RAID Log: Seguimiento de Riesgos, Supuestos, Incidentes y Dependencias
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Un RAID log es el documento único que mantiene cuatro categorías que descarrilan proyectos en un solo lugar: riesgos, supuestos, incidentes y dependencias. La mayoría de los proyectos que superan sus presupuestos o plazos pueden rastrear el daño hasta una de esas cuatro categorías que nadie estaba vigilando activamente.
¿Qué es un RAID log?
Un RAID log es un documento de seguimiento estructurado usado en la gestión de proyectos para registrar y monitorear las cuatro categorías con mayor probabilidad de crear problemas en un proyecto: Riesgos (Risks), Supuestos (Assumptions), Incidentes (Issues) y Dependencias (Dependencies). Cada categoría tiene su propia sección (o sus propias filas con código de color), y el registro completo vive en un lugar compartido donde todas las partes interesadas pueden verlo.
El registro no es una herramienta sofisticada. Generalmente es una hoja de cálculo o una página dentro de su plataforma de gestión de proyectos. Lo que lo hace valioso es la disciplina: los equipos que revisan el RAID log regularmente detectan problemas semanas antes de que se conviertan en crisis.
Datos clave
- El concepto de RAID log surgió de las prácticas de PRINCE2 y del APM Body of Knowledge a principios de los años 2000 y ahora es estándar en el 78% de los proyectos del gobierno del Reino Unido (APM, 2023).
- Los proyectos que mantienen un RAID log activo tienen una tasa de retraso de cronograma significativo un 31% menor en comparación con los proyectos que no lo tienen (PMI Pulse of the Profession, 2024).
- La «I» de RAID (Incidentes) suele capturar 2 a 3 veces más entradas a lo largo de la vida del proyecto que la «R» (Riesgos), porque los riesgos que se materializan se convierten automáticamente en incidentes (datos de la comunidad PMI, 2023).
RAID: qué significa cada letra
RAID es un acrónimo. Cada letra cubre una categoría distinta de incertidumbre del proyecto, y la distinción importa porque cada tipo exige una respuesta diferente.
Riesgos (Risks)
Un riesgo es un evento potencial que aún no ha ocurrido pero podría ocurrir. Los riesgos tienen dos atributos clave: probabilidad (¿qué tan probable es que ocurra?) e impacto (¿qué tan grave sería si ocurriera?).
Ejemplo: Se sabe que un proveedor clave tiene retrasos en la entrega durante el cuarto trimestre. Aún no ha ocurrido en su proyecto, pero la probabilidad es real, y si el proveedor no cumple la fecha de entrega, la salida en producción se retrasa tres semanas.
Los riesgos se gestionan de forma proactiva: se asigna una puntuación de probabilidad, se acuerda un plan de mitigación y se revisan regularmente. Algunos equipos también registran un responsable del riesgo separado del director del proyecto, porque la persona mejor posicionada para monitorear un riesgo suele ser la que está más cerca de él.
Supuestos (Assumptions)
Un supuesto es algo que se trata como verdadero aunque no se haya confirmado formalmente. Todo proyecto opera sobre supuestos, y eso está bien, siempre que se escriban. El problema comienza cuando un supuesto resulta ser incorrecto y nadie lo nota hasta que el trabajo está a mitad.
Ejemplo: El plan del proyecto asume que el equipo legal revisará los contratos en cinco días hábiles. Ese supuesto está integrado en el cronograma. Si el departamento legal tarda en realidad tres semanas, el cronograma se rompe.
Documentar los supuestos obliga al equipo a validarlos temprano. Una vez confirmado, un supuesto se marca como «validado» y se retira del monitoreo activo.
Incidentes (Issues)
Un incidente es un problema que ya ha ocurrido. Es un riesgo que se materializó o un bloqueador que apareció sin previo aviso. Los incidentes necesitan atención inmediata, no monitoreo.
Ejemplo: El entorno de staging ha estado caído durante dos días, bloqueando las pruebas de QA. Eso ya no es un riesgo. Es un incidente activo que está desacelerando el proyecto en este momento.
Los incidentes se rastrean de manera diferente a los riesgos: necesitan un plan de respuesta hoy, no un plan de mitigación para algún día. También necesitan una ruta de escalamiento si el responsable no puede resolverlos dentro de un período definido.
