Ticket Deflection dengan RAG dalam Dukungan SaaS
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Tingkat defleksi adalah metrik yang paling banyak dilacak tim dukungan SaaS saat mengevaluasi AI. Itu juga metrik yang salah untuk dioptimalkan sendiri.
Tingkat defleksi 60% terdengar mengesankan. Tapi jika 40% dari pelanggan yang didefleksi mendapatkan jawaban yang salah atau tidak lengkap, menyerah tanpa menyelesaikan masalah mereka, dan diam-diam mengurangi penggunaan produk atau membuka tiket tiga hari kemudian dengan nada yang lebih frustrasi, Anda tidak telah meningkatkan operasi dukungan Anda. Anda menyembunyikan masalah di balik sebuah metrik.
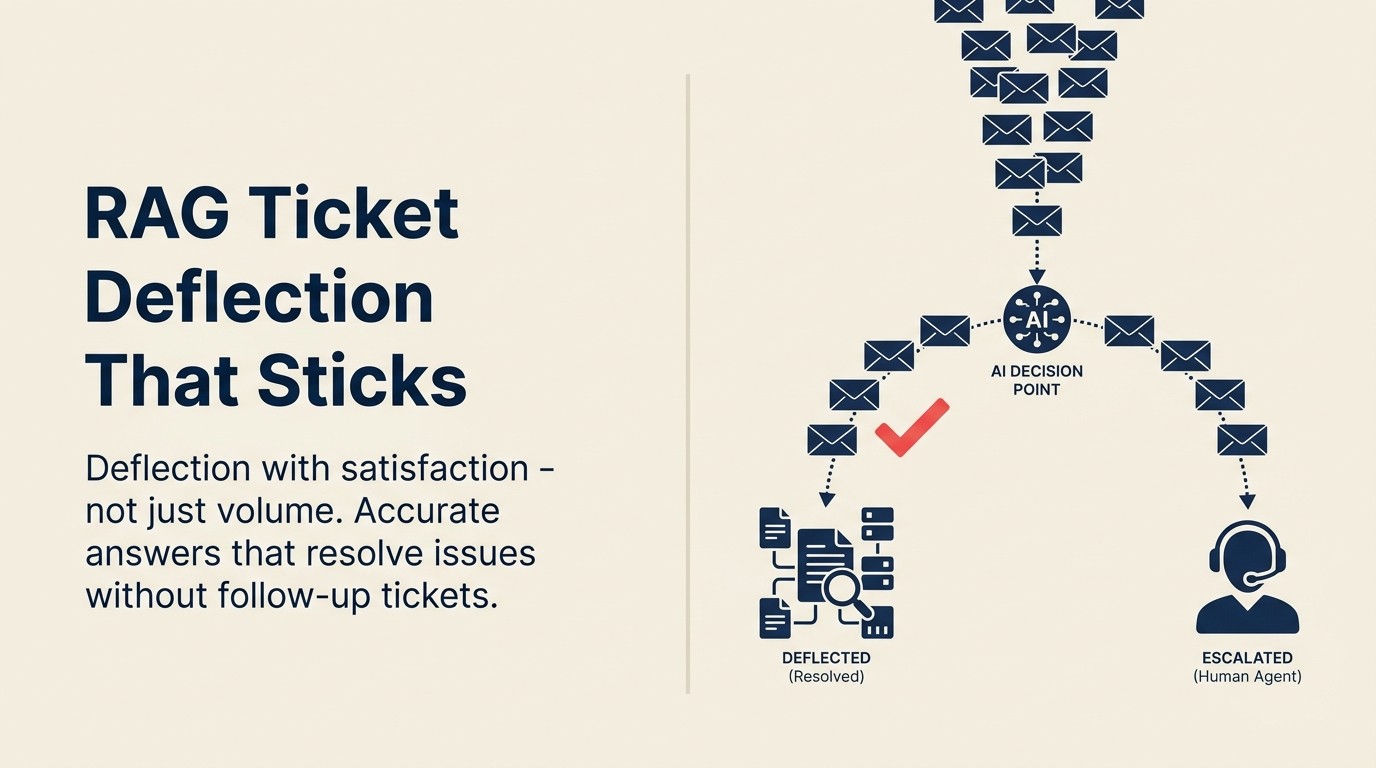
Tujuannya adalah defleksi dengan kepuasan: pelanggan yang mendapatkan jawaban akurat, menyelesaikan masalah mereka, dan tidak perlu membuka tiket tindak lanjut. Tujuan tersebut memerlukan pendekatan desain yang berbeda dari optimasi volume defleksi murni, dan dimulai dengan memahami bagaimana ticket deflection berbasis Retrieval-Augmented Generation (RAG) sebenarnya bekerja.
