changing rep behavior. The five modes are: (1) Biased Training Data, where historical wins over-represent a market segment the team has since moved away from; (2) Score Surfacing Failure, where scores exist in a CRM field reps never see; (3) No Feedback Loop, where the model retrains never and accuracy decays over time; (4) Threshold Miscalibration, where too many leads score as "hot" and the designation becomes meaningless; and (5) Intent Gap, where fit-based scoring identifies ICP-matched accounts but misses active buying signals. Each mode has a distinct fix. Most failures involve more than one mode simultaneously.
Pitfall 2: Scores not surfaced where reps work
The problem: A score buried in a CRM field that's three clicks deep produces zero behavior change. Reps don't change workflows to find information; information needs to meet them where they already are.
What this looks like in practice: Revenue Operations (RevOps) sets up a custom field called "AI Lead Score" in Salesforce. It's on the lead record detail page, below the fold, next to 40 other fields. No one changes the default list view. No notifications fire when a score updates. Reps learn to ignore it because it doesn't interrupt their existing workflow.
The fix: Score surfacing is a workflow design problem, not just a data problem. The score needs to appear in the lead list view (sortable), as a notification trigger (alert when a lead crosses a threshold), and in the rep's daily digest or task queue. If you're using a sales engagement platform like Outreach or Salesloft, the score should gate which leads enter which sequences. The test: if a rep could do their entire workday without seeing the score, it's not surfaced. This is one of the easiest pitfalls to fix and one of the most frequently missed.
Pitfall 3: No feedback loop
The problem: The model scores on static training data indefinitely, with no mechanism to retrain on new closed-won and closed-lost outcomes. Every quarter the model drifts further from current reality, but nobody notices because the scores keep updating and the interface looks the same.
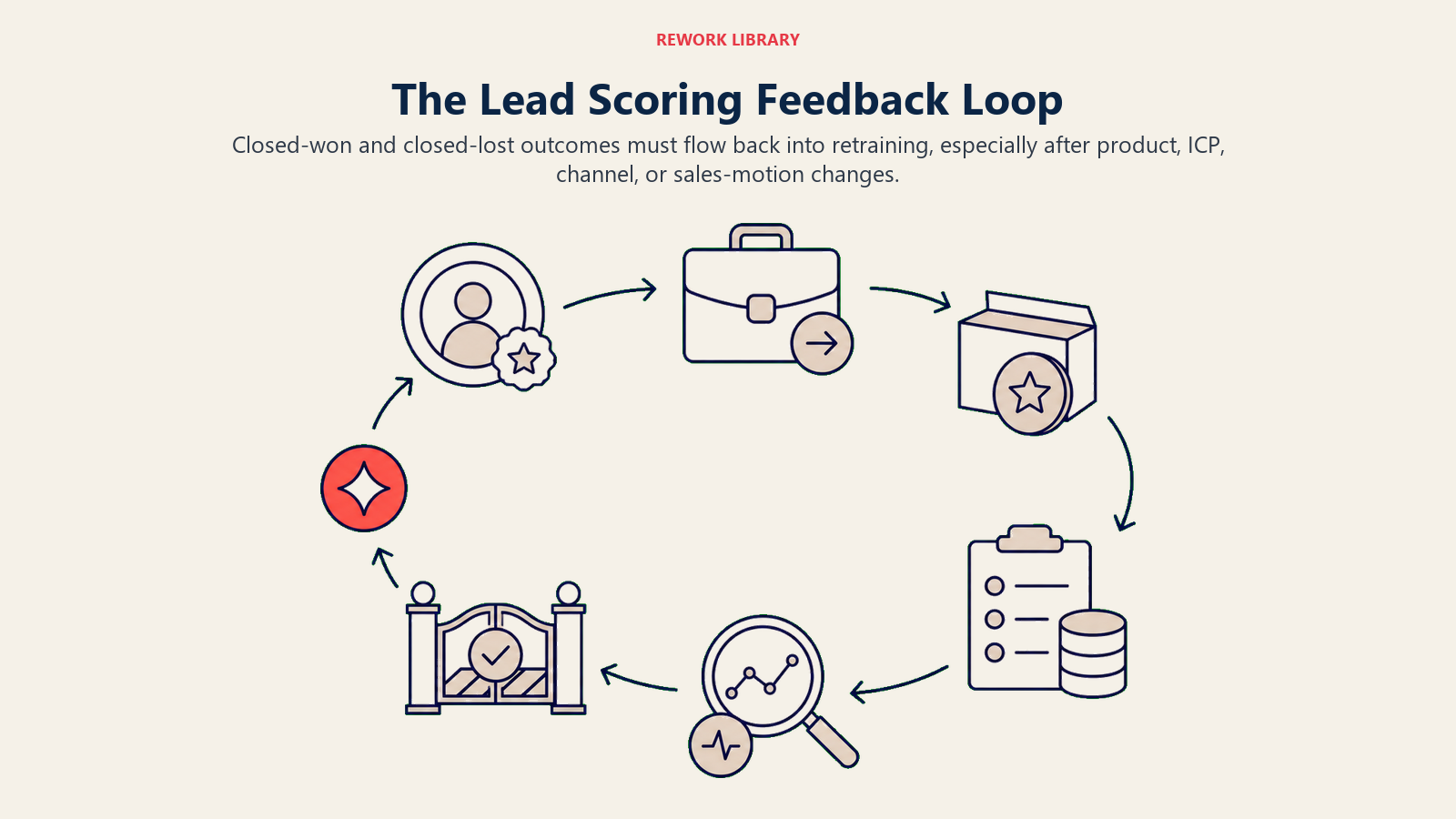
This is the most structurally important failure mode. Unlike the others, which degrade gradually, no feedback loop causes compounding accuracy decay. A model trained in Q1 of last year and never updated has now missed four quarters of deal outcomes that could have sharpened its predictions. The NIST AI Risk Management Framework specifically identifies ongoing monitoring and measurement as a core trustworthiness requirement for any deployed AI system, not a one-time setup task.
What this looks like in practice: A company deploys HubSpot Predictive Lead Scoring in February. It trains on 18 months of historical deals. In April, they launch a new product line that changes their buyer profile. In June, they hire 5 new Account Executives (AEs) who begin closing a different deal profile. In September, a manager notices that scores don't correlate with their best deals. The model was fine in February. It's been degrading since April. Nobody triggered a retraining because the system doesn't alert on drift.