Dependencias (Dependencies)
Una dependencia es una relación entre su proyecto y algo externo: el resultado de otro equipo, un entregable de un proveedor, una aprobación regulatoria o el hito de otro proyecto.
Ejemplo: Su construcción del front-end no puede comenzar hasta que el equipo de diseño entregue los wireframes aprobados. La fecha de salida en producción depende de que el equipo de infraestructura en la nube complete primero una auditoría de seguridad.
Las dependencias son peligrosas porque están fuera de su control directo. Rastrearlas en el RAID log significa que puede detectar bloqueos con anticipación y escalar o ajustar su plan del proyecto antes de que el retraso se convierta en una crisis.
Por qué usar un RAID log
La respuesta corta es que los proyectos tienen demasiadas partes móviles para rastrearlas informalmente. Un RAID log le da un mecanismo de forzado para sacar a la superficie la incertidumbre en lugar de enterrarla.
Fuente única de verdad. En lugar de que los riesgos vivan en la mente de alguien y los supuestos estén dispersos en correos electrónicos, el RAID log le da a todo el equipo un documento compartido. Quien se incorpore al proyecto a mitad puede leerlo y entender el panorama de inmediato.
Registro de auditoría para las decisiones. Cuando un riesgo se materializa y el patrocinador pregunta «¿por qué no lo sabíamos?», el RAID log muestra exactamente cuándo se registró el riesgo, quién era el responsable y cuál era el plan de mitigación acordado. Eso no es solo políticamente útil. Es cómo los equipos aprenden a gestionar mejor el riesgo en el próximo proyecto.
Reuniones de estado estructuradas. El RAID log convierte las reuniones de estado semanales de actualizaciones vagas en un recorrido estructurado. Se revisan los riesgos abiertos, se confirma que los supuestos siguen siendo válidos, se cierran los incidentes resueltos y se verifican las dependencias. Una reunión de 30 minutos con un RAID log logra más que una hora sin él.
Alineación con los marcos de gobernanza. Si su organización usa PRINCE2, el APM Body of Knowledge o los estándares del ciclo de vida del proyecto del PMI, el RAID log ya está incorporado en los requisitos de gobernanza. Mantener uno no es opcional. Es la línea base.
Columnas del RAID log (qué rastrear)

Todo RAID log debe capturar al menos estas columnas. Puede añadir más, pero no elimine ninguna de estas sin una buena razón.
| Columna | Propósito | Ejemplo |
|---|---|---|
| ID | Identificador único para cada entrada (facilita la referencia en las reuniones) | R-001, A-003, I-007, D-002 |
| Tipo | Qué categoría RAID: Riesgo, Supuesto, Incidente o Dependencia | Riesgo |
| Descripción | Enunciado claro en lenguaje sencillo de la entrada | El proveedor podría no entregar el hardware según el cronograma por una interrupción en la cadena de suministro |
| Fecha de registro | Cuándo se registró por primera vez la entrada | 2026-05-14 |
| Responsable | La persona encargada de monitorear o resolver esta entrada | Alex Kim |
| Gravedad | Para riesgos e incidentes: Baja / Media / Alta / Crítica según el impacto y la probabilidad | Alta |
| Estado | Estado actual: Abierto, En progreso, Resuelto, Cerrado, Validado (para supuestos) | Abierto |
| Mitigación / Respuesta | Qué acción se está tomando para reducir el riesgo, resolver el incidente o validar el supuesto | Identificar proveedor de respaldo; programar reunión de seguimiento semanal con el director del proyecto del proveedor |
| Próxima revisión | Cuándo se revisará esta entrada en la reunión de revisión del RAID log | 2026-06-07 |
La columna Gravedad es la parte más debatida de cualquier RAID log. Manténgala simple. Una escala de 3 puntos (Baja, Media, Alta) funciona para la mayoría de los proyectos. Una escala de 5 puntos está bien para programas grandes. Resista la tentación de integrar una matriz completa de probabilidad e impacto en cada fila. Eso pertenece a un registro de riesgos dedicado para proyectos de alto riesgo.
