More in
AI at Work Insights
The Coordination Tax: The Hidden Cost That Kills Operational Velocity
Apr 13, 2026
Measuring AI ROI Beyond 'Time Saved'
Mar 17, 2026 · Currently reading
The Governance Gap: What Leaders Get Wrong About AI at Work
Mar 5, 2026
AI Agents in the Sales Pipeline: Hype, Reality, and What's Actually Working
Jan 22, 2026
AI Copilots vs. AI Agents: Understanding the Difference Matters
Jan 21, 2026
Measuring AI ROI Beyond 'Time Saved'
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Every AI vendor case study reports "40% time saved" or "3 hours per rep per week." These numbers are not ROI. They're activity metrics, and they will not survive a CFO review.
The problem isn't that time savings are meaningless. It's that time savings are an input metric, not an outcome metric. Hours freed up are only valuable if they're redirected to something that generates revenue, reduces cost, or reduces risk. A pilot that saves three hours per rep per week is worthless if those three hours go into longer lunch breaks and scrolling LinkedIn. And most pilot reports don't track what the saved time was actually used for, which means the ROI claim is hypothetical at best.
The companies building genuine business cases for AI investment have moved past time-saved calculations. They're measuring revenue impact, quality improvement, capability extension, and risk reduction. None of those dimensions appear in a standard pilot report, but all of them are measurable if you design for measurement from the start. AI performance measurement covers the instrumentation side — how to set up the measurement infrastructure before a pilot rather than assembling it retroactively.
Why time-saved metrics fail
The most seductive thing about time-saved metrics is that they're easy to calculate and they sound big. "AI saves our sales team 15 hours per week" is a clean, quotable number. Multiply by average fully-loaded cost per hour, and you get an annualized savings figure that looks compelling in a slide deck.

But the calculation has three structural problems:
Problem 1: They don't track reallocation. Time saved is only as valuable as what the time is redirected toward. If a rep saves 15 hours of note-taking per week and spends that time on more prospecting, the value is real. If they spend it on administrative tasks that weren't being done before, the value is real but different. If the time dissipates into unstructured activity, the value is zero. Most pilots measure hours saved, not hours redirected.
Problem 2: They decay. The novelty efficiency bump is real but temporary. When a new productivity tool is introduced, usage is high, teams are motivated, and time savings are at their peak. McKinsey's research on generative AI adoption found that most organizations see productivity gains compress significantly after the initial deployment phase — the "productivity plateau" is a structural phenomenon, not a sign of failed implementation. Six months later, the tool has become part of baseline workflow, the novelty has worn off, and some of the initial time savings have been absorbed by the overhead of managing the tool itself. ROI calculations based on peak-period measurements consistently overstate long-term value.
Problem 3: They're easy to game. When a pilot is evaluated on hours saved, the people being measured have an incentive to report high numbers. Self-reported time savings in vendor case studies have a reliability problem that CFOs are right to be skeptical of. Independent measurement of pre-and-post time allocation requires a methodology that most pilot programs don't implement.
The CFO question isn't "how much time did this save?" It's "what did you do with it, and how do I know?" Most AI pilot teams can't answer the second part of that question. That's the gap this framework is designed to close.
