Arms Race AI dalam SaaS: Kecepatan Pengiriman, dan Kapan Kecepatan Salah

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ketika Intercom meluncurkan Fin pada Maret 2023, setiap pemimpin support di perusahaan SaaS kompetitor mengalami pengalaman yang sama: pertanyaan dari dewan direksi tiba dalam dua minggu. "Apa yang kita lakukan tentang AI?" Bukan "haruskah kita memikirkan AI?" tapi "apa yang kita lakukan?" Framing tersebut mengasumsikan jawabannya sudah ya. Pertanyaannya hanya tentang eksekusi.
Ketika GitHub meluncurkan Copilot ke general availability pada Juni 2022, IDE (integrated development environment) yang telah menjadi produk stabil selama bertahun-tahun tiba-tiba menghadapi pertanyaan kategori yang belum mereka rencanakan. JetBrains, ekstensi VS Code, Sublime Text, semuanya harus memutuskan cara merespons fitur produk yang kini secara aktif dibandingkan pengguna mereka.
Inilah tampilan arms race AI dari dalam. Bukan pergeseran kompetitif yang lambat. Sebuah peristiwa punctuated yang memaksa keputusan respons segera.
Arms race itu nyata. Tetapi "kirimkan fitur AI dengan cepat" bukan strategi. Itu adalah arah. Perusahaan yang menavigasi ini dengan baik tidak hanya mengirim cepat. Mereka mengirimkan fitur spesifik, ke dalam workflow spesifik, dengan telemetri spesifik yang diterapkan untuk mempelajari apa yang berhasil. Yang belum menavigasinya dengan baik mengirimkan wrapper GPT-4 tanpa diferensiasi dan menyaksikan pelanggan pergi ke produk yang melakukan pekerjaannya.
The Weekly AI Ship Cadence
The Weekly AI Ship Cadence adalah kerangka operasional yang mendefinisikan infrastruktur, proses, dan kondisi budaya yang diperlukan untuk mengirimkan peningkatan fitur AI pada siklus mingguan daripada kuartalan. Infrastruktur: abstraction layer LLM API, kontrol versi prompt, dan pipeline telemetri. Proses: tinjauan metrik AI mingguan di mana data acceptance rate dan modification rate dibaca dan ditindaklanjuti; perubahan prompt dikirim minggu yang sama ketika diidentifikasi. Budaya: pemahaman bersama di seluruh produk dan engineering bahwa peningkatan AI adalah tugas operasional berkelanjutan, bukan proyek engineering berkala. Tim yang menjalankan The Weekly AI Ship Cadence menghasilkan fitur AI yang meningkat seiring pengguna terlibat. Tim tanpa itu menghasilkan fitur statis yang stagnan pada kualitas peluncuran.
Mengapa arms race itu nyata
Arms race bukan hype. Ini adalah perilaku pembeli yang berubah pada 2024-2025 dan belum berubah kembali.
Ulasan G2 sekarang menyertakan rating fitur AI sebagai kategori. Pembeli yang meneliti alat SaaS menyaring berdasarkan "apakah alat ini memiliki AI?" sebelum sampai ke perbandingan harga. Komite pengadaan enterprise di 2026 menyertakan kapabilitas AI sebagai kriteria evaluasi eksplisit dalam RFP (requests for proposal) yang tidak akan menyebutkannya di 2022.
Lebih konkret: survei NPS (Net Promoter Score) SaaS berubah. Survei NPS tim support pada 2023-2024 mulai menyertakan pertanyaan tentang bantuan AI. Survei NPS alat CS mulai menanyakan tentang AI health scoring. Sinyal dari pelanggan ke vendor SaaS jelas: kami mengevaluasi AI Anda dan kami akan terus mengevaluasinya.
