Scoring and Routing: Phân loại AI ở quy mô lớn
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
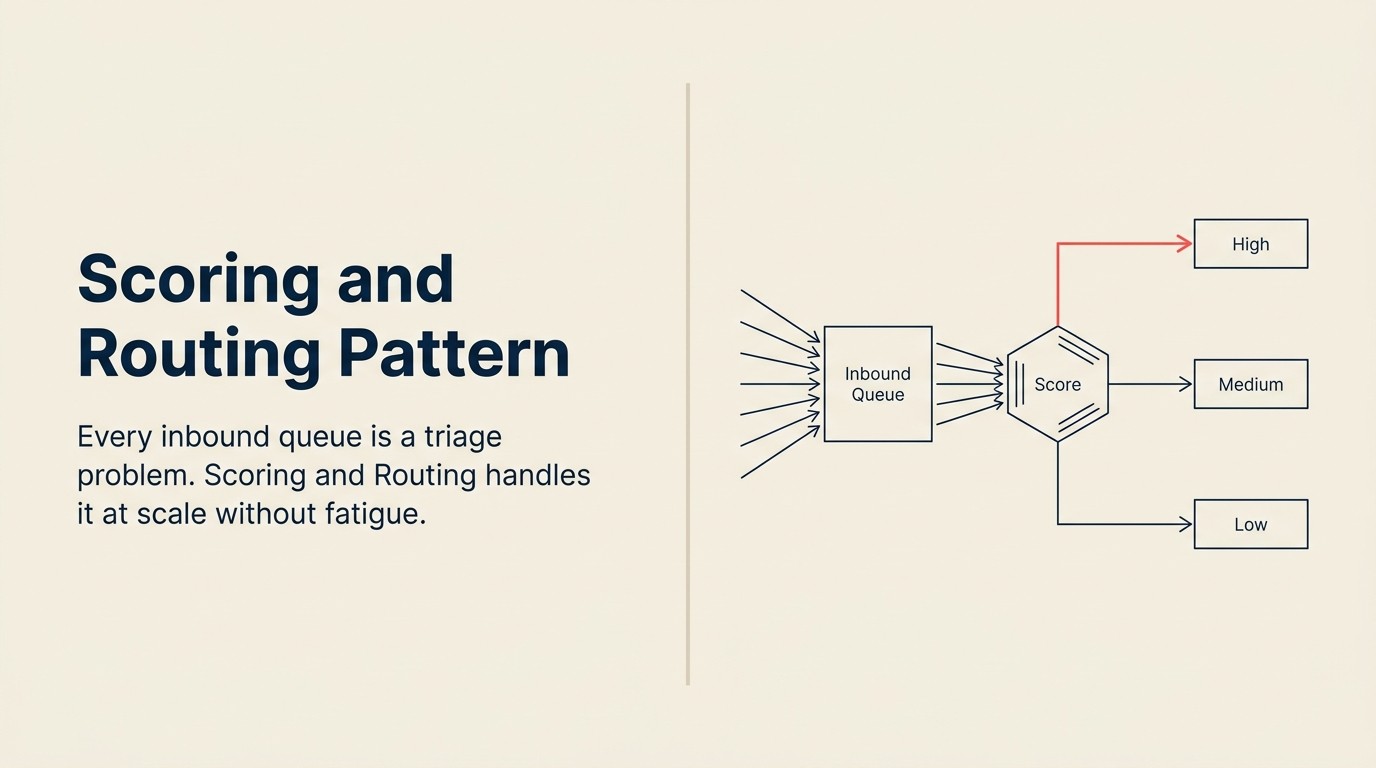
Mỗi hàng đợi đầu vào đều là vấn đề phân loại.
Lead đến từ chiến dịch webinar: 400 contact, 40 người có ý định mua thực sự và 360 người click vì tiêu đề hay. Ticket support chất đống qua đêm: 300 yêu cầu mới, 12 là vấn đề doanh nghiệp khẩn cấp và 288 là câu hỏi L1 đã có câu trả lời trong tài liệu. Đơn vay tiền đến: 1.200 cái trong tuần này, một số đủ tín nhiệm, một số không, một vài cái trông sạch nhưng thực chất là gian lận.