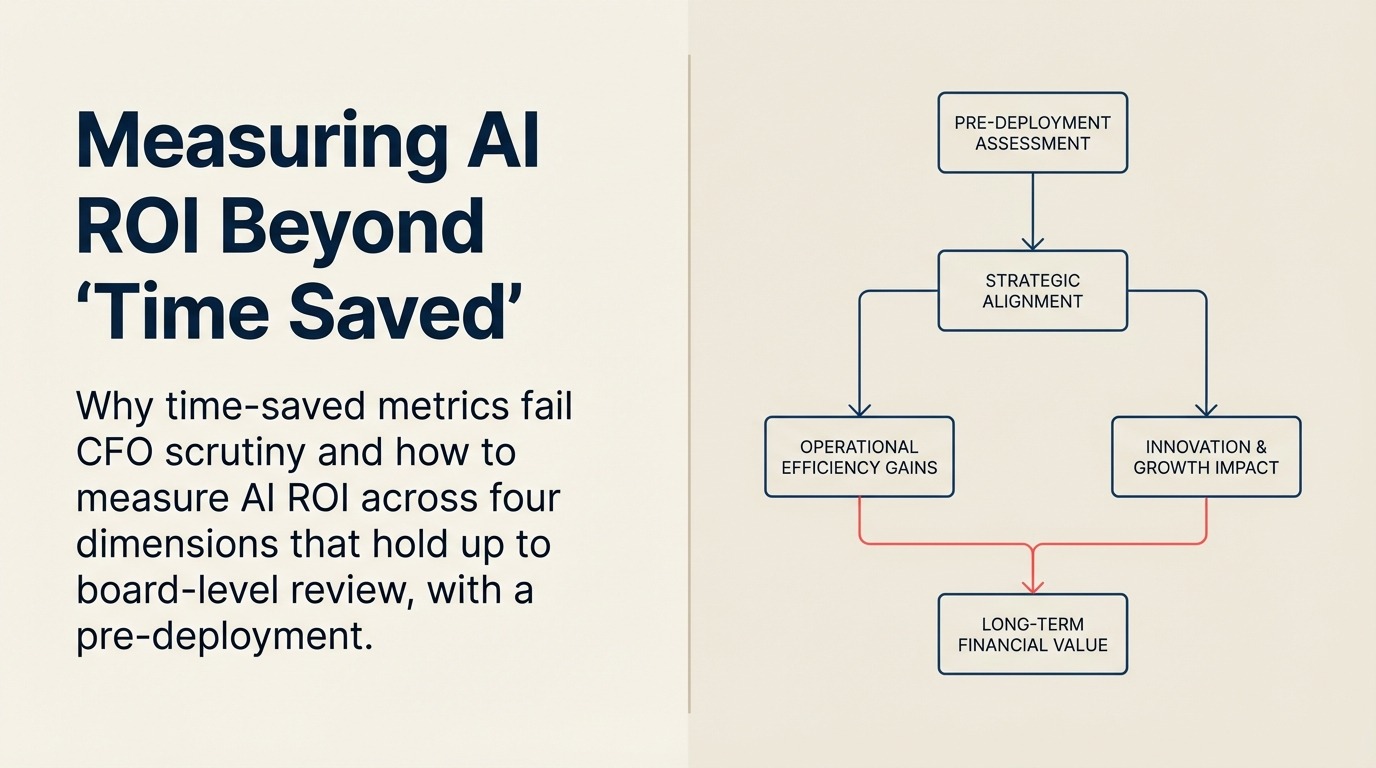
Four dimensions of AI ROI
A complete AI ROI picture covers four distinct dimensions. Most organizations measure one or two. Building a case that holds up at the board level requires measurement design across all four from the start of deployment.