Menurut analisis Level 4.1 ACE Framework, kecepatan iterasi fitur AI telah menjadi sinyal tingkat kategori untuk kualitas produk. Pembeli tidak hanya mengevaluasi apakah Anda memiliki AI. Mereka melihat kadensnya: seberapa sering Anda merilis peningkatan AI? Changelog dengan penurunan fitur AI bulanan menandakan tim dengan infrastruktur AI nyata. Halaman AI di website Anda dengan fitur yang tidak berubah dalam 6 bulan menandakan kotak centang. Analisis McKinsey tentang model bisnis SaaS era AI mencatat bahwa keunggulan kompetitif dalam perangkat lunak beralih dari fitur ke akses data kepemilikan dan kecepatan iterasi, yang membuat kadens pengiriman AI menjadi proxy untuk posisi strategis, bukan hanya metrik produk. Mengapa SaaS adalah adopter AI berkecepatan tertinggi menjelaskan alasan struktural mengapa ekspektasi ini terbentuk lebih cepat di SaaS daripada industri lain mana pun.
Key Facts: Dinamika Kompetitif AI SaaS
- Kesepakatan SaaS yang mereferensikan AI mencakup 72% dari semua transaksi SaaS di 2025, peningkatan 12x sejak 2018; pembeli mengevaluasi kapabilitas AI sebelum perbandingan harga (Software Equity Group, 2025)
- 64% CEO SaaS percaya AI generatif menurunkan hambatan masuk; fitur AI dasar yang dibangun pada LLM (large language model) API dapat direplikasi kompetitor dalam 4-8 minggu (G2/Vendasta, 2025)
- Kecepatan perlu tetapi tidak cukup: narasi AI yang dipimpin fitur tidak lagi menciptakan keuntungan kecuali mengubah cara kerja dilakukan; fitur AI yang dikirim tanpa telemetry loop stagnan pada kualitas peluncuran sementara kompetitor dengan loop terus meningkat setiap minggu (Wing VC/McKinsey, 2025)
Seperti apa first-mover advantage sebenarnya
GitHub Copilot memiliki sekitar 18 bulan kepemimpinan pasar sebelum JetBrains AI Assistant, Cursor, dan alat coding AI lainnya mencapai adopsi yang berarti. Selama 18 bulan tersebut, GitHub membangun telemetry loop, menyempurnakan kualitas saran mereka dari data penerimaan pengguna, dan menetapkan "Copilot" sebagai model mental default untuk bantuan coding AI. 18 bulan itu penting.
Intercom Fin memiliki jendela keunggulan serupa untuk defleksi support berbasis AI. Ketika kompetitor meluncurkan alat support AI mereka sendiri di 2024, Intercom sudah menyelesaikan kompleksitas integrasi, menyetel perilaku fallback, dan membangun kepercayaan pelanggan. Playbook-nya terlihat. Kesenjangan itu nyata.
Tetapi first-mover advantage dalam fitur AI SaaS tidak bertahan selamanya. Ini bertahan sampai kompetitor mengirimkan alternatif yang layak, yang merupakan jendela yang lebih pendek daripada untuk fitur non-AI, karena membungkus LLM API benar-benar cepat. Anda dapat mengirimkan fitur AI MVP dalam 6-8 minggu. Kompetitor Anda juga bisa.
Yang membuat first-mover advantage tahan lama bukan hanya menjadi yang pertama. Ini membangun telemetry loop selama jendela keunggulan sehingga fitur Anda meningkat lebih cepat dari yang bisa dikejar kompetitor. Keunggulan Copilot GitHub di 2026 bukan karena mereka diluncurkan lebih dulu di 2022. Ini karena empat tahun data penerimaan membentuk model yang tidak bisa direplikasi perusahaan yang diluncurkan hari ini dari hari pertama.
Kecepatan paling penting ketika Anda menciptakan kategori fitur AI baru di pasar Anda, bukan ketika Anda mengejar fitur yang sudah dimiliki kompetitor.
Apa yang dihukum arms race
Mengirimkan fitur AI yang tidak bekerja lebih buruk daripada mengirimkan terlambat. Ini adalah kebenaran kontra-intuitif yang hilang dalam tekanan kompetitif.