The fix: Define a retraining cadence before you launch, not after you notice the problem. Quarterly is the minimum for most businesses; monthly is better for fast-growing teams with shifting ICPs. The trigger events for an out-of-cycle retrain: new product launch, significant ICP change, major channel addition, or sales motion change. The mechanic: ensure your CRM is logging closed-won and closed-lost consistently with the fields your model uses as features. Without that logging discipline, you have no new training data to feed back in.
This is also why human-readable score explanations (Pitfall 6) matter for feedback. If a rep can see that a lead scored high because of "company size + tech stack + industry match," they can flag when that logic no longer reflects what's converting. Reps are your early warning system for model drift, but only if they understand the scoring logic.
Pitfall 4: Too many input features, too little data
The problem: Overfitting. The model uses 40 input features to score leads from a training set of 300 historical deals. It memorizes patterns in the training data rather than generalizing to new leads. It looks impressive in evaluation (high accuracy on training data) and fails on live leads.
What this looks like in practice: A RevOps analyst builds a custom lead scoring model in Python using 45 features from Salesforce (every field they could think of: page views, email opens, job title level, company age, LinkedIn followers, funding status, etc.). The model evaluation shows 89% accuracy. When deployed, reps notice the model gives 90+ scores to leads that never engage and low scores to leads that are clearly qualified. The model memorized the training set. It has no predictive value on new data.
The fix: For teams with under 1,000 historical outcomes, use a simpler model with fewer features. 5-10 high-signal features, consistently populated, outperform 45 sparse or inconsistent features. The classic high-value features: company size, industry match, job title seniority, form source (which page/channel), and product-usage signals for expansion leads. Start sparse. Add features as your data volume grows.
For teams with limited historical data, starting with a vendor's pre-trained model (Salesforce Einstein, HubSpot Predictive Lead Scoring) and layering your ICP criteria on top is often more reliable than building from scratch.
Pitfall 5: Score threshold mismatch
The problem: The model outputs probabilities, but the routing thresholds are set incorrectly. A threshold that's too low floods reps with "hot" leads that aren't actually hot. A threshold too high means qualified leads never escalate to human attention.