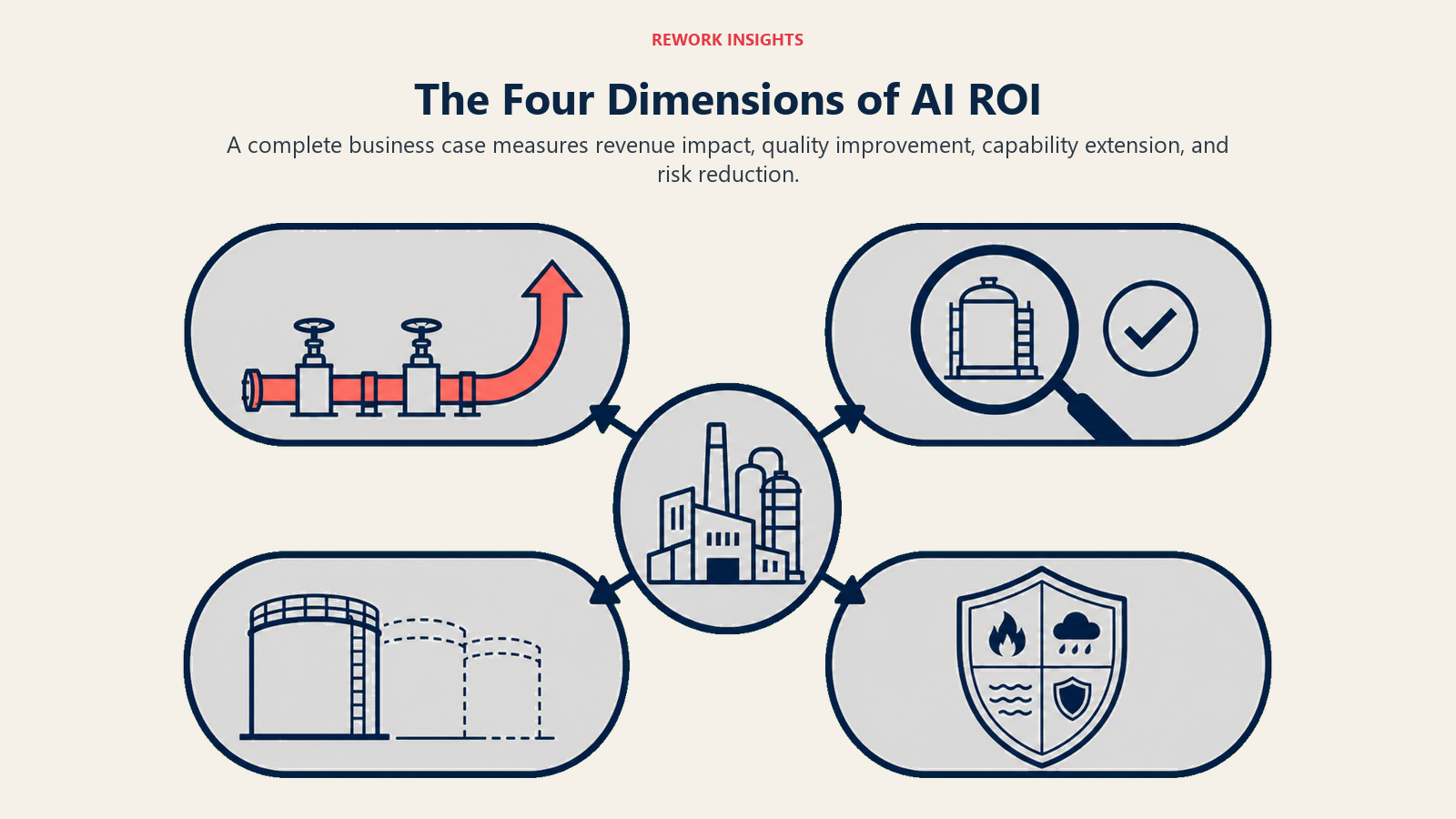
Dimension 1: Revenue impact. The most direct measure of AI ROI in a sales or revenue context. This includes pipeline velocity (do deals move faster when AI is involved in qualification or follow-up?), conversion rate changes (do leads handled with AI assistance convert at a higher rate?), and deal size effects (do AI-assisted proposals or pricing recommendations produce larger initial deal values?).
Revenue impact is the most powerful dimension because it's denominated in the currency leadership cares about most. But it's also the hardest to attribute cleanly, because AI-assisted deals also involve human judgment, market conditions, and relationship factors that all affect outcome. Revenue attribution in general is a notoriously hard problem — why attribution is broken in most RevOps setups is worth reading before you design your comparison group, because the same attribution gaps that distort marketing ROI will distort your AI ROI claims if you don't account for them. Clean measurement requires comparison groups: same rep population, similar lead quality, different tool access. Most pilot programs don't design this in from the start, which is why they can't make revenue impact claims that survive scrutiny.
Dimension 2: Quality improvement. AI consistently improves output consistency even when it doesn't improve speed. Error rate reduction in CRM data entry, consistency in proposal language, accuracy in follow-up cadence, completeness of call logging: these are quality dimensions that affect long-term pipeline health and compliance. They're harder to monetize directly but easier to measure than revenue impact.