Fitur non-AI yang dikirim dengan bug diperbaiki. Pengguna terbiasa dengan iterasi perangkat lunak. Filter daftar yang rusak diperbaiki dalam sprint berikutnya. Model mental pengguna adalah "fitur itu bermasalah, sekarang sudah diperbaiki."
Fitur AI yang dikirim dengan masalah kualitas mendapatkan respons yang berbeda. "AI salah tentang status akun saya" tidak hanya berarti fitur tidak bekerja. Ini berarti AI tidak bisa dipercaya. Dan begitu fitur AI kehilangan kepercayaan pengguna, membangun kembali kepercayaan itu jauh lebih sulit daripada memperbaiki bug.
Bot chat support yang mengarahkan pelanggan ke dokumentasi yang salah tidak hanya menciptakan interaksi support yang buruk. Ini menciptakan pengguna yang secara aktif menonaktifkan AI chatbot dan memberi tahu rekan-rekannya untuk menghindarinya. Itu adalah collapse kepercayaan yang mengikuti fitur selama bertahun-tahun.
AI health scoring yang menyebut akun yang akan churn sebagai "hijau" tidak hanya menghasilkan skor yang salah. Ini melatih CSM (Customer Success Manager) Anda untuk mengabaikan AI. Begitu CSM berhenti mempercayai health score, mereka berhenti menggunakannya, dan Anda telah menghabiskan $80.000/tahun untuk langganan Gainsight yang tim Anda telah secara mental depreciate.
Kepercayaan fitur AI adalah aset. Kecepatan tanpa kualitas membakarnya. Mode kegagalan AI SaaS mendokumentasikan dengan tepat bagaimana erosi kepercayaan terjadi di berbagai jenis fitur AI dan berapa lama pemulihan memakan waktu.
Kuburan wrapper
Antara awal 2023 dan pertengahan 2024, ratusan produk SaaS mengirimkan "fitur AI" yang merupakan wrapper API GPT-4 dengan diferensiasi minimal: antarmuka chat, tombol ringkasan, kolom penyusunan email. Beberapa fitur ini benar-benar berguna. Sebagian besar tidak.
Pelanggan yang mencoba fitur-fitur ini di 2023 dan menemukan kualitasnya rendah sebagian besar telah pergi. Mereka mencoba AI, tidak cukup baik untuk membenarkan perubahan workflow, dan kembali mengerjakan tugas secara manual. Membuat pelanggan tersebut mencoba fitur AI lagi membutuhkan pengalaman yang secara materi lebih baik atau intervensi langsung dari tim produk.
Inilah kuburan wrapper: fitur AI yang dikirimkan untuk mencentang kotak, diadopsi sebentar, gagal menunjukkan nilai di atas baseline manual, dan sekarang memiliki tingkat weekly active user 3-5% sementara fitur tersebut duduk di changelog produk sebagai kapabilitas AI.
Masalahnya bukan bahwa GPT-4 wrapping adalah pilihan teknis yang buruk. Ini mengirimkan wrapper tanpa diferensiasi dan tanpa telemetry loop untuk meningkatkannya tidak menghasilkan fitur yang terus berkembang. Ini menghasilkan fitur yang stagnan pada kualitas peluncuran sementara kompetitor mengirimkan fitur AI yang lebih ketat dan spesifik yang disetel untuk workflow yang tepat.
Notion AI bertahan dari era wrapper bukan karena fitur AI penulisan awal mereka secara dramatis lebih baik dari sesi ChatGPT. Mereka bertahan karena mereka menyematkan AI langsung ke dalam alur pengeditan (tanpa gesekan untuk digunakan), membangun telemetri tentang bagaimana pengguna menerima atau memodifikasi saran, dan mengiterasi setiap minggu. Diferensiasinya ada pada integrasi workflow dan kecepatan peningkatan, bukan model yang mendasarinya. Pertanyaan selanjutnya adalah infrastruktur apa yang membuat kecepatan itu mungkin.