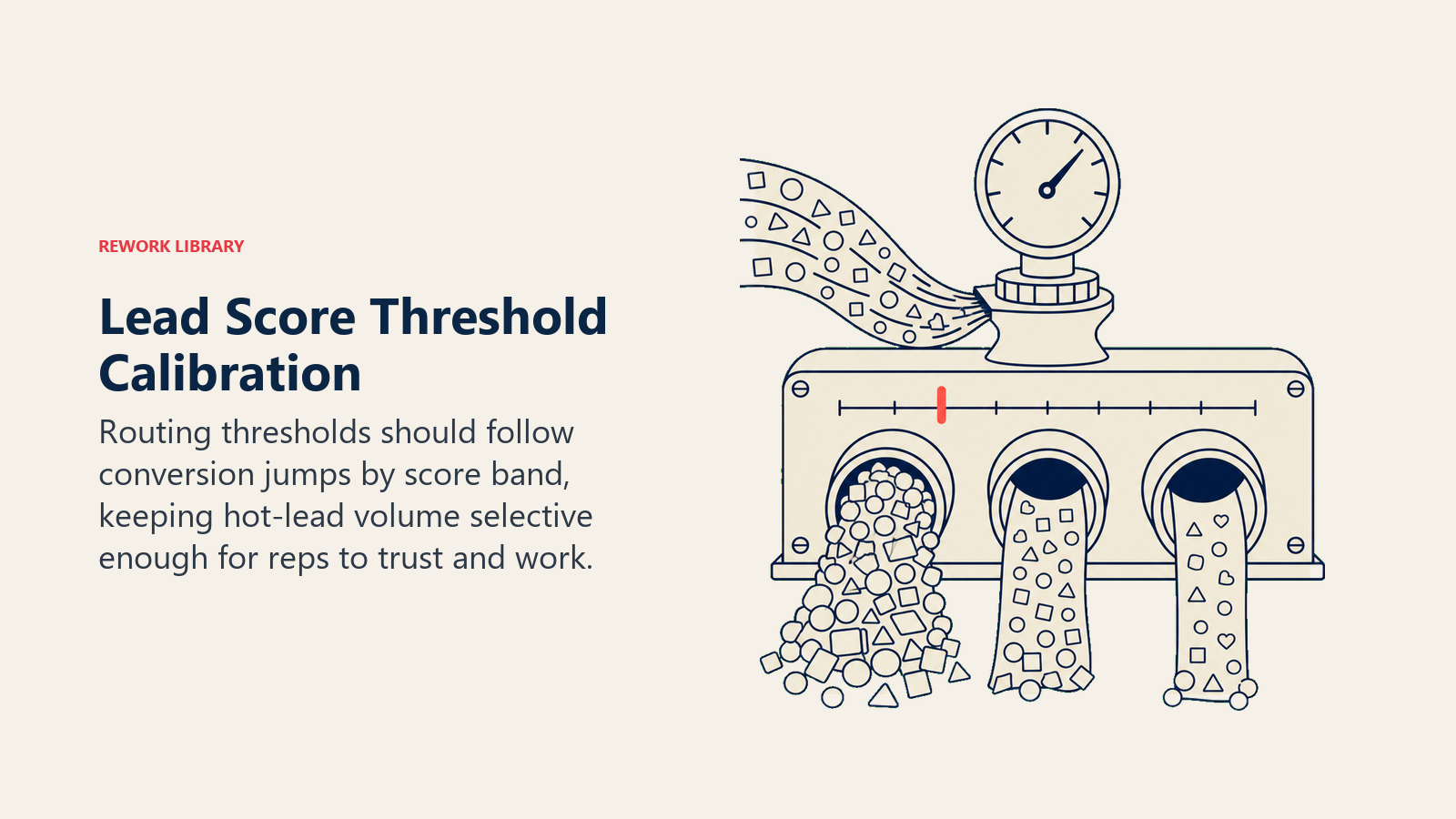
What this looks like in practice: A team sets their "hot lead" threshold at 40 out of 100. Their scoring model was calibrated so that 40 represents a 40% conversion probability. With a threshold at 40, 60% of their inbound is flagged as hot and routed to senior Sales Development Representatives (SDRs). Those SDRs are overwhelmed. Their connect rate on "hot" leads looks terrible because there are too many leads to work properly. The problem isn't the scoring model; it's the threshold.
