More in
AI at Work Insights
The Coordination Tax: The Hidden Cost That Kills Operational Velocity
Apr 13, 2026
Measuring AI ROI Beyond 'Time Saved'
Mar 17, 2026
The Governance Gap: What Leaders Get Wrong About AI at Work
Mar 5, 2026
AI Agents in the Sales Pipeline: Hype, Reality, and What's Actually Working
Jan 22, 2026
AI Copilots vs. AI Agents: Understanding the Difference Matters
Jan 21, 2026 · Currently reading
AI Copilots vs. AI Agents: Understanding the Difference Matters

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Vendors use "copilot" and "agent" interchangeably. That's one of the more expensive confusions in enterprise software right now. Buying a copilot when you need an agent (or vice versa) isn't a minor misalignment. It shapes the operating model, the human roles around the technology, and the risk tolerance required to deploy it successfully. Leaders who don't understand this distinction are making AI investment decisions based on marketing language.
This matters practically, not theoretically. The operational implications of these two categories are fundamentally different, and the CRM market (where AI features are now standard) is a useful lens for understanding why.
The definitional split
A copilot augments a human's decision. It provides information, generates drafts, surfaces recommendations, and flags patterns. But a human reviews the output and takes the action. The AI is in the suggestion business, not the action business.
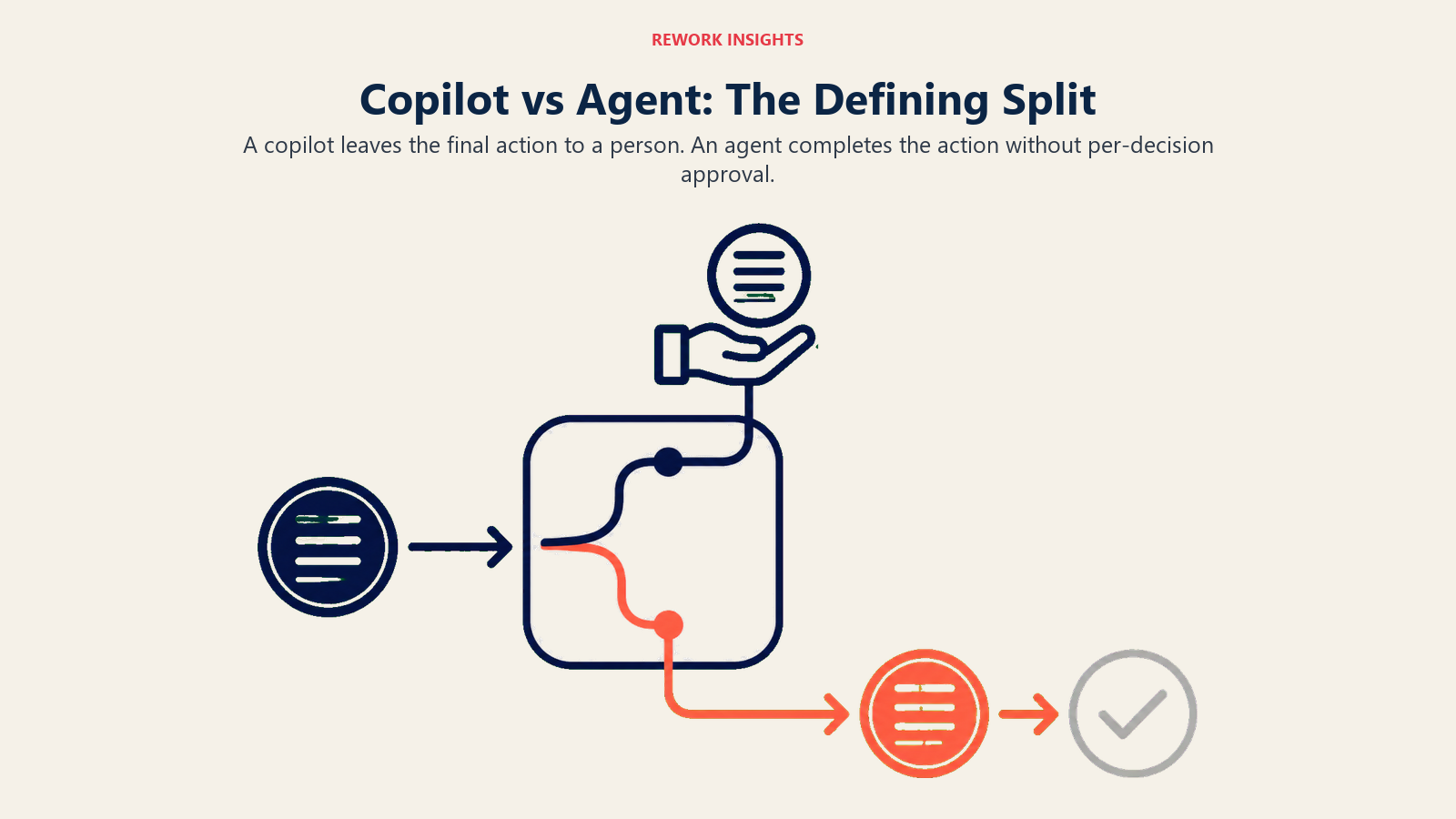
An agent takes action within defined bounds without per-decision approval. It executes tasks, triggers workflows, sends communications, and updates records based on its own outputs. A human defines the parameters and reviews the results, but doesn't approve each action in real time. OpenAI's research on agentic AI systems distinguishes between single-step AI assistance and multi-step autonomous execution — a distinction that maps directly onto the copilot-agent split buyers encounter in enterprise software. Understanding AI workflow automation as a category helps here — the line between "automated workflow" and "AI agent" is thinner than most buyers realize.
The distinction sounds clean until you apply it to real products. HubSpot's AI email composition feature, which drafts a sales email for a rep to review and send, is a copilot. A tool that identifies high-intent leads and automatically enrolls them in a specific sequence without rep involvement is an agent. But when HubSpot's AI scores a contact and that score automatically triggers a workflow that routes the contact to a different queue, is that a copilot or an agent?
It's an agent. The action happens without human approval at the decision point. But most buyers don't think of it that way when they're clicking through a product demo.
Why this distinction is purchase-critical
When you buy a copilot, you're buying a productivity tool. Change management is about adoption: getting people to use the suggestion instead of ignoring it. Failure modes are limited because a human is always between the AI output and the real-world consequence. If the email draft is bad, the rep doesn't send it.
When you buy an agent, you're buying a process redesign. Change management is about operating model restructuring: which decisions are now made by the AI, which roles change as a result, what human review looks like in the new flow, and how you handle the agent's errors before they cause downstream damage. The integration requirements are deeper. The implementation timeline is longer. The organizational change required is more significant.
Companies that buy agents expecting copilot-level deployment effort typically get one of two outcomes. Either the agent gets deployed without adequate oversight design, and errors accumulate until someone reviews the output and discovers a problem. Or the agent gets constrained to copilot behavior post-deployment, the parameters tightened so much that it needs human approval for every action, which means you paid agent pricing for copilot functionality.
The integration requirements also differ substantially. Salesforce Einstein's opportunity scoring feature (a copilot) can generate useful outputs even if your CRM data has gaps, because a sales manager reviews the score and applies their own judgment. An agent that routes leads to different sequences based on AI scoring needs clean, consistent data to function correctly, because there's no human review gate between the AI output and the action. Getting CRM workflow automation right before adding AI agents on top of it is one of the most practical ways to reduce deployment risk. The same product, used agentically rather than as a copilot, requires a much higher data quality floor.
The middle category nobody talks about: supervised agents
Most enterprise AI deployments don't fit cleanly into either category. They operate as supervised agents: systems that take actions autonomously but within a review architecture where humans see what the agent did and can reverse it.
A supervised agent might automatically send a follow-up email to a prospect, but log every sent email in a dashboard that a manager reviews daily. Or it might update a lead's score and trigger a routing change, but flag the change for human confirmation before it fully executes. The automation exists, but so does the oversight layer.