Cara Kerja Defleksi RAG
Ketika pelanggan mengirimkan pesan dukungan, sistem berbasis RAG melakukan hal berikut: mengambil pertanyaan, menjalankan pencarian semantik terhadap korpus knowledge base, mengambil potongan dokumentasi yang paling relevan, dan menghasilkan respons yang langsung berasal dari konten yang diambil tersebut. Respons mencakup tautan sumber sehingga pelanggan dapat membaca dokumentasi asli jika mereka ingin detail lebih lanjut.
Langkah retrieval inilah yang membedakan RAG dari chatbot generik. Chatbot generik menghasilkan respons dari data pelatihannya. Ia mungkin mengetahui secara kasar bagaimana sistem tiket SaaS bekerja, tetapi tidak mengetahui kode error API spesifik Anda, model izin spesifik Anda, atau perubahan workflow yang Anda rilis tiga minggu lalu. RAG mengambil dari konten aktual Anda, sehingga respons didasarkan pada kebenaran produk Anda, bukan perkiraan model terhadapnya. Pola RAG Assistant menjelaskan arsitektur teknis lengkap di balik pendekatan retrieval ini.
Inilah mengapa kualitas retrieval lebih penting dari kualitas generasi untuk dukungan SaaS. Respons yang sedikit kaku yang dihasilkan dari dokumentasi yang diambil secara akurat lebih baik dari respons yang rapi yang dihasilkan dari tebakan terbaik model. Pelanggan menginginkan jawaban yang benar, bukan yang paling lancar namun salah.
Key Facts: Kualitas Ticket Deflection RAG
- RAG dengan knowledge graph mencapai peningkatan akurasi retrieval 77,6% (diukur dengan mean reciprocal rank, skor kualitas pencarian standar) dan pengurangan waktu resolusi 28,6% di tim layanan pelanggan LinkedIn (penelitian LinkedIn/MIT, 2024)
- Hanya 14% masalah layanan pelanggan yang sepenuhnya diselesaikan dalam self-service saat ini, dengan 43% pelanggan melaporkan tidak dapat menemukan konten self-service yang relevan (Gartner, 2025)
- Perusahaan B2B SaaS yang menggunakan platform dukungan AI-first melihat defleksi tiket 60% lebih tinggi dibanding perangkat lunak help desk tradisional, dengan kesenjangan kinerja yang dijelaskan hampir seluruhnya oleh kualitas knowledge base, bukan kualitas model AI (Pylon, 2025)
The RAG Quality Gate
The RAG Quality Gate adalah evaluasi tiga ambang yang berjalan sebelum setiap respons AI disampaikan ke pelanggan. Ambang kualitas korpus: dokumen yang diambil harus telah diperbarui dalam jendela kesegaran yang ditentukan (rekomendasi: 90 hari untuk SaaS yang rilis cepat). Ambang kepercayaan retrieval: skor kemiripan semantik antara pertanyaan pelanggan dan konten yang diambil harus melampaui nilai minimum sebelum menghasilkan respons. Ambang presisi jawaban: jika retrieval mengembalikan beberapa dokumen yang berpotensi bertentangan, sistem menandai untuk tinjauan manusia daripada menghasilkan jawaban campuran yang mungkin berhalusinasi. Tiket yang gagal di ambang mana pun dirutekan ke penanganan manusia dengan sinyal kepercayaan rendah terlampir.
Apa yang Masuk dalam Korpus RAG
Korpus adalah semua yang dapat diambil AI. Untuk dukungan SaaS, korpus yang dirancang dengan baik mencakup lima tipe konten.