The fix: Threshold setting should be calibrated against historical conversion rates by score band, not set arbitrarily. Pull your last 6-12 months of scored leads and conversion outcomes (if you have them). Find the score band where conversion rate meaningfully jumps. That's your routing threshold. If you're setting up scoring for the first time without historical scored leads, start with a high threshold (70+) that keeps the hot-lead volume manageable, and adjust down over time as you accumulate score-to-outcome data.
The threshold question also extends to routing tiers. Define at least three routing tiers: high-priority (human escalation, fast SLA), standard (normal SDR queue), and nurture (automated sequence, no rep contact until intent signal triggers). The thresholds between those tiers need to be tuned, not assumed. And 25-30% of leads scoring "hot" is the diagnostic ceiling: if you're above that, lower the threshold before reps stop trusting the system entirely.
Pitfall 6: Rep distrust from unexplainable scores
The problem: Black-box scoring loses rep adoption. A rep who doesn't understand why a lead scored 87 won't act on it consistently. And when the model makes an error the rep can spot (a clearly low-quality lead with a 90 score), the entire scoring system loses credibility in that rep's mind.
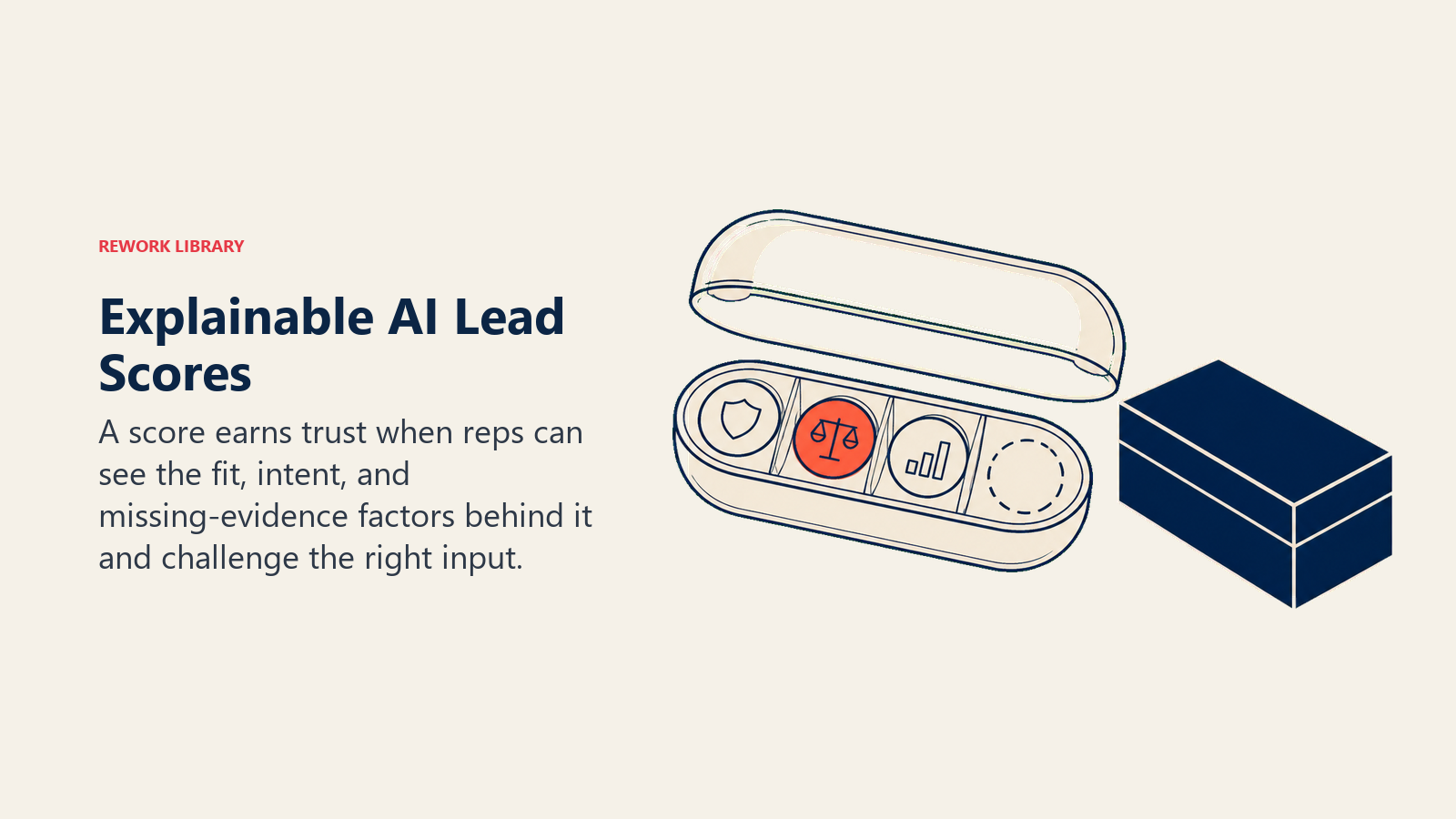
What this looks like in practice: A company deploys a scoring model that uses 15 weighted signals. The interface shows reps a single number: "Lead Score: 82." A rep looks at the lead, sees a 3-person startup at a company type that rarely converts for them, and ignores the 82. Next week they ignore a 91. Within two months, reps have mentally discarded scoring as unreliable. The model might have been accurate on average, but individual errors with no explanation destroyed adoption.