Apa yang sebenarnya dibutuhkan oleh kecepatan pengiriman

"Kirim AI lebih cepat" sering dikatakan seolah-olah itu adalah keputusan budaya. Itu bukan. Kecepatan adalah hasil infrastruktur.
Infrastruktur yang diperlukan untuk mengirimkan fitur AI pada kadens mingguan:
Lapisan integrasi LLM API: Layanan backend yang menangani panggilan API, mengelola batas rate, mencatat permintaan dan respons, dan dapat menukar model yang mendasarinya tanpa perubahan frontend. Tim tanpa lapisan arsitektur ini menghabiskan waktu engineering pada setiap fitur AI untuk menemukan kembali integrasi API. Tim dengan itu menambahkan fitur AI baru dengan menulis spesifikasi prompt, bukan kode infrastruktur.
Kontrol versi prompt: Perubahan prompt adalah perubahan kode. Mereka membutuhkan kontrol versi, environment pengujian, dan kemampuan rollback. Tim yang menyimpan prompt dalam environment variable dan men-deploy-nya dengan perubahan kode produksi tidak dapat mengiterasi setiap minggu. Tim dengan lapisan manajemen prompt (LangSmith, Helicone, atau sistem kustom) bisa.
Pipeline telemetri: Seperti yang dibahas dalam Telemetry Loop untuk In-Product AI, loop yang menangkap event saran, tindakan pengguna, dan feedback outcome. Tanpa ini, mengirimkan lebih cepat hanya menghasilkan lebih banyak fitur statis. Dengan itu, setiap fitur yang dikirimkan mulai menghasilkan sinyal peningkatan dari hari pertama.
Kemampuan AI product manager: PM yang dapat menulis spesifikasi fitur AI yang akurat secara teknis. "Tambahkan AI untuk membantu pengguna menulis email lebih baik" bukan spesifikasi fitur. "Tambahkan saran penulisan ulang yang memicu ketika pengguna berhenti selama 3 detik di kolom badan email, meneruskan konteks email penuh dan data CRM penerima ke Claude 3.5 Sonnet dengan prompt penyempurnaan nada, dan mencatat event accept/edit/dismiss dengan Segment" adalah spesifikasi fitur. Perbedaan waktu dari spek hingga dikirim adalah berminggu-minggu.
Tim yang memiliki infrastruktur ini mengirimkan fitur AI dalam 4-6 minggu. Tim tanpanya membutuhkan 12-16 minggu dan menghasilkan hasil yang lebih rendah kualitasnya.