Dokumentasi bantuan. Pusat bantuan utama Anda: panduan cara kerja, penjelasan fitur, panduan pemecahan masalah, panduan penyiapan integrasi. Ini adalah fondasi. Perlu spesifik (tingkat artikel, bukan hanya tingkat kategori), terkini, dan terorganisir cukup konsisten sehingga pencarian semantik dapat membedakan antara pertanyaan tentang izin pengguna dan pertanyaan tentang izin API.
Dokumentasi API dan pengembang. Untuk perkakas SaaS yang menghadap pengembang, dokumen API, panduan webhook, referensi SDK, dan definisi kode error adalah konten korpus bernilai tinggi. Tiket pengembang cenderung tepat dan teknis, dan jawabannya biasanya ada dalam dokumentasi. Tantangannya adalah menjaga ini tetap terkini seiring API berkembang.
Catatan rilis produk. Ini adalah komponen korpus yang paling sering diabaikan. Setiap rilis fitur, perubahan API, dan perbaikan bug menciptakan pertanyaan dukungan baru. Pelanggan yang memperbarui minggu lalu bertanya tentang perilaku yang tidak mereka lihat sebelum pembaruan. Jika catatan rilis tidak ada dalam korpus, AI menjawab dengan informasi yang sudah usang.
Tiket yang sudah diselesaikan. Tiket yang diselesaikan, dikategorikan, dan dianonimkan adalah konten korpus bersinyal tinggi, terutama untuk kasus tepi yang tidak secara eksplisit tercakup dalam dokumen bantuan. Ketika pelanggan mendeskripsikan perilaku error yang tidak biasa, tiket yang diselesaikan dari pelanggan sebelumnya dengan masalah yang sama dapat menghasilkan respons yang lebih akurat daripada artikel dokumentasi yang hanya mencakup kasus umum. Kesiapan data berdasarkan pola membahas seperti apa data yang bersih dan siap-korpus untuk penerapan RAG.
FAQ dan panduan dalam produk. Jawaban singkat untuk pertanyaan paling umum, tips onboarding, dan panduan kontekstual yang ditautkan dari dalam produk itu sendiri. Ini sering kali adalah konten yang paling mirip secara semantik dengan pertanyaan yang sebenarnya diajukan pelanggan, yang menjadikannya kandidat retrieval tinggi.
Deteksi Kesenjangan Pengetahuan
Output paling berharga dari sistem dukungan RAG bukan defleksi yang berhasil. Itu adalah sinyal kesenjangan pengetahuan dari retrieval yang gagal. Analisis Forrester tentang manajemen pengetahuan dalam layanan pelanggan menemukan bahwa organisasi dengan knowledge base yang matang dan terstruktur dengan baik mencapai tingkat resolusi dan penghematan biaya yang jauh lebih tinggi daripada yang memperlakukan dokumentasi sebagai infrastruktur sekunder.
Ketika AI mencoba mengambil konten yang relevan untuk sebuah pertanyaan dan dokumen yang paling cocok memiliki skor kemiripan yang rendah, itu adalah sinyal bahwa korpus tidak memiliki cakupan yang baik untuk tipe pertanyaan tersebut. Beberapa sistem akan merespons dengan jawaban yang percaya diri bagaimanapun (menggunakan pengetahuan umum model untuk mengisi celah). Sistem yang lebih baik akan mengeskalasi tiket dengan tanda yang menunjukkan retrieval kepercayaan rendah.
Lacak eskalasi kepercayaan rendah tersebut sebagai backlog dokumentasi. Masing-masing mewakili pertanyaan yang diajukan pelanggan Anda yang tidak dijawab dengan baik oleh dokumen Anda. Menyelesaikan tiket manusia yang mendasarinya lalu menulis artikel bantuan dari resolusi tersebut adalah cara tercepat untuk memperluas cakupan defleksi yang efektif.
Intercom Fin melacak ini melalui fitur "Sources" mereka, yang menunjukkan dokumen mana yang dikutip dalam respons AI dan tipe pertanyaan mana yang menghasilkan eskalasi tanpa kecocokan sumber yang baik. Zendesk AI menampilkan sinyal kesenjangan serupa melalui analitik percakapannya. Laporan kesenjangan ini, dijalankan bulanan, menjadi input ke sprint dokumentasi Anda. Pertanyaannya adalah: bagaimana Anda tahu kapan kualitas defleksi benar-benar bekerja?