The fix: Score explanations should appear at the point of use. Not just "Score: 82" but "Score: 82 because company size (mid-market), industry (financial services), and recent funding round all match your ICP. Intent signals: moderate. Missing: confirmed decision-maker contact." With that context, even when a rep disagrees with a score, they understand the reasoning. They can challenge the right input (maybe the "mid-market" classification is wrong because this company recently contracted) rather than dismissing the entire score.
Some tools offer this natively (Salesforce Einstein's score factors, HubSpot's score breakdown). Custom models need it built in deliberately.
Pitfall 7: Ignoring timing signals (fit without intent)
The problem: Fit-based scoring tells you that a company matches your ICP. It doesn't tell you they're actively buying. A perfect-fit company that's not in-market scores high but converts poorly. An average-fit company in active evaluation scores medium but converts better. Intent plus fit together outperforms either alone.
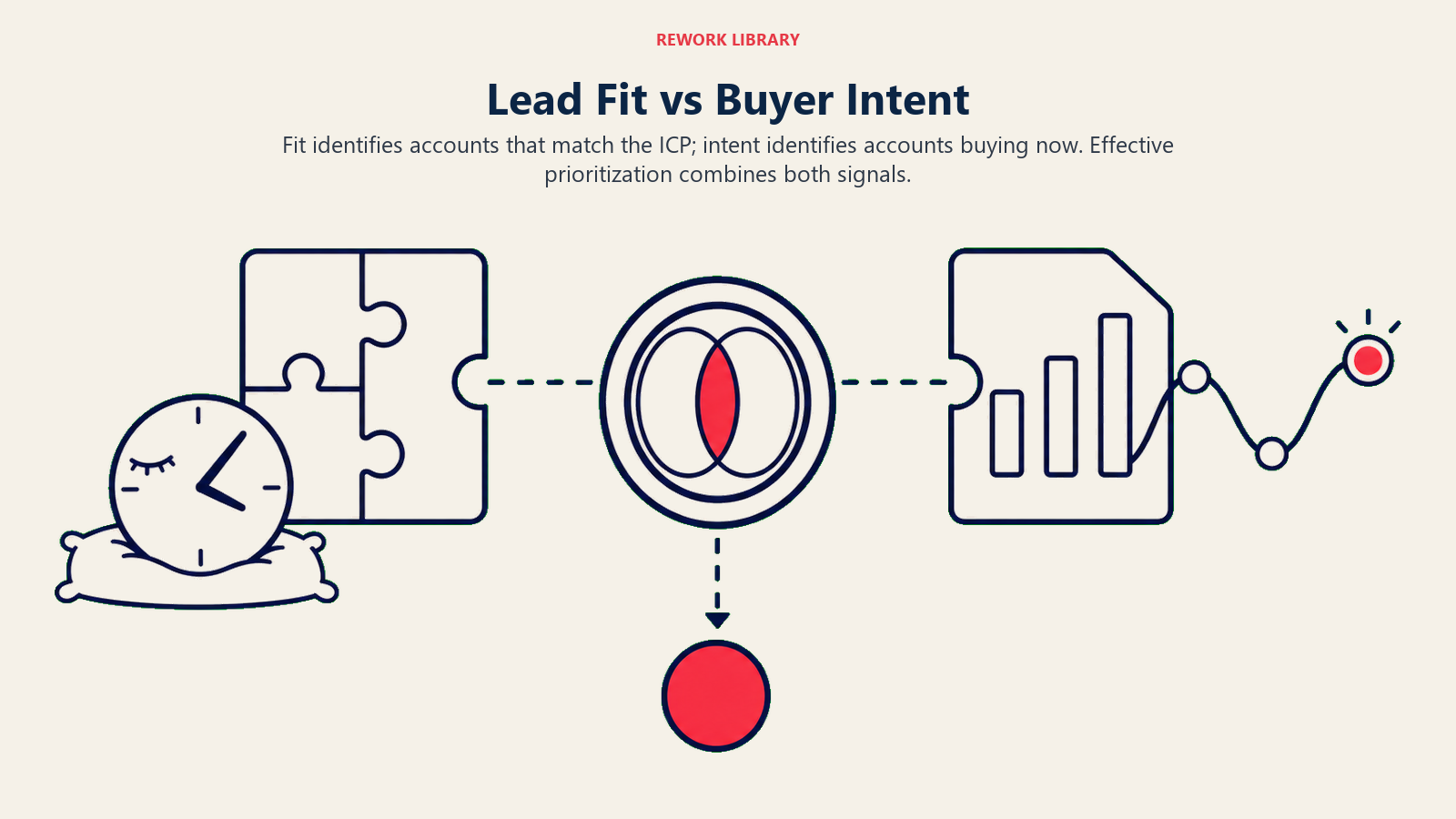
What this looks like in practice: A team's model scores accounts entirely on firmographic fit: company size, industry, tech stack, revenue range. Their "Tier 1" leads are consistently well-matched accounts. But reps complain that they can't get these leads to engage. They're cold ICP matches, not warm buyers. Meanwhile, intent data (Bombora, 6sense) shows several mid-tier accounts actively researching the company's category. Those accounts never surface because they didn't score high on firmographic fit.
The fix: Add timing signals as a scoring layer. Third-party intent (Bombora, 6sense, Demandbase) tells you who is actively researching right now. First-party signals (pricing page visits, documentation reads, feature comparison views) tell you which form submitters are in active evaluation mode. A lead that scores 60 on fit but has high intent signals should route differently than a lead that scores 90 on fit but shows no intent. The combined model catches buyers you'd miss with either signal alone. The buyer intent signal synthesis with AI article shows how to layer these signals in practice.