When Salesforce Einstein's activity capture features improve CRM data completeness from 60% to 85%, the quality improvement is measurable. But getting to a reliable baseline requires your CRM data model to be properly structured first — if required fields aren't defined consistently, completeness percentages measure different things pre- and post-deployment. When AI-assisted proposal generation reduces legal review cycles because the language is more consistent, that's a quality improvement with a real cost-reduction implication. These dimensions require a baseline measurement before deployment and a post-deployment measurement at a defined interval, which most pilots skip.
Dimension 3: Capability extension. Some AI ROI isn't about doing existing things faster. It's about doing things that weren't previously possible at the scale now achievable. A sales team of 10 reps that could previously personalize outreach to 50 prospects per week can now personalize outreach to 200 prospects per week with the same headcount. GitHub's research on Copilot ROI provides one of the most rigorous studies of AI capability extension — developers completed tasks up to 55% faster, but the more durable finding was that engineers took on more complex tasks they previously avoided, a genuine expansion of team capability rather than just efficiency gain. That capability extension doesn't show up in time-saved calculations because it's not about saving time on existing tasks. It's about scale expansion.
Capability extension is particularly important for small and medium businesses. A 50-person company using Notion AI or ClickUp AI to maintain documentation and process consistency that previously required dedicated operations headcount has achieved genuine capability extension, not just efficiency. These tools get purchased without a measurement plan, but the ROI is often clearer in retrospect than it appeared in the pilot.
Dimension 4: Risk reduction. The least commonly measured dimension but increasingly important as AI is embedded in compliance-sensitive workflows. Deloitte's State of AI in the Enterprise report found that risk reduction is now the second most cited driver of enterprise AI investment among regulated industries — ahead of productivity and behind only cost reduction. Consistent CRM data reduces audit exposure. AI-assisted contract review reduces the risk of unfavorable terms being missed. Standardized customer communication reduces the variance in what reps say in sensitive situations. Risk reduction is hard to monetize in a positive ROI frame (you're measuring the cost of things that didn't happen), but it's real, and it matters in regulated industries.
The measurement design problem
The fundamental issue with most AI pilots isn't that the technology doesn't work. It's that the pilots aren't instrumented to measure ROI from day one.

A standard AI pilot looks like this: deploy the tool to a team, get subjective feedback on usefulness, collect self-reported time savings data at the end of the pilot period, combine that into a case study with some anecdotes, and use it to justify a broader purchase. This methodology can't produce an ROI claim that holds up to independent scrutiny.
A properly instrumented pilot looks different. Before deployment: establish baselines on the metrics you'll measure post-deployment. How long do deals currently take to move from stage 2 to stage 3? What's the current CRM data completeness rate? What's the average call-to-proposal turnaround time? What percentage of inbound leads convert past first contact? These baselines require work, but without them, you're measuring change from an unknown starting point.
During deployment: run a comparison group. Deploy the AI tool to a subset of the team while maintaining the control group on the current workflow. Match the groups by rep tenure, territory quality, and historical conversion rate. Measure both groups against the same metrics. This is the only way to isolate AI impact from other variables.
After deployment: measure reallocation, not just savings. If the tool saves three hours per week per rep, what does your CRM data show those hours were spent on? If you can't answer that question, the time savings claim is hypothetical.
This methodology requires more upfront planning than most pilots allow for. But the organizations that skip it end up defending ROI with anecdotes rather than data, which means every renewal cycle is a negotiation based on perceived value rather than measured value.
Before/after methodology: what most companies skip
Even companies that intend to measure AI ROI seriously make two consistent baseline mistakes.
They measure the wrong starting point. Baseline measurement should happen before the tool is announced, not after it's deployed. Once people know an AI tool is coming, behavior changes. Reps start cleaning up CRM records. Managers start enforcing logging standards. The baseline gets artificially inflated, which makes the post-deployment comparison unfavorable. Baseline data collection should be invisible or at least unconnected from the AI deployment announcement.