Pengukuran Kualitas Defleksi
Volume defleksi sebagai metrik tunggal bersifat menyesatkan. Anda perlu empat pengukuran bersama.
Tingkat resolusi. Berapa persentase tiket yang didefleksi AI ditutup tanpa interaksi tindak lanjut dari pelanggan? Tiket yang didefleksi dan dibuka kembali dalam 48 jam bukan tiket yang diselesaikan. Lacak tingkat pembukaan kembali sebagai sinyal kualitas.
CSAT pada tiket yang didefleksi. Ketika pelanggan menilai pengalaman dukungan mereka setelah defleksi AI, apa yang mereka katakan? Sebagian besar platform memungkinkan Anda meminta penilaian jempol atas/bawah atau bintang 1-5 saat tiket ditutup. CSAT pada tiket yang didefleksi AI versus tiket yang ditangani manusia memberi tahu Anda apakah pelanggan menemukan resolusi AI memuaskan atau hanya dapat diterima secara minimal.
Tingkat false-deflection. Tiket yang ditandai diselesaikan oleh AI tetapi di mana pelanggan membuka tiket baru dalam 7 hari yang mendeskripsikan masalah yang sama. Ini adalah ukuran defleksi buruk yang paling jelas: AI mengatakan menyelesaikan masalah, tetapi tidak. Risiko halusinasi berdasarkan pola menjelaskan kondisi di mana bahkan sistem yang didasarkan RAG menghasilkan jawaban yang salah dengan percaya diri.
Tingkat eskalasi setelah percobaan AI. Dari tiket di mana AI mencoba respons sebelum manusia mengambilnya, berapa banyak yang memerlukan manusia untuk mengoreksi atau sepenuhnya mengganti respons AI? Ini mengukur apakah AI membantu agen manusia atau menciptakan lebih banyak pekerjaan untuk mereka.
Operasi dukungan dengan defleksi 40%, CSAT 4,2/5 pada tiket yang didefleksi, tingkat false-deflection 8%, dan tingkat eskalasi 15% setelah percobaan AI berkinerja baik. Operasi dukungan dengan defleksi 55%, CSAT 3,1/5, tingkat false-deflection 22%, dan 35% eskalasi yang memerlukan koreksi tidak. Defleksi lebih tinggi dengan metrik kualitas yang lebih buruk mewakili pengalaman pelanggan yang negatif secara bersih.
"Perusahaan yang mencapai defleksi 40-50% yang berkelanjutan dengan CSAT tinggi tidak menggunakan AI yang lebih baik. Mereka memperlakukan dokumentasi sebagai aset produk dengan ketelitian yang sama yang mereka terapkan pada produk itu sendiri. Lag kesegaran knowledge base adalah metrik yang tepat untuk dilacak: usia rata-rata artikel relatif terhadap perubahan produk terakhir yang mereka cakup." (Rework Analysis, 2025)
Benchmark Kualitas Defleksi
| Metrik | Ambang Baik | Tanda Peringatan | Tindakan Diperlukan |
|---|---|---|---|
| Tingkat resolusi (tidak ada tindak lanjut dalam 48j) | Di atas 85% | 70-85% | Tinjau topik pembukaan ulang umum |
| CSAT pada tiket yang didefleksi | 4,0/5 atau lebih | 3,5-4,0/5 | Audit respons AI terbaru untuk akurasi |
| Tingkat false-deflection (masalah sama, tiket baru dalam 7 hari) | Di bawah 8% | 8-15% | Identifikasi tipe dokumen yang gagal |
| Tingkat koreksi AI saat eskalasi | Di bawah 15% | 15-25% | Selidiki kualitas respons AI per kategori |
Sumber: Zendesk CX Trends 2026, Intercom Fin Performance Data 2025, Gartner Customer Service AI Benchmark 2025
Masalah Kecepatan Rilis SaaS
SaaS rilis dengan cepat. Dokumentasi tertinggal. Ini adalah penyebab paling umum degradasi kualitas dukungan AI dari waktu ke waktu.