Công việc giống hệt nhau trong mọi trường hợp. Phân loại tín hiệu khỏi nhiễu. Ưu tiên đúng item. Đưa mỗi item đến đúng người hoặc đúng quy trình. Làm đủ nhanh để những thứ thực sự khẩn cấp không nằm chờ ba tiếng trong khi một người đọc tay từng cái một.
Phân loại thủ công không mở rộng được. Các rule dựa trên ngưỡng ("định tuyến bất kỳ lead nào từ công ty 500+ nhân viên đến team enterprise") bỏ lỡ context. Chúng không đọc được chuỗi email đính kèm theo lead. Chúng không thấy visitor đó đã dành 40 phút trên trang giá. Chúng không tính đến việc prospect này đã churn sau sáu tháng trước đây.
Scoring and Routing là AI pattern xử lý vấn đề này. Đây là một trong những pattern có giá trị kinh tế cao nhất trong business AI. Hiểu rõ nó, kể cả chỗ nó hay hỏng, là xứng đáng đầu tư.
Công thức: Ingest, Analyze, Predict, Execute
Ingest (record đến) nắm bắt input thô: hồ sơ lead mới, ticket support vừa gửi, đơn xin việc, yêu cầu bồi thường bảo hiểm. Trong hầu hết các triển khai, bước Ingest không chỉ lấy bản thân item đó. Nó kéo thêm context liên quan: lịch sử duyệt web của lead, tier và tuổi tài khoản của khách hàng, resume ứng viên cùng với job description, device fingerprint và merchant history của giao dịch.
Analyze (trích xuất features) chuyển input thô thành các tín hiệu model sẽ dùng. Với lead: quy mô công ty, seniority chức danh, trang web đã truy cập, email domain, ngành, và tương tác trong quá khứ. Với ticket support: phân loại intent (thanh toán? bug? feature request?), sentiment, tier khách hàng, và có khớp với incident pattern đã biết không. Đây là nơi lợi thế của AI bắt đầu hiện rõ. Phân loại thủ công nhìn vào 3-5 tín hiệu. Model đánh giá đồng thời 20-50 tín hiệu, bao gồm cả tương tác giữa các tín hiệu mà người ta thường không để ý.
Predict (chấm điểm) là bước model áp dụng các pattern đã học vào features. Output là một điểm: xác suất hoặc thứ hạng ưu tiên. Với lead: xác suất đóng trong 90 ngày. Với ticket: xác suất cần escalate hoặc cần chuyên gia. Với gian lận: xác suất giao dịch này không được ủy quyền. Predict là bước khớp pattern thuần túy với kết quả lịch sử, thường triển khai bằng logistic regression, gradient-boosted trees, hoặc fine-tuned LLM cho input nhiều text. Model đã xem những record cũ trông giống record này và biết chuyện gì xảy ra với chúng.
Execute (định tuyến hoặc giao) lấy điểm rồi hành động theo đó. Giao lead cho team enterprise. Chuyển ticket vào hàng đợi security. Từ chối giao dịch và kích hoạt review workflow. Tạo Salesforce task. Gửi Slack alert cho rep trực. Execute là nơi điểm số thành quyết định có hậu quả thực tế. Đây cũng là nơi governance quan trọng nhất. Bước Execute tạo ra tác động downstream không phải lúc nào cũng dễ đảo ngược.
Key Facts: Tác động kinh doanh của Scoring and Routing
- McKinsey ước tính AI trong sales và marketing có thể mở khóa 0,8 đến 1,2 nghìn tỷ USD năng suất tăng thêm, với những tổ chức đầu tư vào AI thấy doanh thu tăng 3-15% và ROI sales tăng 10-20% (McKinsey, 2023)
- Các công ty B2B dùng AI-powered lead scoring thấy tỷ lệ chuyển đổi cải thiện 2-3 lần trong tier lead có điểm cao nhất so với hàng đợi phân loại thủ công, trong các triển khai đã chín với 12+ tháng dữ liệu kết quả (Forrester B2B Sales AI Report, 2025)
- Các công ty bảo hiểm dùng Scoring and Routing báo cáo giảm 30-40% chi phí xử lý yêu cầu bồi thường thường xuyên, bằng cách đẩy nhanh các yêu cầu sạch và đưa yêu cầu phức tạp đến chuyên gia giám định (Deloitte Insurance AI Study, 2024)
Năm ví dụ thực tế chi tiết
1. Lead scoring và giao cho rep
Use case kinh điển. Một chiến dịch marketing tạo ra 300 lead đến. Model ingest từng hồ sơ lead cộng với behavioral data từ site analytics và email engagement platform. Analyze xem xét các features như chức danh (VP of Sales điểm cao hơn Sales Intern), quy mô công ty, độ phù hợp ngành, trang đã truy cập (vào trang giá hơn hai lần là tín hiệu mạnh), email mở trong hai giờ, và lịch sử CRM nếu đây là prospect quay lại.