"Mengirimkan fitur AI yang tidak bekerja lebih buruk daripada mengirimkan terlambat. Fitur non-AI yang dikirim dengan bug diperbaiki. Fitur AI yang dikirim dengan masalah kualitas kehilangan kepercayaan pengguna. Dan begitu fitur AI kehilangan kepercayaan pengguna, membangun kembali kepercayaan itu jauh lebih sulit daripada memperbaiki bug. Kepercayaan fitur AI adalah aset. Kecepatan tanpa kualitas membakarnya." (Rework Analysis, 2025)
"GPT-4 wrapping bukan pilihan teknis yang buruk. Mengirimkan wrapper tanpa diferensiasi dan tanpa telemetry loop untuk meningkatkannya tidak menghasilkan fitur yang terus berkembang. Ini menghasilkan fitur yang stagnan pada kualitas peluncuran sementara kompetitor mengirimkan fitur AI yang lebih ketat dan spesifik yang disetel untuk workflow yang tepat. Kuburan wrapper penuh dengan fitur yang secara teknis benar dengan adopsi nol pada bulan keenam." (Rework Analysis, 2025)
Matriks Kecepatan-Kualitas Pengiriman Fitur AI
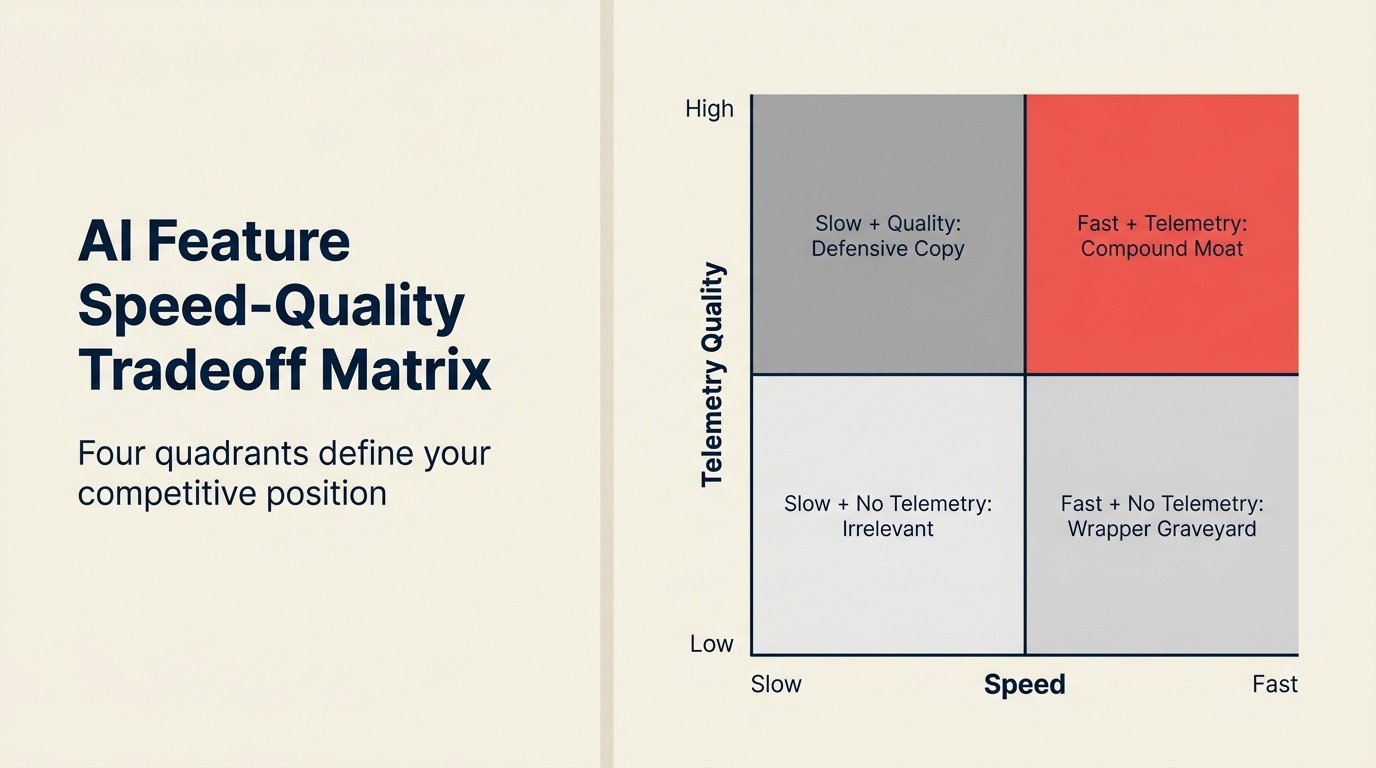
| Pendekatan Pengiriman | Time to Market | Adopsi Fitur (90 hari) | Moat Kompetitif | Profil Risiko |
|---|---|---|---|---|
| Cepat dengan telemetry loop | 4-6 minggu | 40-70% WAU | Dibangun seiring loop berkembang | Rendah: fitur membaik setelah dikirim |
| Cepat tanpa telemetry loop | 4-6 minggu | 3-10% WAU | Tidak ada; dapat direplikasi dalam 4-8 minggu | Tinggi: stagnan pada kualitas peluncuran |
| Lambat dengan quality gate | 12-16 minggu | 30-55% WAU | Moderat saat peluncuran | Sedang: kompetitor mungkin mengirimkan lebih dulu |
| Salinan defensif (mencocokkan kompetitor) | 6-10 minggu | Cocok dengan adopsi kompetitor | Hanya paritas | Sedang: paritas, bukan keunggulan |
Sumber: Wing VC AI Arms Race Analysis 2025, McKinsey AI-Era SaaS Business Models Research 2025, data adopsi GitHub Copilot 2025
Rework Analysis: Uji kalibrasi apakah fitur AI siap dipasarkan sebagai diferensiasi: apakah fitur AI Anda disebutkan tanpa diminta dalam survei NPS? Jika ya, kirim dan pasarkan. Jika Anda harus mencarinya dalam respons yang ditandai, itu belum mendiferensiasikan. AI priority scoring Linear disebutkan tanpa diminta dalam survei NPS tim engineering. Notion AI disebutkan tanpa diminta dalam survei tim marketing. Kedua tim mendapatkan posisi tersebut dengan mengirimkan menggunakan learning loop, bukan dengan menjadi yang pertama ke pasar.