Ketika Anda merilis fitur baru, AI masih mengetahui perilaku lama. Pelanggan yang menggunakan fitur baru mengajukan pertanyaan tentang perilaku yang tidak ada ketika dokumen ditulis. AI mengambil dari dokumen lama tersebut dan menghasilkan jawaban yang benar tiga bulan lalu dan salah hari ini.
Solusinya adalah menghubungkan proses pembaruan dokumentasi ke proses rilis. Setiap rilis harus memiliki tugas dokumentasi yang sesuai: artikel bantuan mana yang perlu diperbarui, artikel baru mana yang perlu dibuat, dokumen API mana yang perlu ditambahkan catatan versi. Rilis tidak dikirimkan tanpa tugas dokumentasi yang sudah dimasukkan ke dalam antrean.
Untuk pertanyaan yang didorong catatan rilis (pelanggan bertanya "apakah ini berubah di rilis terbaru?"), catatan rilis itu sendiri menjadi sumber korpus utama. Pastikan catatan rilis diterbitkan dalam format yang dapat diambil oleh sistem RAG, bukan hanya dikirim melalui email ke pelanggan dan kemudian dilupakan.
Beberapa tim menjalankan audit korpus bulanan: tarik 30 defleksi AI yang berhasil terbaru dan tinjau dokumen sumber. Apakah masih akurat? Apakah ada fitur yang mereka deskripsikan yang telah berubah? Latihan bulanan 2 jam ini mencegah pergeseran lambat menuju jawaban yang salah dengan percaya diri.
Dukungan Multi-Bahasa
Perusahaan B2B SaaS dengan basis pelanggan global menghadapi tantangan defleksi multibahasa. Dokumen Anda mungkin terutama dalam bahasa Inggris. Pelanggan Anda mungkin mengajukan pertanyaan dalam bahasa Jerman, Spanyol, atau Jepang.
Intercom Fin dan Zendesk AI keduanya menangani retrieval multibahasa, baik melalui pencarian semantik multibahasa (menemukan dokumen Inggris yang relevan sebagai respons terhadap pertanyaan yang diajukan dalam bahasa lain) atau melalui retrieval langsung dari dokumentasi terjemahan ketika ada.
Perbedaan kualitasnya signifikan. Pelanggan yang mengajukan pertanyaan dalam bahasa Spanyol dan mendapatkan jawaban yang dihasilkan dari dokumen Inggris yang diterjemahkan secara real time oleh mesin akan memiliki pengalaman yang berbeda dari pelanggan yang pertanyaannya dijawab dari artikel bantuan yang diterjemahkan dengan terminologi yang benar untuk bahasa dan wilayah mereka.
Untuk bahasa pelanggan bervolume tinggi, terjemahkan 50 artikel bantuan teratas terlebih dahulu. Itu mencakup sebagian besar tipe pertanyaan yang dapat didefleksi dengan konten sumber berbahasa asli, dan peningkatan kualitas dalam tiket yang didefleksi bersifat langsung.
Korpus Spesifik Segmen
Pelanggan enterprise dan pelanggan SMB mengajukan pertanyaan yang berbeda. Pelanggan enterprise yang bertanya tentang provisi pengguna melalui SCIM mengajukan pertanyaan yang berbeda dari pelanggan SMB yang bertanya cara menambahkan anggota tim baru.
Ketika basis pelanggan Anda memiliki segmen yang berbeda dengan kebutuhan dukungan yang sangat berbeda, pertimbangkan retrieval yang sadar segmen. Zendesk AI mendukung ini melalui penandaan pelanggan yang mempengaruhi korpus mana yang dicari terlebih dahulu. Intercom Fin menggunakan logika routing percakapan yang dapat membiaskan retrieval ke arah dokumentasi spesifik segmen.
Implementasi praktis: tandai artikel bantuan Anda berdasarkan tier pelanggan (SMB, Mid-Market, Enterprise) dan rutekan tiket masuk dengan tag pelanggan enterprise menuju dokumentasi tier enterprise terlebih dahulu. Artikel bantuan umum tentang manajemen pengguna cocok untuk pertanyaan SMB. Pelanggan enterprise yang bertanya tentang provisi SCIM harus mengambil dari dokumentasi integrasi enterprise Anda, bukan panduan umum "cara menambahkan pengguna" Anda.