Bước Predict gán điểm 0-100 cho mỗi lead, đại diện xác suất chuyển đổi. Bước Execute định tuyến lead trên 75 đến senior reps với SLA cùng ngày, lead từ 40-75 đến SDRs để qualification, và lead dưới 40 vào chuỗi nurture tự động.
Tooling ở đây gồm Salesforce Einstein Lead Scoring, HubSpot Predictive Lead Scoring, và trong Rework, AI-assisted scoring tích hợp vào sales workflow. Hệ thống được calibrate tốt thường chuyển thêm 20-30% pipeline đến lead chuyển đổi cao mà không cần tăng headcount. Để đi sâu vào triển khai sales cụ thể, xem AI lead scoring vượt qua mô hình dựa trên rule.
2. Ưu tiên ticket support và định tuyến team
Một công ty B2B SaaS nhận 600 ticket support mỗi ngày. Model ingest text của mỗi ticket cùng với account data của khách hàng gửi: ARR, tier hợp đồng, usage patterns, lịch sử ticket, và ngày đến hạn gia hạn. Analyze phân loại intent (billing issue, technical bug, feature request, security concern), phát hiện sentiment, và kiểm tra các dấu hiệu rủi ro escalation.
Predict chấm điểm mức độ khẩn cấp: khách hàng ARR cao có billing issue ba tuần trước khi gia hạn đứng đầu bảng. Execute định tuyến ticket khẩn cấp cao đến account manager được chỉ định, vấn đề kỹ thuật đến đúng tier engineering, và feature request ưu tiên thấp vào backlog queue. Kết quả: vấn đề enterprise nhận phản hồi trong vài phút. Nhiễu L1 không chặn team nữa.
Các công cụ trong không gian này gồm Zendesk AI, Intercom ticket intelligence, và Freshdesk Freddy AI.
3. Sàng lọc resume và giao cho recruiter
Một công ty đăng 12 vị trí tuyển dụng và nhận 1.800 đơn ứng tuyển trong hai tuần. Model ingest từng resume và job description. Analyze trích xuất các tín hiệu liên quan: số năm trong vai trò tương ứng, kỹ năng được đề cập, công ty đã làm, trình độ học vấn, cấu trúc và mức độ đầy đủ của resume. Model so sánh từng resume với target profile của vai trò đó.
Predict tạo ra điểm phù hợp cho từng ứng viên với từng vai trò. Execute đưa top quartile lên cho recruiter của vai trò đó, định tuyến ứng viên ở vùng biên đến bước sàng lọc nhẹ hơn, và gửi cho nhóm dưới cùng phản hồi tự động. Lưu ý: đây cũng là nơi bias risk cao nhất. Phần dưới sẽ nói thêm.
Các công cụ gồm Eightfold, HireVue, Paradox, và các AI screening add-on của Greenhouse.
4. Yêu cầu bồi thường bảo hiểm fast-track vs. xem xét thủ công
Một công ty bảo hiểm xử lý 5.000 yêu cầu bồi thường mỗi tháng. Các yêu cầu đơn giản (va chạm nhẹ có ảnh tài liệu và trách nhiệm rõ ràng) có thể thanh toán trong 48 giờ nếu model cho điểm "fast-track". Các yêu cầu phức tạp cần chuyên gia giám định.