This is where most CRM AI features actually live in production. Zoho Zia's sales predictions get applied to pipeline reports that sales managers review. HubSpot's predictive lead scores inform rep prioritization without fully replacing human judgment about which leads to call. Salesforce Einstein's next-step recommendations get followed some of the time, by some reps, in some situations.
The supervised agent category is useful because it acknowledges that the copilot-agent distinction is a spectrum, not a binary. But it also raises the operational question that most buyers don't ask: what does the review architecture look like? Who reviews the agent's actions, with what frequency, and how easy is it to override or reverse what the agent did?
Companies that deploy supervised agents without answering those questions get a ghost governance problem: the agent is technically supervised, but nobody is actually looking at the dashboard, so the supervision is nominal. The governance gap that agentic AI creates for CEOs is a useful complement here — it covers what the oversight failure looks like from the executive level when supervised agents go unwatched.
Role design implications
The most underappreciated consequence of this distinction is what it does to human roles. MIT Sloan Management Review's research on AI and the future of work consistently finds that organizations underestimate the role redesign required when AI moves from assistive to autonomous — the skill shift isn't just "learn to use the tool," it's "redefine what judgment calls the human is responsible for."
When copilots are the standard, human roles change at the task level. A rep who used to spend 20 minutes writing prospecting emails now spends 5 minutes editing AI drafts. The job title stays the same. The skill requirement shifts slightly toward judgment and editing, and away from drafting. But the core role structure is intact.
When agents are operating autonomously in the workflow, roles change at the structural level. If an agent handles lead qualification and initial outreach, the SDR role doesn't disappear. Its scope narrows to the tasks the agent can't handle: complex conversations, relationship-building, handling objections, reading context that isn't in the CRM. Managers spend less time monitoring activity and more time reviewing agent output quality and handling exceptions. The skill mix that matters changes substantially.
This is why buying agents without a role design conversation is a mistake. The technology works differently than it was used before, which means the team needs to work differently too. Skipping that conversation doesn't eliminate the role change. It just makes it messy and unintended. AI change management strategies covers how to run that conversation in a way that doesn't generate resistance before deployment starts.
A practical approach: before deploying any agent-category AI tool, map the workflow it's entering and identify which human tasks it changes or removes. Then explicitly decide what those humans do instead. Not as a threat, but as a design question. The answer often reveals that the agent creates capacity for higher-value work, but only if that work is defined and enabled.
The Autonomy-Stakes Grid
A useful framework for matching AI category to business process is a simple 2x2: autonomy on one axis (how much can the AI act without per-decision human approval), stakes on the other (what goes wrong if the AI is wrong).