Rework Analysis: The silent failure pattern is the most expensive one we see in AI lead scoring deployments. The model is technically running, the vendor is technically still being paid, but reps stopped trusting the scores three months ago and nobody officially acknowledged it. The tell is a survey question: "Do you look at the AI lead score before deciding which leads to work first?" When fewer than 40% of reps say yes, the scoring system is decorative. The fix almost never requires a new vendor. It requires resolving whichever of the five failure modes caused trust to erode, usually threshold miscalibration or score surfacing failure, the two most operationally fixable problems on the list.
Audit checklist: diagnostic questions for your scoring deployment
Use these to diagnose which pitfalls affect your current system:
Training data
- When was the model last retrained? Is there a scheduled cadence?
- What percentage of your current closed-won deals come from segments that were prominent in the training data?
- Are closed-lost deals included in the training set, or just closed-won?
Surfacing and adoption
- Can a rep see the score without leaving their default list view?
- Is there a notification or alert when a lead crosses a threshold?
- Ask three reps: "What does a high lead score mean for your daily workflow?" If the answers are vague, the scores aren't changing behavior.
Feedback loop
- Is there a formal retraining trigger? Who owns it?
- Are closed-won and closed-lost fields mandatory in your CRM, with consistent definitions?
- How would you know if model accuracy was declining?
Threshold calibration
- What percentage of your inbound volume scores as "hot"? If it's above 25-30%, the threshold is probably too low.
- Do you have score-to-conversion outcome data to validate your current thresholds?
Explainability
- Can a rep see what drove a score?
- When a rep disagrees with a score, do they know what input to challenge?
Intent integration
- Is timing/intent data included in scoring, or only firmographic fit?
- Do you have any first-party behavioral signals in the scoring model (page views, email engagement, demo request)?
If you answered "no" to more than three of these, your scoring system has at least one structural problem. The AI lead scoring overview covers how a well-functioning model is built. This article covers why those models fail in the field.