Model ingest dữ liệu form yêu cầu, ảnh đính kèm, lịch sử xe, lịch sử chủ hợp đồng, và hồ sơ bên thứ ba. Analyze trích xuất các chỉ số độ phức tạp: trách nhiệm có rõ ràng không? Có thương tích không? Số tiền yêu cầu có khớp với dữ liệu sự cố tương đương không? Lịch sử của người yêu cầu có pattern bất thường không?
Predict chấm điểm mỗi yêu cầu trên hai chiều: xác suất fast-track (có phải case thường xuyên không?) và xác suất gian lận (có khớp pattern gian lận đã biết không?). Execute định tuyến các yêu cầu fast-track, gian lận thấp đến thanh toán tự động; yêu cầu độ phức tạp trung bình đến chuyên gia giám định; và yêu cầu xác suất gian lận cao đến đơn vị điều tra đặc biệt.
Đây là một trong những use case được chứng minh tốt nhất cho pattern này, với các công ty bảo hiểm báo cáo giảm 30-40% chi phí xử lý trên phần lớn case thông thường.
5. Phát hiện gian lận trong thanh toán
Stripe Radar là một trong những hệ thống scoring được triển khai rộng rãi nhất thế giới, dù hầu hết operator nghĩ đến nó như "ngăn chặn gian lận" thay vì "AI." Với mỗi giao dịch thẻ, model của Stripe ingest card metadata, device fingerprint, số tiền giao dịch, merchant category, geographic data, và behavioral signals (tốc độ điền form, địa chỉ thanh toán và giao hàng có khớp không).
Analyze trích xuất features. Predict gán điểm xác suất gian lận: 99,5% (gần như chắc chắn gian lận) hoặc 0,2% (gần như chắc chắn hợp lệ). Execute hành động theo điểm đó: phê duyệt, chuyển sang 3D Secure review, hoặc chặn hoàn toàn.
Bước Execute ở đây rủi ro cực cao và xảy ra trong mili giây. Đó là lý do threshold calibration cực kỳ quan trọng. Ngưỡng đặt quá chặt sẽ chặn giao dịch hợp lệ và tạo chargeback từ khách hàng tức giận. Quá lỏng và fraud losses tăng lên. Ngưỡng đúng là quyết định kinh doanh, không chỉ là tham số model.
Score-Then-Execute Loop
Scoring and Routing hoạt động theo hai giai đoạn riêng biệt không được gộp lại: giai đoạn scoring nơi mỗi item đến nhận thứ hạng ưu tiên dựa trên features đã trích xuất và các pattern kết quả lịch sử, và giai đoạn execute nơi thứ hạng đó dẫn đến quyết định routing. Bỏ qua giai đoạn scoring và định tuyến thẳng từ rule (quy mô công ty, danh mục ticket) sẽ bỏ lỡ các tín hiệu context phân biệt enterprise lead ý định thấp với SMB lead ý định cao. Dùng thẳng model confidence chưa qua threshold validation làm routing trigger sẽ tạo ra routing instability trong lúc model calibrate. Cấu trúc hai giai đoạn, chấm điểm trước rồi execute dựa trên threshold đã được xác thực, là điều làm cho pattern này đáng tin cậy khi xử lý khối lượng lớn.