Pengiriman AI defensif vs. ofensif
Arms race menciptakan dua tekanan strategis berbeda yang membutuhkan respons berbeda.
Pengiriman AI defensif adalah mencocokkan fitur yang baru saja diluncurkan kompetitor Anda karena pembeli menanyakannya. Ini adalah reaktif dan perlu. Ketika Intercom Fin diluncurkan, setiap SaaS support harus mengirimkan cerita defleksi AI yang kredibel dalam 12-18 bulan atau menerima attrisi pelanggan ke Intercom. Pengiriman defensif adalah tentang feature parity.
Kesalahannya dalam pengiriman defensif adalah memperlakukannya sebagai strategi produk. Mencocokkan fitur AI kompetitor mempertahankan Anda dalam permainan. Itu tidak menciptakan moat. Jika Anda mengirimkan call coaching AI karena Gong memilikinya, Anda membutuhkan Gong untuk terus memilikinya sebagai alasan untuk tetap. Fitur AI Anda perlu akhirnya mendapatkan diferensiasinya sendiri.
Pengiriman AI ofensif adalah meluncurkan kategori fitur sebelum kompetitor melakukannya. Ini membutuhkan keunggulan data kepemilikan (platform Anda menghasilkan data yang memungkinkan fitur AI yang tidak bisa dibangun orang lain) atau wawasan workflow yang tulus (workflow di mana AI menciptakan nilai yang belum diidentifikasi kompetitor). Fitur AI sebagai produk: di mana menambahkannya adalah kerangka untuk menemukan wawasan workflow tersebut sebelum kompetitor melakukannya.
Prioritisasi issue AI Linear adalah contoh pengiriman ofensif: mereka mengidentifikasi bahwa prioritisasi tiket tim engineering adalah use case AI yang benar-benar kurang terlayani dalam manajemen proyek, membangun fitur sebelum Jira dan Asana memiliki yang setara, dan menetapkan bar kualitas dengan data telemetri yang sekarang merupakan biaya pergantian nyata bagi tim engineering yang telah menggunakannya.
Pengiriman ofensif menciptakan first-mover advantage. Pengiriman defensif mencegah first-mover disadvantage. Anda membutuhkan keduanya, tetapi keduanya adalah investasi yang berbeda.
Risiko positioning AI-native
Semakin banyak perusahaan SaaS yang memasarkan diri mereka sebagai "AI-native." Beberapa memang demikian. Kebanyakan tidak.
AI-native berarti AI ada dalam alur produk inti, bukan ditempelkan. Ini berarti proposisi nilai produk sebagian bergantung pada kualitas AI, dan peningkatan kualitas AI langsung meningkatkan outcome pelanggan. Ini tidak berarti Anda memiliki tombol AI di UI.