High autonomy, low stakes: Good fit for full agents. Sending a routine follow-up email to a warm lead, updating contact records with enriched data, generating post-call summaries. If the AI is wrong, the consequence is minor and easily corrected. Full autonomy is appropriate.
High autonomy, high stakes: Requires supervised agents at minimum. Routing inbound leads to different sales tiers, adjusting deal probability scores that inform sales forecasts, triggering contract renewal communications. The action has material consequences, but the scale of the problem makes full human review impractical. Supervised agent design with proper review architecture is the right category.
Low autonomy, low stakes: Good fit for copilots. Drafting emails, suggesting next steps, surfacing contact history before a call. The stakes are low enough that human review isn't burdensome, and the AI assists rather than acts.
Low autonomy, high stakes: Copilots or heavily constrained supervised agents. Performance evaluation AI, legal document review, pricing recommendations for large deals. The stakes require human judgment to be in the loop at the decision point. AI assists; humans decide.
Most AI buying decisions skip this mapping exercise entirely. The result is agents deployed in high-stakes, low-review environments, or copilots deployed where agents would actually be more effective. Gartner's AI hype cycle research places autonomous AI agents near the peak of inflated expectations — the vendors promising full autonomy are typically selling to buyers who haven't mapped their actual risk tolerance against the autonomy-stakes grid. The 2x2 takes about 30 minutes to complete for a specific workflow and saves months of implementation problems.
How CRM AI features map onto the spectrum
It's worth being specific about where major CRM AI features sit, because the marketing language doesn't always match the operational reality.

Salesforce Einstein includes features across the spectrum. Einstein Conversation Insights (which summarizes call transcripts) is a copilot. Einstein Lead Scoring (which assigns a score but doesn't act on it) is also a copilot. Einstein Prediction Builder, configured to trigger workflow actions, is an agent. The same platform holds multiple categories of AI behavior, and buyers should identify which features they're deploying and in which category each sits.
HubSpot AI similarly spans the spectrum. AI-assisted email composition and meeting scheduling recommendations are copilots. Automated sequence enrollment based on lead score crossing a threshold is an agent. The distinction is whether there's a human action required between the AI output and the real-world consequence.
Zoho Zia's capabilities map similarly: its predictions are copilots, but its automation triggers (where Zia's analysis directly initiates a CRM workflow) are agents.
This isn't a criticism of any platform. It's a description of how AI features work operationally, and why treating all AI features in a CRM as a single category is analytically incorrect.
Three questions to ask any AI vendor
Before any AI vendor conversation concludes, get answers to these three questions:
"Walk me through what the AI does after it generates an output. Specifically, what triggers the next action and who has to approve it." This question separates copilots from agents in practice. If the answer is "the user reviews and takes action," that's a copilot. If the answer is "the system automatically...," that's an agent. Vendors will sometimes describe agents as copilots to reduce buyer anxiety. This question makes the operational reality visible.
"What does your review and override interface look like?" Ask to see it, not hear about it. Any supervised agent worth deploying has a functional, visible audit trail and override mechanism. If the vendor struggles to show you this, the review architecture is underdeveloped.
"What's your recommended implementation sequence for a company that hasn't deployed AI agents before?" Experienced vendors will describe a phased approach: start with copilot features, build organizational familiarity with AI outputs, then introduce supervised agents with oversight, then move toward full agent autonomy in low-stakes workflows. Vendors who recommend starting with full autonomy in complex workflows are optimizing for their deployment metrics, not your outcomes.
The copilot-agent distinction won't stay static. As confidence in AI systems grows and oversight architectures mature, the supervised agent category will expand. More decisions that currently require human review will shift to supervised autonomy. But that shift should be deliberate and informed by operational experience with each category, not by vendor roadmaps or competitive pressure.
The companies building real competency with AI right now are the ones who understand what category of technology they're actually deploying, what it requires to work, and what role humans play in the system they're building. That starts with being precise about the distinction between copilots and agents.
Learn More

Co-Founder, Rework.com