Failure modes: điều gì thực sự đi sai
| Failure mode | Nguyên nhân gốc rễ | Giải pháp |
|---|---|---|
| Bias trong training data | Model được train trên kết quả lịch sử bị lệch (reps cũ chỉ đóng từ mid-market; enterprise lead bị ưu tiên không công bằng) | Audit phân phối điểm theo từng segment. Kiểm tra tương quan nhân khẩu học trong dữ liệu ứng viên hoặc khách hàng. |
| Threshold calibration sai | Ngưỡng 70 điểm gửi 60% lead ý định cao đến junior rep vì cutoff không được xác thực với win rate thực tế | Validate threshold với kết quả thực. Coi việc đặt threshold là mục review kinh doanh hàng quý, không phải setup một lần. |
| Feature lỗi thời | Model được train trên dữ liệu Q1 bỏ lỡ product line mới ra mắt Q3, khiến prospect đã vào trang sản phẩm đó không được chấm điểm tốt | Thiết lập lịch retrain tự động gắn với thay đổi sản phẩm hoặc segment. Theo dõi score distribution drift theo thời gian. |
| Feedback loop thất bại | Không ai theo dõi lead đã định tuyến có thực sự đóng không, ticket có thực sự được giải quyết không, hay yêu cầu được định tuyến có thanh toán sạch không | Xây dựng outcome tracking vào workflow từ ngày đầu. Model cần labeled historical data để giữ được calibration. |
| Score lên cao nhưng không có hành động | Scoring chạy nhưng rep bỏ qua thứ tự queue; mọi người làm việc với pipeline của riêng mình | Hiển thị điểm rõ ràng trong giao diện workflow (CRM, support tool). Gắn performance metrics của team với việc tuân thủ scoring, không chỉ output. |
| Routing error im lặng | Execute gửi item đến queue sai mà không ai hay biết trong nhiều tuần | Log mọi quyết định routing. Xây dựng exceptions report để phát hiện mismatch giữa tier được chấm điểm và tier kết quả. |
Hai failure mode có tác động cao nhất (threshold calibration sai và feedback loop thất bại) cũng là hai cái ít thú vị nhất để sửa. Chúng không cần model mới. Chúng cần kỷ luật vận hành: review thường xuyên xem ai được định tuyến đến đâu, và quyết định routing đó có mang lại kết quả không.
Báo cáo AI Operations 2025 của Gartner phát hiện 68% các hệ thống AI scoring kém hơn benchmark ban đầu của mình đều bắt nguồn từ feedback loop failure. Model không bao giờ được retrain với kết quả mới, nên nó tiếp tục chấm điểm lead năm 2025 theo pattern học từ dữ liệu closed-won năm 2022.
Threshold calibration: đòn bẩy bị bỏ qua nhiều nhất
Hầu hết operator deploy scoring system dành 90% thời gian cho việc chọn model và 10% cho việc đặt threshold. Tỷ lệ đó đang bị đảo ngược so với giá trị thực tế.
Nhiệm vụ của model là xếp hạng các item. Nhiệm vụ của threshold là quyết định thứ hạng đó có nghĩa gì về mặt vận hành. Model lead scoring có thể xếp hạng chính xác 300 lead từ 1 đến 300. Nhưng nếu bạn đặt ngưỡng "ưu tiên cao" ở 60 trên 100 và 200 trong 300 lead chấm điểm trên 60, senior rep của bạn bị ngập lụt và phân khúc trở nên vô nghĩa.
Threshold calibration cần ba đầu vào: phân phối điểm của historical data, capacity vận hành của bạn tại mỗi routing tier (team enterprise xử lý được bao nhiêu item mỗi ngày?), và outcome data (khoảng điểm nào thực sự tương quan với win?). Khi có đủ ba thứ này, bạn đặt được threshold khớp với thực tế vận hành, không chỉ là statistical cutoff.
Xem lại threshold ít nhất mỗi quý. Thay đổi thị trường, thay đổi campaign mix, và mở rộng sản phẩm đều làm dịch chuyển score distribution bên dưới bạn.
Khi Scoring + Routing hoạt động, và khi không
Hoạt động tốt khi:
- Bạn có labeled historical outcomes. Model học từ dữ liệu cũ: lead nào đã đóng, yêu cầu nào là gian lận, ứng viên nào được tuyển và ở lại. Không có lịch sử có nhãn thì không có dự đoán có ý nghĩa.
- Bạn có volume. Scoring and Routing được đền đáp khi vấn đề phân loại là thực tế. Nếu bạn nhận 15 lead một tuần, một rep phân loại thủ công trong 10 phút. Nếu bạn nhận 500, bạn cần pattern này.
- Quyết định routing ánh xạ đến hành động cụ thể, có thể thực hiện. "Định tuyến đến team enterprise" là hành động được. "Xử lý lead này cẩn thận hơn" thì không.
- Dữ liệu đủ đầy đủ và nhất quán. Các trường thiếu (lead không có chức danh, ticket không có account link) làm giảm chất lượng dự đoán.