RAID log vs. registro de riesgos vs. registro de incidentes
Estas tres herramientas se superponen y los equipos suelen usarlas indistintamente. Pero sirven a diferentes alcances.
| RAID Log | Registro de riesgos | Registro de incidentes | |
|---|---|---|---|
| Alcance | Las cuatro categorías: Riesgos, Supuestos, Incidentes, Dependencias | Solo riesgos | Solo incidentes |
| Usuario habitual | Directores de proyecto, directores de programa | Gestores de riesgos, PMOs, equipos de cumplimiento | Directores de proyecto, equipos de soporte |
| Profundidad | Moderada: captura los campos clave para cada categoría | Profunda: incluye puntuaciones de probabilidad, calificaciones de impacto, mapas de calor | Profunda: incluye ruta de escalamiento, pasos de resolución, SLA |
| Mejor para | La mayoría de los proyectos, especialmente de complejidad media | Grandes programas, gobernanza empresarial, industrias reguladas | Operaciones, soporte de TI, entrega orientada al cliente |
| Cadencia de actualización | Semanal en las reuniones de estado | Mensual o impulsado por eventos | Diario o cuando surgen incidentes |
Para la mayoría de los equipos de proyecto, el RAID log es suficiente. Cubre todo en un solo lugar. El registro de riesgos y el registro de incidentes tienen sentido cuando una categoría (por ejemplo, los riesgos en un proyecto regulatorio de farmacéutica) necesita más profundidad de la que puede manejar un solo registro.
Cómo crear un RAID log: paso a paso
Paso 1: Elija su herramienta
Comience de forma simple. Una hoja de cálculo compartida en Google Sheets o Excel con una pestaña por categoría RAID (o filas con código de color en una sola hoja) funciona para la mayoría de los equipos. Si trabaja en una plataforma de gestión de proyectos, verifique si tiene una plantilla nativa de RAID log. Herramientas como Rework, Jira o Monday a menudo tienen una vista de registro estructurada que se integra con los datos de sus tareas.
Cualquier herramienta que elija debe ser compartida y accesible para todas las partes interesadas del proyecto. Un RAID log que vive en la carpeta del escritorio de una sola persona derrota todo el propósito.
Paso 2: Configure sus columnas
Use el conjunto de columnas de la sección anterior como línea base. Añada una columna de «Prioridad» o «Indicador de escalamiento» si su organización lo requiere. Mantenga el número de columnas manejable. Los registros con 20 columnas raramente se completan de forma consistente.
Paso 3: Llene el registro en el inicio del proyecto
El mejor momento para iniciar un RAID log es durante el taller de inicio. Realice una lluvia de ideas estructurada con el equipo central: ¿Qué podría salir mal? ¿Qué estamos asumiendo? ¿Qué estamos esperando de otros equipos? Esta población inicial lleva de 30 a 60 minutos y saca a la superficie los puntos ciegos de inmediato.
En el inicio, concéntrese especialmente en los supuestos. La mayoría de los proyectos tiene de 10 a 20 supuestos tácitos que nadie ha escrito. Llevarlos al papel es en sí mismo un acto de reducción de riesgos.
Paso 4: Revise el registro en cada reunión de estado
El registro solo es útil si está vivo. Reserve de 10 a 15 minutos en su reunión de estado semanal para revisar las entradas abiertas: actualice los estados, confirme las próximas fechas de revisión, escale lo que se ha vuelto urgente y cierre lo que se ha resuelto. Durante las fases del ciclo de vida del proyecto que implican muchas dependencias externas, puede que necesite revisar el registro más de una vez por semana.
Paso 5: Archive las entradas resueltas
No elimine las entradas cerradas. Muévalas a una pestaña de «Archivados» o cambie su estado a «Cerrado». Los incidentes resueltos y los supuestos validados forman parte del conocimiento institucional de su proyecto. El próximo director de proyecto que gestione un proyecto similar le agradecerá haber dejado un registro claro de lo que sucedió y cómo se manejó.
Plantilla de RAID log
Copie esta estructura de tabla en su herramienta preferida. Añada una fila por entrada.