They skip the qualitative baseline. Numbers alone don't tell the full story. Before deployment, interview a sample of the team: where do they spend the most time? What's the most tedious part of their workflow? What information do they wish they had that they currently don't? This creates a qualitative baseline that lets you assess whether the AI actually addressed the pain points it was supposed to address, not just whether aggregate metrics moved.
For Notion AI and ClickUp AI in productivity contexts, the before/after methodology needs to include a team documentation audit: how many processes are currently documented? How current is the documentation? How often is it actually used? These questions establish the capability baseline that AI documentation assistance is supposed to improve. Companies that skip this baseline can't tell whether AI helped or whether the team just documented things because there was a new tool available.
The AI ROI Measurement Canvas
A pre-deployment planning tool for mapping AI investment against measurable outcomes across all four dimensions:
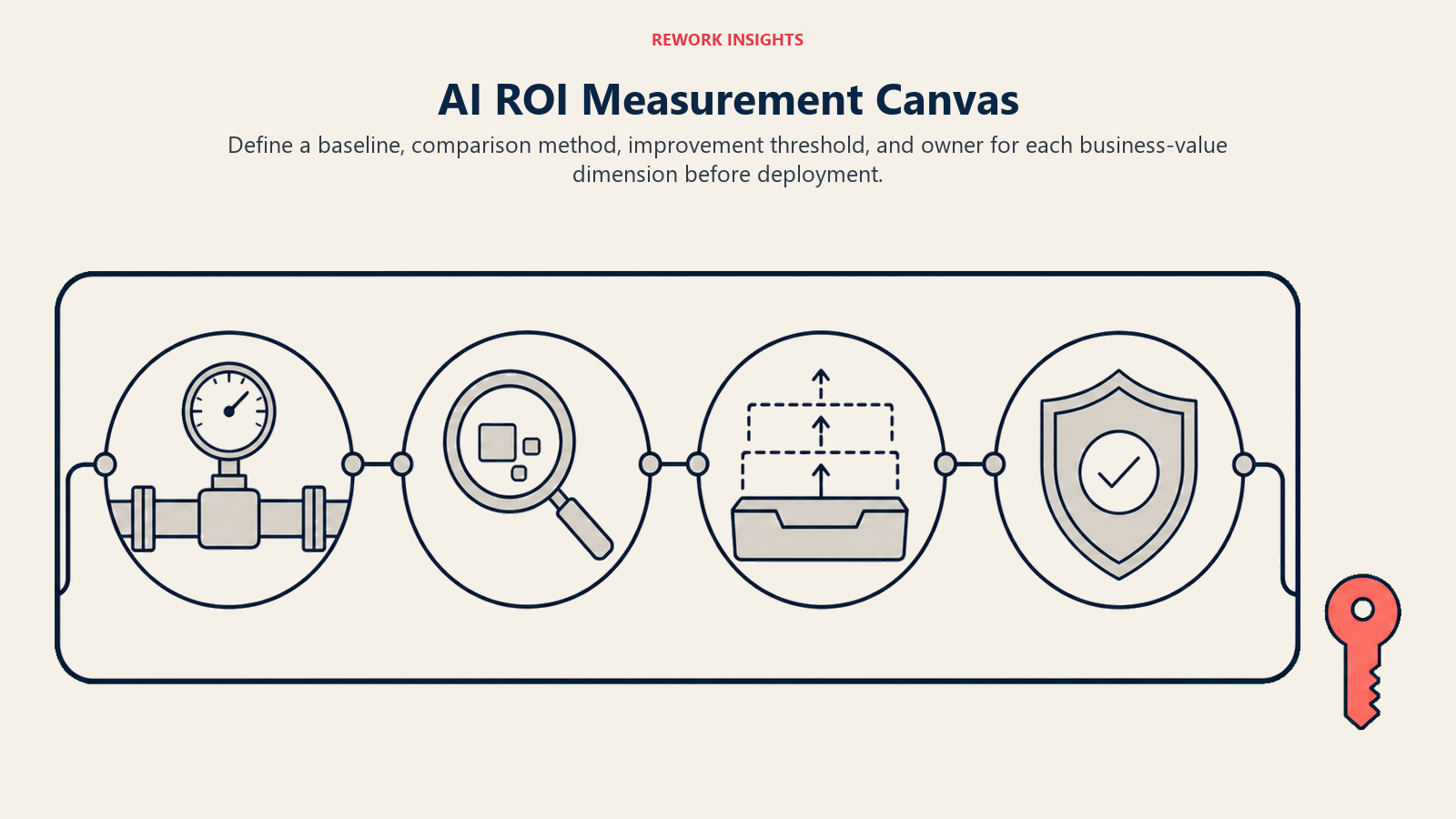
Revenue Impact quadrant. Define: which pipeline stage will show measurable change? What's the current conversion rate or velocity at that stage? What comparison group will you use? What improvement threshold would justify the investment?