Failure modes: when AI sales ops backfires extends this analysis beyond scoring to the broader RevOps stack.
The honest summary
AI lead scoring pitfalls are all fixable. But most fixes are operational, not technical. You don't need a different vendor for most of these. You need a retraining cadence, a score surfacing workflow, a threshold calibration process, and an explainability layer.
The most dangerous failure mode is also the most common: a model that runs indefinitely without a feedback loop, slowly diverging from reality while everyone assumes it's still working because the interface looks unchanged. Scoring with no retraining is like navigating with a map from last year. The terrain might have shifted; the map doesn't know it yet.
Frequently Asked Questions
Why do most AI lead scoring deployments fail quietly?
Quiet failure happens because there's no error message or system crash when a scoring model stops being useful. The model continues producing scores, the CRM field continues updating, and the vendor continues billing. But reps gradually stop acting on the scores, and nobody officially records that the system has stopped working. The failure is attributed to lead quality or rep performance rather than the structural problems driving it: biased training data, no retraining cadence, miscalibrated thresholds, or scores buried in a CRM field nobody sees.
What is the most critical AI lead scoring failure mode?
The feedback loop failure, where the model runs indefinitely without retraining on new closed outcomes, is the most structurally important. Unlike other failure modes that degrade gradually, no feedback loop causes compounding accuracy decay. A model trained in Q1 that never retrains has missed every market shift, ICP change, and channel addition since then. The NIST AI Risk Management Framework classifies ongoing monitoring as a core trustworthiness requirement, not optional maintenance.
How do you know if your AI lead scoring thresholds are miscalibrated?
Three signals indicate threshold problems: more than 25-30% of total inbound volume scores as "hot" (threshold too low), reps complain that hot leads aren't converting (same problem), or reps are manually re-prioritizing leads based on gut feel rather than score (threshold has lost credibility). Fix by pulling the last 6-12 months of scored leads with outcomes, finding the score band where conversion rate meaningfully increases, and setting the hot-lead threshold at that band.
What should a rep be able to see when they look at a lead score?
A complete score surfacing experience shows: the score itself (e.g., 82/100), the top three factors driving the score (e.g., company size: mid-market, industry: financial services, recent funding: Series B), any intent signals detected, and what's missing that would improve the score (e.g., no confirmed decision-maker contact). Without this context, reps can't challenge wrong inputs, can't build intuition about what high scores mean, and can't trust the system when they see individual errors.
How often should an AI lead scoring model be retrained?
Quarterly is the minimum; monthly is better for fast-growing teams or those shifting ICP. Out-of-cycle retraining triggers include new product launches, significant ICP changes, major new channels, or material changes in deal size distribution. The retraining mechanism requires that closed-won and closed-lost outcomes are consistently logged with the fields the model uses as features. Without that logging discipline, there's no new training data to feed back into the model.
What is the difference between fit scoring and intent scoring?
Fit scoring measures how well a company matches your ICP on firmographic dimensions: company size, industry, tech stack, revenue range. Intent scoring measures whether a company is actively researching and buying right now: third-party data from Bombora or 6sense showing category research, plus first-party signals like pricing page visits and feature comparison views. Fit-only scoring produces a list of your best potential customers, most of whom aren't in buying mode today. Combining fit and intent surfaces who's best AND most ready. A 60-fit/high-intent lead often converts better than a 90-fit/no-intent lead.
Why do reps stop trusting AI lead scores after a few weeks?
Trust collapses when reps see high scores on leads they know are wrong, with no explanation for why the lead scored high. A rep who sees a clearly low-quality company with an 85 score, and can't see what drove that score, concludes the entire system is unreliable. Black-box scoring destroys adoption because reps can't distinguish between a genuinely good model making a rare error and a broken model producing random numbers. Score explanations prevent this: with context, reps can challenge a specific input rather than discarding the system.
Learn More

Co-Founder, Rework.com
On this page
- Pitfall 1: Training on biased historical data
- The 5 Lead Scoring Failure Modes
- Pitfall 2: Scores not surfaced where reps work
- Pitfall 3: No feedback loop
- Pitfall 4: Too many input features, too little data
- Pitfall 5: Score threshold mismatch
- Pitfall 6: Rep distrust from unexplainable scores
- Pitfall 7: Ignoring timing signals (fit without intent)
- Audit checklist: diagnostic questions for your scoring deployment
- The honest summary
- Learn More