| ID | Tipo | Descripción | Fecha de registro | Responsable | Gravedad | Estado | Mitigación / Respuesta | Próxima revisión |
|---|---|---|---|---|---|---|---|---|
| R-001 | Riesgo | El proveedor clave podría no cumplir la entrega del Q3 por problemas en la cadena de suministro | 2026-05-10 | Alex Kim | Alta | Abierto | Identificar proveedor de respaldo; llamada semanal con el director del proyecto del proveedor | 2026-06-07 |
| A-001 | Supuesto | Legal revisará los contratos en 5 días hábiles | 2026-05-10 | Priya Sharma | Media | Sin validar | Confirmar SLA con el director legal antes del 2026-05-20 | 2026-05-20 |
| I-001 | Incidente | Entorno de staging caído; pruebas de QA bloqueadas por 48 horas | 2026-05-28 | Sam Torres | Crítico | Abierto | Ticket de TI levantado; escalado al líder de infraestructura | 2026-05-29 |
| D-001 | Dependencia | Construcción del front-end en espera de wireframes de diseño del equipo de UX | 2026-05-10 | Jamie Lee | Media | En progreso | Diseño confirmó entrega para el 2026-05-22 | 2026-05-22 |
Ejemplos de RAID log
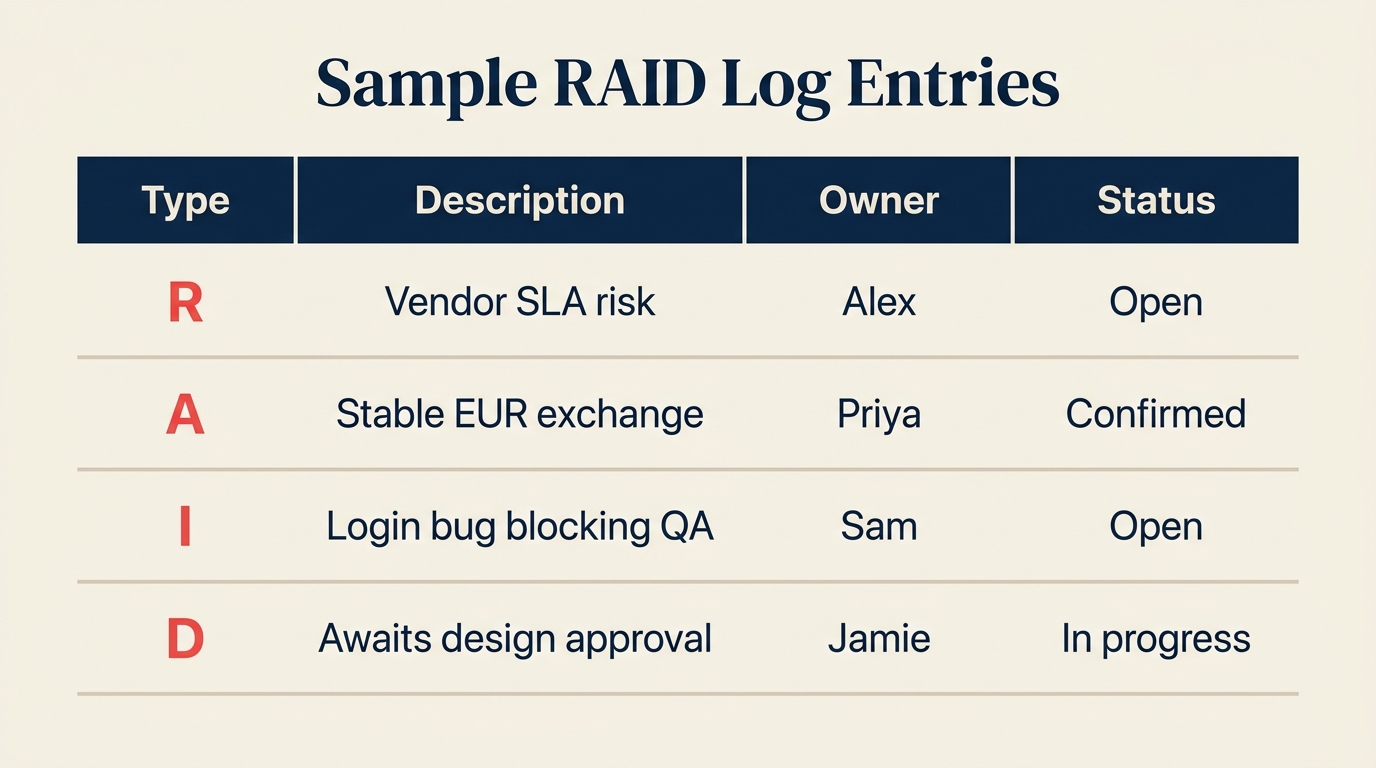
Así es como se ve un RAID log realista para un lanzamiento de software de tamaño mediano. Observe cómo cada tipo de entrada exige una respuesta diferente aunque estén en el mismo documento.