Risiko mengklaim posisi AI-native sebelum mendapatkannya: pelanggan mengevaluasinya. Pembeli yang memilih produk Anda sebagian karena posisi AI-native dan kemudian menemukan bahwa fitur AI dangkal akan merasa dijual kepada. Itu adalah churn dengan cerita yang terlampir, dan cerita itu menyebar. Penelitian McKinsey tentang imperativ perangkat lunak berbasis AI menggambarkan kesenjangan kredibilitas ini secara langsung: ketika produk AI+SaaS semakin banyak melakukan pekerjaan daripada hanya mendukungnya, pelanggan dapat mengukur kesenjangan antara kapabilitas AI yang diklaim dan aktual, dan ketidakselarasan ini meruntuhkan kepercayaan lebih cepat dari hampir semua mode kegagalan produk lainnya.
Uji kalibrasinya: apakah fitur AI Anda sesuatu yang disebutkan pelanggan tanpa diminta dalam survei NPS? Jika ya, ini sudah cukup mendiferensiasikan untuk dipasarkan. Jika Anda harus mencarinya dalam respons yang ditandai, belum sampai di sana.
Linear disebutkan tanpa diminta dalam survei NPS tim engineering untuk fitur AI-nya. Notion AI disebutkan dalam survei NPS tim marketing. Ini adalah produk yang mendapatkan posisi AI-native. Mereka mendapatkannya dengan mengirimkan kualitas, mengukur adopsi, dan mengiterasi setiap minggu berdasarkan telemetri.
Kirim cepat dengan learning loop
Perusahaan yang memenangkan arms race AI di 2026 bukan mereka yang mengirimkan paling banyak fitur AI. Mereka adalah yang fitur AI-nya benar-benar digunakan, menghasilkan telemetri, dan meningkat.
Coda mengirimkan fitur AI setiap dua minggu. Linear memiliki peningkatan AI di sebagian besar changelog bulanan. Fitur penulisan Notion AI di 2026 berperilaku berbeda secara bermakna dari peluncuran 2023 mereka karena 3 tahun data penerimaan membentuknya. Ini bukan kebetulan. Ini adalah hasil dari mengirimkan dengan loop yang sudah terpasang.
Kecepatan tanpa pembelajaran adalah cara Anda berakhir di kuburan wrapper. Kecepatan dengan pembelajaran adalah cara Anda membangun moat yang terus berkembang.
Sikap kompetitif yang tepat: kirimkan cukup cepat untuk tetap relevan dalam perbandingan pembeli, tetapi jangan pernah lebih cepat dari yang diizinkan infrastruktur Anda untuk belajar. Jika Anda mengirimkan fitur AI tanpa telemetri, Anda tidak memenangkan arms race. Anda hanya membakar sumber daya engineering tanpa berkembang.
Bangun loop dulu. Kemudian kirim secepat loop mengizinkan.
Pertanyaan yang Sering Diajukan
Mengapa arms race AI SaaS itu nyata dan bukan sekadar hype?
Perilaku pembeli berubah pada 2024-2025 dan belum kembali. Ulasan G2 sekarang menyertakan rating fitur AI sebagai kategori. Komite pengadaan enterprise menyertakan kapabilitas AI sebagai kriteria evaluasi eksplisit dalam RFP. Survei NPS SaaS mulai menanyakan tentang bantuan AI. Sinyal dari pelanggan ke vendor SaaS jelas: kami mengevaluasi AI Anda dan kami akan terus mengevaluasinya. Kesepakatan yang mereferensikan AI mencakup 72% dari semua transaksi SaaS di 2025, peningkatan 12x sejak 2018.
Berapa lama first-mover advantage bertahan dalam fitur AI SaaS?
Sampai kompetitor mengirimkan alternatif yang layak, yang merupakan jendela yang lebih pendek daripada untuk fitur non-AI. Fitur AI MVP yang dibangun pada LLM API dapat dikirimkan dalam 6-8 minggu. First-mover advantage menjadi tahan lama hanya jika tim terdepan membangun telemetry loop selama jendela keunggulan. Keunggulan Copilot GitHub di 2026 bukan dari peluncuran pertama di 2022. Ini dari empat tahun data penerimaan yang membentuk model yang tidak bisa direplikasi pendatang baru dari hari pertama.
Apa itu kuburan wrapper?