Cân nhắc lựa chọn khác khi:
vs. Anomaly Agent: Scoring and Routing gán ưu tiên trong các danh mục đã biết. Anomaly Agent gắn flag cho các item không thuộc danh mục nào (unknown unknown). Nếu bạn cần phát hiện các fraud pattern mới không trông giống bất kỳ fraud nào trước đây, Anomaly Agent là lựa chọn đúng. Scoring and Routing sẽ chấm điểm các case mới đó là rủi ro trung bình vì chúng trông như record bình thường, không phải vì chúng là fraud pattern quen thuộc.
vs. Workflow Copilot: Scoring hoạt động không cần người dùng. Copilot hỗ trợ người dùng trong lúc làm việc. Nếu quy trình của bạn cần phán đoán không thể ủy thác theo thuật toán (cuộc gọi sales enterprise phức tạp, đàm phán tinh tế, tình huống khách hàng nhạy cảm), Copilot hỗ trợ người thay vì thay thế quyết định phân loại của họ.
vs. Autonomous Agent: Scoring and Routing đưa ra một quyết định tại một điểm trong workflow. Autonomous Agent chạy vòng lặp nhiều bước, đưa ra nhiều quyết định để hoàn thành một mục tiêu. Scoring and Routing là module bên trong workflow lớn hơn. Autonomous Agents là workflow đầy đủ.
Tín hiệu ROI: đo thế nào để biết nó đang hoạt động
| Metric | Đo gì | Benchmark hợp lý |
|---|---|---|
| Speed-to-first-contact | Thời gian từ khi gửi lead đến khi rep outreach đầu tiên | Giảm 50-70% so với hàng đợi thủ công |
| Rep utilization theo tier | Tỷ lệ thời gian enterprise rep dành cho lead được chấm điểm enterprise | Baseline: ~40%. Với scoring: 65-80% |
| Win rate: có scoring vs. không scoring | So sánh tỷ lệ chuyển đổi qua các dải điểm cao/trung bình/thấp | Dải cao nên 2-3x win rate dải thấp trong triển khai đã chín |
| Ticket resolution time theo routing path | Ticket được AI định tuyến vs. sắp xếp thủ công | Giảm 20-35% time-to-resolution cho AI-routed |
| False positive rate | Item được đưa vào priority queue không xứng đáng ưu tiên | Theo dõi hàng quý; nhắm đến dưới 15% false positives trong tier enterprise |
| Score distribution drift | Phân phối điểm của model có đang dịch chuyển theo thời gian không | Gắn flag nếu điểm trung bình thay đổi hơn 10 điểm theo từng quý |
So sánh win rate giữa lead có chấm điểm và không chấm điểm là bằng chứng mạnh nhất. Nếu lead trong dải điểm trên đóng ở tỷ lệ 28% và lead trong dải dưới đóng ở 7%, model đang kiếm được tiền của mình. Nếu hai con số đó gần nhau, model không phân biệt được gì có ý nghĩa, và bạn đang có vấn đề về training data hoặc features.
Yêu cầu governance
Scoring and Routing chạm đến kết quả kinh tế của con người: hoa hồng của sales rep, offer việc làm của ứng viên, phê duyệt hoặc từ chối của khách hàng. Đó không phải lý do để tránh dùng nó. Đó là lý do để quản trị nó nghiêm túc.
Audit model mỗi quý. Kiểm tra phân phối điểm qua các segment nhân khẩu học, địa lý, và firmographic. Nếu model lead scoring của bạn có hệ thống cho điểm thấp hơn với lead từ các khu vực hoặc ngành cụ thể mà không có lý do kinh doanh, bạn đang có vấn đề bias dù model có "chính xác" về mặt kỹ thuật.
Xác định rõ quy trình human override. Bất kỳ rep nào cũng phải có thể gắn flag cho lead điểm thấp mà họ tin là ý định cao. Bất kỳ recruiter nào cũng phải có thể chuyển tay resume lên vòng tiếp theo. Quy trình override cần được log để bạn kiểm tra được liệu override có hệ thống khác với model prediction không, và liệu các override đó có đúng không.
Cadence retrain. Với hầu hết ứng dụng kinh doanh, retrain hàng quý là mặc định hợp lý. Hàng tháng nếu thị trường của bạn thay đổi nhanh. Hàng năm thì gần như luôn quá chậm. Bạn đang chấm điểm prospect 2025 bằng model 2023.