| ID | Tipo | Descripción | Responsable | Gravedad | Estado | Respuesta |
|---|---|---|---|---|---|---|
| R-002 | Riesgo | El cambio en la tasa de cambio EUR/USD podría aumentar el costo de licencias de terceros en un 12% | Priya Sharma | Media | Abierto | Acordar precios de contrato anual antes de la renovación del Q3 |
| A-002 | Supuesto | La tasa de cambio de divisas se mantiene estable dentro de una variación del 5% durante la duración del proyecto | Priya Sharma | Media | Confirmado | Validado con Finanzas el 2026-05-15 |
| I-002 | Incidente | Bug de inicio de sesión que bloquea todos los casos de prueba de QA en Chrome v124 | Sam Torres | Alta | Abierto | Ticket de desarrollo D-4421 levantado; parche programado para el 2026-06-03 |
| D-002 | Dependencia | Conjunto de funcionalidades final en espera de aprobación de diseño del líder de producto | Jamie Lee | Alta | En progreso | Revisión de diseño programada para el 2026-06-02; bloqueante si se retrasa más allá del 2026-06-05 |
El riesgo (R-002) y el supuesto (A-002) están estrechamente vinculados: el riesgo es lo que sucede si el supuesto se rompe. Ese es un patrón común. Cuando registra un supuesto, vale la pena preguntarse «¿cuál es el riesgo si este supuesto es incorrecto?» y registrar ese riesgo en la misma sesión.
Para la dependencia (D-002), observe cómo la entrada especifica tanto la fecha de entrega esperada como un «umbral de bloqueo», la fecha a partir de la cual todo el cronograma está en riesgo. Esa precisión es lo que hace que un RAID log sea realmente útil en las reuniones en lugar de solo un ejercicio de marcar casillas.
Si su equipo usa una matriz RACI, puede hacer referencias cruzadas de los responsables del RAID log directamente con los roles responsables del RACI. Esto elimina la ambigüedad sobre quién es responsable de la resolución de cada entrada.
Errores comunes
| Error | Mejor enfoque |
|---|---|
| Solo registrar riesgos, ignorar los supuestos | Llene las cuatro categorías en el inicio; los supuestos son a menudo donde mueren los proyectos |
| Tratar el registro como de solo lectura después del inicio | Revíselo y actualícelo cada semana; un registro obsoleto da una falsa confianza |
| Usar descripciones vagas («problemas de comunicación») | Escriba descripciones específicas y verificables («Las partes interesadas del cliente no han confirmado la aprobación del documento de alcance antes del 2026-06-01») |
| Registrar todo como gravedad Alta | Calibre la gravedad con honestidad; si todo es alto, nada recibe atención |
| No asignar responsable a cada entrada | Cada entrada debe tener un responsable nombrado. No un equipo. Una persona. |
| Eliminar las entradas resueltas | Archívelas. Las entradas cerradas son memoria institucional. |
| Confundir riesgos con incidentes | Un riesgo aún no ha ocurrido. Un incidente sí. Mantenga la distinción clara para que las respuestas sean apropiadas. |
Mejores prácticas
- Comience en el inicio, no a mitad del proyecto. Un RAID log construido dos meses después del inicio del proyecto está tratando de ponerse al día. La fuente más rica de riesgos, supuestos y dependencias es el taller de inicio, cuando el equipo está pensando activamente en el trabajo por delante.
- Nombre a los responsables de forma específica. «El equipo» no es un responsable. Asigne cada entrada a una persona por nombre. Esa persona es responsable de actualizar la entrada y escalar si es necesario.
- Vincule las entradas del RAID al cronograma. Si una dependencia no se resuelve en una fecha determinada, ¿qué tareas se retrasan? Conecte el RAID log con su diagrama de Gantt o ruta crítica para que el impacto en el cronograma sea visible.
- Revise semanalmente sin falta. Omita dos semanas y el registro se convierte en ficción. Las entradas permanecen en «Abierto» indefinidamente, los responsables olvidan sus obligaciones y el registro pierde credibilidad.
- Escale los bloqueantes temprano. Si un incidente no se resuelve después de dos ciclos de revisión sin progreso, escálelo al patrocinador del proyecto. El RAID log hace que esa escalada sea fácil de justificar porque el historial está ahí mismo.
- Mantenga las descripciones específicas y basadas en hechos. «El proveedor está tarde» no sirve. «El proveedor ha confirmado que las piezas llegarán de 10 a 14 días tarde, trasladando las pruebas de integración del 2026-06-10 al 2026-06-24» es accionable.