Fitur AI yang dibangun sebagai wrapper LLM API generik dengan diferensiasi minimal dan tanpa telemetry loop. Fitur-fitur ini diadopsi sebentar pada 2023-2024, gagal menunjukkan nilai di atas baseline manual, dan sekarang memiliki tingkat weekly active user 3-5%. Masalahnya bukan pilihan teknis. Ini mengirimkan tanpa diferensiasi dan tanpa loop. Wrapper generik stagnan pada kualitas peluncuran sementara kompetitor mengirimkan fitur yang lebih ketat dan spesifik workflow yang terus berkembang dari data pengguna.
Infrastruktur apa yang diperlukan untuk mengirimkan fitur AI pada kadens mingguan?
Tiga komponen. Lapisan integrasi LLM API: layanan backend yang menangani panggilan API, mengelola batas rate, dan dapat menukar model yang mendasarinya tanpa perubahan frontend. Kontrol versi prompt: perubahan prompt diperlakukan sebagai perubahan kode dengan kontrol versi, environment pengujian, dan kemampuan rollback. Pipeline telemetri: penangkapan event terstruktur untuk penerimaan saran, modifikasi, dan outcome. Tim dengan infrastruktur ini mengirimkan peningkatan AI dalam 4-6 minggu. Tim tanpanya membutuhkan 12-16 minggu dan menghasilkan hasil yang lebih rendah kualitasnya.
Apa perbedaan antara pengiriman AI defensif dan ofensif?
Pengiriman defensif mencocokkan fitur yang baru saja diluncurkan kompetitor. Ini reaktif dan perlu untuk mempertahankan paritas. Pengiriman ofensif meluncurkan kategori fitur sebelum kompetitor melakukannya, membutuhkan keunggulan data kepemilikan atau wawasan workflow yang belum diidentifikasi kompetitor. Pengiriman defensif mempertahankan Anda dalam permainan tetapi tidak menciptakan moat. Pengiriman ofensif menciptakan first-mover advantage. Anda membutuhkan keduanya, tetapi keduanya membutuhkan investasi dan metrik keberhasilan yang berbeda.
Bagaimana Anda tahu kapan fitur AI sudah cukup mendiferensiasikan untuk dipasarkan?
Uji kalibrasinya: apakah fitur tersebut disebutkan tanpa diminta dalam survei NPS? Jika ya, pasarkan. Jika Anda harus mencari di respons yang ditandai, fitur tersebut belum mendiferensiasikan. AI priority scoring Linear dan Notion AI keduanya mendapatkan penyebutan NPS tanpa diminta. Kedua tim mendapatkan posisi tersebut dengan mengirimkan menggunakan quality gate dan learning loop, bukan dengan menjadi yang pertama ke pasar.
Pelajari Lebih Lanjut:
- Telemetry Loop untuk In-Product AI: infrastruktur yang membuat "kirim cepat dengan learning loop" menjadi nyata
- Mode Kegagalan AI SaaS: seperti apa erosi kepercayaan dan berapa lama pemulihan memakan waktu
- Fitur AI sebagai Produk: Di Mana Menambahkannya: kerangka untuk mengidentifikasi peluang pengiriman ofensif
- Beli vs. Bangun untuk Fitur AI SaaS: keputusan yang menentukan seberapa cepat Anda dapat mengirimkan
- Mengapa Sebagian Besar Transformasi AI Gagal: konteks strategis mengapa kecepatan tanpa kualitas menghancurkan nilai

Co-Founder, Rework.com
On this page
- The Weekly AI Ship Cadence
- Mengapa arms race itu nyata
- Seperti apa first-mover advantage sebenarnya
- Apa yang dihukum arms race
- Kuburan wrapper
- Apa yang sebenarnya dibutuhkan oleh kecepatan pengiriman
- Matriks Kecepatan-Kualitas Pengiriman Fitur AI
- Pengiriman AI defensif vs. ofensif
- Risiko positioning AI-native
- Kirim cepat dengan learning loop