Tài liệu hóa cho ngành được quy định. Trong financial services, cho vay, bảo hiểm, và tuyển dụng, các quyết định scoring tự động có thể cần khả năng giải thích theo ECOA, GDPR Điều 22, hoặc luật AI cấp địa phương. Biết thẩm quyền của bạn. "Model nói vậy" không phải lý giải có thể bảo vệ cho quyết định tín dụng bất lợi.
Vendor và tooling landscape
| Use case | Công cụ chính |
|---|---|
| Lead scoring | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Định tuyến ticket support | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Sàng lọc ứng viên | Eightfold, HireVue, Paradox, Greenhouse AI |
| Phát hiện gian lận | Stripe Radar, Kount, Featurespace, Sardine |
| Yêu cầu bồi thường bảo hiểm | Shift Technology, Tractable, Cape Analytics |
| Custom scoring infrastructure | Pinecone (vector embeddings cho feature similarity retrieval), Tecton (feature stores), AWS SageMaker, Azure ML |
Với team xây dựng custom scoring: Pinecone và Weaviate thường được dùng cho similarity-based feature retrieval, nhưng core scoring model thường là gradient-boosted tree (LightGBM, XGBoost) hoặc fine-tuned LLM cho input nhiều text. Infrastructure quan trọng ít hơn chất lượng labeled historical data và độ nghiêm ngặt của threshold calibration.
Kết nối với AI Sales Operator
Scoring and Routing là một trong bốn pattern cốt lõi của AI Sales Operator (Level 3 trong ACE Framework). Trong bối cảnh đó, lead scoring không chỉ là tính năng marketing automation. Đó là lớp quyết định đầu funnel xác định cách mỗi ngày làm việc của rep được tổ chức. Khái niệm AI Sales Operator giải thích cách bốn pattern này phối hợp với nhau trong thực tế.
Các tổ chức sales hiệu suất cao nhất dùng scoring không chỉ để ưu tiên lead đến mà còn ưu tiên thời gian rep qua toàn bộ pipeline: deal nào cần đẩy, account nào cần engage để mở rộng, renewal nào có churn risk. Khi Scoring and Routing kết nối với Meeting Intelligence (phân tích cuộc gọi) và Workflow Copilot (gợi ý tích hợp CRM), ba pattern cùng nhau tạo thành closed loop: AI chấm điểm opportunity, AI phân tích cuộc gọi, AI gợi ý hành động tiếp theo.
Kiến trúc đó là điều phân biệt team sales được tăng cường AI với team chỉ có một công cụ AI để giao lead.
Rework Analysis: Hầu hết team triển khai lead scoring đều làm đúng model và sai vận hành. Model chấm điểm lead chính xác. Nhưng threshold được đặt một lần lúc launch, outcome data không bao giờ được đưa lại, và team không bao giờ audit xem lead điểm cao có thực sự đóng ở tỷ lệ cao hơn lead điểm thấp không. Sáu tháng sau, rep đã ngừng tin tưởng thứ tự queue và quay lại làm pipeline của riêng mình. ROI của model tan biến không phải vì AI thất bại mà vì feedback loop không bao giờ được xây dựng. Scoring and Routing đòi hỏi hai cam kết tổ chức, không phải một: một hệ thống scoring và một quarterly outcome review để giữ nó được calibrate. Team thực hiện cả hai thấy cải thiện 2-3x tỷ lệ chuyển đổi. Team chỉ thực hiện cam kết đầu thì thấy mọi thứ từ từ trôi ngược về phân loại thủ công.
Câu hỏi thường gặp
AI pattern Scoring and Routing là gì?
Scoring and Routing là AI pattern tự động ưu tiên và phân công các item đến (lead, ticket, đơn ứng tuyển, yêu cầu bồi thường) bằng công thức bốn bước: Ingest record đến và context, Analyze features đã trích xuất, Predict điểm ưu tiên, và Execute quyết định routing. Pattern xử lý triage ở volume mà đánh giá thủ công không thể theo kịp, và đánh giá đồng thời 20-50 tín hiệu so với 3-5 mà người làm triage thủ công thường nhìn vào.
AI lead scoring hoạt động như thế nào?