Loop Peningkatan Berkelanjutan
Ticket deflection dengan RAG bukan sistem yang dapat diterapkan dan dilupakan. Ia meningkat secara berkelanjutan dengan investasi yang disengaja.
Loop peningkatan berjalan pada siklus bulanan. Tarik sinyal kesenjangan pengetahuan dari bulan lalu: tipe tiket mana yang menghasilkan retrieval kepercayaan rendah, pertanyaan mana yang memiliki tingkat false-deflection tinggi, area produk mana yang melihat eskalasi terbanyak setelah percobaan AI. Ubah itu menjadi tugas dokumentasi. Tulis artikelnya, perbarui yang sudah usang, tambahkan catatan rilis yang tidak ada dalam korpus.
Lacak kualitas defleksi dari bulan ke bulan. Jika CSAT pada tiket yang didefleksi naik, loop peningkatan berhasil. Jika stagnan atau menurun, dokumentasi tertinggal dari perubahan produk Anda.
Perusahaan yang mencapai defleksi 40-50% yang berkelanjutan dengan CSAT tinggi tidak menggunakan AI yang lebih baik. Mereka memperlakukan dokumentasi sebagai aset produk dengan ketelitian yang sama yang mereka terapkan pada produk mereka sendiri. Gartner memperkirakan AI agentik akan secara otonom menyelesaikan 80% masalah layanan pelanggan umum tanpa intervensi manusia pada 2029, dan organisasi yang paling siap untuk mencapai batas atas tersebut adalah yang membangun disiplin dokumentasi sekarang. Sprint dokumentasi ada dalam roadmap. Audit korpus ada dalam kalender ops dukungan. Laporan kesenjangan pengetahuan pergi ke tim dokumentasi, bukan hanya tim dukungan. Keunggulan telemetri produk dalam AI SaaS menjelaskan bagaimana data penggunaan dalam produk dapat mengisi korpus dukungan Anda dan menampilkan pertanyaan sebelum pelanggan bahkan menanyakannya.
AI Support Agent untuk Self-Service SaaS mencakup struktur tier lengkap: bagaimana defleksi RAG terhubung ke bantuan agen manusia dan eskalasi spesialis sebagai sistem dukungan yang lengkap.
AI Knowledge Base Maintenance untuk SaaS Docs membahas lebih dalam siklus hidup dokumentasi: cara mengaudit cakupan, menjaga dokumen tetap terkini dengan rilis, dan menggunakan AI itu sendiri untuk memelihara korpus.
Multi-Tier AI Routing dalam SaaS Help Desk mencakup apa yang terjadi setelah RAG mencoba defleksi: bagaimana tiket yang memerlukan penanganan manusia dirutekan ke agen yang tepat tanpa triase manual.
Tim dukungan yang menang dengan RAG adalah yang melacak kualitas defleksi bersamaan dengan volume defleksi. Pelanggan yang puas karena melayani diri sendiri adalah tujuannya. Pelanggan yang menyerah dan pergi dengan diam bukan. Rancang untuk yang pertama dari awal.
Rework Analysis: Tingkat false-deflection adalah metrik yang paling kurang dilacak dalam AI dukungan SaaS. Tim mengoptimalkan untuk volume defleksi mentah, merayakan tingkat defleksi 50%, dan melewatkan bahwa 18% dari pelanggan yang "didefleksi" tersebut membuka tiket baru dalam 7 hari dengan masalah yang sama dan frustrasi tambahan. Tingkat defleksi nyata bukanlah yang dilaporkan sistem. Itu adalah apa yang terjadi 7 hari kemudian. Tim yang melacak tingkat pembukaan kembali 7 hari bersamaan dengan volume defleksi menemukan tingkat defleksi efektif mereka biasanya 10-15 poin persentase lebih rendah dari angka headline, dan itulah angka yang harus dioptimalkan.
Pertanyaan yang Sering Diajukan
Apa perbedaan antara tingkat defleksi dan tingkat resolusi dalam dukungan RAG?