- Use el registro para preparar las reuniones del comité directivo. Extraiga los elementos abiertos de mayor gravedad y preséntelos como un resumen breve. Las partes interesadas que ven un RAID log bien mantenido confían en la capacidad del director del proyecto para controlar el trabajo.
- Intégrelo con su estructura de desglose del trabajo. Los programas grandes se benefician de que las entradas del RAID estén etiquetadas con elementos específicos de la WBS, lo que facilita ver qué flujos de trabajo conllevan mayor riesgo.
Preguntas frecuentes
¿Cuál es la diferencia entre un RAID log y un registro de riesgos?
Un registro de riesgos cubre solo riesgos, generalmente con mayor profundidad. Suele incluir puntuaciones de probabilidad, calificaciones de impacto y un plan de respuesta al riesgo completo con contingencias. Un RAID log cubre las cuatro categorías (Riesgos, Supuestos, Incidentes, Dependencias) en un solo documento con profundidad moderada. La mayoría de los equipos de proyecto comienzan con un RAID log. Los programas altamente regulados en finanzas, farmacéutica o gobierno suelen mantener un registro de riesgos separado junto al RAID log solo para la categoría de riesgos.
¿Quién es el responsable del RAID log?
El director del proyecto es el responsable del registro como documento y es quien lo mantiene actualizado. Pero cada entrada individual tiene su propio responsable, la persona encargada de monitorear o resolver ese elemento específico. Un RAID log bien gestionado es un documento del equipo, no la lista de pendientes personal del director del proyecto.
¿Con qué frecuencia se debe actualizar el RAID log?
Como mínimo, una vez por semana en la reunión de estado regular. Los incidentes de alta gravedad a menudo necesitan actualizaciones diarias. Los supuestos deben revisarse cada vez que se toma una decisión importante del proyecto, porque las decisiones frecuentemente invalidan supuestos que se registraron al inicio.
¿Cuál es la diferencia entre un riesgo y un incidente?
El tiempo. Un riesgo es un evento futuro potencial que aún no ha ocurrido. Un incidente es un problema que ya está sucediendo. Cuando un riesgo se materializa, se mueve de la sección de Riesgos a la sección de Incidentes y se pasa de un plan de mitigación a un plan de resolución. Esa transición es importante de rastrear porque el tipo de respuesta cambia completamente.
¿Los equipos Agile usan RAID logs?
Sí, aunque el formato se adapta. Los equipos de metodologías Agile y Scrum a menudo sacan a la superficie los elementos del RAID durante las retrospectivas del Sprint o el refinamiento del Backlog en lugar de en una revisión semanal dedicada. Algunos equipos Agile mantienen un tablero RAID ligero junto a su tablero de Sprint, rastreando las dependencias en particular, ya que las dependencias entre equipos son uno de los mayores bloqueantes en la entrega Agile a escala. Las cuatro categorías son igual de relevantes en Agile que en waterfall. Solo cambia la cadencia de revisión.
Un RAID log funciona porque impone una disciplina que la mayoría de los equipos resiste: escribir lo que aún no saben y en qué están contando que sea verdad. Esa incomodidad es exactamente el punto. Los proyectos no fracasan porque los equipos sean malos haciendo el trabajo. Fracasan porque no sacaron a la superficie las incertidumbres correctas con suficiente anticipación para actuar sobre ellas. Comience su RAID log en el inicio, manténgalo vivo durante cada reunión de estado, y las cuatro letras lo salvarán de las cuatro formas más comunes en que los proyectos se desmoronan.

Senior Operations & Growth Strategist
On this page
- ¿Qué es un RAID log?
- RAID: qué significa cada letra
- Riesgos (Risks)
- Supuestos (Assumptions)
- Incidentes (Issues)
- Dependencias (Dependencies)
- Por qué usar un RAID log
- Columnas del RAID log (qué rastrear)
- RAID log vs. registro de riesgos vs. registro de incidentes
- Cómo crear un RAID log: paso a paso
- Paso 1: Elija su herramienta
- Paso 2: Configure sus columnas
- Paso 3: Llene el registro en el inicio del proyecto
- Paso 4: Revise el registro en cada reunión de estado
- Paso 5: Archive las entradas resueltas
- Plantilla de RAID log
- Ejemplos de RAID log
- Errores comunes
- Mejores prácticas
- Preguntas frecuentes