AI lead scoring ingest từng hồ sơ lead cộng với behavioral data (trang đã truy cập, email engagement, thời gian trên trang giá), trích xuất features (quy mô công ty, seniority chức danh, ngành, lịch sử CRM), rồi áp dụng model đã train để gán điểm xác suất. Model học từ historical outcomes: lead cũ nào với profile tương tự thực sự đã đóng. Điểm thúc đẩy routing: điểm cao đến senior rep với SLA cùng ngày, điểm trung bình đến SDR để qualification, điểm thấp vào chuỗi nurture tự động.
Failure modes phổ biến nhất trong Scoring and Routing là gì?
Hai failure mode có tác động cao nhất là threshold calibration sai và feedback loop thất bại. Threshold calibration sai gửi tỷ lệ sai lead đến mỗi routing tier, hoặc ngập senior rep với lead chất lượng trung bình hoặc định tuyến dưới mức với prospect ý định cao thực sự. Feedback loop thất bại xảy ra khi outcome data (ai đã đóng, ai churn, yêu cầu nào là gian lận) không được đưa lại để retrain model, khiến nó chấm điểm record hiện tại theo pattern lịch sử lỗi thời. Gartner phát hiện 68% hệ thống scoring kém hiệu quả đều bắt nguồn từ feedback loop failure.
Score-Then-Execute Loop là gì?
Score-Then-Execute Loop là cấu trúc hai giai đoạn của Scoring and Routing: đầu tiên giai đoạn scoring nơi mỗi item nhận thứ hạng ưu tiên từ features đã trích xuất và pattern kết quả lịch sử, sau đó giai đoạn execute nơi threshold đã được validate chuyển thứ hạng đó thành quyết định routing. Gộp hai giai đoạn, ví dụ như định tuyến thẳng từ rule-based threshold không qua model scoring, bỏ lỡ các tín hiệu context phân biệt lead ý định cao với lead ý định thấp. Dùng thẳng raw model confidence không qua threshold validation tạo ra routing instability.
Khi nào nên dùng Scoring and Routing thay vì Anomaly Agent?
Dùng Scoring and Routing khi cần triage item trong các danh mục đã biết: gán ưu tiên qua lead, ticket, hoặc đơn ứng tuyển đều theo các pattern quen thuộc. Dùng Anomaly Agent khi cần phát hiện item không thuộc danh mục nào, như fraud pattern mới không trông giống fraud cũ. Scoring and Routing sẽ chấm điểm fraud mới là rủi ro trung bình vì nó trông như giao dịch bình thường. Anomaly Agent gắn flag chính xác vì nó lệch khỏi statistical baseline.
ROI kỳ vọng từ Scoring and Routing là bao nhiêu?
Triển khai đã chín với 12+ tháng outcome data thấy cải thiện 2-3x tỷ lệ chuyển đổi trong tier lead có điểm cao nhất. Team sales thấy giảm 50-70% speed-to-first-contact. Định tuyến ticket support thường giảm 20-35% time-to-resolution. Công ty bảo hiểm báo cáo giảm 30-40% chi phí xử lý yêu cầu bồi thường. Đạt được các benchmark này đòi hỏi cả scoring system được calibrate và quarterly outcome review để retrain model trên closed data mới.
Tìm hiểu thêm

Co-Founder, Rework.com
On this page
- Công thức: Ingest, Analyze, Predict, Execute
- Năm ví dụ thực tế chi tiết
- 1. Lead scoring và giao cho rep
- 2. Ưu tiên ticket support và định tuyến team
- 3. Sàng lọc resume và giao cho recruiter
- 4. Yêu cầu bồi thường bảo hiểm fast-track vs. xem xét thủ công
- 5. Phát hiện gian lận trong thanh toán
- Score-Then-Execute Loop
- Failure modes: điều gì thực sự đi sai
- Threshold calibration: đòn bẩy bị bỏ qua nhiều nhất
- Khi Scoring + Routing hoạt động, và khi không
- Tín hiệu ROI: đo thế nào để biết nó đang hoạt động
- Yêu cầu governance
- Vendor và tooling landscape
- Kết nối với AI Sales Operator
- Tìm hiểu thêm