Tingkat defleksi mengukur berapa banyak tiket yang ditangani AI tanpa dieskalasi ke manusia. Tingkat resolusi mengukur berapa banyak dari tiket yang ditangani AI yang benar-benar diselesaikan, artinya pelanggan mendapatkan jawaban yang akurat dan tidak membuka kembali masalah tersebut. Tingkat defleksi 60% di mana 20% pelanggan membuka kembali tiket yang sama dalam 7 hari mewakili tingkat resolusi nyata mendekati 48%. Mengoptimalkan untuk tingkat resolusi daripada tingkat defleksi menghasilkan pengalaman pelanggan yang lebih baik dan CSAT yang lebih tinggi.
Apa yang seharusnya masuk dalam korpus RAG untuk dukungan SaaS?
Lima tipe konten: dokumentasi bantuan, dokumen API dan pengembang, catatan rilis produk, tiket yang diselesaikan dan dianonimkan, dan panduan FAQ atau dalam produk. Catatan rilis adalah yang paling sering diabaikan. Setiap rilis fitur menciptakan pertanyaan baru, dan jika catatan rilis tidak ada dalam korpus, AI menjawab dengan informasi yang sudah usang. Target kesiapan dokumentasi yang praktis: 50 tipe tiket teratas harus memiliki artikel bantuan yang khusus dan spesifik yang diperbarui dalam 90 hari terakhir.
Bagaimana cara mendeteksi ketika kualitas defleksi RAG menurun?
Tiga sinyal mengindikasikan degradasi. Pertama, CSAT pada tiket yang didefleksi turun di bawah 3,8/5 selama periode bergulir 30 hari. Kedua, tingkat false-deflection (masalah sama, tiket baru dalam 7 hari) naik di atas 10%. Ketiga, tingkat koreksi AI saat eskalasi (agen manusia harus mengoreksi atau mengganti respons AI) naik di atas 20%. Sinyal mana pun dari ini memicu audit dokumentasi untuk kategori tiket yang terpengaruh.
Bagaimana kecepatan pengiriman SaaS memengaruhi akurasi RAG dari waktu ke waktu?
SaaS rilis terus-menerus. Ketika sebuah fitur berubah, dokumentasi yang mendeskripsikan perilaku lamanya tetap ada dalam korpus dan dikembalikan sebagai hasil retrieval untuk pertanyaan baru. AI menghasilkan jawaban yang percaya diri berdasarkan materi sumber yang sudah usang. Perbaikannya adalah menghubungkan pembaruan dokumentasi ke proses rilis. Setiap rilis harus menghasilkan tugas dokumentasi: artikel mana yang perlu diperbarui, artikel baru mana yang perlu dibuat. Rilis tidak dikirimkan tanpa tugas dokumentasi yang sudah dimasukkan ke dalam antrean.
Apa itu deteksi kesenjangan pengetahuan dalam dukungan RAG?
Deteksi kesenjangan pengetahuan adalah penggunaan sinyal retrieval kepercayaan rendah untuk mengidentifikasi dokumentasi yang tidak ada. Ketika AI mencoba retrieval dan dokumen yang paling cocok memiliki skor kemiripan yang rendah, tipe tiket dicatat sebagai kesenjangan. Log kesenjangan ini, ditinjau bulanan, menjadi backlog dokumentasi. Setiap kesenjangan mewakili pertanyaan pelanggan yang tidak dijawab dengan baik oleh dokumen Anda. Menyelesaikan tiket manusia dan menulis artikel bantuan darinya adalah cara tercepat untuk memperluas cakupan defleksi.
Pelajari Lebih Lanjut:
- Pola RAG Assistant: arsitektur teknis lengkap untuk AI dukungan yang ditingkatkan dengan retrieval
- Risiko Halusinasi berdasarkan Pola: di mana AI yang didasarkan RAG masih gagal dan cara mengkalibrasi ambang eskalasi
- Kesiapan Data berdasarkan Pola: seperti apa data yang bersih dan siap-korpus untuk penerapan RAG
- AI Support Agent untuk Self-Service SaaS: struktur tier lengkap untuk AI dukungan SaaS
- Multi-Tier AI Routing dalam SaaS Help Desk: routing cerdas setelah percobaan defleksi
- AI Knowledge Base Maintenance untuk SaaS Docs: menjaga korpus tetap terkini dengan produk Anda

Co-Founder, Rework.com