Quality Improvement quadrant. Define: which output quality metrics are currently tracked? Which ones could be tracked that aren't? What's the current baseline? How much improvement is operationally significant?
Capability Extension quadrant. Define: what tasks are currently capacity-constrained? What scale expansion would be valuable if it were achievable? What's the current volume, and what would expanded volume mean for revenue or cost?
Risk Reduction quadrant. Define: what compliance or consistency risks exist in the current workflow? Which ones does this AI tool address? How would you measure risk reduction (incident rate, audit findings, legal review cycles)?
The canvas takes about 90 minutes to complete for a specific deployment. It's not an academic exercise. It's a deployment planning tool that forces the measurement infrastructure to be designed before the tool goes live. When the pilot ends, the data for the ROI case is already being collected rather than retroactively assembled.
Five metrics to track in the first 90 days
If you're deploying AI without a complete measurement framework and need a practical starting point, these five metrics proxy for real ROI across all four dimensions. For a broader set of AI productivity ROI metrics that apply beyond sales contexts — including for ops, marketing, and support teams — the library article covers additional benchmarks and measurement templates.
Pipeline stage velocity. Measure average time spent in each pipeline stage before and after deployment. Faster movement through stages indicates genuine workflow improvement, not just activity shuffling.
CRM data completeness rate. Measure the percentage of contact and activity records with complete required fields. Improvement indicates quality gains that compound into better forecasting and segmentation.
Rep time allocation shift. For two weeks before and two weeks after deployment, have reps log (or derive from CRM activity data) how they're spending their working time. Look for reallocation toward high-value activities, not just reduction in low-value ones.
Inbound lead response time. The time between a lead entering the system and receiving first human contact. AI-assisted routing and qualification should compress this. It's easy to measure and directly correlated with conversion rates.
AI output rejection rate. How often are AI-generated suggestions (emails, next steps, summaries) being ignored or significantly modified by the humans reviewing them? Low rejection rates indicate high relevance. High rejection rates indicate a model quality or data quality problem that will limit long-term value.
These five metrics aren't comprehensive. But they're measurable from day one, they span multiple ROI dimensions, and they give you something real to show in a 90-day review that doesn't rely on self-reported time savings.
What to do retroactively
If you've already deployed AI tools without a measurement plan, you're not out of options. You can reconstruct baselines from historical CRM data: look at pipeline velocity, data completeness, and activity patterns from 6–12 months before deployment. The retrospective baseline won't be as clean as a prospective one, but it gives you a comparison point.
Start collecting the forward-looking metrics now, even if the backward-looking baseline is imperfect. A 12-month trend showing improving pipeline velocity and CRM data quality is a credible ROI story even without a precise pre-deployment baseline, as long as you're transparent about the methodology.
The companies that struggle most in AI ROI conversations are those that bought tools on perceived value, deployed without measurement, and are now defending renewal costs without data. The fix isn't a better slide deck. It's building the measurement infrastructure (even retroactively) and using actual performance data to anchor the conversation.
That's what CFOs are asking for when they push back on "time saved." They want to know what the business got for the investment, measured in terms that connect to revenue, quality, capability, or risk. Time saved is a means. Those four dimensions are the ends.
Learn More
